一种基于多字互信息与邻接熵的改进新词合成算法
2018-05-18王欣
王欣
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引言
随着互联网的发展,网络不断改变着人类的交流方式和表达方式,因此,产生了大量的新词。作为大数据时代最热门的社交网络媒体,微博成为了互联网上新词诞生和高速流传的重要平台。因为对新词的识别不够充分,很大程度上影响了中文分词的准确性。所以,基于微博短文本的新词发现具有十分重要的研究意义与价值。
虽然现在对于新词的研究已经逐渐深入,但是关于新词的界定还没有一个准确的定义。目前,主流的新词概念有两种,未登录词和新词。未登录词(Unknown Word)是指没有收录在词典中的词语[1];新词(New Word)是指随着时代的发展而出现的具有新的构词规则、新的使用方法或新的意义的词语[2]。
新词发现的方法按处理的候选字符可以分为:基于重复字符串的方法和基于分词的方法。基于重复字符串的方法是先从语料中按不同长度依次切割得到候选字符串,然后再判断候选字符串是不是新词。基于分词的方法则是在对预料进行分词的基础上,在切分成多个词的字符串中发现新词。
基于重复字符串的方法简单易懂,且容易实现,但是由于逐字滑动切割固定长度的字符串,会产生大量的重复串,效率比较低。孙立远等人[3]采用N元递增算法(N-gram)获取所有2-5字组成的汉字符串作为候选字符串,用词频和词语灵活度对候选词进行过滤得到新词。Du Y等人[4]提出了一种结合传统N-gram算法和基于词向量的相似度剪枝方法进行新词识别。唐波等人[5]采用广义后缀树的数据结构存储字符串及其前后缀,通过构词能力提取候选词。郑家桓等人[6]用新词的构规则总结归纳了适用于网络新词发现的构词规则库,取得很好的效果,但构词规则的制定需要大量人工标注,且可移植性比较差。Su Q L等人[7]针对微博文本特点和统计手段的缺陷,分析了5种经典统计量,在此基础上改进了邻接熵,通过计算加权相对临界熵,新词抽取能力提升且对词频不敏感。夭荣明等人[8]提出了一种MBN-gram算法,用多个统计量过滤重复字符串得到候选项,基于改进互信息和邻接熵对候选项进行扩展和过滤,从中筛选出新词,并在不同语料规模上进行实验,均有效可行。梁韬等人[9]根据词语信息量特征和条件随机场进行新词发现,取得了一定的效果。邢恩军等人[10]提出了一种基于上下文词频词汇量的统计指标,基于改进信息熵公式和邻接关系的字符串连接方法发现新词,改善了左右信息熵在识别新词时特征不明显和N-gram固定滑窗缺陷。
基于分词的方法是虽然效率有所提高,不会产生过多的重复串,但对分词器的效果有较强的依赖。张华平等人[11]针对社会媒体的特征,提出一种基于条件随机场实现的字符标注分词算法,结合基于全局特征的过滤方法进行新词识别,算法所有步骤均为线性时间复杂度,速度有所提升,实验效果也较好。周霜霜等人[12]融合构词规则、改进的C/NC-value算法和条件随机场模型进行微博新词抽取,提高新词识别准确率以及对低频微博新词的识别率。Chen F等人[13]利用条件随机场和多个词边界统计特征进行开放领域的新词发现。雷一鸣等人[14]采用互信息统计模型对最小搭配单元的候选词进行向右扩展统计并去除低频词以获得新词,规避了N元重叠问题。周超等人[15]根据字符串频率、成词规则和邻接域变化特性筛选新词,在COAE2014评测任务上取得了较好的成绩,但对低频词不友好,且垃圾串并未完全过滤。李文坤等人[16]针对分词后的散串,结合词内部结合度和边界自由度进行新词发现,该方法在大规模语料上有效,但对低频词的识别并不是很有效。
本文在进行了相关理论研究的条件下,对新词发现方法进行分析和讨论。针对现有方法中对低频新词不敏感、新词合成算法发现的新词内凝聚度不够稳固等问题,改进了一种结合统计、规则和改进的新词合成算法发现新词的方法。通过设计对比的实验证明,这种方法能够提高新词发现的效率。
1 新词特征选择
判断两个汉字是否能构成一个词语,需要判断两个汉字之间结合的紧密程度,词内凝聚度可以用来衡量两个汉字构成词语的可能性。词内凝聚度越大,表明汉字之间的结合程度越紧密,构成词语的可能性越大。当词内凝聚度大于一定的阈值时,就可以认为它们能构成一个词语。
