公共舆论和选择性螺旋
——中国网络新闻中的美国观
2018-05-15季佳颖钱晓杭
季佳颖, 钱晓杭
随着网络时代2.0的发展,互联网变成一个交互式的媒体平台,为传播学研究者们提供了很多从行为或心理层面上研究用户使用习惯的机会。仅仅通过点击动作,人们便可以获得以各种形式呈现的信息。本文所使用的数据来自2015年3月至2016年11月的“今日头条”新闻数据库,包括点击量、转发量、新闻标题长度、新闻图片数目等变量。本文使用内容分析的研究方法,分析中美新闻标题,旨在探究从中国互联网新闻中所显示出的美国观。传统内容分析和机器学习技术相结合的内容分析是本研究方法上的亮点。这种研究方法不仅帮助研究人员获得数量庞大的研究样本,还可以减轻劳动力成本,降低人工编码的误差率。本研究主要采用SPSS软件进行线性回归和调节回归的定量研究方法,将“对于美国而言的媒体导向”作为调节变量,观察它如何影响“对于中国而言的媒体导向”和“点击量/转发量”之间的关系。之后对比两个调节回归的趋势,运用理论来解释可能的潜在原因及其影响。
一、 文献综述
(一) 中美关系及公共舆论
中美两国的国际关系是国际上最为重要的双边关系之一,两大经济体的关系不仅涉及经济利益,还涉及政治、国家安全、文化影响等众多因素。
而公共舆论在中美双边关系中起着至关重要的作用,因为它不仅在政府间和公众层面影响着双方的协调合作,同时还影响到国家的决策和方针(Tan,2011)。皮尤全球态度项目(Pew Global Attitudes Project)对64个国家的45万多名受访者进行调查,为用户提供有关各种话题的主要态度趋势。数据表示中国的国家形象能够部分地被对中国的公共舆论所衡量。同样地,美国的国家形象也能够部分地被对美国的公共舆论所衡量。从图1可看出,两国的偏好率在40%~50%浮动。从2005—2016年,美国对中国的公共舆论的平均偏好率是42.75%,略低于同期中国对美国的公共舆论的平均偏好率45.8%(Pew Research Center,2016)。

图1 中美两国公共舆论偏好率
在2016年皮尤研究中心(Pew Research Center)春季的“皮尤全球态度调查”中约有50%的受访者选择了偏好中国的选项,有52%的受访者认为美国在阻止中国变得更加强大,而只有29%的受访者认为美国愿意接受中国的崛起。中心自2017年2—3月的调查显示,美国对中国的偏好率在2016年为37%;而到2017年春季有所改善,上升至44%。报告指出上升可能是由于中国经济威胁日益减少。目前,两国的年轻人更愿意对彼此国家持有偏好的态度。中国年轻人持有对美国的偏好率比老年人高,美国民众对中国的偏好率上也有相似的年龄层的差距。18~29岁的民众中,对中国持有偏好的占51%;而30~49岁的民众中对中国持有偏好的占47%;50岁以上的民众中,只有36%的民众选择对中国持有偏好的选项。
(二) 选择性螺旋
在信息传播的过程中,社交媒体逐渐代替印刷媒体和大众媒体,成为信息传播的主要平台之一。社交媒体为用户参与信息交互创造了新的途径,因为移动应用程序能提供相关的用户行为的数据,例如点击、投票、转发、评论等。这一现象吸引了许多学者对信息传播的路径进行探究(Zhang et al.,2014)。
选择性螺旋可以被认为是沉默螺旋理论、犬儒主义理论、强化理论等的拓展。第一轮的传播是指“发布→阅读→转发”的“三重奏”。在第一轮传播之后,其他的传播螺旋会在转发后通过再次阅读以及转发的形式被激发。因此,“选择性螺旋”一词被用来指引整个信息传播的循环和演化过程。此外,尽管整个过程,无论是否容易被测量,都会因为受到许多因素的影响而变得复杂,但可以确定的是整个传播过程都带有选择性。在社会科学和传播学领域中,许多理论可以作为选择性螺旋的例证,例如:创新扩散理论、知识鸿沟理论、沉默的螺旋理论、犬儒主义理论等①。选择性螺旋使用元理论的研究方法,选择了一组经典和现代的传播学理论来描述网络新闻环境中的新现象,产生全新理论框架,进一步填补学术和理论的不足。
(三) 计算机辅助的内容分析
