基于大数据技术的日志分析体系结构的研究
2018-05-07张建东
张建东
(乐山师范学院计算机科学学院,乐山 614000)
0 引言
随着网络应用的爆发式增长,以及用户使用量的增加,网络流量增长越来越快,这也导致日志数据的爆炸式增长,如何更好地分析日志数据,并从中找出用户的行为模式,以及发现用户的异常模式以便更好地为用户服务,同时找出网络异常方便管理员对网络进行维护升级和发现安全隐患,成了一个亟待解决的问题。大数据指的是无法在规定时间内用现有的常规软件工具进行收集、存储和处理的数据集合,通常指10TB以上规模数据。大数据技术是能突破常规软件限制,对大数据进行收集、存储和处理技术的统称。大数据的主要特征有:数据体量巨大,数据类型繁多,价值密度低,处理速度快。从以上分析可以看到目前的网络日志数据满足大数据的特征。
当日志数据量比较小的时候,主要是采用单机进行数据分析,随着数据的增长,单机分析日益不能满足要求。目前常用的日志分析方法有ELK日志分析平台,ELK 是由 ElasticSearch、Logstash、Kibana组成的开源日志处理平台解决方案。ELK能实现日志收集,存储,统计分析并使用Web页面显示等功能,可以起到实时系统监测、网络安全事件管理等功能[1]。但是ELK提供的分析技术相对较简单,还需要设计辅助程序来满足特定系统和环境的分析要求。Chukwa是Hadoop项目中开源的分布式系统数据收集和分析工具,包含了包括数据收集、重组、分析和展示的完整流程,但是Chukwa不能应用于所有的数据分析场景。传统的日志分析技术不能满足具有大数据特征的海量网络日志数据的处理[2],将大数据分析技术用于日志分析是目前研究的热点。
1 大数据分析体系结构
数据分析的步骤:
(1)明确分析的目的和分析思路。
(2)收集数据,根据分析的目的来收集不同数据源的数据。
(3)存储数据,对海量数据可以使用Hadoop的HDFS存储系统。
(4)对数据进行处理,包括数据预处理、数据清洗,数据转换等。
(5)数据计算。分析逻辑的实现,常用的计算技术MapReduce、Spark、Storm 等。
(6)展示结果,包括Web展示,撰写报告等。
图1为数据分析的主要步骤。
数据分析的主要内容包括三个方面:
(1)现状:过去发生了什么,通过历史数据的统计可以实现。
(2)原因:某一现象为什么发生,这部分要结合具体的业务来分析。
(3)预测:预测将来会发生什么。
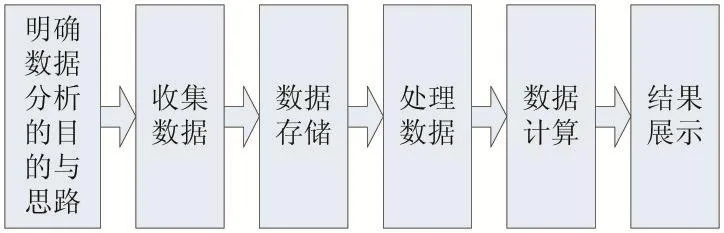
图1 数据分析的主要步骤
当数据海量增长的时候,单机处理能力已经不能满足需求,就需要用集群技术来解决。在Hadoop出现之前,海量数据存储和分析都非常困难。只有少数公司掌握着高效的分布式计算、分布式存储的核心技术[3]。Hadoop是一个提供可伸缩、可信赖的分布式计算的开源项目,支持Google的MapReduce编程模型,能够将作业分割成许多小的任务,并将这些任务放到任何集群节点上执行,用户可以在不了解分布式系统底层细节的情况下,开发分布式应用程序,实现大规模分布式并行计算、存储和管理海量数据。Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)、MapReduce计算框架和分布式资源调度框架YARN。HDFS对海量数据提供高可靠性、高容错性、高可扩展性、高吞吐的存储方案。MapReduce是一种用来处理海量数据的并行编程模型和计算框架,用于对大规模数据集进行并行计算。
数据分析分为实时数据分析和离线数据分析,实时数据分析在金融,电子商务等领域的使用较多,往往要求在数秒内返回上亿行数据的分析结果,从而达到不影响用户体验的目的。对时间没有那么敏感的数据分析任务,如数据挖掘、搜索引擎索引计算、推荐系统、机器学习等场景,往往需要对海量数据做复杂的多维度的计算,这些计算所需要的时间较长,常常是几小时甚至几天,对这种类型的数据分析任务,可以采用离线数据分析的方式[4]。
日志分析采用最多的处理技术是离线数据处理方式。图2是离线大数据技术分析步骤。
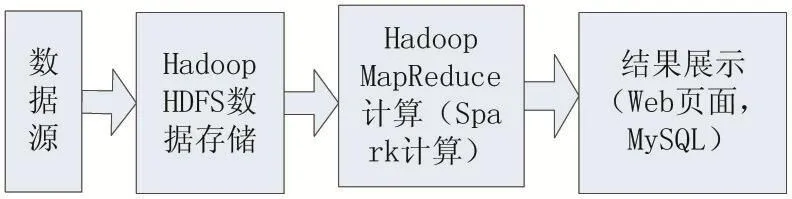
图2 离线大数据技术分析步骤
有部分应用需要实时分析产生的数据,可以采用流式大数据分析技术,图3是流式大数据技术分析步骤。Flume用来获取数据;Kafka用来临时保存数据;Strom用来计算数据;Redis是个内存数据库,用来保存数据。

图3 流式大数据技术分析步骤
2 大数据技术在日志分析中的应用
2.1 日志分析的体系结构
日志就是按照一定的规则将操作系统、应用程序、网络设备中发生的事件记录下来,日志已成为系统管理中不可或缺的工具。日志的主要应用主要表现在一下几方面:对用户行为进行审计,监控恶意行为,对入侵行为的检测,系统资源的监控,帮助恢复系统,评估造成的损失,计算机犯罪的取证,生成调查报告等。
由于日志不仅数据海量,格式和存储方式不统一,而且不同类型的日志间相互联系,使得对日志的分析变得更加困难。如果网络管理员能了解日志的含义,知道如何分析和使用日志,那么日志用于网络安全管理和决策支持的价值将无法估量。
根据不同的应用场景,日志的分析可以分为离线分析和实时分析,图4给出了日志分析的体系结构。体系结构主要包括三个部分:日志的收集和预处理;日志数据的存储;日志的分析、展示和使用[5]。
2.2 基于大数据技术的日志分析方法
(1)离线分析日志文件:
为了对日志进行深度的数据分析和挖掘,以及对一些后台操作记录进行追溯,需要对海量的日志信息进行持久化存储,Apache的Hadoop项目提供了解决方案,并在数据持久化存储和分析中得到了广泛的应用。对不需要进行实时分析的海量数据,可以将其保存在分布式文件系统HDFS上,然后通过MapReduce或者Hive SQL进行数据分析和挖掘,对需要进行实时展示的内容,则可以将其保存在HBase上,HBase是高可靠、高性能、可伸缩的列式存储系统,支持数据表的自动分区,避免了传统关系型数据库单表容量的局限性,能支持海量数据的存储。离线日志分析的特征是:批量获取数据、批量传输数据、周期性批量计算数据、数据展示。
