多媒体情感标签标注中音频信号重要性分析
2018-05-08陈墨,郭雷
陈 墨,郭 雷
CHEN Mo,GUO Lei
西北工业大学 自动化学院,西安 710072
School ofAutomation,Northwestern Polytechincal University,Xi’an 710072,China
1 引言
情感计算被定义为“与情感有关、能够激起或者影响情感活动的相关计算”最早由Picard于1995年提出[1]。情感计算被认为是一种横跨计算机科学、心理学和认知科学的跨专业学科[2-3]。多媒体刺激的情感标签标注是情感计算的一个重要领域[3]。在该领域,研究者们的工作主要可以分为两类。其中一类,研究者们通过直接分析刺激的音视频内容确定对应刺激的情感标签,这类研究可被称为外显式情感标注。研究者通过分析该刺激所引起的被试的响应确定多媒体刺激唤起的情感类型属于另一类方法,这类研究也可被称为内隐式情感标签标注,使用的生理信号包括脑电图、外周生理信号、面部表情等[4]。
本文作者Chen等[5]提出了一个新的进行情感标签标注的架构。在这个架构中,作者引进了大脑编解码的概念以解决内隐式情感计算中生理信号采集成本高时间长、可用数量少的问题,其中该工作使用的大脑编码思想也被其他文献采用[6-7]。基于文献[5]提出的框架,多媒体刺激缺失的生理响应特征可以由此补全,并进一步充分利用视频刺激和大脑响应两方面的信息从而提高多媒体情感标签标注的准确性。
但该大脑编解码框架[5]主要关注点是通过大脑编码补全缺失模态提升情感标签标注的总体性能,对其中各因素对最终性能的影响并未进行分析。而在外显式情感标注和内隐式情感标注中,研究者们都分析了音频信号在唤起被试情感的过程中所起的作用。在外显式情感标签标注文献[8]中,作者强调了音频特征的重要性,认为与视频信号相比,音频信号与刺激的情感类型的相关性较高的。此外有部分情感标签标注工作着重于单独分析音频信号的作用[9-10]。但以上两个工作仅使用音频信号作为刺激,并没有与视频信号对照分析。因此讨论音频信号在该框架下对多媒体情感标签标注的重要性就成为一个有意义的研究主题。
为分析音频信号对文献[5]中提出的多媒体刺激情感标签标注框架性能的影响,本文提出在该框架下固定框架内其他可变因素,如大脑特征模板、进行大脑编码的回归器、模态融合和分类器等,分别仅使用视频特征进行情感标注和联合使用音视频特征进行同样任务,并通过对比以上两者之间准确率的差异分析音频信号在该框架下对情感标签标注的重要性。
本文其余部分组织如下:首先在第2章研究方法中本文描述了文中工作的框架和细节。在第3章实验设计与实验结果中本文描述了实验的具体步骤,包括使用的基准数据库和脑电信号预处理等,并按照2.6节情感标签辨识中的描述的情感标签辨识标注方法对多媒体刺激进行标注给出其准确率结果。最后本文在第4章结束语中讨论了音频信号对文献[5]提出框架下的情感标签标注性能的影响和未来该方向的可能扩展工作。
2 研究方法
2.1 工作总体描述
本文称直接从多媒体刺激上提取的视频特征和音频特征为底层特征,称从被试脑电信号提取的特征为高级特征。本文使用文献[5]提出的架构,针对具有被试响应的多媒体刺激首先提取其底层特征和高级特征,之后使用这两种特征训练大脑编码模型;针对没有被试响应的多媒体视频,则首先提取其底层特征并使用底层特征,再结合训练获得的大脑编码模型预测与该视频对应的高层特征。在完成测试视频的高层特征预测步骤之后,将所有视频的底层特征与高层特征进行特征融合获得融合特征,最后使用融合特征进行多媒体刺激的情感标签标注。
2.2 底层特征提取
本文底层特征包括所述一种音频特征与三种视频特征。本节中所述底层特征在后续章节中生成两类六组用于大脑编码模型训练、脑电响应补全和特征融合生成融合特征。
2.2.1 音频特征提取
为提取多媒体刺激的音频特征,本文通过音视频分离工具从多媒体刺激中分离出音频信号。对分离后的原始音频信号首先进行降采样操作,其采样率由44 100 Hz降至22 050 Hz,降采样后双声道信号转换为单声道信号。
