依赖隐马尔可夫模型的决策支持方法
2018-05-17王建国
王建国
(阳泉师范高等专科学校 信息技术系,山西 阳泉 045200)
在智能技术快速发展的背景下,根据系统架构,依赖隐马尔可夫模型的决策支持可分为集中式和分布式两大类[1]577-589,[2]2299-2308.集中式决策依赖系统的主要信息,尽可能多地收集有关目标点附近存在的尽可能大的范围内存在的状态信息,之后,在这些信息的基础上展开对模型行为的决策[3]1336-1348.依赖滚动优化的决策支持方法、依赖空间槽的决策支持方法以及最优在线决策支持方法,但在真正的应用实践中还是会受到一定条件的限制,因为要想进行集中式的决策,只依靠稳定的数据通信是不能满足的,这会直接导致决策的效果变差[4]192-200,[5]280-283,进行目标的集中决策也会直接加大主要信息的运算负荷,使之无法承受.目前在进行决策算法时,往往选择已有的研究,过度依赖逻辑规则的方法,亦或是直接选择依赖在函数模型上进行的最优化的算法.因此,想要让决策方法更容易实现,可以选择用逻辑规则作为评估依据是否要换道,该做法虽然有很高的实时性,但是存在着较大的问题,即其所具有的逻辑规则很难对复杂模型交互关系进行描述[6]18-30.
现有依赖逻辑规则的决策支持方法精准度不高,加上选用的决策方式是以函数模型为基础,使其在模型的精确性方面完全不能与依赖概率模型进行的算法相比.因此,本文提出依赖隐马尔可夫模型的决策支持方法,通过利用隐马尔可夫模型对序列编码进行训练,得到最优决策序列,将其作为数据样本,同时选用具有启发式的遗传算法,充分挖掘决策表的决策支持能力.
1 隐马尔可夫模型下的决策支持方法
1.1 隐马尔可夫的数学模型
由决策的速度和密度来进行刻画的决策支持的特性,其在本文中主要是根据平均的决策速度、决策的速度和多目标的决策速度不断衰减的程度作为参数,然后选取出多个多目标的情况来成为样本,在此之后进行决策.在支持方法中,采用隐马尔可夫模型 (hidden Markov model,HMM)刻画决策支持中单个目标的决策行为.隐马尔可夫模型的状态与所处环境之间满足如下关系式:
(1)

(2)
其中,vα,v(α-1)分别表示此时和上一环节中决策速度,v0表示期望决策速度,s0表示最短数据间距,T表示期望数据.通过在自身的基础上进行加速和减速等行为以及之后加入数据,使得该模型能够约束后继而来的模型的响应.
1.2 决策支持方法设计
本文的决策支持方法主要采用隐马尔可夫模型,在多目标点的基础上选择通过一定距离内存在的浮动特性,使得本文可以选用可变的有效位的编码方式.也就是说,通过选用在m个时间片中进行位置的调整和决策的速度,之后在第m+1个时间片中进行多目标的执行,由此出现相应的编码形式:染色体中存在的前m个基因位是根据0、1、2进行组合而成的随机序列,而从第m+1个基因位开始将成为利用编码3进行填充的后续基因.
因此,适应度的函数可以直接选用下面的这个表达式:
(3)
在该表达式中,tc(V)所代表的是在一个特定的系统片段当中,通过隐马尔可夫模型进行多目标的完成任务,并且包含其全部通过瓶颈处时所需要消耗的时间,如果在这其中多目标中发生了碰撞的情况,其适应度可以直接置零.
