基于可变形卷积神经网络的手势识别方法
2018-05-09苏军雄见雪婷华俊达张胜祥
苏军雄,见雪婷,刘 玮,华俊达,张胜祥
(华南农业大学数学与信息学院,广东 广州 510642)
0 引 言
手势识别是人机交互的一种直接的表达形式,将手势作为计算机的输入已经日益成为一种趋势。神经网络通过连接到计算机相机捕获手势或更一般的人体姿势和运动来判别手势[1-3]。2015年11月,Google发布深度学习框架TensorFlow并宣布开源,使得神经网络与手势识别更好地融合。现今伴随着人机交互技术飞速发展,手势识别技术也逐渐出现在人们的视野中。在家庭娱乐方面被广泛熟知的微软Xbox游戏机,主要由Kinect3D体感摄影机组成,上面集成了可以识别动作及表情的摄像头和红外传感器。手势识别也应用在智能驾驶中,在2015年的CES展上,宝马展出了最新iDrive系统,其重要变化之一就是引入了手势识别功能,通过安装在车顶上的3D传感器对驾驶员的手势进行识别,实现驾驶员能够利用手势控制车辆导航、信息娱乐等功能。
传统的手势识别模型大致可以分为以下3类:1)基于加速传感器戒指等可穿戴设备的手势识别方法[4]。该方法有效且可用于复杂环境下的手势识别,即将识别问题转换成求解样本间的稀疏表示问题。该方法一般都使用穿戴型的传感器进行数据采集,并非直接在视频流和图片上获取,只借助电脑无法实现数据获取。2)基于视觉的手势识别。例如,基于RGB图像的时间序列手势轮廓模型的手势识别方法[5]、多色彩度结合的手势识别算法[6]和人工设计特征提取的手势识别算法[7-8]。由于RGB图像只包含色度信息,对于其他肤色或近肤色的抗干扰性较差。3)基于RGB-D图像(彩色和深度图像)的手势识别技术,该方法信息获取简单方便、信息量丰富、自由度高[9]。通过模糊聚类算法对手、脸的近距离遮挡进行分割,利用SVM和深度HOG特征完成静态手势识别。其能够较好地分割出近脸的静态手势,但是该方法的实时性和在不同距离下的适用性有待于验证[10]。后2种方法都是基于人工提取图像中的特征实现的。然而,人工提取图像的特征过程复杂,需要有较高的专业知识和经验,难于轻易地泛化到大多数的场景中来。
卷积神经网络[11]是目前机器视觉和图像处理领域应用广泛的模型之一,受到了工业界和学术界的高度关注。近年来,卷积神经网络已成功应用于图像检索[12]、表情识别[13]、行人检测[13]、人体行为检测[14]和手势识别[15]中。得益于卷积神经网络可以直接从原始图像中识别视觉模式,其需要的预处理工作很少[15]。并且卷积神经网络一般在图像处理方面有如下的优势:1)输入图像和网络的拓扑结构能很好地吻合;2)特征提取和模式分类能够同时进行;3)权值共享可以大大减少网络的训练参数,使得神经网络结构变得简单,泛用性增强[16]。
