英文发音中错误语音自动识别系统设计
2018-05-15王兴刚
王兴刚

摘 要: 传统的英文发音识别系统对于学习者的错误发音不能及时进行反馈与纠正,存在误导学习者以及学习者英文水平提高缓慢的弊端。在此设计新的英文发音错误语音自动识别系统,其由语音录制模块、语音播放模块、英语发音评分模块和发音共振峰图像显示模块构成,给出评分模块的发音评分流程,实现英文发音的有效评分以及评分的存储,系统通过发音共振峰图形显示模块,清晰地表达出学习者发音与标准发音的不同之处,纠正其错误读音。通过英语音素检错程序使用独立阈值的方式来提高错误读音的检测性能,对不同音素用独立阈值进行衡量,使得英语发音中的错误语音自动识别结果更加科学化、精准化。实验结果表明,所设计的系统具有较高的错误语音自动识别能力。
关键词: 英语发音; 错误语音; 自动识别; 发音评分; 发音共振峰图像显示; 独立阈值
中图分类号: TN912.34?34 文献标识码: A 文章编号: 1004?373X(2018)10?0179?04
Abstract: The traditional English pronunciation recognition system fails to timely feed back and correct learners′ mispronunciation, which misleads learners and leads to learners′ slow improvement in English level. Therefore, a new error speech automatic recognition system for English pronunciation is designed. The system is composed of voice recording module, voice playing module, English pronunciation scoring module, and pronunciation formant image display module. The pronunciation scoring process of the scoring module is given to realize the effective scoring of English pronunciation and storage of scores. The pronunciation formant graphic display module is adopted to clearly express the differences between learners′ pronunciations and standard pronunciations, so as to correct their wrong pronunciations. The detection performance of wrong pronunciations is improved by using the independent threshold mode and the English phoneme error detection procedure. Different phonemes are measured with the independent threshold to make the wrong speech automatic recognition results of English pronunciation more scientific and accurate. The experimental results show that the designed system has a high error speech automatic recognition capability.
Keywords: English pronunciation; error speech; automatic recognition; pronunciation scoring; pronunciation formant graphic display; independent threshold