互信息是常用的表示词内凝聚度的统计量,可以用来推断多个特征关联程度的大小,通常用来衡量两个信号之间的依赖程度[16]。在做文本分类时,可能会判断一个词和某类的相关程度,但是在计算时未必会考虑词频的影响。所以,在计算两个词语共同出现的概率时,更多的是使用点互信息(Pointwise Mutual Information,PMI)来度量两个词内部结合的紧密程度。点互信息越大,说明词的词内凝聚度越大,成为新词或者新词的一部分的可能性就越大。计算公式见式(1)。
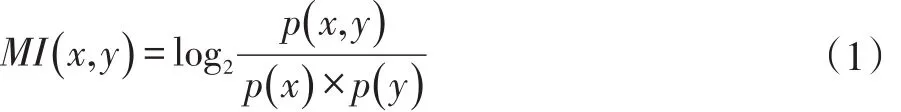
其中,p(x,y)是字符x和y在语料里同时出现的概率;p(x)是字符x单独出现的概率;p(y)是字符y单独出现的概率。当MI(x,y)≫0时,表明x和y是高度相关的,他们经常同时出现,字符串xy就很有可能构成新词;当MI(x,y)=0时,表明x和y是相互独立分布的;当MI(x,y)≪0时,表明x和y是互不相关分布的。
点互信息对于二元词组的计算有很好的效果,但是对大于两个字的多字词如何划分成两部分是比较困难的,针对这个问题,本文采用多字点互信息计算公式[17],见式(2)、式(3)和式(4)。
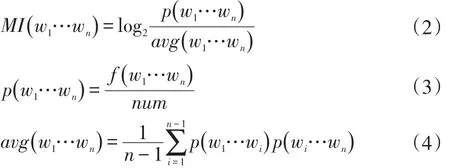
其中,w1…wn为多字字符串,p(w1…wn)是字符串w1…wn在语料中出现的概率;f(w1…wn)表示字符串w1…wn在语料里出现的次数;num表示语料里的总字数;avg(w1…wn)表示多字字符串不同组合的平均概率。改进后的计算公式能够计算多字词语之间的点互信息,本文算法所使用的是多字点互信息。
两个汉字是否能够构成一个词语,除了推断汉字之间的结合程度外,词语相邻字的多样性也是一个衡量标准。边界自由度是指与一个字符串相邻的所有字符种类的数量。边界自由度越大,表示字符串的相邻字符集合中的字符类别就越多,与该字符串相邻的字符就越丰富多样,那么该字符串的边界就越明确,这个字符串成为词语的可能性就越大。目前常用的外部统计量包括邻接熵[18]和邻接类别[19](Accessor Variety,AV)。通过已有的对比方法发现邻接熵比邻接类别的准确率要高,所以大多数研究都是以信息熵作为衡量字符串成词概率的外部统计量。
在新词发现任务中,确定词语的左边界和右边界的统计量通常是左右信息熵。一个候选词组的左信息熵是指该候选词组和与它左边所有相邻的字结合的信息熵之和,用来判断该候选词组的左邻接字的多样性。左信息熵越大,说明该候选词组左边相邻的字的种类越多,那么该候选词组成为某个词语的左边界的可能性越大;反之,左信息熵越小,该候选词组左边相邻的字的种类越少,它不是某个词语的左边界的情况就越肯定,那么就应该对该候选词组向左扩展直到左边界确定为止。式(5)为候选词左信息熵的计算公式。

其中,Hleft(W)是候选词语w的左信息熵,Cleft是候选词w的左邻接字集合,p(wleft|w)是候选词w出现的情况下它左边的邻接字是wleft的条件概率。如果N(wleft)是左邻接字wleft和候选词w共同出现的概率,N(w)是候选词w单独出现的概率,p(wleft|w) 的计算公式如式(6)所示。

同理,右信息熵用来推断词语的右边界,候选词的右信息熵计算公式见式(7)。
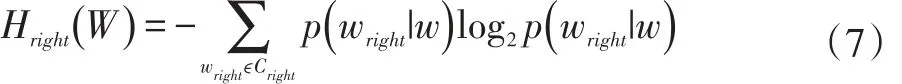
其中,Hright(W) 是候选词w的右信息熵,Cright是候选词的w的右邻接字集合,p(wright|w)是候选的词w出现的情况下其右邻接字是wright的条件概率。如果N(wright)是wright和w同时出现的概率,N(w)是w单独出现的概率,那么p(wright|w)的计算公式见式(8)。

因此,若Hleft(W)大于指定的阈值,则左边界确定;若Hright(W)大于制定的阈值,则右边界确定[20]。
2 新词合成算法
基于规则和统计的新词发现是一种有效的新词抽取方法,目前己经提出了很多融合的方法,基于词内部凝结度和边界自由度的新词发现算法是目前比较常用的信息发掘方法,本文对该类算法进行了全面的分析,并基于此改进了适合微博新词发现的方法。