但是传统的卷积神经网络的采样会受卷积核的影响,其采样的性能会受限于卷积核中固有的几何设计。因此,本文基于对卷积神经网络的卷积层结构进行改进,提出一个名为DC-VGG的卷积神经网络,较好地解决了手势识别上图像采样的问题。通过在实验中比较改进后的DC-VGG与传统的VGG、LeNet-5网络的性能,得出一些有益的结论,有利于以后的研究。
1 卷积神经网络
在传统的图像识别中,建立图像识别的分类模型是一件十分费力的事情,需要输入图像,通过设计一系列模型对图片进行预处理,根据提取出来的指标进行分类得到输出结果,如图1所示。而利用卷积神经网络则不需要考虑特征设计和提取的问题,它只需直接将图像作为数据输入网络中,就可以在输出端得到分类结果。如图2所示。

图1 传统分类模型

图2 卷积神经网络分类模型
得益于卷积神经网络可以直接利用原始图像作为输入数据,使得前期所需要进行的预处理大大减少。并且卷积神经网络可以通过局域感受域、权值共享和降采样这3种方法来实现对图片的处理。局部感受域指的是在卷积层中,每一层的神经元只与上一层的一个小邻域内的神经单元连接,通过局部感受域,每个神经元可以提取初级的视觉特征;权值共享可以是卷积神经网络的参数共享,具有更少的参数,从而减少了训练所需要的数据;降采样是在池化层进行的,降采样可以减少特征的分辨率,实现了对位移、缩放和其他形式的扭曲的不变性[16]。
但是,在传统的卷积层中,局部感受域的几何结构是方块型卷积,致使局部感受域中提取的特征也属于方块型的特征。而图像中的手势是不规则的形状,直接用固定的方块型卷积提取其特征会使卷积层中的几何变换能力变得低效,增大识别的难度。
相比原本的卷积核,引入可变形的卷积核可以使接受图像的感受域的区域变得更符合实际情况的需要。即引入可变形的卷积核可以根据实际物体的形状而进行自我提取特征,提取图像物体的轮廓也不是固定的正方形,而是以一种近似于物体沦落的形状作为卷积核的提取特征的“滑动框”。这样极大地保留了图像中物体原本所具有的特征,不会因受限方形的提取特征的“滑动框”而使得某些特征被割裂,使图像中物体特征提取受到一定的损失或者丢失。另外,这样也符合实际情况的需要,使得图像中物体的特征保留得更完整、更全面,从而能有效地提高网络的性能,较好地进行手势识别。因此,本文引入一种改进卷积核[17]结构的方法,具体原理如1.1节所示。
1.1 可变形卷积层
传统的卷积层的几何结构是固定的,采取的是方块型卷积核。若采用二维网格图表示,则如图3(a)所示,因而其几何变换的能力有限。而对于可变形卷积则会突破几何结构的固定性,在每一个卷积核上加入一个偏移的向量,如图3(b)~图3(d)所示,从而可以提升卷积神经网络的泛化能力,提高不规则图形上的识别效果。
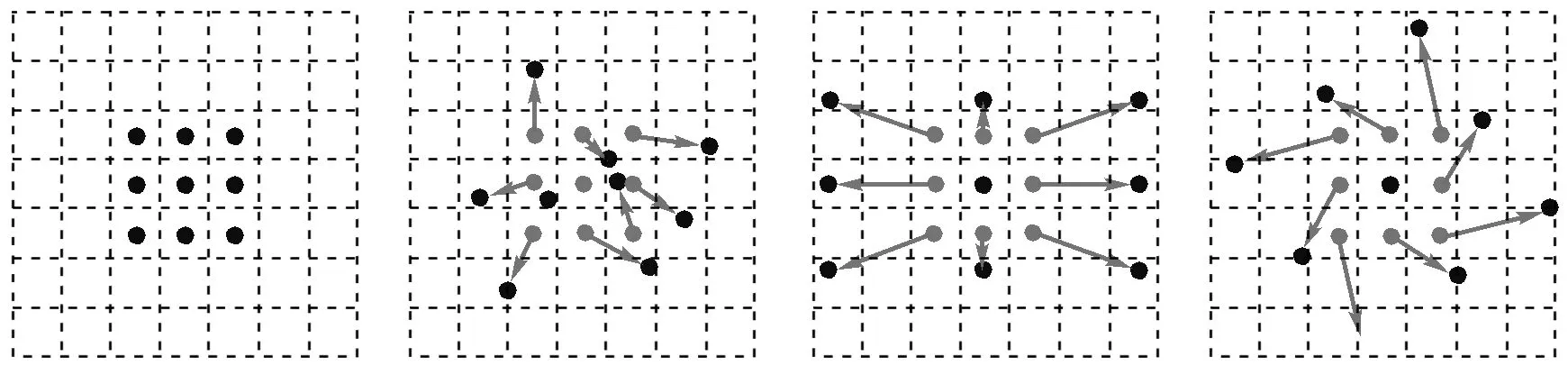
(a) (b) (c) (d)图3 卷积核采样点的位置分布图
