基于JNI和C++的Intel集成众核并行方法
2018-05-09刘开兴白明泽
桑 喆,邓 川,苟 聪,刘开兴,白明泽
(1.重庆邮电大学生物信息学院,重庆 400065; 2.重庆邮电大学软件工程学院,重庆 400065)
0 引 言
在最新颁布的2016年全球超算TOP500的榜单[1]中,有18%的超算采用异构系统,利用GPU等加速卡强大的浮点计算能力来提升系统的计算性能。而这一比值在2013年还只是10.8%,3年间增长了67%,可以预见在今后会有越来越多的超算将会采用异构系统。我国自主研发的超级计算机——天河2号[2],曾连续6年位列全球超算TOP500榜单的榜首,采用的是Intel Xeon Ivy Bridge CPU芯片和Intel Xeon Phi协处理器混合的异构众核并行架构。Intel Xeon Phi协处理器是首款英特尔集成众核(Many Integrated Core, MIC)架构产品,拥有比常规GPU更多的核心,并且是基于x86处理器架构。与CPU相同的架构则意味着它对已有的程序有较好的兼容性。
MIC支持C/C++/Fortran这3种编程语言,由于MIC是基于x86处理器架构,这使得MIC在以Native模式工作时,可以作为独立计算节点直接运行既有的C/C++/Fortran程序代码;而在以Offload模式工作时,可以作为协处理器辅助CPU计算。通过对需要在MIC上运行的代码块添加Offload引语,MIC即可隐式地帮助完成数据的拷贝操作。但普通的GPU编程则需要程序员重新编写代码并手动完成数据的拷贝。MIC这2种模式的灵活性及其易编程性可以在一定程度上减轻程序员的负担。尽管MIC上可以安装定制的Linux系统并作为独立节点进行计算,但当前Intel并未在MIC上提供Java环境的支持。这带来一个问题就是MIC的协处理器难以将自己强大的计算能力发挥到大量用Java语言开发的许多大数据应用上。随着Hadoop[3],Spark[4]等大数据处理并行计算框架的广泛应用,很多大数据处理的应用都是采用Java编写的。常被用来作为加速卡的GPU在这个方面的发展则成熟得多,有较多的方法能够实现Hadoop+GPU的联合使用[5]:1)通过JNI[6],JNA[7]接口调用C++的Native代码供Java程序使用;2)Java Aparapi[8]能够将Java字节码转换为OpenCL并在GPU上执行;3)Nvidia CUDA提供有Java绑定和相关的库JCUDA[9]。
为了解决Java程序难以利用MIC计算资源的问题,本文研究JNI(Java Native Interface)技术与C++中的OpenMP[10]并行技术,提出基于JNI和C++的MIC混合并行方法,并对MIC并行的Java程序和MIC串行的Java程序的性能进行比较。本文主要的工作为以下2方面:
1)提出在Intel MIC协处理器上适配Java程序的并行方法。
2)评估、分析MIC在进行向量运算时的加速比。