随着先进技术的高速发展,数据变得更容易追踪和存储,大数据是通过不同方式收集的大量数据,这为社会科学计算机辅助研究方法进步创造了新的机会(Lazer et al.,2009)。在传播学研究领域,许多反映受众行为心理的数据可通过社交媒体应用提供的推文、状态、推荐等获得(Lewis et al.,2013)。以“今日头条”为例,阅读量可以反映新闻的吸引力和观众的注意力,转发量可以显示人们传播新闻的意愿和新闻的影响力,而整个过程可以展示新闻传播和舆论循环。
在传播学领域,计算机辅助内容分析方法的应用能生产更可靠和高质量的研究,吸引了很多学者将其与传统的内容分析相结合,将两者相结合的方法是基于不同软件算法和人工监督的机器学习过程(Su et al.,2017)。借助大数据或智能算法能让内容分析更加先进:第一,在样本和总体方面,机器辅助方法可以显著提高p值,因为计算机辅助方法可以获得更大的样本数据量,甚至可以获得总体的数据。第二,基于计算机的内容分析能避免人工操作中不可避免的弊端,因此可以降低错误率,提高产量和可信度(Krippendorff,2012)。第三,人工操作内容分析的明显缺点是时间和劳动力成本相较于机器辅助过高,特别是对于大量数据,在这个烦琐的工作过程中,标识人员长时间集中精力地工作会让标识过程更容易出错。因此大规模的人工标识是不可行的(Hopkins & King,2010),而计算机程序可以以惊人的速度分析大数据(Conway,2006)。因此,计算机辅助的内容分析可以促进纯粹的人力工作效率,降低错误率,提高可靠性、效率和标识员间的可信度。
另外,这种方法也有缺点。人类标识员在面对复杂潜在的表达或解释信息背景时,能更加专业地处理一些含有深刻意义的分析(Krippendorff,2012)。一些学者认为对于潜在和隐藏的内容,人类标识员显得更可靠和不可替代(Sjøvaag & Stavelin,2012)。此外,句子的一些表达方法如隐喻、讽刺,对计算机方法来说也是个难点。随着社交媒体的大规模转移,大量的新词或者网络词汇出现,对这项技术构成挑战。还有一点是,虽然方言的词汇和短语在新闻中并不频繁,但也处于计算机方法的不可及范围。而传统内容的分析单位是指长篇文章,如新闻文章评论等,研究人员会较容易深入分析其框架或语气(Lewis et al.,2013)。
目前计算机辅助内容分析技术的发展,首先要提到的是字典方法(Krippendorff,2012),基于字典的计算可以由几个软件程序实现,如TaxtPack、VBPro和WordStat;另一种方法称为统计关联方法,用于常语义分析、框架文本分析等(Krippendorff,2012)。区别于理论驱动的字典方法,这种方法因为没有预先设定好的类别而更倾向于数据驱动,它确保分析更加客观(Simon & Xenos,2004),也更通用、更精确,并能排除潜在的人工操作的弊端。
二、 研究问题和假设检验
为了探究中国媒体平台受众的公共舆论与选择性螺旋,此项研究提出了2条假设检验和4个研究问题。
第一,数据的描述性信息将会给出此项研究中因变量(对于中国而言的媒体导向)、自变量(阅读量、转发量)、调节变量(对于美国而言的媒体导向)基本信息。在本研究中,“对中国而言的媒体导向”是指涉及中美两国新闻的舆论导向对中国而言是正面、负面或是中性;同样地,“对美国而言的媒体导向”是指涉及中美两国新闻的舆论导向对美国而言是正面、负面或是中性。举例来看:2016年6月6日的一篇媒体报道题为《1死15伤!中国旅游团在美国发生重大车祸详情》。该标题运用了感叹号,强调了此次车祸的死伤人数,同时 “重大”这一形容词也被用来强调此次车祸的严重性,因而这篇报道不管对美国还是中国而言都是一个负面事件,并且媒体刻意强调了这一事件的负面性。因而,在标识过程中,此篇报道“对于中国而言的媒体导向”会被标识成负面,“对于美国而言的媒体导向”也会被标识成负面。
同时,描述信息也会佐证选择性螺旋所提出的信息从发布伊始到被阅读再至被转发(发布→阅读→转发)的螺旋。例如,新闻的阅读量能够显示第一轮转发阅读的结果,阅读量和转发量的百分比(阅读量/转发量)能反映第二轮阅读到转发的结果。所以第一个研究问题将会解决数据的整体性描述。
研究问题1: 关于“对于中国而言的媒体导向”“对于美国而言的媒体导向”“阅读量”“转发量”这四个研究变量的整体性描述是什么?