图3中分别展示4种3×3的卷积核采样点的位置分布图。图3(a)代表传统的卷积核的取样点;图3(b)代表引入一种随机偏移向量的卷积核的取样点;图3(c)与图3(d)是图3(b)的特殊情况,都是引入规则性偏移向量的卷积核取样点,表明可变形卷积可以在各种尺度、各种旋转变换下推广。
通常,二维卷积核的提取分为2个步骤:1)在特征图上利用一个规则化的网格R进行采样;2)在每个采样点处乘上相应的权值w并求和。
下面,以一个二维的3×3的卷积核采样为例:
R={(-1,-1), (-1,0), …, (0,1), (1,1)}
在传统卷积核中,每一个位置p0的输出结果为:
(1)
其中pn表示在区域R的任一位置。
在可变形卷积核中,引入一个偏移向量{Δpn|n=1,…,N},其中N=|R|。式(1)可变形为[17]:
(2)
其中,pn表示在卷积窗口中任意一个像素点,w(pn)表示像素点pn的权重,x表示输入层像素点的集合,Δpn表示像素点pn的偏移量。
由于采样是在不规则区域上进行,会导致偏移向量通常情况下为分数。因此,式(2)需要通过双线性插值来实现:
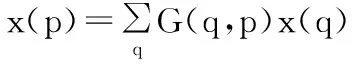
(3)
其中p表示区域中的任意位置,且p=p0+pn+Δp; q表示所有的空间分布特征;G(·,·)表示双线性插值核,由于其是二维的,可以分解成2个一维的内核:
G(q,p)=g(qx,px)g(qy,py)
(4)
其中g(a,b)=max (0,1-|a-b|)。
图4展现了可变形卷积层的实现过程。在输入层中原本固定采样区域分别加入偏移向量,然后在卷积核中通过双线性插值的算法将带有偏移向量的采样点集中在一起,并且使得带偏移向量的输出特征图与输入的特征图具有一致的空间分辨率,最终传递给下一个网络层。这样,在不改变空间分辨率的情况下,实现对不规则图像特征的提取。
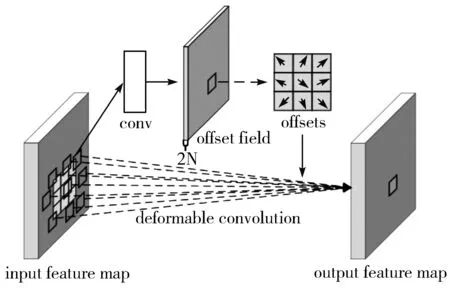
图4 可变形卷积层的实现过程
1.2 池化层
在池化层中,本文选用了平均池化的池化方法,即对邻域内的特征点求其平均。
因此,在池化层的形式如式(5)所示:
(5)
其中,pn表示在池化窗口中任意一个像素点,ni,j表示固定在bin里的总像素数。
2 卷积网络结构及改进
2.1 VGG卷积网络结构
VGG-16卷积网络共有21层,其中包括13个卷积层、5个池化层和3个全连接层,具体的网络结构如图5所示。其中,VGG-16使用多个较小卷积核的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面进行了更多的非线性映射,可以增加网络的表达能力。
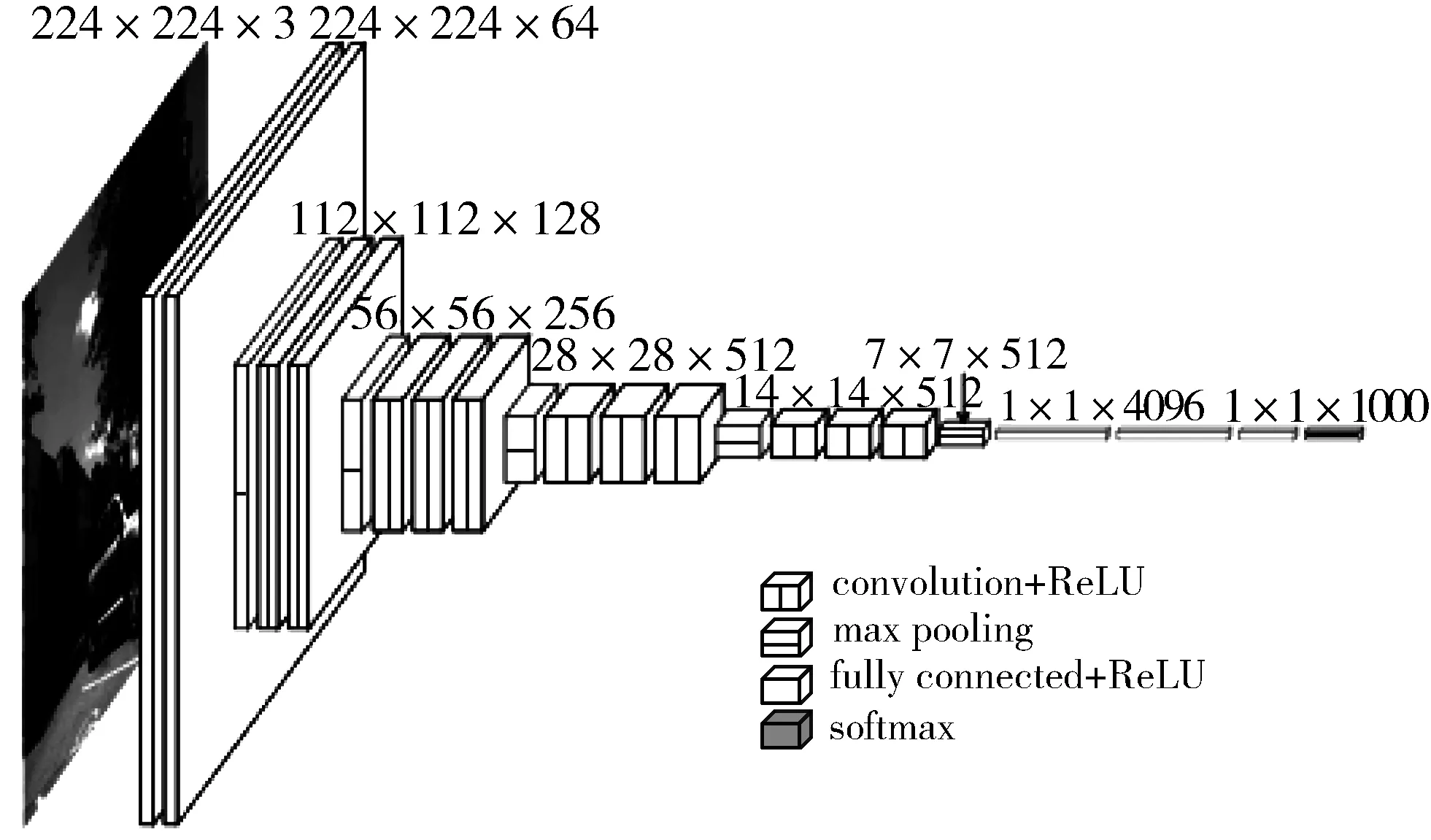
图5 VGG-16的网络结构
2.2 VGG卷积网络的改进