评估结果表明在开启不同的线程数进行计算以及在不同的计算数据量下,MIC的计算效率有着不同的表现。随着计算数据量的增长,将MIC协处理器的线程全部开启用于计算,相对于MIC上的单线程计算所获得的加速比是比较好的。
1 背 景
1.1 Intel集成众核与Xeon Phi
集成众核(MIC)[11]是英特尔设计的专用于高性能计算的协处理器架构,其产品是Intel Xeon Phi芯片。本文中在讨论架构的时候用MIC来指代,在讨论具体硬件指标的时候用Xeon Phi指代。与常规CPU相比,Xeon Phi有着许多新的特性。它包含了57个简化了的x86核心,每一个核心通过特殊的超线程技术可以并发执行4个线程,并且拥有一个强大的向量处理单元(VPU),其向量宽度可以支持512 bits的向量计算。这对于高性能计算中需要大量单指令多数据运算的程序而言是极为重要的。
Xeon Phi的内存容量相对CPU的内存较小,这对某些算法而言可能是个性能瓶颈。每一个MIC核心拥有32 kB的一级数据缓存、32 kB的一级指令缓存和512 kB的二级缓存。图1给出了以缓存共享为主要特点的MIC协处理器架构,它通过一个高速环形拓扑总线连接MIC内核的同时也连接了所有L2高速缓存。有数据访问需求时,内核间首先访问彼此的L2高速缓存而不是访问内存,从而大大提升了数据通信效率。因为众核的架构中并没有L3高速缓存,数据从L2高速缓存出来之后,读取速度将大幅降低。但是,Xeon Phi仍然有着高达350 GB/s的内存带宽和5 GB/s的总线速度。此外,Xeon Phi协处理器与CPU通过PCIe线缆连接,但主协处理器的内存空间相互独立,并未共享。
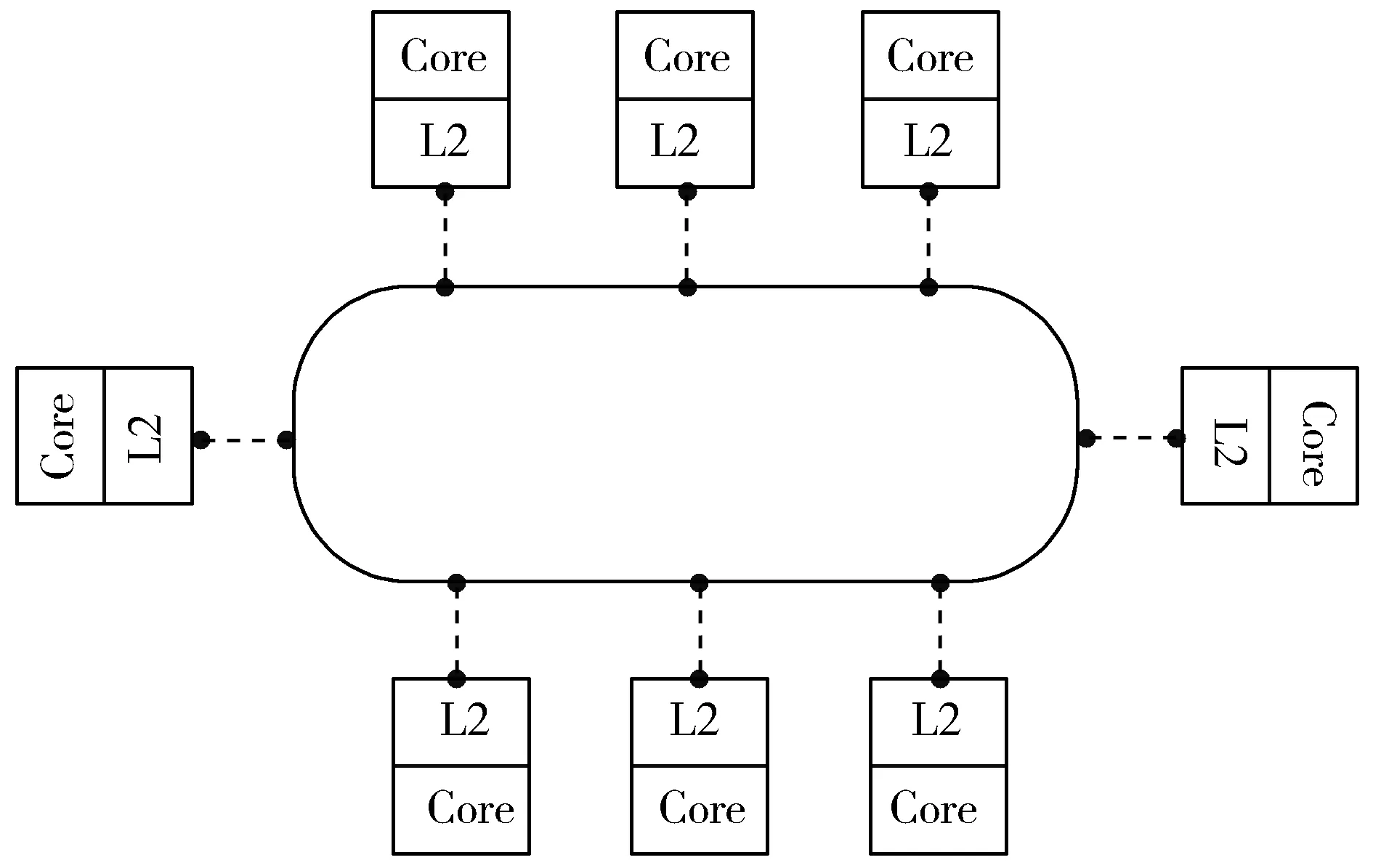
图1 MIC协处理器架构
MIC协处理器主要支持2种编程模型[12]:Offload模式和Native模式。在Native模式下,MIC可被当作是一个独立的SMP系统,可安装定制的Linux系统,并支持TCP/IP通信和众多标准API,如MPI[13]。在MIC上以Native模式运行程序之前,用户需要将程序代码和所需的数据从CPU节点传输到MIC节点上,并通过SSH登录到MIC卡上才能运行程序。由于MIC内存容量的限制,内存需求大的程序并不适合在MIC上运行。以Native模式运行的程序的编译和运行比较简单:在使用ICC(Intel C++ Compiler)编译C/C++代码时,加上-mmic参数,即得到可以在MIC上运行的可执行文件。
在Offload模式下,MIC以协处理器的身份辅助CPU工作,完成CPU分配的子任务。在此模式下,程序代码和计算所需的数据可以动态地由CPU传输至MIC,不需要一次性全部加载,所以MIC上的内存容量在Offload模式下一般不会成为一个大的性能瓶颈。对于在MIC上执行的代码,可用#pragma offload的指令语句在行首进行标注。