现有的多种基于词内部凝结度和边界自由度的新词发现算法之间的不同之处通常体现在候选词串的选择上。一种是通过N-gram算法对文本语料进行切分,选择频率达到阈值并满足条件的词作为候选词。N-gram算法最大的优势是具有语言无关性,不需要对文本语料进行语法规则和专业词典等语言学方面的处理,对于书写错误也有很强的容错性。虽然N-gram算法简单易实现,但是效率并不高,不适合针对规模较大的文本进行新词挖掘。另一种是利用分词工具对文本语料进行分词,统计分词后的文本中散串,针对散串进行新词发现。所谓散串,是指经过分词软件分词以后,连续多个单字(不包括标点符号)组成的字符串[16]。虽然大多数新词都以散串的形式出现,但是个别词会被分词工具切分成双字或多字的形式,影响新词识别的召回率。常用的新词发现算法流程如图1所示。
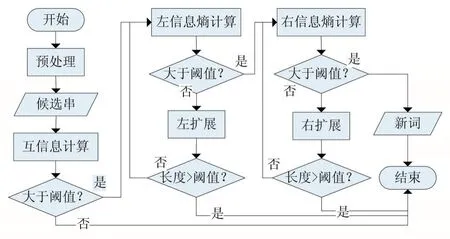
图1 新词合成算法流程
考虑到现有的基于词内部凝结度和边界自由度的新词发现算法存在的不足之处,为了改善更多新词存在的情况以及对结合后的新词内凝聚度不充足的问题,本文在NLPIR分词工具[21]对已经预处理好的语料进行分词后,采用改进的新词合成算法对全文进行新词发现,改进的新词合成算法的算法流程如图2所示。
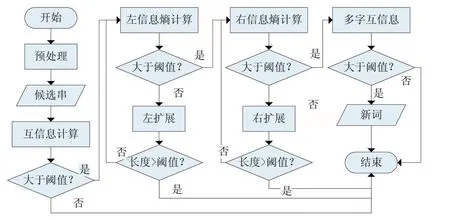
图2 改进新词合成算法流程
3 实验结果及分析
①实验数据
语料:本实验选用的是NLPCC2014任务1提供的评测数据,其中情绪表达抽取子任务的训练集包含1000条微博,共3454个句子;测试集包含10000条微博,共36005句。
符号过滤表:利用正则表达式从语料中挑选的标点符号和特殊符号。
标准新词集:从训练语料中人工抽取新词,作为标准新词集。在本研究任务中,新词是指有一定使用频率、被分词工具切分错误且不在常用词典中的未登录词。本文人工标注了该数据集中情绪表达抽取子任务训练集的新词共150个。
工具:NLPIR分词工具、Python3.6。
②评价指标
对于新词发现任务的训练集,采用PRF值即正确率(Precision)、召回率(Recall)和 F 值(F-measure)来评价各个新词发现的性能,PRF计算公式如下:

其中,GN表示新词发现方法正确识别出来的新词个数,N表示新词发现方法识别出的词语总数,M表示在语料中人工标注的新词总数。
③新词合成算法对比实验
根据上一部分实验的分析,在语料库上进行实验,将点互信息与邻接熵结合的新词发现作为基线(PMI+BE)实验,对比多字点互信息与邻接熵结合的新词发现(nPMI+BE,即本文方法)进行对比实验,实验结果如表所示。
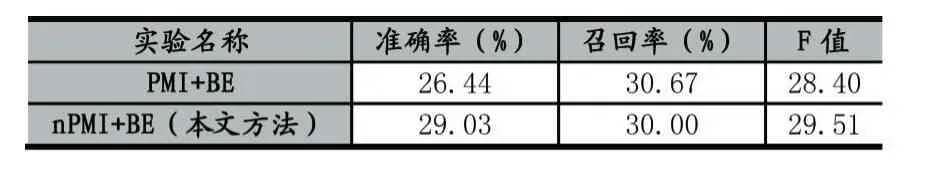
表1 新词合成算法对比实验
实验结果分析:通过改变点互信息可以提高微博新词的识别精度。本文在进行左信息熵和右信息熵计算之后,对扩展的候选词进行二次互信息计算,可以得到词内凝聚度更高的候选新词,减少因成词概率低导致的错误结合,一定程度上提高了新词识别的准确率。
4 结语
本文就微博新词发现和新词的情感极性判断问题进行了研究,首先分析了现有新词发现方法仍存在的问题,针对被分词工具错分成多个词的新词,结合多字点互信息和左右邻接熵以及本文改进的新词合成算法对相邻词进行合并,得到候选新词;再对候选新词集合进行低频词、首尾停用词、构词规则、常用词典等规则与统计相结合的过滤方法,去除不符合要求的字符串,最后得到新词集合。并通过在NLPCC2014会议任务提供的评测数据上的新词发现对比实验验证了该方法的可行性和有效性。但同时,本文方法还有一些需要改进的地方,可以深入分析新词识别中的结果错误,多角度分析与总结结合错误的字符串的特点与规律,找到更通用的过滤方法。发掘更多的统计量特征,提出新的统计算法,找到有效的方法实现对新词快速准确的抽取,以及探寻新的新词发现方法,提高新词发现的效率。
参考文献:
[1]Ling G C,Asahara M,Matsumoto Y.Chinese Unknown Word Identification Using Character-Based Tagging and Chunking[J].Proceedings of Annual Meeting on Association for Computational Linguistics,2003:197-200.