本文的卷积网络结构是在VGG-16的网络结构基础上加以改进的。原先的VGG-16网络结构包括13个卷积层(C)、5个池化层(S)和3个全连接层(F),而改进的网络结构缩减了卷积层的个数,并且引入可变形卷积层,将部分的传统卷积层替换成可变形卷积层,最终包括6个卷积层(C)、4个可变形卷积层(DC)、5个池化层(S)和3个全连接层(F)。改进后的网络称为DC-VGG网络。具体的网络结构连接方法如图6所示。
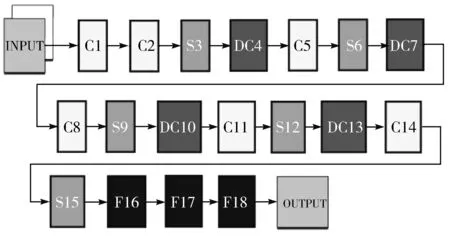
图6 DC-VGG的网络结构
2.3 DC-VGG的网络结构
本文搭建的DC-VGG网络结构共由18层组成。该网络的输入层需要256×256大小的图像作为输入,经过卷积层(C)、可变形卷积层(DC)、池化层(S)和全连接层(F)的共同作用,最终得到输出的结果(其中各阶段输出结果见表1)。
表1 DC-VGG网络结构输出结果
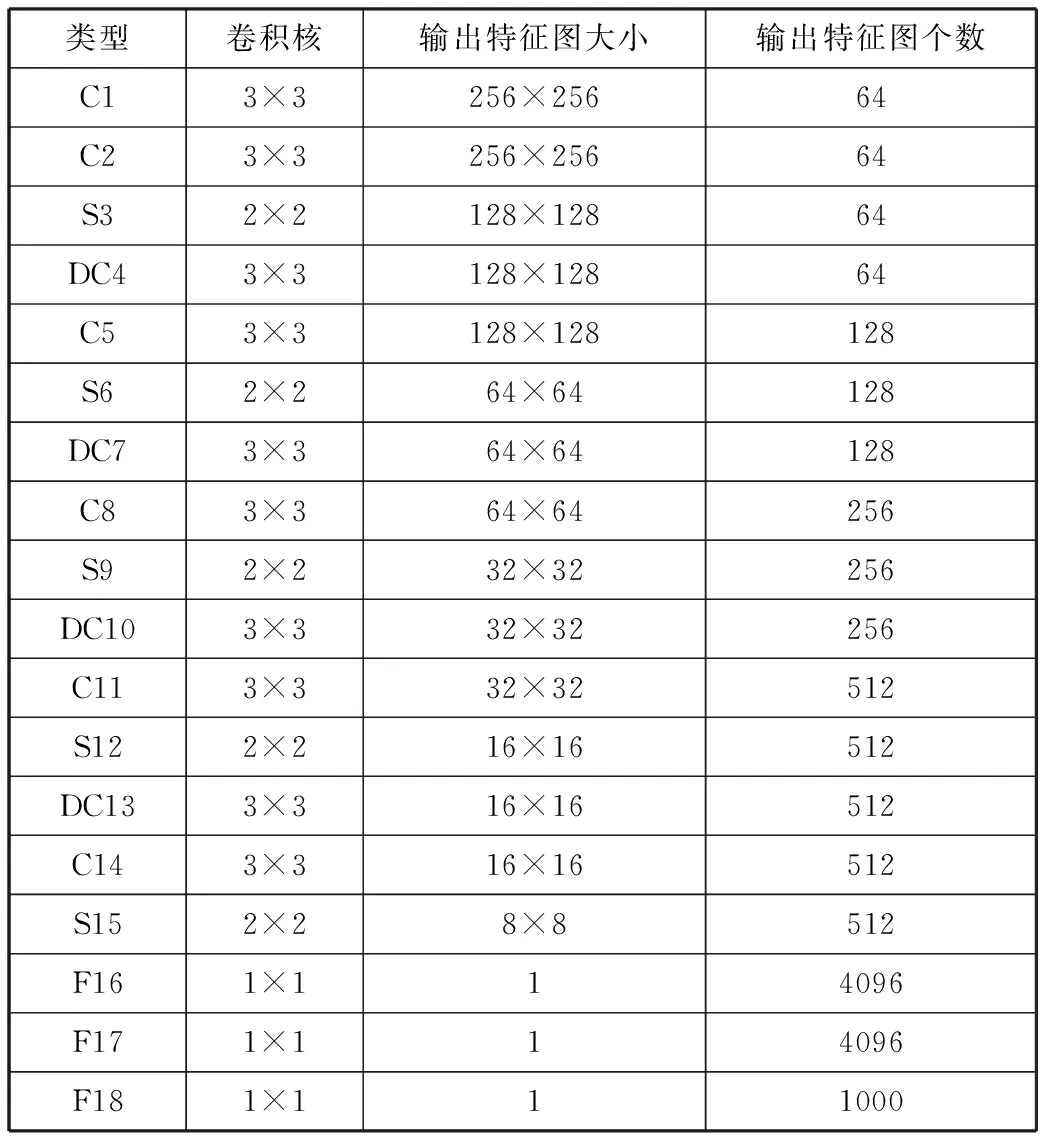
类型卷积核输出特征图大小输出特征图个数C13×3256×25664C23×3256×25664S32×2128×12864DC43×3128×12864C53×3128×128128S62×264×64128DC73×364×64128C83×364×64256S92×232×32256DC103×332×32256C113×332×32512S122×216×16512DC133×316×16512C143×316×16512S152×28×8512F161×114096F171×114096F181×111000
在C1,C2网络层中,会对输入的图像进行方形区域内的卷积作用。因此,每个神经元会与输入图像中的某个3×3的方形区域相连接,得到64个特征图,其大小为256×256。
在S3网络层中,则会对C2的特征图进行降采样处理。在该网络层中将会利用2×2的抽样窗口进行操作,得到64个特征图,其大小为128×128。
在DC4网络层中,会对S3的特征图进行不规则区域内的卷积作用。因此,该层中的每个神经元会与S3的特征图中的某个3×3的延伸不规则区域相连接,得到64个特征图,其大小为128×128。
在C5网络层中(同C1),对DC4进行卷积的操作,得到128个特征图,其大小为128×128。
在S6网络层中(同S3),为第2个池化层,继续进行降采样处理。抽样窗口为2×2,特征图为128个,其大小为64×64。
在DC7网络层中(同DC4),继续在不规则区域提取特征图。其中,卷积核为3×3,得到特征图为128个,其大小为64×64。
在C8网络层中(同C1),对DC7进行卷积操作。其中,卷积核为3×3,得到256个特征图,其大小为64×64。
在S9网络层中(同S3),为第3个池化层,继续进行降采样处理。抽样窗口为2×2,特征图为256个,其大小为32×32。
