一种文本聚类的增强数据挖掘方法
2018-05-09魏爽
魏爽
(三亚学院信息与智能工程学院,海南 三亚 572000)
1 引言
各种信息源的信息每天都在快速地增长,从大量的信息中提取并发现有价值的信息的需要也与日俱增。数据挖掘就是一个用于从大量的原始数据集中提取有用信息的方法。
文本挖掘是从不同的文本源中通过识别不同的模式和趋势来获得高质量信息的过程。由于传统的数据库有已知的、固定的结构,而文档是非结构化的或者半结构化的,文本挖掘比一般意义上的数据挖掘要困难得多[1,2]。故而,文本挖掘涉及到一系列的进行数据预处理和建模的步骤,以获得适用于结构化数据挖掘方法的数据[3]。文本挖掘可以节省大量的人力,通过利用信息检索、机器学习、信息理论以及概率统计等方法,可以解决诸如文档检索、文档归类、文档比较、提取关键信息、摘要文档等问题。
2 基本概念
自然语言处理(Natural Language Processing,NLP)是计算机科学、人工智能以及语言学结合的一门技术,处理机器和人类自然语言的交互[4]。要机器理解人类语言,就需要对人类对世界的认识进行一定形式的表达。文本挖掘就是利用自然语言处理和数据挖掘技术,试图发现新的未知的信息。文本挖掘存在的一个问题就在于,自然语言是用于人类间交流以及记录信息的,而计算机离理解自然语言有很大的差距。
聚类可以认为是非监督学习的最重要的一个问题,它要在没有标注的数据中找到一种结构。一个类别就是一组有相似特征的对象的集合,而与其它类中对象不相似。
动词相关的角色研究称为题元角色分析。一般来说,一个句子的语义结构可以通过动词参数结构(Verb Argument Structure)来辨别[5]。动词参数结构可以将文本表面的结构参数和其语义角色关联起来。
3 基于概念的挖掘模型
基于概念(concept-based)的挖掘模型在句子、文档以及文集级别分析句子的各个项目(item),可以高效地将句子中对于构成句子语义非重要的项目和包含了句子语义的概念区分开。采用该模型,可以通过句子的语义有效地识别出文档间重要的匹配概念。
模型分析句子和文档中每一个项目的语义结构而不是仅仅计算出其在一个文档中的出现频率。模型的输入为原始的文本文档,每个文档都定义好了句子边界。文档中的每个句子的每个项目都会被自动地贴上标注。贴上这些语义角色标注后,文档中的每个句子就会有一个或者更多的带标注的动词参数结构(Verb Argument Structure)。这些动词参数结构的数量完全取决于句子中的信息量。拥有多个带有参数的动词的句子,就会有多个带标注的动词参数结构。这些标注决定组成句子语义的项目在句子中的语义角色。句子中的每个项目有一个语义角色,即“概念”(concept)。概念可以是一个词,或一个短语,完全取决于句子的语义结构。当对一个新的文档进行分析的时候,该挖掘模型通过扫描新文档、提取出匹配的概念,可以检测出该文档中与之前处理过的所有文档相匹配的概念。
带标注的动词参数结构是语义角色标注的输出,会在句子、文档以及文集等级别分别进行分析。在该模型中,动词和其参数都认为是项目。一个项目可以视作同一个句子中的多个动词的参数。这就意味着,这些项目在一个句子中可能会有多个语义角色。
通过对文档进行NLP,可以获取其中的概念。例如,对于句子“张三打球”,动词是“打”,ARG0是“张三”,ARG1是“球”。这就贴上了语义标注。通过使用语义角色,就可以获得词在句子中的内容。
4 挖掘模型实现
模型分为以下四个部分:
(1)文本预处理
从文集中读出文档。根据每个句子中项目对应的动词数量,将这些参数标注为ARG0、ARG1、ARG2等。此外,降低文本的维度在进行文本挖掘时也很重要,即去除非必要词语,可以通过标准停止字列表实现:对每一个词进行检测,如果是一个停止字,如“的”、“地”、“得”、“啊”、“了”等,就认为其是非关键词并将其移除。
(2)概念识别
通过第一步,留下来带标注的待匹配的项目,每个项目就是一个概念。概念分析分三种:基于句子的概念分析,基于文档的概念分析以及基于文集的概念分析。通过基于句子的概念分析,获取概念项目频率(conceptual term frequency,ctf)。通过基于文档的概念分析,获取项目频率(term frequency,tf),即概念在原始文档中出现的次数。通过基于文集的概念分析,获取文档频率(document frequency,df),用于区别不同的文档。
(3)计算ctf
首先,计算出句子s中的ctf,即句子s的动词参数结构中概念c出现的次数。然后,计算文档d中概念c的ctf。在一个文档d中,对于每个概念c,在不同的句子中,可能有多个ctf,那么,文档d中概念c的ctf值就通过如下公式计算:
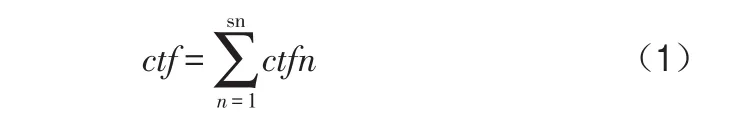
其中,sn为文档d中包含概念c的句子的总数,ctfn为第n个句子中概念c的ctf值。
(4)文档聚类
聚类就是将一组对象集进行分组,这样每组中的对象在某种意义上比其他组中的对象有更多的相似处。聚类是探测性数据挖掘的主要工作,统计分析的常用技术聚类算法有很多,这里采用层次聚类和k-最近邻聚类方法[6-8]。层次聚类是一种非递增贪婪聚类算法,用来将原始文档数据进行分层。K-最近邻是一种递增式的聚类算法,对于每个新文档,先算出和所有其它文档的相似度,然后选取最相近的k个文档,并将该新文档归入到这k个文档所属类中。
文档d1和d2相似度的计算见公式(2)和(3)。其中li1、li2分别为两个文档中动词参数结构中每个概念的长度,Lvi1、Lvi2为包含匹配概念的动词参数结构的长度,N为文档的总数。