第二,为了探究“对于中国而言的媒体导向”与“阅读量”“转发量”之间的关系,此项研究提出两条假设检验。
假设检验1: “对于中国而言的媒体导向”与“阅读量”之间呈现正向相关。(TC&RD)
假设检验2: “对于中国而言的媒体导向”与“转发量”之间呈现正向相关。(TC&RL)
第三,之前并未有研究着眼于新闻标题所反映出来的对中美之间的舆论导向,此项研究将针对这一点提出研究问题:
研究问题2: 假设检验1中提出的两个变量之间的关系会如何被“对于美国而言的媒体导向”所调节?(TC&RD/TA)
研究问题3: 假设检验2中提出的两个变量之间的关系会如何被“对于美国而言的媒体导向”所调节?(TC&RL/TA)
第四,为了检验选择性螺旋理论,此项研究将提出研究问题4对研究问题2和研究问题3进行比较分析。
研究问题4: 研究问题2和研究问题3之间存在何种异同?
三、 数据和研究方法
(一) 数据来源
此项研究来源于“今日头条”手机应用。“今日头条”应用人工智能技术,通过一系列算法模型,能够基于用户的使用习惯为用户精准推荐相关新闻。人工智能推荐技术、自媒体平台理念让“今日头条”在中国拥有很大的用户群体。该应用在2012年8月正式发布,到2017年1月用户数已达7亿,其中月活跃用户达1.75亿。本研究的数据来源于“今日头条”2015年3月至2016年11月的全部新闻,包括阅读量、转发量、新闻标题等。经过筛选关键词“美”和“美国”,本次研究共筛选出47266万条美国相关新闻以进行相关问题研究和假设检验。
(二) 内容分析和标识
内容分析和标识过程共历时三个月,由6名标识员共同完成。此项研究基于47266万条新闻,其中10000条新闻由标识员共同标识处理,剩余37266条数据由程序员基于标识结果结合机器学习进行处理。为了在标识员之间形成高信度,6个标识员之间协同合作,参考大量文献作为理论指导,在经过前期一系列的训练后,讨论形成了严格的标识本。此过程旨在从“正面”“中性”“负面”三个维度标识 “对于中国而言的媒体导向”和“对于美国而言的媒体导向”这两个变量。在这里还需要说明的是,这两个变量在标识过程中是从国家层面,判断特定的新闻报道对于这个国家(美国或中国)而言是正面报道、负面报道还是中性报道。再经过6轮标识训练后,6名标识员两两组合标识10000条新闻,标识员之间形成了极高的可信度(见表1)。

表1 标识员之间信度
在标识过程中,基于手机短新闻交互设计的考虑,标识员基于新闻标题而非新闻摘要与正文进行标识。与传统纸媒以及网页新闻不同的是,手机端新闻并不能将新闻标题、新闻摘要或者新闻正文在同一界面同时呈现。出于用户快速浏览阅读习惯的考虑,手机端新闻往往仅呈现新闻标题。用户在大致浏览新闻标题,快速定位到感兴趣的新闻后,再选择点击该新闻进一步的阅读。
(三) 机器学习
作为一个跨学科多合作的研究项目,在内容分析中提及的机器学习部分交由程序员完成。程序员基于6名标识员标识产生的10000条数据进行机器学习,历时一个月,共机器学习37266条数据。截止到2017年4月,此项研究所基于的47266条数据完整生成。
(四) 调节模型和回归分析
针对4条研究问题和2条假设检验,从“今日头条”上抓去的两个变量——“阅读量”和“点击量”,以及通过内容分析和标识过程生成的两个变量——“对于中国而言的媒体导向”和“对于美国而言的媒体导向”,将分别作为此项研究的自变量、因变量以及调节变量。
自变量: “对于中国而言的媒体导向”。与调节变量一样,自变量也是经由机器辅助标识产生,分别用1、2、3标识负面报道、中性报道、正面报道。在接下来的分析过程中,将由“Tc”表示这个变量。
因变量: 阅读量和转发量。这两个变量直接由程序员从“今日头条”手机应用程序实时抓取。为了表述方便,阅读量和转发量将分别由“RD”和“RL”表式。
调节变量: “对于美国而言的媒体导向”。这个连续变量由机器辅助标识产生,分别用1、2、3标识负面报道、中性报道、正面报道。在接下来的分析过程中,将由“TA”表示这个变量。