本文按照已有文献[5,11]中相关内容,提取了单声道音频信号的平均能量和5 500 Hz以下的谐波分量。本文还提取了Mel-frequency类特征。Mel-frequency方法由Mermelstein[12]于1976年提出,并被应用于语音分析等文献[5,13]。为提取特征,本文使用MIRToolbox工具箱[14]提取音频信号的Mel-frequency特征,其中包括MFC coefficients、derivative of MFC coefficients、autocorrelation of MFC coefficients、spectral flux、delta spectrum magnitude、band energy ratio、spectral centroid、pitch、zero cross rate、zero cross rate standard deviation和silence ratio等。
2.2.2 视频特征提取
本文共提取三类视频特征,分别使用DEAP[11]、ImageNet[15]和SentiBank[16]工作中所描述方法进行提取。
DEAP特征是Keolstra等。在2012年发表工作[11]使用的一系列视频特征的集合,由一组基于关键帧的特征和基于连续帧的特征构成。为提取该类视频特征,本文首先将视频转换为MPEG-1编码,之后提取视频的所有I-Frame以便进一步提取视频特征。
本文在每个视频的I-Frame上提取了key lighting、colorvariance、median luminance、histogram ofhue and histogram of values等特征,之后计算所有I-frame帧特征的均值,其结果作为该视频的对应特征值使用。
本文在每个视频上提取了grayness、fast motion、visual excitement、shot change rate 和 stand variation of shot durations等基于视频内容的特征。
本文使用的ImageNet特征是基于Baveye等于2015年提出的一个基于卷积神经网络(Convolutional Neural Network,CNN)的视频情感标注方法[15]使用的基于帧内容的特征。本文采用视频关键帧集合对视频整体进行描述的思路,使用预先训练完毕的ImageNet模型提取每个关键帧的ImageNet特征,最后计算所有关键帧的ImageNet特征的均值被作为该视频的ImageNet视频特征。
与视频ImageNet特征提取类似,对SentiBank的视频特征提取也基于对应视频的关键帧进行。本文首先提取了每个视频的关键帧,利用其预先训练完毕的DeepSentiBank模型对每个关键帧提取SentiBank特征,所有关键帧的SentiBank特征的均值被视为该视频的SentiBank特征。
2.3 脑电信号特征提取
本文使用功率谱密度(Power Spectral Density,PSD)特征来表征被试在观看多媒体刺激时的大脑做出对应响应的EEG信号。
信号f()
t功率谱密度可以按照如下公式计算:
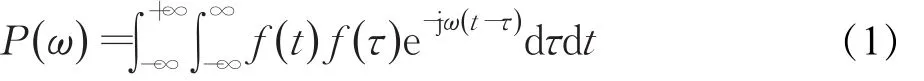
脑电PSD特征可依据信号来源分为两类。本文在单通道EEG信号上计算了 θ(4~8 Hz),慢 α(8~10 Hz),快 α(10~12 Hz),β(12~30 Hz)和 γ(30~47 Hz)共5个波段上的PSD特征。在对称电极的EEG差值信号上,本文计算了 θ(4~8 Hz),α(8~12 Hz),β(12~30 Hz)和γ(30~47 Hz)共4个波段上的PSD特征。
为便于使用计算机进行计算,在实际计算中本文采用Welch方法[17]计算两类脑电信号的PSD特征。
由于并非所有的脑电PSD特征都具有辨识多媒体刺激的情感标签的能力,本文在完成脑电信号 PSD特征提取后使用Fisher Linear Discriminant对脑电特征进行选择。其计算公式如下:其中μ1i和μ2i分别代表属于两类样本的第i维特征的均值,和代表其对应的方差。给定阈值θ后,在特征选择结果中仅保留满足Ji≥θ的对应特征。

2.4 大脑编码模型和脑电特征预测
大脑编码原理可由下式进行一般性描述[5]:

其中Y和X分别为高层特征和底层特征,在本文中为脑电PSD特征和音视频特征,本文假设σ为白噪声。