通过公式(3)计算出文档d中概念i的基于概念的权值,其中tfweighti的值代表文档d中概念i在文档级别的权值,ctfweighti代表文档中概念i根据其在文档d中句子语义的组成在句子级别的权值。当概念i出现在少量的文档中时,log(N/dfi)补偿了其在文集级别的权值。tfweighti和ctfweighti的和准确表达了每个概念对句子语义的构成的重要性。通过公式(3)可以有效地区别文集中不同的文档。
随着匹配的概念的长度越接近其动词参数结构的长度,公式(2)的值会更高。因为该概念包含更多关于句子语义的信息。

在公式(4)中,对文档d中项目频率tfij矢量长度进行了标准化。cn是文档d中有项目频率的概念的总数。
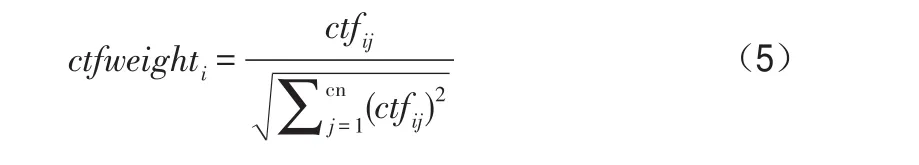
将模型应用于1000篇分别关于动物(350篇)、植物(370篇)、微生物(200篇)以及人文介绍(80篇)的文档集合中,得到实验结果如表1所示:

表1 实验结果
由于人文类别的文档中包含部分动物、植物相关信息,这三者之间有所混合,出现一定错误。而微生物类别比较突出,能完全识别。可见,该模型的聚类准确率高。
5 结语
文章将NLP和文本挖掘联系起来,提出了一个新的基于概念的挖掘模型。该模型可以改进文本聚类。通过利用文档中句子的语义结构,获得了更好的聚类结果。首先是基于句子的概念分析,通过ctf分析每个句子的语义结构来捕获句子中的概念;然后是基于文档的概念分析,利用tf分析文档层面的每个概念;再在文集层面,通过df进行文集层面的概念分析;最后,根据句子语义、文档主题以及文集中文档分类,计算基于概念的相似度。通过此方法,可以在文集中进行概念匹配、概念相似度计算。该方法可靠性、准确率高。通过此模型进行的文本聚类准确率大大超过了传统的基于单一项目的方法。该模型尚需进行完善,以便用于其他类型的文档聚类,如Web文档聚类。
参考文献:
[1]薛为民,陆玉昌.文本挖掘技术研究[J].北京联合大学学报(自然科学版),2005(04):59-63.
[2]谌志群,张国煊.文本挖掘研究进展[J].模式识别与人工智能,2005,18(01):65-74.
[3]谌志群,张国煊.文本挖掘与中文文本挖掘模型研究[J].情报科学,2007(07):1046-1051.
[4]李生.自然语言处理的研究与发展[J].燕山大学学报,2013,37(05):377-384.
[5]曹火群.题元角色:句法—语义接口研究[D].上海:上海外国语大学,2009.
[6]陈磊磊.不同距离测度的K-Me a n s文本聚类研究[J].软件,2015,36(01):56-61.
[7]奚雪峰,周国栋.面向自然语言处理的深度学习研究[J].自动化学报,2016,42(10):1445-1465.
[8]曹晓.文本聚类研究综述[J].情报探索,2016(01):131-134.
