一种权值可发育的视觉选择性注意模型研究
2018-05-15李福进杜建任红格史涛
李福进 杜建 任红格 史涛

摘 要: 针对Itti视觉选择性注意模型不具有子特征图显著图归一化过程中权值随任务改变而改变的问题,借鉴自主发育在视觉选择性注意学习的研究成果,提出一种权值可发育视觉选择性注意模型作为图像特征提取的学习机制。该算法采用三层自组织神经网络和Itti视觉选择性注意模型相结合的决策进行寻优,通过对模型的训练学习获取最优权值更新。这样既可以保证在初期特征提取内容的完整性,又降低了系统对不同任务条件的约束性,提高了模型特征提取能力。利用权值可发育视觉选择性注意模型对图像进行感兴趣区域特征提取实验,结果表明,该方法能够提高特征提取准确性、减少运算时间,获得了良好的动态性能。
关键词: Itti视觉选择性注意模型; 权值可发育; 自主发育; 特征提取; 显著图; 模型训练
中图分类号: TN911.73?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2018)10?0183?04
Abstract: In the Itti visual selective attention model, the weight does not change as the task changes during the saliency map normalization of child feature map. Therefore, a visual selective attention model with weight development is proposed to be the learning mechanism of image feature extraction by learning from the research achievements of autonomous development in visual selective attention learning. In the algorithm, the strategy of combining three?layer self?organized neural network with Itti visual selective attention model is used for optimization. The optimal weight update is obtained by training and learning of the model, which can not only guarantee the completeness of the initial feature extraction content, but also reduce the constraint of the system on different task conditions, and improve the feature extraction capability of the model. An interested?area feature extraction experiment was carried out for images by using the visual selective attention model with weight development. The results show that the proposed method can improve the accuracy of feature extraction, reduce the computation time, and obtain a good dynamic performance.
Keywords: Itti visual selective attention model; weight development; autonomous development; feature extraction; saliency map; model training
0 引 言
视觉选择性注意(Visual Selective Attention)机制[1]是一种视觉感知机能,它是灵长目类动物长期进化的结果。研究表明,人类在感知外界信息信号过程中大约有75%的信息来源于视觉,在面对海量的感知信息时,为确保大脑处理信息的效率,视觉系统会选择感知信息中的一个子集做优先处理。在认知心理学中,这种选择有限信息进行优先处理的机制称为视觉选择性注意机制。基于此,研究者们根据心理学、生理学、认知科学的相关实验结果,模拟出一系列视觉选择性注意模型,1998年Itti和Koch提出显著性模型[1?2](Itti模型),该模型是以特征整合理论为基础,利用高斯金字塔生成多尺度图像,对图像滤波提取颜色、亮度、方向特征,后由中心周边差得到三种特征的子显著图(Saliency Map),通过子显著图归一化生成总的显著图,并采用赢者求全机制和返回抑制机制控制视觉注意焦点的转移,该模型是最为经典的可计算视觉注意模型之一。2007年Taatgen提出基于SR的显著性模型[3],计算空域下的显著图,分析图像对数频谱抽取图像剩余残谱。其特点是计算速度快,但是模型在边缘信息处理方面表现效果一般。2009年Judd提出一种自顶向下[4?6]的注意模型,该模型具有一定的仿生特性,训练过程采用眼动数据,针对特定目标训练模型计算过程耗时略长。2016年王凤娇提出了一种视觉注意分类模型(CMVA)[7],该模型是在基于眼动数据的基础上搭建而成,以预测视觉显著性,与其他现有几种视觉选择性注意模型的比较,特征显著点选择效果比较好,但要求的初始条件约束比较多,计算量很大。