在DC10网络层中(同DC4),继续在不规则区域提取特征图。其中,卷积核为3×3,得到特征图为256个,其大小为32×32。
在C11网络层中(同C1),对DC10进行卷积操作。其中,卷积核为3×3,得到512个特征图,其大小为32×32。
在S12网络层中(同S3),为第4个池化层,继续进行降采样处理。抽样窗口为2×2,特征图为512个,其大小为16×16。
在DC13网络层中(同DC4),继续在不规则区域提取特征图。其中,卷积核为3×3,得到特征图为512个,其大小为16×16。
在C14网络层中(同C1),对DC13进行卷积操作。其中,卷积核为3×3,得到512个特征图,其大小为16×16。
在S15网络层中(同S3),为第5个池化层,继续进行降采样处理。抽样窗口为2×2,特征图为512个,其大小为8×8。
在F16,F17,F18的全连接层中,把S15层的特征图的数据向量化后连接到输出层,最终得到一个1×1×1000的输出结果,用来进行识别。
3 实验和结果分析
3.1 图像的预处理
在手势识别系统设计中,为了有效提高算法性能,通常要进行手势区域检测、分割和手势的规范化处理等预处理操作。
在本次实验中,对数据集的图片仅进行了手势的规范化处理。将数据集的所有RGB图片保持原本的长宽比,裁剪成256×256大小,用来作为实验的输入层数据,同时裁剪后的图像能够降低网络的运算量,更容易提取出合适的特征,从而提高识别率。
图7为手势预处理演示图。

图7 手势预处理演示图
3.2 实验分析
3.2.1 实验基础

图8 10种手势
本文的所有实验都是在Ubuntu 16.04 LTS系统下利用TensorFlow框架完成的,系统的硬件环境为I5-7300HQ处理器,主频为2.50 GHz。而实验的数据集则是选取了一个公共的手势库,手势库的名称为Large RGB-D Extensible Hand Gesture Dataset[18]。选取10种手势用于实验,如图8所示。将数据集设置为1500张,测试集设置为150张。每个手势的实验分别运行5次,取其识别率的平均值,作为最终某个手势的识别率。同时也记录3种网络单张图像的平均识别时间,通过结合手势的识别率来反映3种网络的性能情况。
3.2.2 LeNet-5, VGG, DC-VGG对比
本文自行搭建了LeNet-5, VGG-16, DC-VGG这3种网络结构的卷积神经网络来对实验的数据集进行训练。分别将3种卷积神经网络应用到10种手势的数据集中,学习率设置为0.001, batch-size设置为32,意味着每次传入32张图片进行训练,每训练100次记录一次识别率(记作迭代1次),总共迭代20次。取最后5次迭代时记录的识别率,计算其平均值,从而得到3种网络结构的实验结果,具体如表2所示。
表2 3种网络结构的实验结果
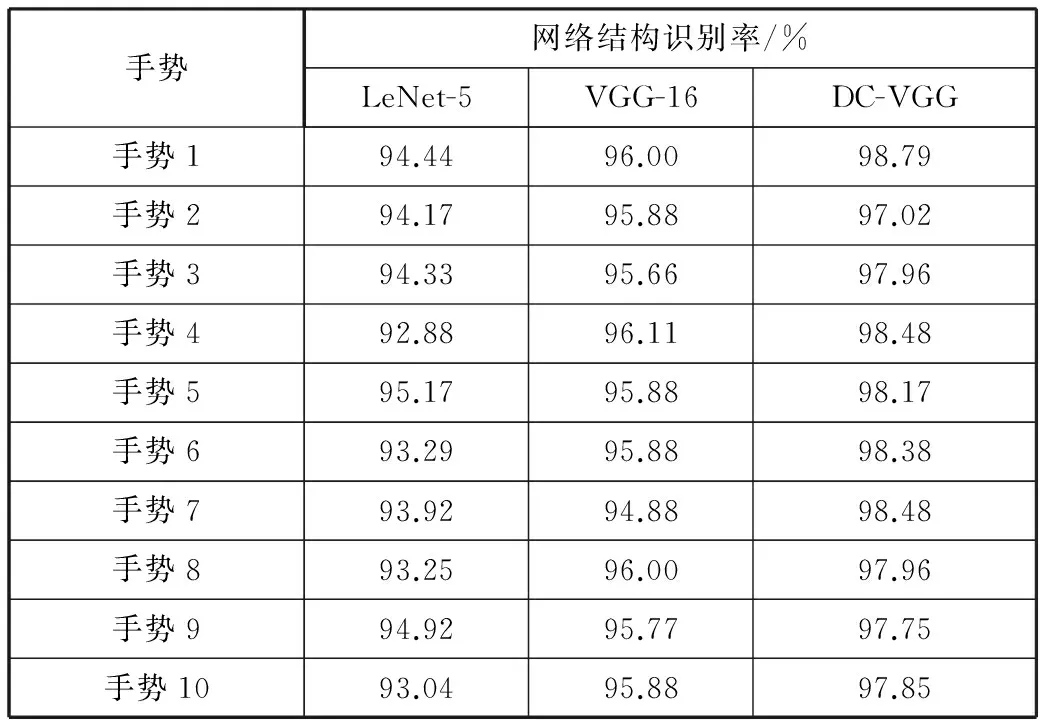
