基于深度层级特征的中国传统视觉文化符号识别及应用
2018-05-08吴晓雨张愉谭笑杨磊
吴晓雨,张愉,谭笑,杨磊
(中国传媒大学 信息工程学院,北京100024)
1 引言
本课题的研究内容来源于国家科技支撑计划课题《区域公共文化云服务平台关键技术研究》,主要研究区域公共文化云服务平台的关键技术,在此基础上形成区域公共文化网络平台上支持各种服务模式及相关业务的技术解决方案。本课题主要负责基于图像识别的线上线下互动技术的研究与实现,旨在完成对典型视觉文化符号的特征量分析,抽象特征提取和识别,服务于视觉文化符号新型展示和推广应用。这一课题的研究,有助于加快中国传统视觉文化领域的研究速度,与时俱进,推动我国传统文化的数字化进程,以便达到更高的研究水平。
目前,计算机技术在中国传统视觉文化符号大类之间的识别研究还是空白,且依靠于深度学习卷积神经网络来识别传统文化符号的研究还很少见,所以将深度学习卷积神经网络应用在中国传统视觉文化符号的研究中,并建立相应的识别系统的工作需要我们快速推进。
2 基于浅层学习的视觉文化符号识别
我们先从简单的分类任务入手,利用浅层学习中多特征融合的方法来解决分类问题,结果显示在提取轮廓特征、颜色特征及SIFT特征并结合空间金字塔的思想,将融合后的多特征送入SVM中训练并测试,效果最好。
基于空间语义信息的多特征融合和SVM对中国传统视觉文化符号进行识别,总体框架如图1。
主要根据局部特征和全局特征的优势互补性,将几种特征结合在一起形成多特征,我们分析了几种特征组合的识别结果,即SIFT+RGB,SIFT+RGB+LBP,SIFT+HOG+RGB等,其中在SIFT特征提取过程中,我们引用了词包模型和空间金字塔的思想[1],使得提取到的特征具有空间语义信息。同时,根据对视觉文化符号的特征分析,我们在提取SIFT特征的基础上,又加入了轮廓特征和颜色特征等,并将以上几种特征融合,将融合后的特征作为图像的具有空间语义信息的特征表达。并用核函数为的SVM作为文化符号的分类器来将文化符号分类。实验中,使用的数据是从视觉文化符号数据集中抽取的典型的8类符号作为数据集A,实验证明,基于浅层学习的中国传统视觉文化符号识别算法中,最有效的识别算法组合是含有空间位置信息的SIFT、HOG和RGB融合的多特征,并结合核函数为的SVM作为分类器,识别的平均F-值在97.5%左右。但考虑到实际生活中识别系统的拒识能力和泛化能力,我们对正样本进行了数据扩充并加入了负样本,此时数据集A变为数据集A+,也就是在数据集A+上再次使用前面的方法进行实验,实验结果如表1所示。从表1中,可以发现,当识别任务变复杂后,准召率明显下降,F-值降低了约6个百分点,对实验结果进行错误分析后,我们觉得在分类任务变复杂后,使用浅层学习的SIFT+HOG+RGB(SPM)方法并不能够很好地完成分类任务。这就说明浅层学习在处理复杂的分类任务上,效果并不理想,所以我们对于这一问题的解决还需要进一步研究。

图1 基于空间语义信息的多特征融合和SVM的视觉文化符号识别总体框架

类标签准确率.(%)召回率.(%)F-measure.(%)数据集A数据集A+数据集A数据集A+数据集A数据集A+00.94200.84961.00000.92270.97010.914311.00000.94620.98520.95050.99260.961420.95980.92890.97950.94970.96950.9609

续表
3 基于深度学习的视觉文化符号识别
为了克服现有技术的不足,我们在本部分先使用深度学习中卷积神经网络来解决这个问题。实验中我们在Caffe框架[2]上使用网络Alexnet[3],为了使网络有一个好的初始化,加快网络收敛,我们在已有的模型上finetuning[4]。同时使用GPU加速训练。并选取数据集A+进行实验,将实验结果与第2部分提到的基于浅层学习中识别性能最好的方法做比较。实验结果如表2所示,从表2的实验结果中可以发现基于深度学习的识别效果要比浅层学习好,使用Alexnet网络进行实验的效果比较理想。最后为了验证识别系统的识别性能,我们又选用了较为复杂的数据集B+做验证,实验证实了我们得出的结论,也就是使用Alexnet网络处理较为复杂的分类任务,效果最好,实验结果如表3所示。除此之外我们也经过实验验证了对数据进行手动扩充和虚拟扩充后训练出的模型更具有泛化能力,并且关于负样本个数的问题,我们经过实验验证发现当负样本和正样本总量相当的情况下,对识别系统的拒识能力越有利。在降维的实验中,我们发现降维可以有效地减少噪声,去掉冗余特征,提升识别性能,实验结果显示,当特征降到256维时,识别系统的识别性能最好。
之后,我们又提出了基于深度层级特征和SVM结合的中国传统视觉文化符号识别的方法,总体框如图2所示。基于深度层级特征和SVM结合的中国传统视觉文化符号识别方法,首先将数据集转化为lmdb格式送入到深度学习卷积神经网络中训练分类模型;其次在训练好的模型中提取全连接层fc6和fc7的视觉文化符号特征,将提取到的两层的特征合并成一个长向量;最后,将该向量作为每一类图像的图像特征表达送入到浅层学习SVM中进行分类。