近些年,随着仿生学在视觉感知领域的深入发展,越来越多的仿生模型[8?9]出现,也使得自主发育[10]成为视觉选择性注意研究领域的热点。本文针对Itti模型在子特征显著图归一化过程中权值不能随自上而下的任务而自动调整问题,提出了一种权值可发育的视觉选择性注意模型(权值可发育Itti模型)。采用三层自组织发育神经网络[11]与Itti模型结合发育学习,其中发育学习由感知端[X]、脑分析端[Y]和效应端[Z]组成,来模仿人类大脑。通过发育学习训练对网络中神经元权值进行更新,由神经元的更新实现Itti模型的底层特征图提取的准确性和快速性,发育学习后将学习结果存储在神经元中,来实现对新知识的学习和理解。仿真结果表明,这种权值可发育Itti模型在特征提取上更符合灵长目类的视觉感知特性,表现了该模型的权值自主学习的动态变化特性,并生动地模拟了图像中感兴趣区域的特征提取过程。
1 视觉选择性注意模型
可计算Itti模型是由Itti提出的视觉选择性注意模型,也是目前最具影响力的一种数据驱动型模型,主要根据所寻目标与周围环境之间的差异,提取图像中感兴趣区域。
2 三层自主发育网络
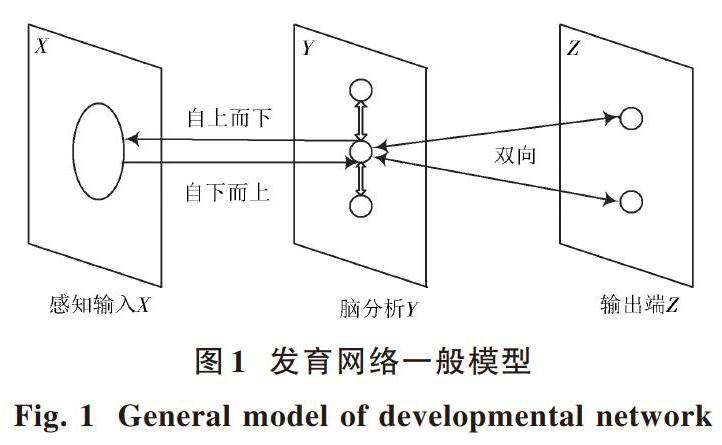
本文采用Weng提出的自主发育神经网络[12],由[X,Y,Z]三层组成。其中[X]为感知输入层,[Y]为脑分析层,[Z]为输出端。发育网络一般模型如图1所示,[X]与[Y]、[Y]与[Z]之间均可双向传递信息,[X]作为输入端感知外界信息,[Y]收集来自[X]的信息并传递给[Z]。设计者并没有事先知道智能体将来要学习的任务,设计者只是设计一些自主学习规则。因此,发育学习程序是任务非特定性的,其核心思想是,在不同的环境下,智能体(具备感知,处理和行动的物体)通过它的感知端[X]和效应端[Z]与外部环境和内部大脑交互,自我构建脑中的连接,来适应不同的外部环境。
3 权值可发育的Itti视觉选择性注意模型
3.1 权值可发育Itti模型结构
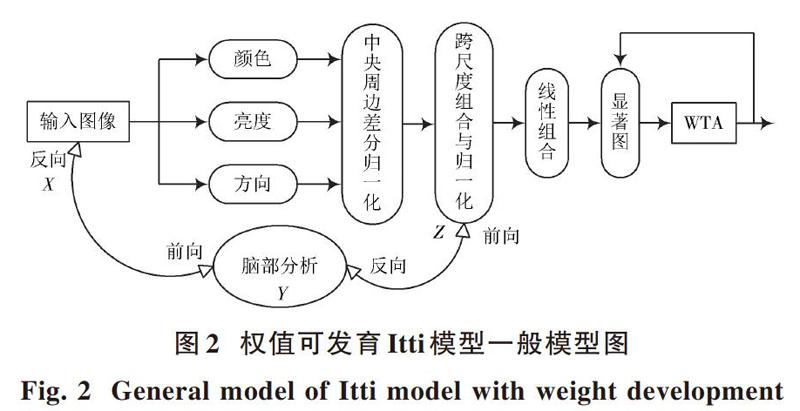
由于Itti视觉选择性注意模型在感兴趣区域特征提取上并无主动学习能力,而只是通过环境自底向上地做出选择,因此不能做出准确的特征提取。而灵长目类视觉系统具有学习、理解特性,能将自下而上的数据和大脑分析相交互处理,通过发育学习,在视觉選择性注意上远远超出简单的自下而上型注意机制功能,权值可发育Itti模型如图2所示。
感知输入端[X]接受环境传入信号传送至脑分析端[Y],[Y]端传出信息调整效应端[Z],信息可向反馈调整后权值结果。整个过程都使权值的调整处于一个可控范围,并随前端任务动态调整。
3.2 发育网络算法
通过发育神经网络模型简单模仿人类大脑。使感知端[X]与效应端[Z]通过大脑分析建立连接,以适应感知端输入图像的变化。同时,[Y]端理解并存储所学“知识”,以神经元的形式存储记忆,整个过程类似大脑发现?思考?记忆?注意过程。用神经元的激活、抑制来实现Itti模型的底层特征图提取过程中权值的分配,发育算法如下:

式中,[k=1],所以只有惟一获胜的神经元被激活,其余的神经元则被抑制。在发育学习阶段,被激活后的神经元更新相应的突触权重,三层神经元之间相联系的向量便可得到更新。这是一种增量式学习过程,每当环境产生变化时,不需要更新所有神经元权值,仅做由于新增数据所引起的更新,是符合人类视觉的学习过程。
4 实验过程与分析
为了检验本文所提方法的可靠性,将Itti模型算法与本文算法分别在实验室所提供上位机(Intel[?] CoreTM i5?2430M CPU@2.4 GHz,RAM4.00 GB,Windows 7)和Matlab 2012b编程环境下实现仿真处理。图像选自Caltech?101数据库图像,从中选取三幅图像,图3a)为所选取的汽车、鹤和花的原图,图3b)为Itti模型算法仿真所得结果图,图3c)为本文所提的权值可发育Itti模型算法所得结果。三幅Itti模型算法仿真结果图都注意到了感兴趣区域,基本上能识别出目标的大体轮廓,但注意目标的细节信息还是被复杂地背景模糊掉了。权值可发育Itti模型算法结果图能注意到最显著区域,对于复杂背景下的目标对象识别效果还是比较优秀的,在背景简单的目标上表现更出色,如图3c)中的鹤和花相比Itti模型算法所得结果具有非常好的显著性。

仿真时间对比如表1所示。
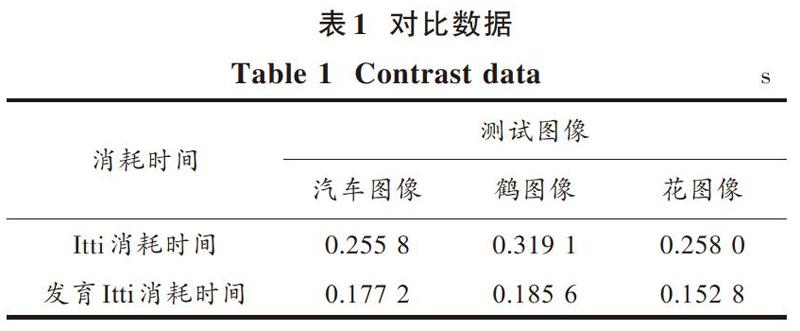
由表1可以看出,Itti模型算法仿真计算耗时较多,本文所提出的权值可发育Itti模型算法在时间上占有明显优势。
5 结 语
为了改善Itti视觉选择性注意模型中存在的特征提取不精确、无自主选择性、耗时较多等缺点,提出一种权值可发育的视觉选择性注意模型。通过训练三层自组织发育网络来对注意模型进行发育学习,有效地降低了模型对不同任务的条件约束性,提高了模型特征提取能力和自主学习能力,改善了Itti模型无自主选择性、耗时多等缺点。