整个数据处理和分析过程将借助SPSS完成。除了描述性数据外,本次研究数据分析会集中在线性回归分析和调节模型建立。线性回归旨在探究自变量“对于中国而言的媒体导向”(TC)分别与两个因变量“阅读量”(RD)和“转发量”(RL)之间存在的关系。建立调节模型旨在探究“对于美国而言的媒体导向”这个调节变量会对线性回归所发现的变量之间的关系产生何种影响。
四、 结果
(一) 数据描述
从表3可见,此次数据分析共基于大约4.7万条数据,最高阅读量为600万,最高转发量为4万。4.7万条新闻的平均阅读量可达82950次,平均转发量可达449次。也就是说,每篇新闻平均而言可获得大约8.3万次的阅读和450次的转发,平均每一千次阅读可产生5.412次的转发(表2)。从表3还可看出,阅读量和转发量的平均值都高于其中位数。这就说明,阅读量和转发量的总体分布情况并非呈现正态分布,而是向数值低的方向倾斜。

表2 数据描述

表3 阅读量(RD)、转发量(RL)、对于中国而言的媒体导向(TC)、对于美国而言的媒体导向(TA)
(二) 线性回归验证假设检验1(TC&RD)
线性回归的结果呈现在表4中。从以上表格可以看出,预测变量TC(对于中国而言的媒体导向)可以解释阅读量0.3%的变化(调整R方=0.003,F(1,47263)=143.158,p<0.001)。TC的非标准化系数是一个正值(b=35172.157,p<0.001)。因此,由对于中国而言的媒体导向(TC)来预测阅读量的表达式为:RD=8827.34+35172.157TC。

表4 线性回归
(三) 线性回归验证假设检验2(TC&RL)
线性回归的结果呈现在表5中。从以上三张表格可以看出,预测变量TC(对于中国而言的媒体导向)可以解释转发量0.3%的变化(调整R方=0.004,F(1,47263)=176.270,p<0.001)。TC的非标准化系数是一个正值(b=214.054,p<0.001)。因此,由对于中国而言的媒体导向(TC)来预测阅读量的表达式为:RL=-1.886+214.054TC。
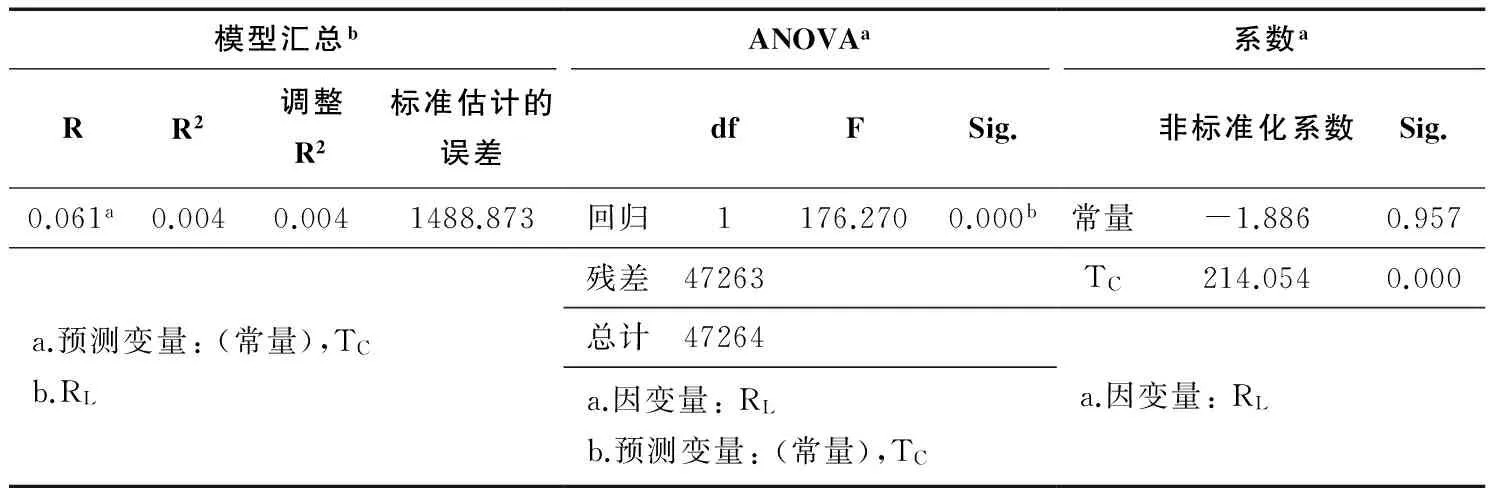
表5 线性回归
(四) 调节模型
为了建立调节模型,在本次分析中,基于原有变量,又重新生成另外4个新变量分别是: D1、D2、TC×D1和TC×D2。首先,D1和D2这两个变量是基于“对于美国而言的媒体导向(TA)”这个变量。D1是指对于美国而言的媒体导向为负面。也就是说,如果对于美国而言的媒体导向为负面(TA=1),那么D1=1;反之,如果对于美国而言的媒体导向为正面或中性(TA=2或TA=3),那么D1=0。同样地,D2这个变量也是如此生成。D2是指对于美国而言的媒体导向为正面。也就是说,如果对于美国而言的媒体导向为正面(TA=3),那么D2=1;反之,如果对于美国而言的媒体导向为负面或中性(TA=1或TA=2),那么D2=0。TC×D1和TC×D2这两个变量是由“对于中国而言的媒体导向(TC)” 分别与D1和D2相乘而得。
研究问题2(TC&RD/TA):
整个调节模型建立为: RD=a1+b1TC+b2D1+b3D2+b4TCD1+b5TCD2
多元线性回归的结果呈现在表6中。从上表可看出,TC、D1、D2、TC×D1、TC×D2这5个变量解释了阅读量中0.7%的变化(调整R方=0.007,F(5,47259)=64.011,p<0.001)。TC的非标准化系数是正值(b=44043.025,p<0.001),D1的非标准化系数是正值(b=87089.817,p<0.001),D2的非标准化系数是正值(b=100327.335,p<0.001),而TC×D1的非标准化系数是负值(b=-23299.661,p<0.001),TC×D2的非标准化系数是负值(b=-53082.205,p<0.001)。因而,我们可得出a1=-15811.838,b1=44043.025,b2=87089.817, b3=100327.335,b4=-23299.661,b5=-53082.205;