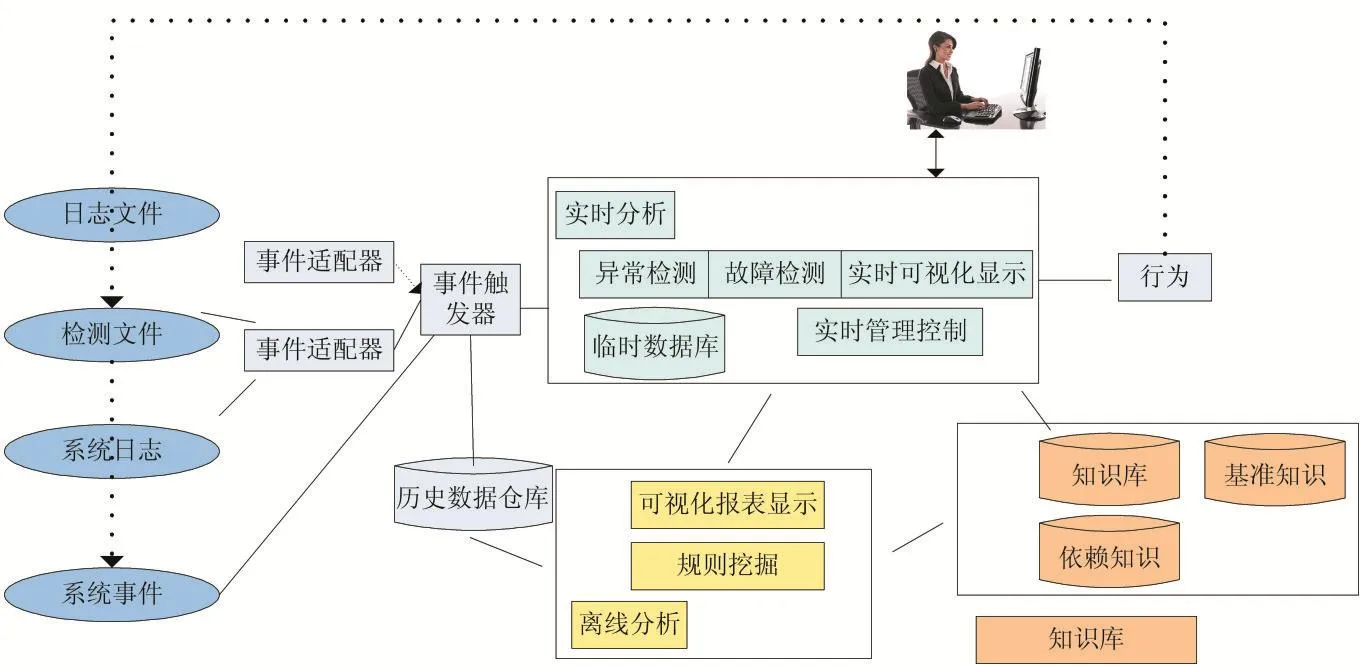
图4 日志分析体系结构
常用的日志分析方法有关联分析、序列分析、聚类分析[6]。
关联分析又称关联挖掘,用于发现存在于数据集中的频繁模式、关联、相关性或因果结构,从而描述一个事物中某些属性同时出现的规律和模式。计算机系统多种日志之间存在着隐蔽的关联,通过关联分析可以找出不同日志间关联的事件,典型的应用是可以进行系统故障的溯源。常用的关联分析算法有Apriori算法、LIG算法、FP算法等,其中Apriori算法最为经典,众多算法均给予该算法改进。文献[7]中分析了使用Apriori算法挖掘用户频繁访问页面在Hadoop上的应用。
序列分析:关联分析是在忽略事物间在时间维度上的关系的前提下发现同一事物中的项之间存在的某种联系。然而在日志分析中某一系统故障可能是另一系统故障的引发的,网络入侵事件也具有相似的特征,因此事件发生的时间也非常重要。研究者经常利用时间对日志进行关联以完成日志的序列分析,来达到网络攻击的预测及防范、系统故障的溯源等。
聚类分析是把数据划分为有意义的组或簇,目标是同一组对象间的相似度最大,不同组中对象间的相似度最小。聚类分析是数据分析的一种重要技术,应用十分广泛。聚类分析是数据分析的起点,对划分成组的日志数据还要进一步结合具体的应用进行分析。
要深度分析日志数据,可以把文本日志转换为离散的结构化的事件,然后进行日志依赖性挖掘,根据事件的依赖关系对系统故障进行溯源[8-9]。
(2)实时日志分析技术
流式数据的特征是数据会源源不断地从各个地方汇集过来,来源众多,格式复杂,且数据量巨大。对于流式数据的处理,有这样的一种观点,数据的价值随着时间的流逝而降低,因此数据生成后要尽快处理,而不是等到数据累积后再定期地进行处理。这样,对应的数据处理工具必须具备高性能、实时性、分布式和易用性等特征。对于流式数据的处理,更多关心的是数据的整体价值,而非数据的局部特征。在很多应用中需要分析实时日志数据,比如实时分析线上应用的负载、网络流量、磁盘I/O等系统信息,异常日志的检测。
流式计算的特征是:数据实时产生、数据实时传输、数据实时计算、实时展示。实时日志分析中需要多个大数据分析工具:Flume实时获取数据,Kafka实时数据存储,Storm实时数据计算,Redis实时结果缓存,MySQL实现持久化存储。将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果,用来支持实时决策。
Flume作为数据传输工具获取新增加的日志,并把新增的数据传输到指定的位置。Storm是Twitter公司开源的分布式实时流处理框架,可以实现单节点百万级的数据处理与运算。