通过仿真实验证明,权值可发育Itti模型较传统Itti模型有着良好的表现,也符合灵长目类视觉感知机能,具有较高的理论研究和实践价值,如何将方法应用到实际的问题中将成为下一步的研究重点。
参考文献
[1] ITTI L, KOCH C, NIEBUR E. A model of saliency?based visual attention for rapid scene analysis [J]. IEEE transactions on pattern analysis & machine intelligence, 1998, 20(11): 1254?1259.
[2] ITTI L, KOCH C. Computational modelling of visual attention [J]. Nature reviews neuroscience, 2001, 2(3): 194?203.
[3] NYAMSUREN E, TAATGEN N A. The synergy of top?down and bottom?up attention in complex task: going beyond saliency models [C]// Proceedings of the 35th Annual Conference of the Cognitive Science Society. Austin: Cognitive Science Society, 201: 3181?3186.
[4] JUDD T, EHINGER K, DURAND F, et al. Learning to predict where humans look [C]// Proceedings of 12th IEEE International Conference on Computer Vision. Kyoto: IEEE, 2009: 2106?2113.
[5] BORJI A. Boosting bottom?up and top?down visual features for saliency estimation [C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 438?445.
[6] ZHAO Q, KOCH C. Learning a saliency map using fixated locations in natural scenes [J]. Journal of vision, 2011, 11(3): 74?76.
[7] 王凤娇,田媚,黄雅平,等.基于眼动数据的分类视觉注意模型[J].计算机科学,2016,43(1):85?88.
WANG Fengjiao, TIAN Mei, HUANG Yaping, et al. Classification model of visual attention based on eye movement data [J]. Computer science, 2016, 43(1): 85?88.
[8] ALM?SSY N, EDELMAN G M, SPORNS O. Behavioral constraints in the development of neuronal properties: a cortical model embedded in a real?world device [J]. Cerebral cortex, 1998, 8(4): 346?361.
[9] BERRIDGE K C. Motivation concepts in behavioral neuroscience [J]. Physiology & behavior, 2004, 81(2): 179?209.
[10] WENG J. Three theorems: brain?like networks logically reason and optimally generalize [C]// Proceedings of International Joint Conference on Neural Networks. San Jose: IEEE, 2011: 2983?2990.
[11] LUCIW M, WENG J. Where?what network 3: developmental top?down attention for multiple foregrounds and complex backgrounds [C]// Proceedings of International Joint Conference on Neural Networks. Barcelona: IEEE, 2010: 1?8.
[12] WENG J, LUCIW M. Brain?like emergent spatial processing [J]. IEEE transactions on autonomous mental development, 2012, 4(2): 161?185.