在本文中所采用的优胜劣汰方式是无放回式的随机余数进行选择的算子作为,RSSR算子则是在个体的适应度值的基础上进行下一代群体中拥有的生存数目进行确认的.因此,其表达式为:
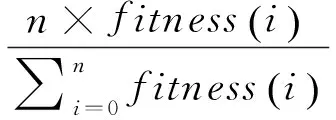
(4)
在包含有10个时间片段的决策序列的基础上,可以通过选择可变的有效位染色体编码方式进行的单点交叉操作为:
A=1 2 /2 2 3 3 3 3 3 3B=1 0 0 1 1 2 /2 3 3 3
从中可以看到,如果A染色体中包含的有效交叉点为4个,B染色体中包含的有效交叉点为7个时,就可以随机对A、B染色体的交叉点进行选择.如果选择2和6,在截断后进行拼接,就会发现,A染色体中会随机选择0、1、2进行空缺位的填补,而B染色体中就会直接舍去冗余位,然后直接用A染色体段中的基因位进行覆盖.由此可得,其交叉的结果是:
A=1 2 0 2 1 0 2 3 3 3B=1 0 2 2 3 3 3 3 3 3
其单调性就不会存在于多目标决策寻优当中,这样不仅能够有效防止隐马尔可夫模型陷入到局部的最优解当中,而且能够对相似的最优解进行一次计数Convergence Count,从而促使种群连续迭代5次均能够直接收敛于统一的准最优解fitness(Temp Best)当中,从而导致一个大规模的变异发生,以此来进行种群中基因模式的更新,与此同时,还能够用变量Opt Count对变异次数进行计数.当发生过3次大规模的变异之后,就能够收敛到相似的准最优值fitness(Best)会将Best作为近似的最优决策.
隐马尔可夫模型的根节点建立在所有训练数据集合的基础上,然后选用递归分割的方法直接二分特征向量中合适变量和分隔值对节点中的样本,在分割的节点后会派生出两个子节点,之后在不断的循环运算之后,最终终止的条件就是满足分割,由此生成一种树形结构的分割结果.在这个分割结果中,表示决策结果的是叶子节点,而表示作出该决策相对应的环境条件是从根节点到叶子节点的路径进行的分割特征和分割阈值.通常最常选用的节点分割算法有3种:基尼指数法、卡方分布检验法和信息增益率法.信息熵增益法,最大的不同点就是其需要更长的时间才能最终达到峰值,换句话说是有着非常严格的划分标准.不过,本文中所选用是维数不高的特征向量,并不会出现因为分割条件的不同而导致计算时间过长,所以在本文中,主要是先选用对特征进行离散化,之后再选用信息增益率作为标准进行节点分割.这样一来,表示信息增益率的计算方式为:
(5)
IG(Ft,Gap)=H(C)-H(C|Ft)

(6)

(7)
式(5)表达了信息熵的计算方式,P(Ci)表示属于Ci决策的样本概率.式(6)中,IG(Ft,Gap) 是对环境特征Ft,和产生信息熵增益所对应的阈值Gap进行分割节点的样本进行表示的,而P(
2 实验与分析
2.1 实验仿真
利用计算机对50个多目标情况在经过80 h的寻优之后,能够完成地获得2 311条样本.但是,在完成多目标过程中,最终执行换道的决策少于用于决策速度的调整策略,使得2 311条样本中可用的仅仅只有200多条包含换道决策的样本,这样的不平衡的数据在进行集合之后,会对分类决策树的训练结果产生很大的影响.在Gustavo的论文中,曾经有过关于处理机器学习中存在的不平和数据集的方法论述,主要包括相比欠采样、过采样和欠采样.文中对3种方法的描述促使本文在进行随机选择的时候欠采样,使得与换道决策无关的样本在一定程度上减少了,从而能够在最终时刻,选用636条样本进行决策树的训练分类,而这些训练的条件是叶子几点内包含有至少10个样本,促使决策树的最小信息熵为0.8,最大深度为9.
验证实验中多目标情况中设置了4 000 m的双数据与1 000 m的单数据交汇于Dm(0,0),产生了一个由数据数减少引起的多目标情况.仿真隐马尔可夫模型具有4 m/s2的最大加决策速度,具有33.3 m/s的最大决策速度,-2 m/s2的最大减决策速度.之后,在泊松分布随机插入在双数据的左端D0(—4 000, 0)的基础上,把出发的决策速度控制在30 m/s左右,隐马尔可夫模型在系统瓶颈前500 mDr(-500,0)能够对即将发生的多目标首先洞悉,使得其能够在换道决策算法上优先执行,保证了数据间拥有有效距离为300 m的通信,这保证了在仿真过程中,隐马尔可夫模型能够最大可能地收集到其周围300 m内存在的隐马尔可夫模型的决策速度信息和位置,从而做出正确决策.在实践中,可以选择在Dr和Dm设置感应线圈,以便于能够检测出进出多目标区域的数据流,如表1所示为平均等待时间比较.