本文采用支持向量回归器[18]作为大脑编码工具,使用同时具有底层特征与脑电特征的样本进行训练以获取从底层特征影射至脑电特征的大脑编码模型 f。在取得大脑编码模型 f后,以没有对应脑电信号的多媒体视频刺激的底层特征为输入,通过大脑编码模型取得这些视频可能唤起的脑电PSD特征。
2.5 特征融合
本文采用Guo等提出的多视角模态特征融合方法[19]。该方法具有能够自动选择模态权重的优点。原始文献[19]中的参数n代表聚类数量,本文中用n确定融合特征的维数,与文献[5]相同。
2.6 情感标签辨识
本文采用机器学习方法中的支持向量机(Support Vector Machine,SVM)对多媒体视频刺激的情感标签进行辨识,其具体实现为libSVM[20]。
3 实验设计与实验结果
3.1 实验设计
本文采用DEAP数据库[11]作为测试基准。该数据库拥有120段视频,每段视频长度为60 s。其中的40段视频具有对应的生理响应信号,作者一共采集了32个被试的生理响应信号。这40段视频被作为训练集,用于训练大脑编码模型和情感标签标注分类器。其余的80段视频用于性能测试。
本文按照2.2节底层特征提取中所述方法对所有的多媒体视频刺激提取其音频特征和视频特征。
DEAP数据库中脑电信号的原始采样频率为512 Hz,在预处理中首先将脑电信号降采样至128 Hz,之后移除伪迹以进行后续操作。
在完成脑电信号特征提取步骤后,本文按照文献[5]中的方案对每个被试进行留一法情感标签标注测试。以分类准确率为指标,最高标注准确率对应的被试及其特征选择阈值所给出的脑电特征被用作大脑编码模型训练的脑电特征模板。
为分析音频信号对最终结果的影响,实验中共使用两组共六类底层特征,其中一组只使用视频特征如DEAP、ImageNet和SentiBank,使用此类特征的准确率被用作比较基准;另一组使用联合底层特征如DEAP+音频、ImageNet+音频和SentiBank+音频,其结果与基准进行比较计算由于加入音频特征引起的性能改变。
根据第2章研究方法所述,本文首先使用训练集的一种底层特征和对应的脑电特征模板训练大脑编码模型,之后在此基础上使用测试集上的同种底层特征和训练好的大脑编码模型预测测试集视频对应的脑电PSD特征。在特征融合步骤中,训练集和测试集的底层特征与脑电PSD特征进行多模态融合获取融合特征。在情感标签辨识步骤中,本文首先将融合特征进行分离重新分为训练集和测试集,之后使用SVM对测试集的情感标签进行辨识并测量辨识性能。其结果在3.2节实验结果中予以阐述。
3.2 实验结果
实验结果如表1和表2所示。两表中视频特征指底层特征仅使用对应列所指的视频特征类型,联合特征指底层特征使用对应列所指视频特征类型+音频特征。表中以粗体显示较高的结果。
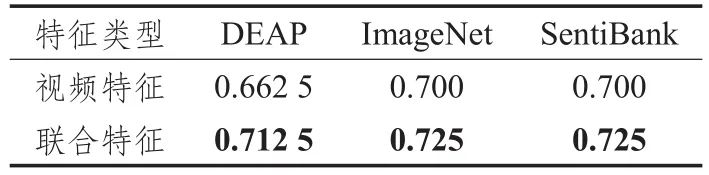
表1 Valence水平标注结果
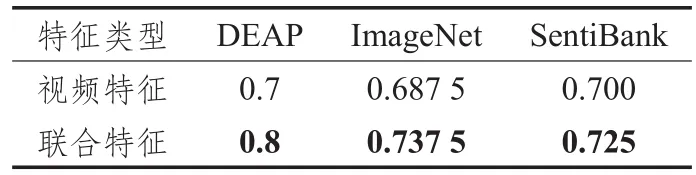
表2 Arousal水平标注结果
从表格所示结果可以看出,对所有三种视频特征,在增加音频特征后按照文献[5]进行的情感标签标注的准确性均有不同程度的提高。音频特征对valence水平情感标签标注的贡献分别为0.05(DEAP)、0.025(Image Net)和 0.025(SentiBank),对 arousal情感水平标签标注准确率提升的贡献分别为0.1(DEAP)、0.05(ImageNet)和0.025(SentiBank)。
通过以上比对可以推论,在框架[5]下,增加音频特征可以提高该框架对情感标签标注的性能。
4 结束语
本文对基于大脑编解码框架下[5]音频信号对情感标签标注性能的影响进行了分析。通过比对同类视频特征在是否联合使用音频特征情况下最终分类准确率,本文推论在控制框架内其他因素的条件下,增加音频特征可以提高该框架的标注性能,且未出现因特征维数增加导致性能下降的情况。未来可将本工作的应用范围由DEAP数据库扩展至其他情感计算数据库,实现跨数据库的训练-标注应用。
参考文献:
[1]Picard R W.Affective computing,Technical Report 321[R].Cambridge,MA,USA:M I T Media Laboratory Perceptual Computing Section,1995.