无论是以Native模式还是Offload模式运行,都需要诸如OpenMP,TBB[14],Cilk[15]和OpenCL[16]等多线程并行编程模型来帮助实现程序在MIC上的并行化。本文选用Offload模式,因为使用Offload模式可以避免消耗太多的内存空间。此外,MIC可以只运行程序中计算量高度集中部分的代码,发挥其计算性能;而CPU则负责执行较为复杂的逻辑,从而避免对原有Java代码做过多的更改。
尽管MIC是HPC领域的一颗新星,它已经被许多科研、工业团队广泛使用。天河2号现在已经被用于天气预测、粒子撞击模拟、汽车碰撞模拟等,这表明大量科学程序已经使用MIC加速。而这些应用实例成功应用也是源于一些重要的科学算法的成功移植,比如矩阵相乘、快速傅氏变换、分子动力学等。
1.2 OpenMP
OpenMP(Open Multi-Processing)是一个在C/C++/Fortran中支持多平台共享内存并行编程接口。OpenMP采用Fork-join模式:在程序刚开始运行的时候只有一个主线程运行,当执行到并行域时,由主线程派生出若干个子线程(Fork),然后系统将并行域的计算任务划分并分配给各线程进行并行计算,并行域子任务全部完成之后,各线程可按照代码指示将一些数据归拢(Join)到主线程。在并行域的任务执行结束之前,程序不会执行串行部分代码。使用OpenMP可以使程序员较为轻松地编写可移植的多线程程序,不需要手动进行复杂的线程创建、同步、负载均衡和销毁等工作。
因此,当需要将程序在MIC上并行化时,采用OpenMP是种较为容易的方法。
1.3 Java Native Interface
Java Native Interface (JNI)是一个编程框架,它使运行在Java虚拟机中的Java代码能够调用Native层的程序或者是C/C++编写的库文件;也可以使Java代码被Native层所调用。有时候一个应用程序不能完全用Java语言来编写,或是出于效率需要使用C/C++编写的执行效率更高的程序;或是出于硬件原因需要采用更底层的C/C++语言才可以控制硬件。此时,JNI就可以作为Java代码和C/C++代码之间的桥梁,使Java和C/C++混合编程得以实现。
与JNI相关的还有JNA(Java Native Acess)技术,它是建立在JNI之上的Java开源框架,所以其效率不如JNI,但开发人员可以更简单快捷地编写Native层的代码。基于效率的考虑,本文选用JNI技术来探索利用MIC计算资源加速Java程序的可行性。
2 方法及实现
2.1 混合并行方法
本文根据MIC的体系结构/编程环境和JNI技术提出支持Java并行的混合模型,如图2所示(图中实线代表程序的调用和数据传入,虚线代表被调用程序返回的数据)。在这个模型中,Java主程序通过JNI调用Native层的C++程序,实现2种语言的混合计算;Native层的C++程序通过OpenMP的帮助,将需要高性能计算的代码通过Offload模式提交到MIC的多核上并行计算,并接收来自MIC的计算数据。