手势网络结构识别率/%LeNet-5VGG-16DC-VGG手势194.4496.0098.79手势294.1795.8897.02手势394.3395.6697.96手势492.8896.1198.48手势595.1795.8898.17手势693.2995.8898.38手势793.9294.8898.48手势893.2596.0097.96手势994.9295.7797.75手势1093.0495.8897.85
另外,对3种网络的单张平均识别时间进行统计,记录运行识别集所需要的时间,再除以对应的识别集的图像数,得到各网络结构的单张平均识别时间如表3所示。
表3 3种网络结构的单张平均识别时间
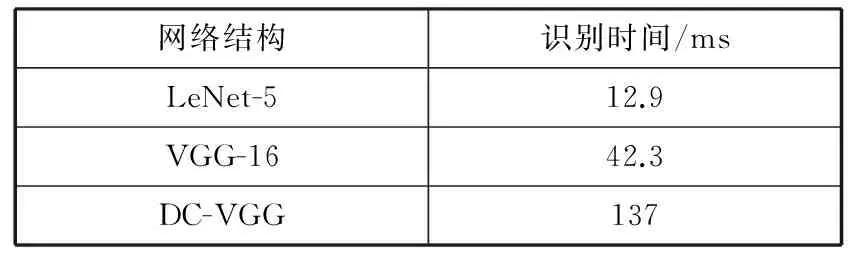
网络结构识别时间/msLeNet-512.9VGG-1642.3DC-VGG137
从上述的实验结果来看,引入可变形卷积层的DC-VGG网络的识别率优于LeNet-5和VGG-16网络,说明引入可变形卷积层可有效提高网络的性能,提升了卷积神经网络对样本对象的容忍度和多样性,丰富了卷积神经网络特征的表达能力。
不过在识别时间的表现上差强人意,这其中的差异是由于网络结构层数的不同所造成的。网络层数越深,所需要经历的时间越长;还有可变形卷积层的采样需要借助双线性插值来实现,从而增加了网络运算的复杂度,导致时间比VGG-16的长。这一点,是今后需要优化和改进的地方。
3.2.3 DC-VGG网络与其他模型对比
在实验中选取有代表性的传统手势识别算法,依此在公共的手势库Large RGB-D Extensible Hand Gesture Dataset[18]上进行实验的验证。
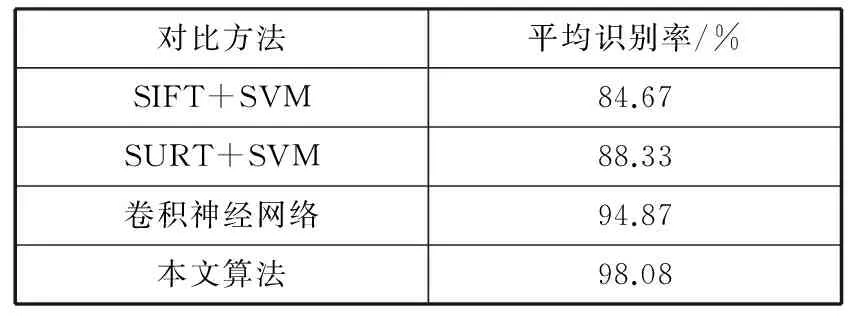
表4中列举了比较实验的结果。其中,SIFT+SVM方法[7]是将SIFT特征提取与SVM(支持向量机)分类器结合组成的,获得了84.67%的识别率;将SURT方法特征[8]提取与SVM分类器结合组成的方法,获得了88.33%的识别率;在传统的卷积神经网络模型上,获得了94.87%的识别率;而本文的可变形卷积网络算法,得到了98.08%的识别率,优于传统的卷积神经网络和基于人工特征设计的传统算法。
表4 DC-VGG网络与其他方法识别性能比较
对比方法平均识别率/%SIFT+SVM84.67SURT+SVM88.33卷积神经网络94.87本文算法98.08
通过上述比较实验结果可知,人工设计特征算法的识别率没有卷积神经网络的识别率高,这说明卷积神经网络的特征提取更充分、更真实,在识别率上的表现更出色。另外,通过对传统的卷积神经网络进行加入可变形卷积层的扩展,明显地提高了手势识别的识别率,表明卷积神经网络具有优异的可扩展性,同时,结构性的扩展也展现出对性能巨大的提升潜力。
4 结束语