调节模型为:RD=a1+b1TC+b2D1+b3D2+b4TCD1+b5TCD2,也就是: RD=-15811.838+44043.025TC+87089.817D1+100327.335D2-23299.661TCD1-53082.205TCD2;
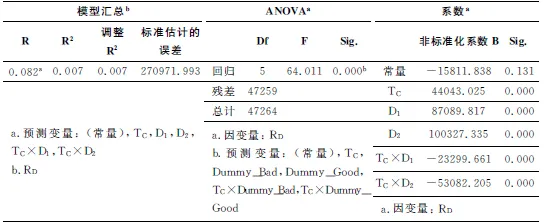
表6 调节建模(TC&RD/TA)
如果对于美国而言的媒体导向为正面,即D1=0,D2=1,那么RD=(b1+b5)TC+(a1+b3),即RD=-9039 TC+84516;
如果对于美国而言的媒体导向为中性,即D1=0,D2=0,那么RD=b1TC+a1,即RD=44043 TC-15811;
如果对于美国而言的媒体导向为负面,即D1=1,D2=0,那么RD=(b1+b4)TC+(a1+b2),即RD=20744 TC+71278。
结果呈现如图2。

图2 调节模型可视化(TC&RD/TA)
研究问题3(TC&RL/TA):
整个调节模型建立为: RL=a2+b6TC+b7D1+b8D2+b9TCD1+b10TCD2
多元线性回归的结果呈现在表7中。从上表可看出,TC、D1、D2、TC×D1、TC×D2这5个变量解释了阅读量中0.8%的变化(调整R方=0.007,F(5,47259)=75.739,p<0.001)。TC的非标准化系数是正值(b=276.553,p<0.001),D1的非标准化系数是正值(b=533.762,p<0.001),D2的非标准化系数是正值(b=650.339,p<0.001),而TC×D1的非标准化系数是负值(b=-148.960,p<0.001),TC×D2的非标准化系数是负值(b=-339.445,p<0.001)。因而,我们可得出a2=-167.947, b6=276.553, b7=533.762, b8=650.339, b9=-148.960, b10=-339.445;
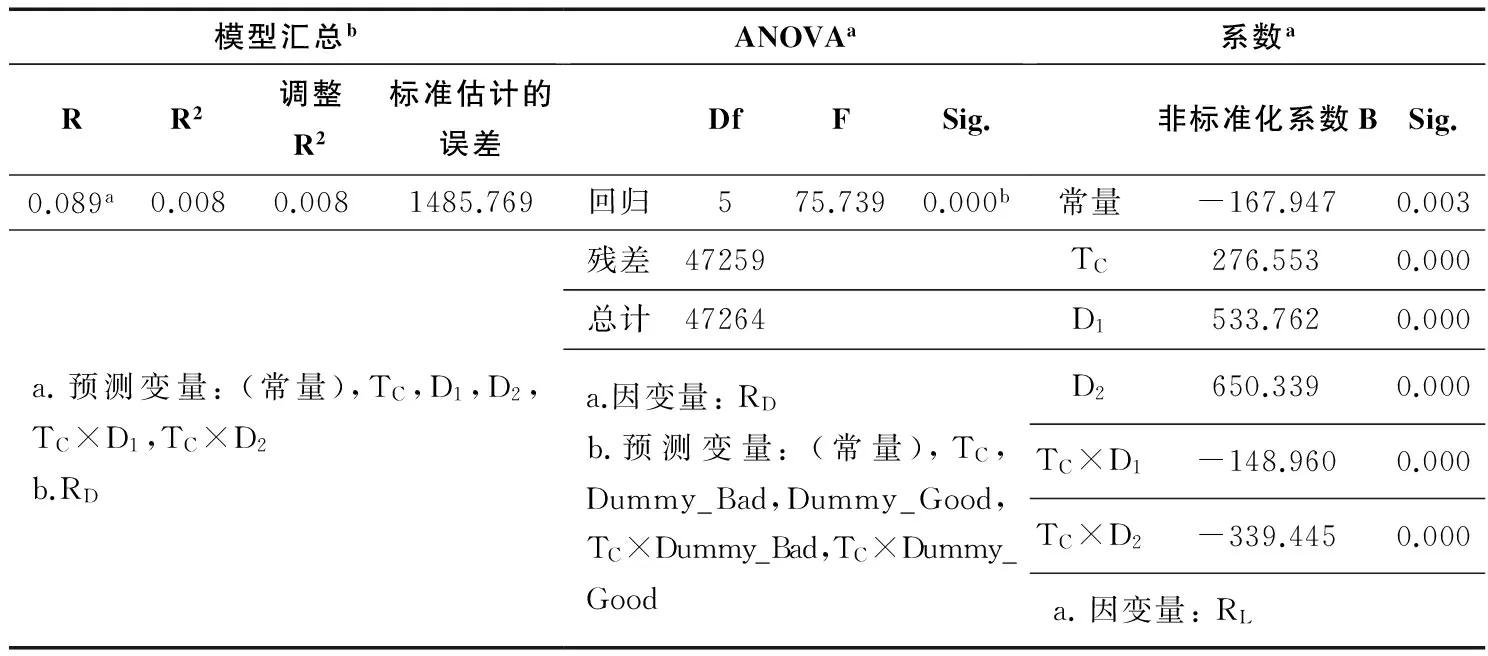
表7 调节建模(TC&RL/TA)
我们的调节模型为: RL=a2+b6TC+b7D1+b8D2+b9TCD1+b10TCD2,也就是:RL=-167.947+276.553TC+533.762D1+650.339D2-148.960TCD1-339.445 TCD2;
如果对于美国而言的媒体导向为正面,即D1=0,D2=1,那么RL=(b6+b10)TC+(a2+b8),即RL=-63 TC+484;
如果对于美国而言的媒体导向为中性,即D1=0,D2=0,那么RL=b6TC+a2,即RL=276 TC-167;
如果对于美国而言的媒体导向为负面,即D1=1,D2=0, 那么RL=(b6+b9)TC+(a2+b7),即RL=128TC+336。
结果呈现如图3。
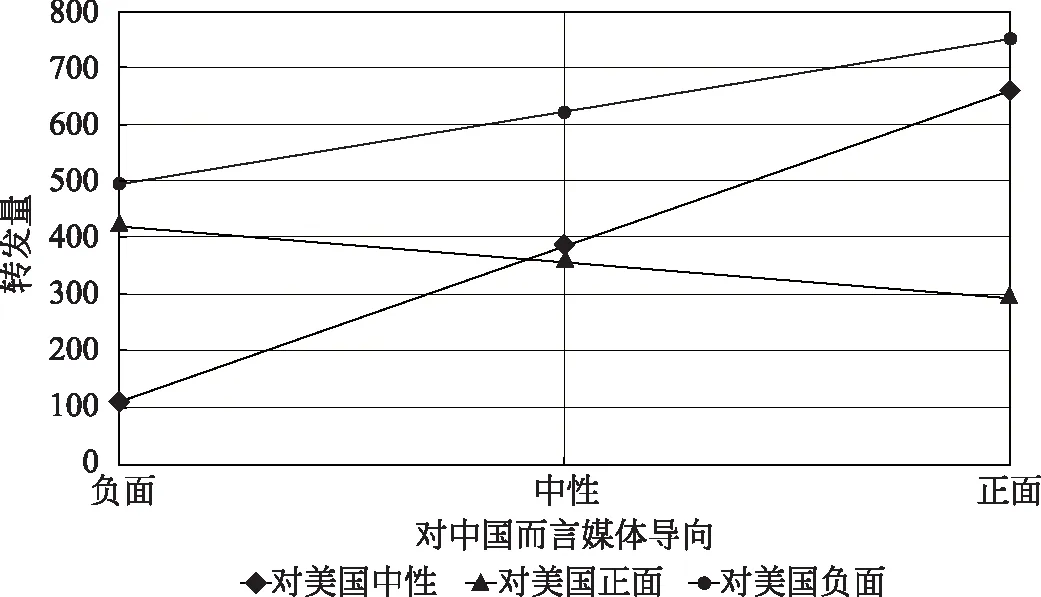
图3 调节模型可视化(TC&RL/TA)
五、 讨论和总结
从数据描述,我们有以下几点发现: (1)每1000个阅读量才能带来5次转发。(2)TC(对中国而言的媒体导向)和TA(对美国而言的媒体导向)这两个变量的均值分别为2.11和1.91。第一条发现证明了尽管在阅读和转发之间只差了一个点击的行为,实际却差距很大。这一个小小的点击行为的发生需要新闻能引起读者更多的兴趣和关注,同时也给了新闻内容创作更多的压力来刺激读者进一步支持某类特定的新闻,对此产生更大的兴趣,从而最终愿意去转发该新闻。此外,从第二条发现可以看出对中国和美国而言的媒体导向十分接近,并都趋于中性。
从两次线性回归分析的结果可以看出,阅读量(RD)和转发量(RL)都与对中国而言的媒体导向(TC)呈现正性相关。这也就是说,如果新闻报道对中国越正面,就会产生更多的阅读量和点击量,这也意味着中国读者更喜欢阅读和转发对中国正面的报道。