JNI也是Java代码到C++代码的数据传输接口,运行在CPU上的Native层C++代码会从JNI接收来自Java程序的数据;之后它会对其进行再度处理,使其符合MIC协处理器数据传输的要求,并通过Offload语句传输到MIC上开启多线程进行并行计算。计算的结果会被返回给CPU中运行的Native层C++程序,在被其处理、包装之后通过JNI接口传输到Java程序中。混合模型将计算由Java代码迁移到C++代码、由CPU迁移到MIC上,从而实现CPU-MIC的主副协同计算。
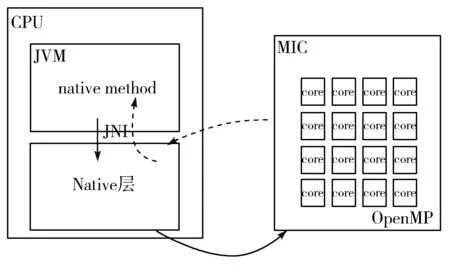
图2 混合并行方法架构
混合模型的指导思想是,程序中较为复杂的逻辑仍由CPU执行,保持原有Java代码不变;而那些适合并行化的、计算量较大的计算任务则通过JNI接口传输到C++Native层,由Native层执行。
方法具体流程为:首先要对原有Java代码进行分析,分离出需要并行化的部分,设计其C/C++并行方案;然后,根据C/C++方案所需要的数据来设计JNI接口,需要确保数据的正确传输;最后完成C++的并行程序的编码,这里需要用到OpenMP。
2.2 并行方法的实现过程
图3给出了一个矩阵相乘的Java/C++混合并行化实现过程,将其作为例子说明本文提出的混合并行方法的具体实现过程。
1)在Java项目中创建一个声明了Native方法的类,比如MICArrayMultipy.java,其中包含着一个public native int[] compute(int[] array_1, int[] array_2, int size)的方法,native是关键词,表明该方法是Native层的程序,将由C++语言实现。Java程序调用该方法时,将传入2个整型数组及数组的大小,计算结束后返回一个数组。
2)使用javac编译该Java代码,获得class文件。
3)使用javah-jni命令和Java类名生成C++的头文件,这个头文件中包含着Native方法的声明。
4)在与头文件同名的cpp文件中编写C/C++代码实现Native方法。为实现MIC并行,在计算相乘的for循环加上Offload语句,意在将这个for循环放在MIC上并行计算。同时还要在Offload代码块上加上OpenMP语句,将这段for循环开辟为并行域,选择适当的调度策略和线程数量。
5)将Native层的代码编译为一个动态链接库,在Java代码中使用System.loadLibrary()载入动态库。
6)运行程序。
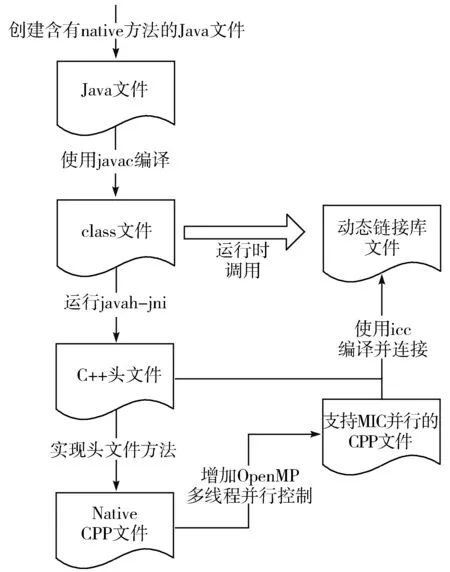
图3 混合并行方法的实现步骤
3 实验与结果