0 引 言
在經济全球化全面发展、我国对外开放进程不断推进的背景下,世界各国沟通往来不断加强,英语作为应用最频繁的语言,发挥了不可替代的作用[1]。在学习英语的过程中,存在学习者口语较差的现象,口语作为英语学习中既关键又困难的部分,日益受到关注。因此,设计科学、高效的英文发音错误语音自动识别系统势在必行。传统的英文发音识别系统对于学习者的错误发音未能及时进行反馈与纠正,存在误导学习者以及学习者英文水平提高缓慢的弊端。针对该问题,本文设计面向英文学习者发音错误及时反馈并纠正的错误语音自动识别系统,为学习者提供了良好的口语学习环境。
1 英文发音中错误语音自动识别系统设计
1.1 系统总体构架
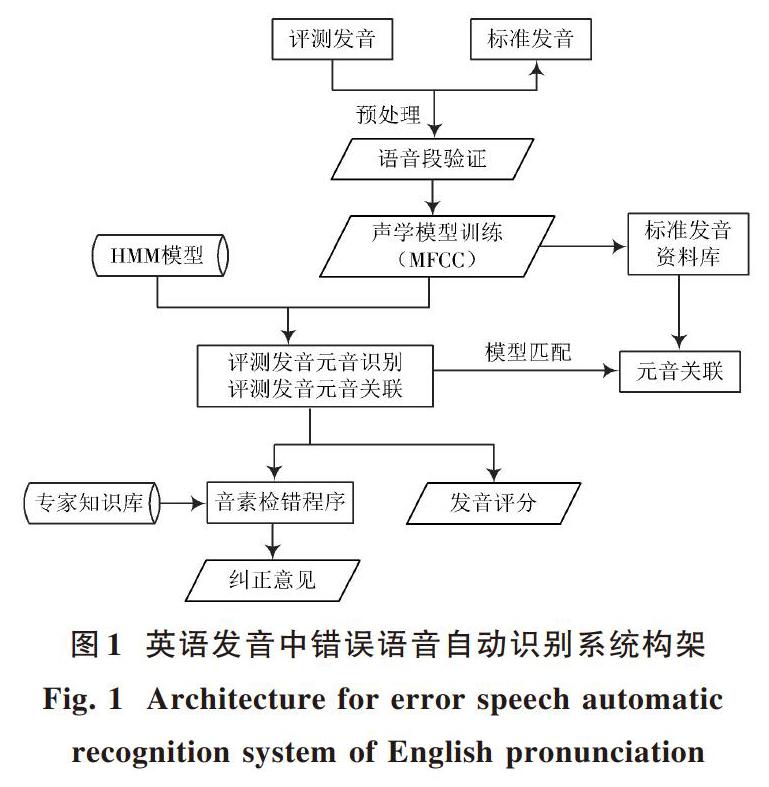
随着国际大环境发展,我国学习英文口语人数大量增长,为学习者们提供一个科学化、系统化语音纠错方式至关重要,各种语音自动识别系统应运而生。图1为本文设计英语发音中错误语音自动识别系统构架图。系统通过分割元音段、建立验证体系以及检测系统是否科学三方面对英语学习者发音实施语音验证;采用HMM模型面向海量正确发音信息实施声学模型训练方式,保证语音段在Viterbi算法运作之下合理的分解,确保英语发音错误语音自动识别系统的发音评测模块能够接收到评比参数的提取、参数关联流程及评测机制等信息。英语音素检错程序是整个系统的关键部分,能衡量英语发音中各参数权值[2],提取出英语发音中的错误音节,向发音者进行反馈,以达到纠正错误并改进,促使英语发音者提高发音水平的目的。
1.2 系统硬件设计
1.2.1 系统的模块组织结构
本文设计的英文发音错误语音自动识别系统组织结构,由语音录制模块、语音播放模块、英语发音评分模块以及发音共振峰图像显示模块构成[3],详细结构如图2所示。该系统重点是基于AP的發音评分模块以及发音共振峰图像显示模块,这两部分是进行错误语音识别的关键性步骤。
1.2.2 英语发音评分模块设计
系统在基于AP的发音评分技术基础上,对英语发音评分模块进行整合,英语发音评分及参数生成构成模块两大核心部分,两者在为英语发音者做出科学评分与评分参数自适应生成方面发挥着不可替代的作用[4]。
系统面向测试发音以及标准发音实施分帧加窗、端点检测等操作,即进行预处理。接着,采取MFCC特征提取以及DTW动态归纳的方式,确保预处理后的英语发音数据得到有效的特征采集以及模式匹配计算[5],获取测试发音及标准发音的帧平均匹配距离。基于不同的目标动机,分为两种情况:
1) 当需要进行参数生成时,经过专家的经验评分,获取帧平均匹配距离以及专家经验评分之间一定的对应关系,获取英语评分的自适应参数x,y,确定评分函数来实施发音评分。
2) 当需要进行发音评分时,测试英语发音以及标准发音的帧平均匹配距离会被输入到评分函数中,最终获取英语发音评分。
准确输出评分参数是发音评分部分及评分参数生成部分连接点[6],参数生成部分的存在,使得获取的参数准确无误地输入到英语发音评分部分。系统采用SharePreferences组件存储评分函数的重点参数,实现参数的永久性保存。
1.2.3 发音共振峰图形显示模块设计
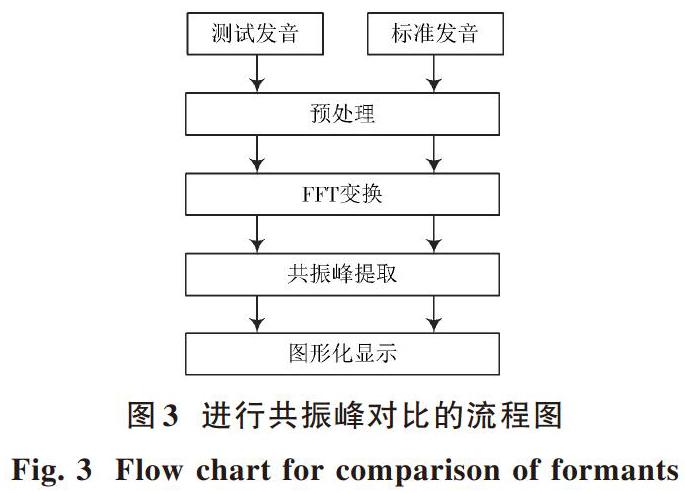
标准英语发音以及学习者发音的共振峰变化形态会以图形化的方式在发音共振峰的图像显示模块中完整地体现出来,清晰地展现出两者的不同之处,识别出学习者在英文发音过程中与正确发音的不同之处[7],纠正错误的英语发音。图3详细描述了共振峰的执行流程。
发音共振峰图形显示模块采用预处理、FFT变换及共振峰提取的方式对英语测试发音及标准发音实施操作[8],获取学习者英语发音与标准发音共振峰信息。通过共振峰将两种结果进行对比,能清晰地表达出学习者英语发音与标准发音的不同之处,纠正其错误读音,为英文口语学习者提供科学、系统、便捷的学习环境。
1.3 系统软件设计
1.3.1 英语音素检错程序构建