[2]邹纲,刘洋,刘群,等.面向 Internet的中文新词语检测[J].中文信息学报,2004,18(6):1-9.
[3]孙立远,周亚东,管晓宏.利用信息传播特性的中文网络新词发现方法[J].西安交通大学学报,2015,49(12):59-64.
[4]Du Y,Yuan H,Qian Y.A Word Vector Representation Based Method for New Words Discovery in Massive Text[J].Springer International Publishing,2016,10102:76-88.
[5]唐波,陈光,王星雅,王非,陈小慧.微博新词发现及情感极性判断分析[J].山东大学学报(理学版),2015,50(01):20-25.
[6]郑家恒,李文花.基于构词法的网络新词自动识别初探[J].山西大学学报(自然科学版),2002(02):115-119.
[7]Su Q L,Liu B Q.Chinese New Word Extraction from MicroBlog Data[C].International Conference on Machine Learning and Cybernetics.IEEE,2014:1874-1879.
[8]夭荣朋,许国艳,宋健.基于改进互信息和邻接熵的微博新词发现方法[J].计算机应用,2016,36(10):2772-2776.
[9]梁韬,张瑞.基于词语条件信息量的新词发现[J].电子技术与软件工程,2014,(11):181-182.
[10]邢恩军,赵富强.基于上下文词频词汇量指标的新词发现方法[J].计算机应用与软件,2016,33(6):64-67.
[11]张华平,商建云.面向社会媒体的开放领域新词发现[J].中文信息学报,2017,31(03):55-61.
[12]周霜霜,徐金安,陈钰枫,张玉洁.融合规则与统计的微博新词发现方法[J].计算机应用,2017,37(04):1044-1050.
[13]Chen F,Liu YQ,Wei C,Zhang YL,Zhang M,Ma SP.Open Domain New Word Detection Using Condition Random Field Method.Journal of Software,2013,24(5):1051-1060(in Chinese).
[14]雷一鸣,刘勇,霍华.面向网络语言基于微博语料的新词发现方法[J].计算机工程与设计,2017,38(03):789-794.
[15]周超,严馨,余正涛,洪旭东,线岩团.融合词频特性及邻接变化数的微博新词识别[J].山东大学学报(理学版),2015,50(03):6-10.[16]李文坤,张仰森,陈若愚.基于词内部结合度和边界自由度的新词发现[J].计算机应用研究,2015,32(8):2302-2304.
[17]Ye Y.M,Wu Q.Y,Li Y,et al.Unknown Chinese Word Extraction Based on variety of Overlapping Strings[J].Information Processing&Management,2013,49(2):497-512.
[18]Huang J H,Powers D.Chinese Word Segmentation Based on Contextual Entropy[C].Proceedings of the 17th Asian Pacific Conference on Language Information and Computation,2003:152-158.
[19]Feng H,Chen K,Deng X,et al.Accessor Variety Criteria for Chinese Word Extraction[J].Computational Linguistics,2004,30(1):75-93.
[20]Thomas M.Cover,Joy A.Thomas著.信息论基础(原书第2版)[M].阮吉寿,张华译.北京:机械工业出版社,2007:9-16.
[21]张华平.汉语分词系统[EB/OL].http://www.nlpir.org/.