本文在VGG-16卷积神经网络中引入可变形卷积层的模块,应用到公共的手势识别数据库中,对比传统的LeNet-5和VGG-16的网络结构,均取得较好的识别率。这说明加入可变形卷积这种空间变化的模块,能有效地提高卷积神经网络的性能,提高卷积神经网络的特征表达能力,为复杂背景下有效识别手势提供参考,并且具有一定的延拓能力。实验结果表明,改进的DC-VGG与VGG-16网络相比结构简单,比传统的人工设计特征的算法识别率更高,更加稳定。卷积神经网络局部感受域和权值共享的特征,直接将RGB图像输入神经网络中,亦大大减少了图片预处理的难度。
参考文献:
[1] Pavlovic V I, Sharma R, Huang T S. Visual interpretation of hand gestures for human-computer interaction: A review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997,19(7):677-695.
[2] Wu Ying, Huang T S. Vision-based gesture recognition: A review[C]// Proceedings of the 1999 International Gesture Workshop on Gesture-based Communication in Human-Computer Interaction. 1999:103-115.
[3] Jaimes A, Sebe N. Multimodal human-computer interaction: A survey[J]. Computer Vision and Image Understanding, 2007,108(1-2):116-134.
[4] Xie Renqiang, Sun Xia, Xia Xiang, et al. Similarity matching-based extensible hand gesture recognition[J]. IEEE Sensors Journal, 2015,15(6):3475-3483.
[5] 庞海波,李占波,丁友东. 基于时间序列手势轮廓模型的动态手势识别[J]. 华南理工大学学报(自然科学版), 2015,43(1):140-146.
[6] Bhuyan M K, Kumar D A, MacDorman K F, et al. A novel set of features for continuous hand gesture recognition[J]. Journal on Multimodal User Interfaces, 2014,8(4):333-343.