图2 基于深度层级特征的视觉文化符号识别技术总体框架
提出该方法的理论依据是因为卷积神经网络的网络结构效仿了人脑视觉机制,能够自行地从原始图像中学习到具有普适性的深层特征。并且基于上面提到的传统网络中Softmax的缺点考虑到SVM不用计算代价函数,这样的话就省略了参数更新的过程,使得收敛速度更快。并且SVM最大的优势就是抗噪声的能力,以及可以采用核函数进行维度变化,将线性不可分的低维特征通过映射变到高维空间上进行分类,它是基于结构风险最小化理论在特征空间中建构最优分割超平面,使得学习达到全局最优[5]。考虑到卷积神经网络可以学习到良好的特征,而传统分类器SVM又具有优越的分类性能,所以我们利用两者的优势互补性将卷积神经网络和传统分类器相结合,把卷积神经网络看作为特征提取器,提取深度层级特征,再使用SVM进行训练和分类来获取最好的分类性能。
实验中我们用到的网络是Alexnet,为了提升训练速度我们使用GPU并且在别人已经训练好的成熟模型上finetuning。模型训练好后,提取最后两层特征,并将两层特征结合并做降维处理,将此作为深度层级特征。最后将深度层级特征送入核函数不同的SVM中进行训练与测试。实验结果显示如表2和表3,通过据集A+和B+的实验结果显示,将传统神经网络Alexnet中提取到的深度层级特征与核函数为直方图交叉核的SVM结合使用,识别性能最好。