在语音识别技术的基础上,系统的英语发音自动检错程序实现了判断不同音素是否符合标准。英语发音自动检错程序的操作主要分为两大步骤:第一,采用依据音素序列归纳学习者语句的方式,获取不同音素相应的发音片段;第二,采用音素发音质量GOP(Goodness of Pronunciation)的方式对得到的发音片段进行衡量[9]。观测语音向量、当前音素以及所有音素集合分别用[O],[P]以及[Q]来描述,音素[P]的声学模型转换成观测语音向量几率用[POP]来描述。GOP具体计算过程见图4。采用对GOP实施[FrameCountO]优化归纳的方式,确保长短不一音素的GOP值相对可比。
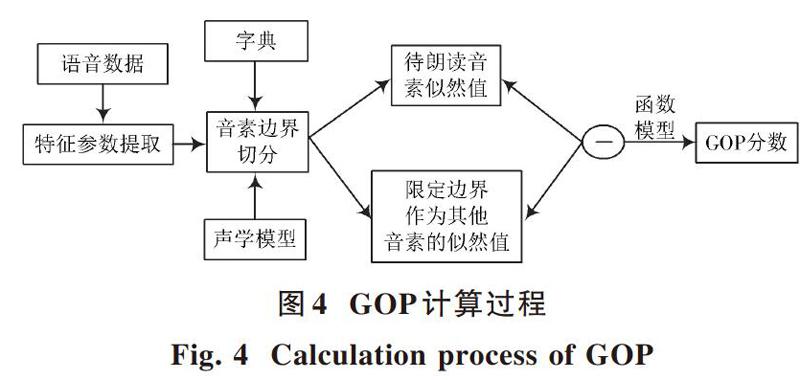
检错识别功能是在本文系统判断音素GOP值是否不超过某个阈值基础上实现的。从标注数据集中可获取到上述阈值。音素检错程序具体构建如下:
1) 声学属性。人耳的听觉属性是依赖于Mel频率倒谱系数MFCC进行体现的,音素检错模块将人耳听觉属性列入声学属性参数,采用MFCC_E_D_A D对详细数据进行设置。
2) 声学模型。本文程序采用的HMM模型在语音识别中应用频率较高,详细表现为MonoPhone,3状态,每状态24高斯。该模型通过合理分析标准英文发音数据集的方式,确保声学模型可以辨别发音是否准确,该数据集具体包含30个人15 h发音信息。
3) 音素分割网络。音素分割网络主要来源于学习者的朗读音频相应的音素序列。
4) 音素辨识表。从理论层面出发,为得到科学精确的GOP值,需要对那些自动切分获取的音素对应片段进行计算[10]。而具体应用中,仅使用频繁出现的竞争子集来确保识别系统的使用效率。
5) 音素竞争子集的选取。详细的例子见表1。下面对采集依据进行分析:声学以及语音学经验、不同音素模型相互距离以及相似度、记录人工标注中频繁混淆的音素对。

1.3.2 使用独立阈值提高错读检测性能
1) 统一阈值与独立阈值。采用统一衡量阈值进行判断,然而分析表明,错误英语发音与标准发音GOP分布图存在明显差异。为实现英语音素检错程序科学化、精准化,对不同音素限定特有阈值。

2 实验分析
2.1 語音录入测试
实验对本文系统的语音录入性能实施测试,检测系统对用户进行发音跟读过程中,是否可将发音正确录入。实验采用的数据是:元音18个、辅音22、单词10个。将首次发音当成发音测试结果。测试成功率=成功[用例数总测试用例数]。测试用例与测试结果见表2、表3。
测试结果表明,本文系统能够正确录入元音以及单词,受到局部辅音发音时间短以及音量低的干扰,有5.5%的辅音没有正确录入,总体上得出本文系统的成功录入率较高。

2.2 反馈纠正测试
实验对本文系统的反馈纠正性能进行测试,通过比较发音共振峰图像的方式来验证是否可以科学、精确地实施语音识别纠错功能。实验数据是:元音发音18个、单词发音10个(共振峰未显示辅音发音状况)。通过共振峰图像改进发音状况,能够确保提高发音评分,这种情况下,反馈纠正性能属于有效,相反就是效果微弱甚至无效。有效率=[有效数总发音个数。]测试用例与测试结果用表4、表5所示。
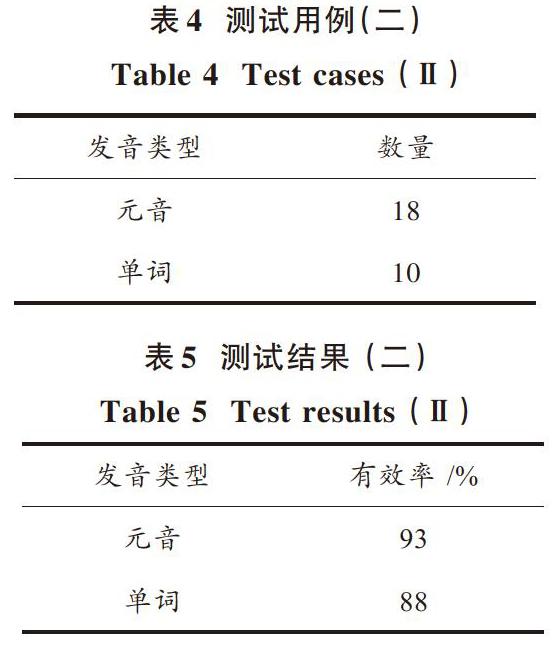
测试结果表明,本文系统采取共振峰对比的措施,确保发音自动识别的纠正平均有效率在90.5%左右,对于学习者的英文发音练习起到很大作用。
3 结 论
本文设计的英文发音错误语音自动识别系统对于学习者的错误发音能够及时进行反馈与纠正,解决了学习者发音水平提高缓慢的问题,为英文学习者提供一个良好的学习环境。
参考文献
[1] 张庆芳,赵鹤鸣,龚呈卉.基于因子分析和特征映射的耳语说话人识别[J].数据采集与处理,2016,31(2):362?369.
ZHANG Qingfang, ZHAO Heming, GONG Chenghui. Whispered speaker identification based on factor analysis and feature mapping [J]. Journal of data acquisition & processing, 2016, 31(2): 362?369.
[2] YOUNG S C, WANG Y H. The game embedded CALL system to facilitate English vocabulary acquisition and pronunciation [J]. Journal of educational technology & society, 2014, 17(3): 239?251.