[7] 李翠,王小妮,刘园园. 基于SIFT算法的手势控制系统的设计与实现[J]. 现代经济信息, 2016(10):337.
[8] Wallach H M. Topic modeling: Beyond bag-of-words[C]// Proceedings of the 23rd International Conference on Machine Learning. 2006:977-984.
[9] 曹洁,赵修龙,王进花. 基于RGB-D信息的动态手势识别方法[J/OL]. http://www.arocmag.com/article/02-2018-06-050.html, 2017-06-14.
[10] 刘斌,赵兴,胡春海,等. 面向颜色深度图像手脸近距遮挡的手势识别[J]. 激光与光电子学进展, 2016(6):134-143.
[11] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems. 2012,1:1097-1105.
[12] 陈祖雪. 基于深度卷积神经网络的手势识别研究[D]. 西安:陕西师范大学, 2016.
[13] 柯圣财,赵永威,李弼程,等. 基于卷积神经网络和监督核哈希的图像检索方法[J]. 电子学报, 2017,45(1):157-163.
[14] Fan Yin, Lu Xiangju, Li Dian, et al. Video-based emotion recognition using CNN-RNN and C3D hybrid networks[C]// Proceedings of the 18th ACM International Conference on Multimodal Interaction. 2016:445-450.
[15] 左艳丽,马志强,左宪禹. 基于改进卷积神经网络的人体检测研究[J]. 现代电子技术, 2017,40(4):12-15.
[16] 赵志宏,杨绍普,马增强. 基于卷积神经网络LeNet-5的车牌字符识别研究[J]. 系统仿真学报, 2010,22(3):638-641.
[17] Dai Jifeng, Qi Haozhi, Xiong Yuwen, et al. Deformable Convolutional Networks[DB/OL]. https://arxiv.org/abs/1703.06211, 2017-06-05.
[18] Multimedia Computing Laboratory. Large RGB-D Extensible Hand Gesture Dataset[DB/OL]. http://mclab.citi.sinica.edu.tw/dataset/lared/lared.html#download, 2014-07-18.