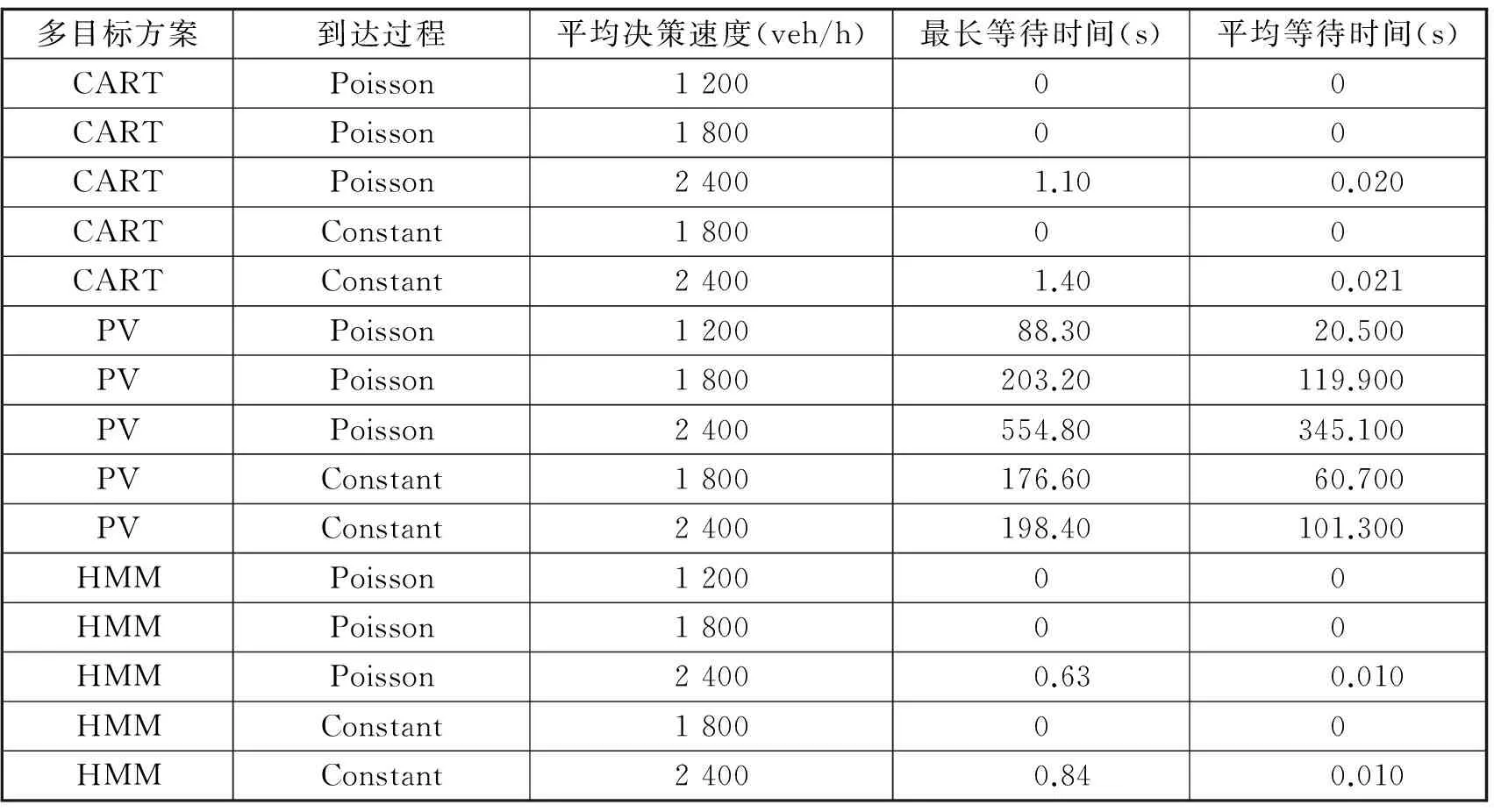
表1 平均等待时间比较
本文主要是选取了有关于隐马尔可夫模型的平均决策速度、等待时间和通行量,这些都能够作为多目标效果进行评测的依据,隐马尔可夫模型的决策速度如果低于0.5 m/s的时间累积成均值就是平均等待时间,这个平均等待时间通常是在系统的瓶颈处因为拥堵造成的数据等待而产生的.除此之外,本文还选用了1 200 veh/h、1 800 veh/h和2 400 veh/h的顶端双数据决策速度,这其中的3种数据流密度是非常符合恒定和泊松分布的两种数据流的特性.如果在上述3种多目标方案上进行实验,仿真运行为1 200 s,这就会导致在不同的数据流特性和决策速度的情况下,依赖隐马尔可夫模型的多目标方案相较于PV方法具有明显优势,且其平均等待时间与依赖全局信息方法相近.
2.2 实验结果分析
在系统瓶颈点底端上的一个系统截面中,通过在单位时间内存在的数据数量,就是平均通行量,平均通行量能够对多目标效率进行直观的反应.图1描述顶端双数据总决策速度为1 400 veh/h和2 600 veh/h时底端的平均通行量.

图1 底端平均决策速度
在1 400次/h决策速度状况下,0~200 s内存在着3种方法的多目标效果差异几乎不存在.差异产生是在200 s之后,当PV在1 050 veh/h左右最终稳定之后,CART与HMM就能保持着几乎一致的稳定时性,使得系统瓶颈点上的顶端和底端决策速度也能够保持着一致的稳定,从而有效阻止了拥堵现象的出现.