实时日志分析的过程是:使用Flume监听日志文件,并实时把每一条日志信息抓取下来存入Kafka消息系统中,再由Strom消费Kafka中的消息,接下来使用用户定义的Storm Topology进行日志的分析并输出到Redis缓存数据库中,最后由应用程序读取缓存数据库的内容并显示,也可以把结果持久化的存储在MySQL中。在Flume和Storm中加一个Kafka消息系统是为了防止Flume和Storm的处理速度不匹配而丢失数据。
(3)结果报表
常见的结果报表有:1)进行各种数据统计,这是最典型的报表形式,方便管理人员了解网络的使用情况。2)分析某一现象为什么发生,为了进一步找出原因,可能需要和领域专家进行沟通,设计进一步的数据分析方案。3)通过历史数据的分析,可以使用分析报告给出未来的趋势,提供给管理人员与决策者作为决策的参考。Highcharts是一个主流的JavaScript图表库,主要为Web站点提供直观的、交互式的图表体验,支持线图、条形图、曲面图、条形曲面图、柱状图、饼图、散布图等图表样式。使用Highcharts可以生产直观的报表。
3 结语
本文介绍数据分析和网络日志分析的背景及常用分析技术。分析了大数据的特征,以及大数据分析的步骤及两种典型的大数据分析模型。目前的日志数据满足大数据的特征,以前的常规分析方法不再有效,根据使用场景构建了实时和离线的大数据日志分析体系结构。进一步的研究工作是要通过深入挖掘日志文件的隐含信息,并利用日志信息进行信息系统的故障溯源。
参考文献:
[1]赵迦琪,张彩云,牛永红.ELK日志分析平台在系统运维中的应用[J].电子技术与软件工程,2017(06):182-183.
[2]冯兴杰,王文超.Hadoop与Spark应用场景研究[J].计算机应用研究,2018(09):1-8.
[3]彭敏佳林勇吴翀严盟.MapReduce技术在日志分析中的研究应用[J].计算机时代,2017(06):26-28.
[4]陈康贤.大型分布式网站架构设计与实践[M].北京:电子工业出版社,2014.
[5]李涛.网络安全中的数据挖掘技术[M].清华大学出版社,2017.
[6]薛文娟.基于层次聚类的日志分析技术研究[D].山东师范大学,2013.
[7]陈爱民,盛昀瑶.基于MapReduce的Web日志挖掘算法研究[J].现代计算机(专业版),2017(16):14-18.
[8]Tang Liang,Li Tao.LogTree:A Framework for Generating System Events from Raw Textual Logs[C].Data Mining(ICDM),2010 IEEE 10th International Conference on,2010:491-500
[9]Tang Liang,Li Tao,Perng Chang-Shing.LogSig:Generating System Events from Raw Textual Logs[C].Proceedings of the 20th ACM International Conference on Information and Knowledge Management,2011:785-794