[3] 张圣,郭武.采用通用语音属性建模的说话人确认[J].小型微型计算机系统,2016,37(11):2577?2581.
ZHANG Sheng, GUO Wu. Speaker verification based on universal speech attributes [J]. Journal of Chinese computer systems, 2016, 37(11): 2577?2581.
[4] 晁浩,宋成,刘志中.语音识别中基于发音特征的声调集成算法[J].计算机工程与应用,2014,50(23):21?25.
CHAO Hao, SONG Cheng, LIU Zhizhong. Integrating tone models into speech recognition system based on articulatory feature [J]. Computer engineering and applications, 2014, 50(23): 21?25.
[5] 张少白,陈燕俐,何利文.基于DIVA模型的中文复合元音发音方法研究[J].系统仿真学报,2017,29(2):255?263.
ZHANG Shaobai, CHEN Yanli, HE Liwen. Research of Chinese diphthongs pronunciation based on DIVA model [J]. Journal of system simulation, 2017, 29(2): 255?263.
[6] 唐郅,侯进.基于深度神经网络的语音驱动发音器官的运动合成[J].自动化学报,2016,42(6):923?930.
TANG Zhi, HOU Jin. Speech?driven articulator motion synthesis with deep neural networks [J]. Acta automatica sinica, 2016, 42(6): 923?930.
[7] 岳源,张清芳.汉语口语产生中音节和音段的促进和抑制效应[J].心理学报,2015,47(3):319?328.
YUE Yuan, ZHANG Qingfang. Syllable and segments effects in mandarin Chinese spoken word production [J]. Acta psychologica sinica, 2015, 47(3): 319?328.
[8] 黄浩,徐海华,王羡慧,等.自动发音错误检测中基于最大化F1值准则的区分性特征补偿训练算法[J].电子学报,2015,43(7):1294?1299.
HUANG Hao, XU Haihua, WANG Xianhui, et al. Maximum F1?score criterion based discriminative feature compensation training algorithm for automatic mispronunciation detection [J]. Acta electronica sinica, 2015, 43(7): 1294?1299.
[9] WANG X, YAMAMOTO S. Speech recognition of English by Japanese using lexicon represented by multiple reduced phoneme sets [J]. IEICE transactions on information & systems, 2015, 98(12): 2271?2279.
[10] 杜先娜,俞一彪.有效频带多分辨率特征提取及说话人年龄识别[J].信号处理,2016,32(9):1101?1107.
DU Xianna, YU Yibiao. Multi?resolution feature extraction of effective frequency bands for age recognition [J]. Journal of signal processing, 2016, 32(9): 1101?1107.