两次调节模型的建立均以对美国而言的媒体导向(TA)为调节变量。第一次模型建立以阅读量(RD)为因变量,结果呈现在图2中。首先,图2中的两条上升直线分别是媒体导向对美国呈现中性和负面的报道,阅读量和对中国的媒体导向依旧呈现正性相关关系,也就是说,中国读者更喜欢阅读对美国负面的报道。这种现象可能部分地由民族主义的概念来解释,民族主义是意识形态层面对自己国家多元的共同认同,它认为,国家应该保护自己免受外界的干扰和攻击,这个概念与文化、宗教和政治等有相似之处(Triandafyllidou,1998)。中国和美国不仅是战略伙伴,也是潜在的对手,在某种程度上,这两个国家之间存在不同的国家利益、意识形态和国家制度,这可能是导致这一现象的潜在原因。
近十年来,随着中国的崛起,中国的民族主义一直被广泛讨论。自20世纪90年代初以来,“崛起的民族主义”已经成为中国海上强制性外交一个明显的因素。然而,Alastair Iain Johnston分析了1998—2015年的调查数据,并得出这个因素是不准确的。其他因素如组织兴趣、意见领袖均会影响其外交(Johnston,2017)。另外,Aeron L.Raach比较和界定了美国与中国之间的民族主义。他声称中国民族主义的特点是不干涉别国的内政,对霸权毫无兴趣,而美国民族主义则以“普遍”价值观为特征,寻求单极化世界(Roach,2016)。
第二,从下降的直线我们可以看出当对美国而言的媒体导向(TA)为正时,对中国而言的媒体导向(TC)和阅读量(RD)之间存在负相关关系。这意味着当对美国的新闻报道偏向正面的时候,对中国的报道越负面,阅读量反而会越高。这种现象可能是因为人们更多地关注冲突新闻。现在有关政治新闻讨论存在两大相关主题: (1)负面新闻框架,(2)与政治冲突和角逐相关的战略新闻报道。这两大主题中,人们往往对消极的战略新闻架构感兴趣。此外,在该作者的研究中,受访者更倾向于选择政治冲突和角逐相关的战略新闻或故事(Trussler & Soroka,2013)。Jamieson和Capella认为,对于战略新闻报道,观众更倾向于认为导致新闻事件发生的深层原因是争夺权利,而非为了共同利益。Shanto Lyengar和Helmut Norpoth在研究中发现在选举新闻中,读者也更倾向于带有冲突和角逐的新闻(Hahn & Iyengar, 2002)。就像选举新闻一样,当涉及两国的报道时,读者也更喜欢阅读存在冲突和角逐的新闻报道。
再来看第二次模型建立。第二次模型建立以转发量(RL)为因变量,结果呈现在图3中。我们可以发现,第二次模型建立呈现的结果与第一次极为相似,同样是两条上升直线,一条下降直线。选择性螺旋理论给出了一个合理的推论。由于转发这一行为,这些被选择被转发的新闻又可以产生下一轮的新闻传播引起下一轮的再阅读。这一过程对冲突性新闻(即中美媒体导向相反的新闻)至关重要。这会导致,一些新闻会被传播至更多读者而获得更多阅读量。选择性螺旋给出了这一现象的运行机制和内在原因,关于这些选择性新闻的进一步传播背后的深层次原因可见反射理论。在社会科学领域,低层级的反射在很大程度上是由社会塑造的,而高层级的反射与社会流动性、既定规范、政治等因素有关。社会反射使人们能够进行自我调查和调整,这是现实生活的重要特征(Flanagan,1981)。一些选择性新闻/信息会进一步传播,对个人的想法或心态产生深远的影响。这个进程不可避免地会涉及个人的社会反思,最终形成一个更负面/积极的社会舆论。
六、 反思和局限
首先,“今日头条”手机应用程序仅针对中国新闻观众,不能说明美国对华的舆论,因而无法进行国际双边关系的比较分析。所以未来的研究可引进有关美国对中国舆论的其他一些研究材料和调查作为补充。
其次,阅读量和转发量被用作定量研究方法的因变量。然而,数字背后的根本原因,如更深层的行为和社会心理原因,是模糊和不确定的。政治学、心理学和社会学等其他学科理论亟待引入。此外,未来可对这些深层原因进行定性研究以作为进一步的研究。
第三,由于无法编码的运行规则和机制,应用计算机辅助内容分析的方法可能会导致一些技术缺陷。
第四,重大事件会对政策进程和决策过程产生很大影响(Underdal,1979)。此项研究时间是从2015年3月到2016年11月。在这个时期,不乏涉及两个国家的国家利益的重要国际事件,如2016年9月23日中国国家主席习近平会见美国总统奥巴马。具体事件会对两国舆论产生不同影响,而此项研究着眼于整个舆论,并未着眼于具体事件。