本文设计了一组实验,以检验基于JNI和MIC的Java/C++混合编程模型的性能。实验平台为部署在国家蛋白质科学中心(北京)的与天河2号同结构的高性能计算平台中的一个计算节点,它配备一个Ivy Bridge Xeon处理器(3.07 GHz)与一个Xeon Phi协处理器,CPU拥有64 GB的内存,MIC拥有8 GB的内存。操作系统是国产麒麟操作系统(版本NeoKylin release 3.2,内核版本2.6.32-431.29.2.2.ky3.1.x86_64)。Java的版本为1.8,使用ICC编译器(版本14.0.2)将Native代码编译为一个动态链接库,在Java代码中载入并调用该动态库。
在实验方法的选择上,本文没有使用Linpack[17]这样的Benchmark程序来做性能测试,而是根据MIC协处理器擅长进行向量运算,选择向量乘法计算进行实验。因为Linpack是通过计算N阶的线性代数方程组的时间来估测计算机每秒的浮点运算,它一般被用来评测不同硬件平台的浮点计算能力。本文要比较的是不同的编程模型的性能差异。
做向量乘法的数组大小分别为1000,10000,100000,1000000这4个等级,旨在通过设定数量级递增的4个测试数据,测试MIC在进行较大数据量的计算任务时的表现。本文测试了MIC上的串行和不同线程数程序的并行计算时间,线程数分别为:32,64,128,256(超出MIC核数量的线程数用来测试Intel的超线程技术[18])。向量乘是一种非常简单的运算,为了加长计算时间以尽量减小其它程序的干扰,在每次测试中都让乘法重复计算1000次。测试的计算时间结果如表1所示,表中的时间值为重复5次测试后取得的中位数值。
表1 单、多线程下运行时间/ms
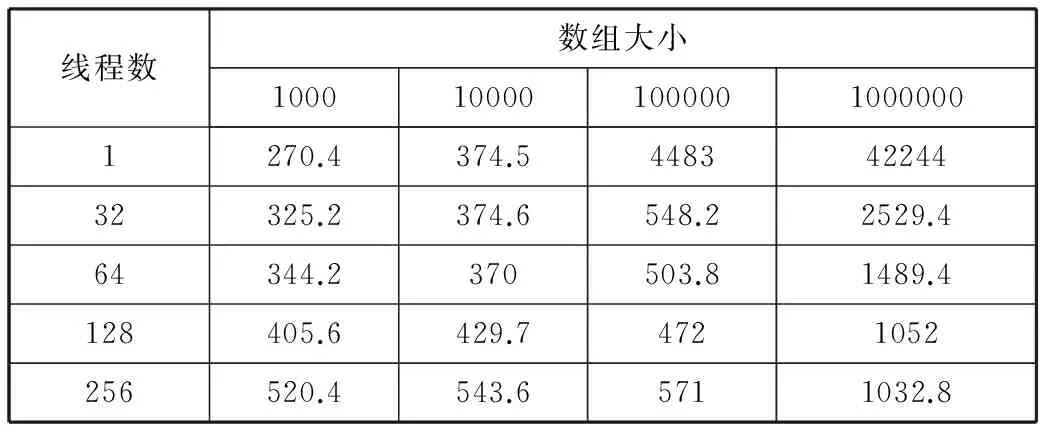
线程数数组大小10001000010000010000001270.4374.544834224432325.2374.6548.22529.464344.2370503.81489.4128405.6429.74721052256520.4543.65711032.8
为更好地比较模型的并行性能,本文计算并行计算的加速比。加速比公式:Sp=Tp/T1,其中Sp为加速比,Tp是p条线程程序的运行时间,T1是单核/单线程下的运行时间。加速比结果如表2所示。为更直观观察加速比结果,图4给出了以数组大小为视角的加速比折线图,4条折线分别代表着4种数组大小(小于1.2的值用实线表示,大于1.2的值用虚线表示)。从图4可以明显地观察到,在数组较小(1000和10000)时,加速比均小于或等于1,而且随着线程数的增多而下降。这说明在数据量较小时,并行计算根本没有得到性能提升。当数组大小增长到100000时,可以发现加速比在线程数为32~128时有平稳的提升,但是在线程数进一步增长到256时开始下降。而数组大小为1000000时,随着线程数的增加,加速比有大幅提升,从16.7快速增长到40.16(线程数为128)。在线程数为256时,出现了与100000的情况类似性能下降的情况。
表2 不同数组大小下各线程数取得的加速比
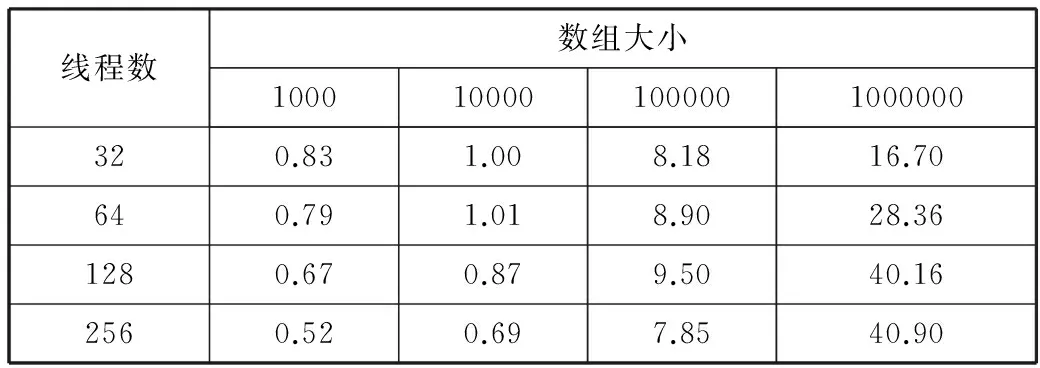