表2 数据集A+:各类别识别性能比较
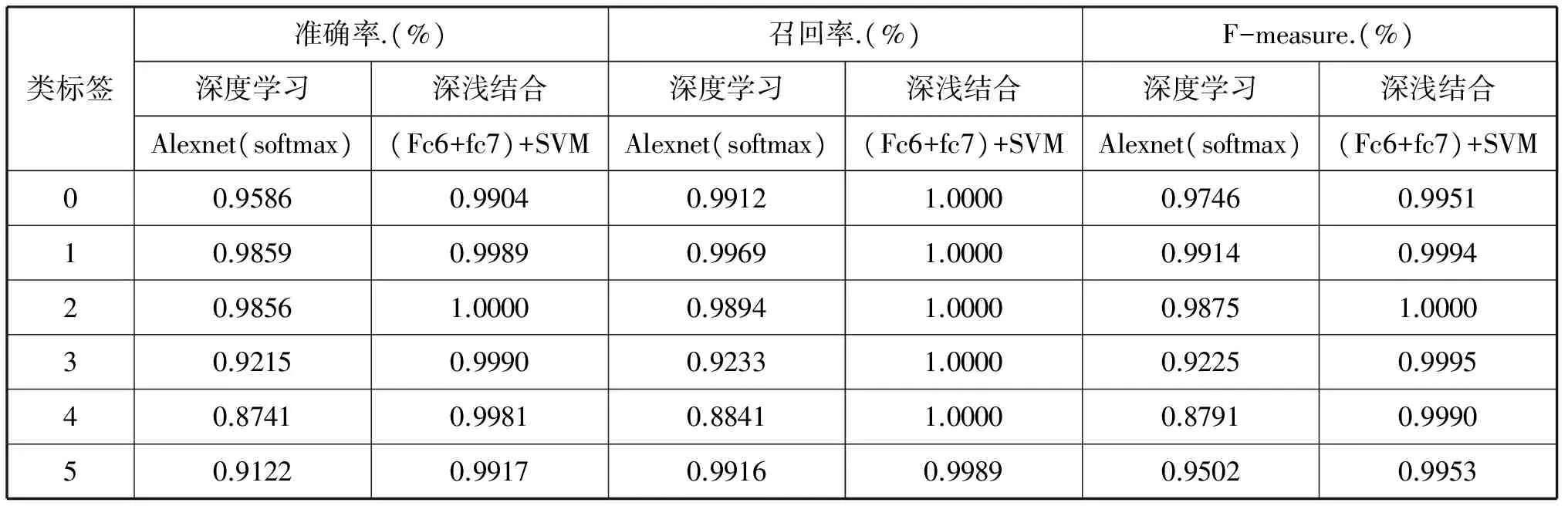
表3 数据集B+:各类别识别性能比较

续表
4 基于展品识别的线上线下互联系统研发
由于本项目最终是服务于博物馆、艺术馆等文化场馆中,为了方便游客更好地了解中国传统视觉文化,实现文物信息的数字化。我们将上述研究成果做成手机APP,该APP的主要作用是,当游客在参观博物馆时,如果对某件展品感兴趣想了解该展品的相关信息以及展品背后的故事,可以使用该APP对展品进行拍照,然后APP获取数据后通过HTTP协议,传送到云服务器端进行特征提取,及识别,最后将相应的展品信息及相关数据返回到客户端。这样游客在欣赏展品的同时,也可以获取到公共文化知识进而可以促进公共文化的传播;或者游客可以将展品拍下保存在本地相册,当想了解某件展品时,再通过APP获取相应的信息。如此一来人们可不受时间和空间的局限,随时随地获取公共文化云服务信息、享受公共文化服务资源,使公共文化真正成为公民“身边的文化”,不仅有利于公民自身知识的拓展,也有利于中国传统视觉文化的传播。
我们先从客户端获取所要识别的图像,然后在服务器端(云端)调用提取特征的脚本以获取该图像的特征,其实主要是将图像送入到指定的卷积神经网络中,提取fc6和fc7层的特征,作为该图像的特征表达。其中fc6层的特征维数是4096,fc7层特征经过降维降256维,这样得到的结果应该是一个维度为4096+256的长向量,然后将该向量送入到已加载模型的SVM中,得到测试结果,最后将测试结果返回给客户端。依靠“云到端”的图像识别完成线上线下的互联。实验显示,当对感兴趣展品进行拍照上传后,服务器端可以精准地识别,从图像上传到展品信息被反馈到客户端,所用时间不超过1.5s。成品展示说明如下:
(1)当识别50类中的瓷器展品时,会显示瓷器的相关介绍,如图3所示。

图3 识别50类中的展品示例
(2)当识别非以上50类的瓷器,或者其他非瓷器的物品时,会显示“检测范围之外”如图4所示。
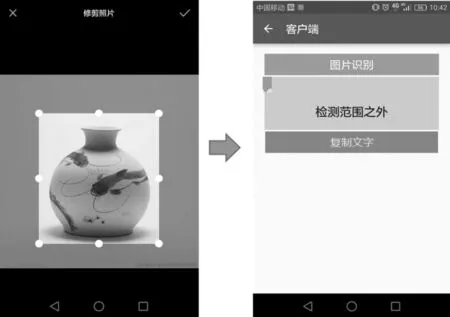
图4 识别非50类中的展品识别示例
基于文化展品识别的线上线下连接系统研发。主要是提到了博物馆中文化展品的采集以及利用第四部分提到的识别技术对采集到的数据进行训练和识别,完成客户端到云服务器端的交互,也就是面向智能终端完成基于展品识别的线上线下互联。
5 结论
中国传统视觉文化符号识别的核心技术就是图像识别,针对图像识别技术而言传统的方法主要是基于浅层学习或者深度学习来进行识别,本论文在第二、三部分分别使用了浅层学习和深度学习对视觉文化符号进行识别,并在此基础上提出第四部分的算法,然后在第五部分实际应用中使用第四部分的算法对文化展品进行识别,完成“云—端”的线上线下的交互。将计算机技术与中国传统视觉文化相结合,不仅有利于中国传统视觉文化的传播,而且对于计算机技术在中国传统视觉文化上的应用也起到了推动作用。在基于展品识别的线上线下互联技术中,我们使用基于深度层级特征的识别方法,实验显示使用该方法可以准确高效地完成识别任务。从实验和实践上都证明了所提方法的可行性与可靠性。同时识别系统搭建简单,识别算法具备完全自动化、结果准确的特性。
[1]Lazebnik S,Schmid C,Ponce J.Beyond Bags of Features:Spatial Pyramid Matching for Recognizing Natural Scene Categories[C].Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on IEEE,2006.2169-2178.
[2]http://caffe.berkeleyvision.org/.
[3]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[C].International Conference on Neural Information Processing Systems,Curran Associates Inc,2012.1097-1105.
[4]Yanai K,Kawano Y.Food image recognition using deep convolutional network with pre-training and fine-tuning[C].Multimedia & Expo Workshops(ICMEW),2015 IEEE International Conference on,IEEE,2015.1-6.
[5]Vapnik VN.The nature of statistical learning theory(statistics for engi- neering and information science)[M].New York,NY:Springer- Verlag,1999.