第五,基于大数据分析的方法虽然可以得到所有新闻的总体信息,但没有任何细分。因此,此项研究不可能通过性别、年龄、教育和就业等不同属性进一步分析可能潜在的意见。
注释
① 2016年赵心树教授于莱斯特大学举办的国际媒介与传播研究学会(IAMCR)上提出“选择性螺旋”概念。
参考文献
Flanagan, O.J.J. (1981). Psychology, progress, and the problem of reflexivity: A study in the epistemological foundations of psychology.JournaloftheHistoryoftheBehavioralSciences, 17(3), 375-386. doi: 10.1002/1520-6696(198107)17:3〈375::AID-JHBS2300170308〉3.0.CO;2-U
Hahn, K. & Iyengar, S. (2002). Consumer demand for election news: The horserace sells. InAnnualMeetingoftheAmericanPoliticalScienceAssociation. Boston: American Political Science Association.
Hopkins, D.J. & King, G. (2010). A method of automated nonparametric content analysis for social science.AmericanJournalofPoliticalScience, 54(1), 229-247. doi: 10.1111/j.1540-5907.2009.00428.x
Johnston, A.I. (2017). Is Chinese nationalism rising?Evidence from Beijing.InternationalSecurity, 41(3), 7-43. doi: 10.1162/ISEC_a_00265
Krippendorff, K. (2012).Contentanalysis:anintroductiontoitsmethodology(3rd Ed.). Thousand Oaks, CA: Sage.
Lazer, D., Pentland, A., Adamic, L., Aral, S., Barabási, A.L., Brewer, D., Christakis, N., Contractor, N., Fowler, J., Gutmann, M., Jebara, T., King, G., Macy, M., Roy, D. & Van Alstyne, M. (2009). Computational social science.Science,323(5915), 721-723. doi: 10.1126/science.1167742
Lewis, S.C., Zamith, R. & Hermida, A. (2013). Content analysis in an era of BigData: A hybrid approach to computational and manual methods.JournalofBroadcasting&ElectronicMedia, 57(1), 34-52. doi: 10.1080/08838151.2012.761702
Pew Research Center (2016). Global Indicator Database. Retrieved from http://www.pewglobal.org/database/indicator/1/country/45/