线程数数组大小1000100001000001000000320.831.008.1816.70640.791.018.9028.361280.670.879.5040.162560.520.697.8540.90
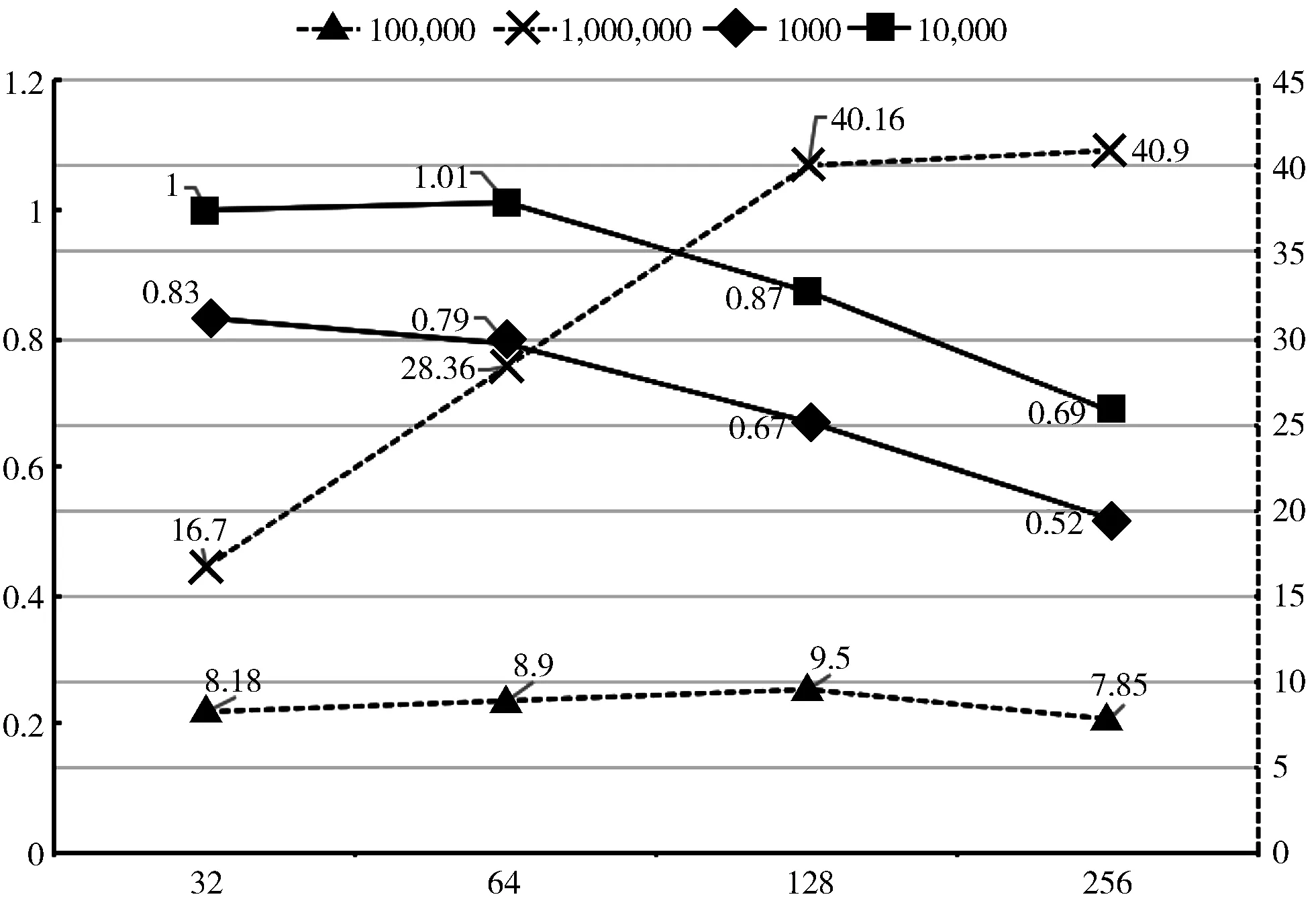
图4 以数组大小为主视角的加速比折线
图5从线程数量角度展示了各种实验组合的加速比。通过图5可以看出整体的趋势是,多线程加速的效果随着数组规模的增大而提高。而且在数组大小为100000时,大于32的线程数没有获得更好的并行性能。在数组大小达到1000000的时候,加速比差异才体现得较明显:线程数越多,加速越显著(线程数为256时除外,后面将讨论)。
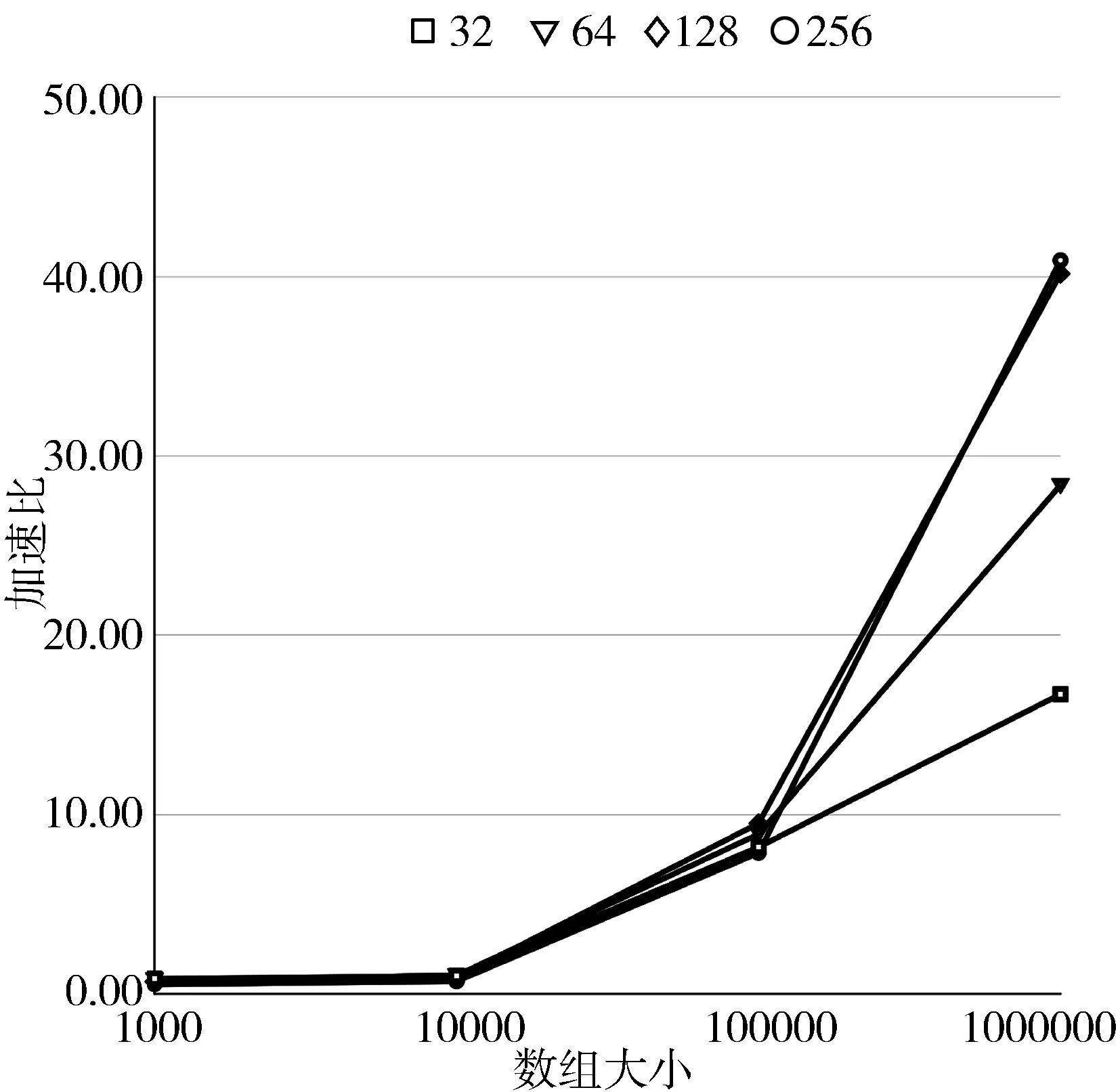
图5 以线程数量为主视角的加速比折线图
下面讨论这些性能差异产生的原因。在数组大小为1000~10000时,采用MIC进行多线程并行计算耗时(成本)要多于多线程并行所节约的时间(收益),因此并行反而比串行更慢。这里的成本包括:CPU-MIC之间的数据传输、OpenMP的初始化、并行域的创建、数据的分发和归拢等一系列行为所需的时间。这里面比重较大的是CPU与MIC协处理器之间的通信开销,它把大量的数据在CPU和MIC协处理器之间传递,耗费了较多的时间成本。
当数组大小增长到100000和1000000时,并行计算都得到了明显的加速,这是因为在成本增长较少的时候,并行计算的收益快速增长。另外,在这2个数据量级的条件下,线程数128并行性能最好。这与英特尔超线程技术是有关的,通过虚拟逻辑核心,得到2倍于原处理器核心数的线程,而MIC协处理器有57个计算核心,乘以2得到接近128的线程数量。当线程数量继续增长到256时,由于这超出了系统所能提供的量,只会在没有更多收益的情况下增加并行操作成本,从而减慢总的计算速度。
综上,选择较大的数据规模和合适的线程数(核心数×2),本文提出的JNI/C++混合并行方法可以取得良好的并行加速成绩。
4 结束语
Java语言编写的程序无法直接采用MIC协处理器进行并行化,这影响了这些应用在基于MIC的高性能计算机上的应用推广,也不利于计算机资源的有效使用。本文因此提出JNI与C++的混合并行方法。将JNI作为沟通Java主程序和C++计算密集代码的接口,使数据可以由Java程序载入C++程序中,进而调用强大的MIC协处理器进行计算。分析与测试表明,MIC协处理器的计算资源可以通过该并行方法被Java程序调用,并在数据量较大和线程数设置合适时获得较好的性能提升。这表明在涉及大量的复杂计算时,可以利用MIC强大的并行计算能力给程序性能带来提升,甚至是用Java语言编写的程序也可以做到这一点。
未来将继续深入研究数据在MIC上的持久性问题,即如何在Offload模式下进行迭代计算时,减少数据向MIC和CPU之间的拷贝次数,降低通信成本、提高效率。
参考文献:
[1] 国际TOP500组织. 全球超级计算机排行榜TOP500[DB/OL]. https://www.top500.org/lists/2017/06/, 2017-06-30.
[2] 王涛. “天河二号”超级计算机[J]. 科学, 2013,65(4):52.
[3] White T. Hadoop: The Definitive Guide[M]. Yahoo Press, 2011.
[4] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[C]// Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing. 2010: Article No. 10.
[5] Zhu Jie, Li Juanjuan, Hardesty E, et al. GPU-in-Hadoop: Enabling MapReduce across distributed heterogeneous platforms[C]// Proceedings of the 13th IEEE/ACIS International Conference on Computer and Information Science. 2014:321-326.
[6] 任俊伟,林东岱. JNI技术实现跨平台开发的研究[J]. 计算机应用研究, 2005,22(7):180-184.
[7] Fast T, Wall T, Chen Liang. Java Native Access (JNA)[EB/OL]. https://github.com/twall/jna, 2007-05-09.
[8] Okur S, Radoi C, Lin Yu. Hadoop+Aparapi: Making Heterogenous MapReduce Programming Easier[DB/OL]. http://www.semihokur.com/docs/okur2012-hadoop_aparapi.pdf, 2012-04-10.
[9] Yan Yonghong, Grossman M, Sarkar V. JCUDA: A programmer-friendly interface for accelerating Java programs with CUDA[C]// Proceedings of the 15th International Euro-Par Conference on Parallel Processing. 2009:887-899.
[10] Chandra R, Dagum L, Kohr D, et al. Parallel Programming in OpenMP[M]. Morgan Kaufmann, 2001.