[2]Tao J,Tan T.Affective computing:A review[M]//Affective Computing and Intelligent Interaction.Berlin Heidelberg:Springer,2005:981-995.
[3]Chen M,Han J,Guo L,et al.Identifying valence and arousal levels via connectivity between EEG channels[C]//International Conference on Affective Computing and Intelligent Interaction,Xi’an,Shaanxi,China,2015:63-69.
[4]Karyotis C,Doctor F,Iqbal R,et al.A fuzzy modelling approach of emotion for affective computing systems[C]//The First International Conference on Internet of Things and Big Data,Special Session,Recent Advancement in Internet of Things,Big Data and Security(RAIBS),2016.
[5]Chen M,Cheng G,Guo L.Identifying affective levels on music video via completing the missing modality[J].Multimedia Tools&Applications,2017(3):1-16.
[6]Yin Z,Zhao M,Wang Y,et al.Recognition of emotions using multimodal physiological signals and an ensemble deep learning model[J].Comput Methods Programs Biomed,2017,140:93-110.
[7]Han J,Zhang D,Wen S,et al.Two-stage learning to predict human eye fixations via SDAEs[J].IEEE Transactions on Cybernetics,2016,46:487-498.
[8]Wang H L,Cheong L F.Affective understanding in film[J].IEEE Transactions on Circuits and Systems for Video Technology,2006,16:689-704.
[9]Argstatter H.Perception of basic emotions in music:Culture-specific or multicultural?[J].Psychology of Music,2015,44:674-690.
[10]Naji M,Firoozabadi M,Azadfallah P.Emotion classification during music listening from forehead biosignals[J].Signal Image&Video Processing,2015,9(6):1365-1375.
[11]Koelstra S,Muhl C,Soleymani M,et al.DEAP:A database for emotion analysis using physiological signals[J].IEEE Transactions on Affective Computing,2012,3:18-31.
[12]Mermelstein P.Distance measures for speech recognition,psychological and instrumental[J].Pattern Recognition and Artificial Intelligence,1976,116:374-388.
[13]Ganchev T,Fakotakis N,Kokkinakis G.Comparative evaluation of various MFCC implementations on the speaker verification task[C]//Proceedings of the SPECOM,2015:191-194.
[14]Lartillot O,Toiviainen P,Eerola T.A matlab toolbox for music information retrieval[C]//Preisach C,Burkhardt H,Schmidt-Thieme L,et al.Proceedings of the 31st Annual Conference of the Data Analysis,Machine Learning and Applications,Gesellschaft für Klassifikation eV,Albert-Ludwigs-Universität Freiburg,March 7-9,2007.Berlin Heidelberg:Springer,2008:261-268.
[15]Baveye Y,DellandréA E,Chamaret C,et al.Deep learning vs.kernel methods:Performance for emotion prediction in videos[C]//2015 International Conference on Affective Computing and Intelligent Interaction(ACII),Xi’an Shaanxi,China,2015:77-83.
[16]Chen T,Borth D,Darrell T,et al.DeepSentiBank:Visual sentiment concept classification with deep convolutional neural networks[J/OL].Computer Science,2014(2014-10-30)[2017-12-28].http://adsabs.harvard.edu/abs/2014arX-iv1410.8586C.
[17]Welch P D.The use of fast Fourier transform for the estimation of power spectra:A method based on time averaging over short,modified periodograms[J].IEEE Transactions on Audio and Electroacoustics,1967,15:70-73.
[18]Smola A,Vapnik V.Support vector regression machines[J].Advances in Neural Information Processing Systems,1997,9:155-161.
[19]Guo D,Zhang J,Liu X,et al.Multiple kernel learning based multi-view spectral clustering[C]//International Conference on Pattern Recognition,2014:3774-3779.
[20]Chang C C,Lin C J.LIBSVM:A library for support vector machines[J].ACM Trans Intell Syst Technol,2011,2:1-27.