Roach, A.L. (2016). Spectrums of nationalism: A comparison of American and Chinese nationalism.Inquiries, 8(9), 1.
Simon, A.F. & Xenos, M. (2004). Dimensional reduction of world-frequency data as a substitute for intersubjective content analysis.PoliticalAnalysis, 12(1), 63-75. doi: 10.1093/pan/mph004
Sjøvaag, H. & Stavelin, E. (2012). Web media and the quantitative content analysis: Methodological challenges in measuring online news content.Convergence:TheInternationalJournalofResearchintoNewMediaTechnologies, 18(2), 215-229. doi: 10.1177/1354856511429641
Su, L.Y., Cacciatore, M.A., Liang, X., Brossard, D., Scheufele, D.A. & Xenos, M.A. (2017). Analyzing public sentiments online: Combining human- and computer-based content analysis.Information,Communication&Society, 20(3), 406-427. doi: 10.1080/1369118X.2016.1182197
Tan, Q.S. (2011). The change of public opinion on US-China relations.AsianPerspective, 35(2), 211-237.
Triandafyllidou, A. (1998). National identity and the “other”.EthnicandRacialStudies, 21(4), 593-612. doi: 10.1080/014198798329784
Trussler, M. &Soroka, S. (June 2013). Consumer demand for cynical and negative news frames. InAnnualConferenceofthePoliticalScienceAssociation.Victoria, BC: Political Science Association.
Underdal, A. (1979). Issues determine politics determine policies: The case for a “rationalistic”approach to the study of foreign policy decision-making.CooperationandConflict, 14(1), 1-9. doi: 10.1177/001083677901400101
Zhang, L., Peng, T.Q., Zhang, Y.P., Wang, X.H. & Zhu, J.J.H. (2014). Content or context: Which matters more in information processing on microblogging sites.ComputersinHumanBehavior, 31, 242-249. doi: 10.1016/j.chb.2013.10.031