[11] Chrysos G. Intel®Xeon PhiTMcoprocessor (codename knights corner)[C]// Proceedings of the 24th Hot Chips Symposium. 2012, doi: 10.1109/HOTCHIPS.2012.7476487.
[12] Wang Endong, Zhang Qing, Shen Bo, et al. High-performance Computing on the Intel®Xeon PhiTM: How to Fully Exploit MIC Architectures[M]. Springer, 2014.
[13] Clarke L, Glendinning I, Hempel R. The MPI message passing interface standard[M]// Programming Environments for Massively Parallel Distributed Systems. Birkhauser, 1994:213-218.
[14] Reinders J. Intel Threading Building Blocks: Outfitting C++ for Multi-core Processor Parallelism[M]. O’Reilly Media, 2007.
[15] Randall K. Cilk: Efficient Multithreaded Computing[R]. Massachusetts Institute of Technology, 1998.
[16] Stone J E, Gohara D, Shi Guochun. OpenCL: A parallel programming standard for heterogeneous computing systems[J]. Computing in Science & Engineering, 2010,12(3):66-73.
[17] Dongarra J J. The Linpack benchmark: An explanation[C]// Proceedings of the 1st International Conference on Supercomputing. 1987:456-474.
[18] Tian Xinmin, Chen Yenkuang, Girkar M, et al. Exploring the use of hyper-threading technology for multimedia applications with Intel®OpenMP*compiler[C]// Proceedings of the 17th International Symposium on Parallel and Distributed Processing. 2003, doi:10.1109/IPDPS.2003.1213118.