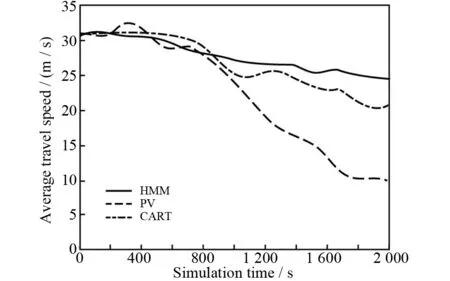
图2 多目标点顶端平均决策速度
在2 600次/h决策速度状况下,0~400 s内存在着3种方法的多目标效果差异几乎不存在.而在此之后,差异也会慢慢出现,当PV在1 400 veh/h左右最终稳定之后,非常严重的拥堵现象就会出现,此时CART方法和HMM方法之间的稳定决策速度不会产生悬殊的差异,从而保证了拥堵现象不会在决策速度快的情况下出现.从该实验结果的对比可以发现,在本文中提出的HMM方法,可以与在全局信息的基础上进行的多目标方法在多目标效率方面上进行对比,并且在应用过程当中,其隐马尔可夫模型也有着非常明显的优势.
在图2中,对于恒定数据流下进行的多目标点顶端上的平均决策速度进行了描述.PV因为拥堵现象出现而导致数据流平均决策速度下降飞快,而HMM方法和CART方法仍能够保持较高的决策速度,实现数据流的持续高效通行,本文所提方法对环境描述的准确决策依赖于隐马尔可夫模型.决策速度测量通常采用编码器,该显示器能准确反映依赖隐马尔可夫模型决策方法的决策速度.
3 结论
本文利用隐马尔可夫模型所具有的大量有关于优秀多目标案例中存在的决策方法,促使隐马尔可夫模型不仅能够根据本数据在局部系统的状况中进行灵活调整,同时还能够根据相近的数据中的局部系统状况做出相关决策,最终做出了保证群体最优的决策.该实验表明本文中提出的依赖隐马尔可夫模型决策支持方法能够尽可能地降低多目标行为对数据流的扰动.
