一种新的音乐检索技术研究
2018-05-07伍寅峰张明
伍寅峰,张明
(上海海事大学信息工程学院,上海 201306)
0 引言
音乐作为一种重要的数据形式,充斥着新一代人的生活和工作,传统的音乐检索采用的是文本注释的方法进行标记,但是由于标记的复杂性和标记者的主观性,传统的音乐检索技术已经逐渐走下历史的舞台。哼唱检索(Query By Humming,QBH)作为一种新兴的检索方法由于其方便简单的特性被广大用户所接受,它是指用户哼唱歌曲的某个片段作为查询输入,然后从歌曲数据库中检索出相对应的音乐。因此,相对传统的以文本注释的搜索方法,哼唱检索更能提高用户的搜索体验。
对于哼唱检索来说,特征的提取好坏对检索的结果影响巨大,大量研究证明对于歌曲来说,旋律是其本质的特征,音高、音长和节奏是旋律的重要属性。1995年,Ghias[1]展示了首个QBH系统,创造性的将歌曲转换为音调轮廓信息进行匹配,利用三个字符S、U、D来表示音乐的旋律轮廓。McNab等[2,3]增加了对音乐节奏信息的提取提高检索成功率。Blackburn[4]、Roland[5]和Shih[6]等发展了McNab的方法,使用基于树的数据库搜索技术来提高搜索精度和速度。随后Shih[7]在其QBH系统中使用了隐马尔科夫模型,这项技术已经被成功应用到语音识别等领域。Zhu等[8]用动态时间规整(Dy⁃namic Time Warping,DTW)索引技术将演唱歌曲直接与数据库中的歌曲进行比较。
通过以上的研究分析发现,以往的研究方法总是集中于搜索准确率或搜索时间某一点上,很难从两者之间做出平衡,搜索精度高的算法往往运行时间过长,而搜索时间很短的算法精度却不高,本文在上述研究的基础上,首先改进了基于短时自相关法的基音估值算法,然后使用一种新的线性伸缩方法进行音高轮廓的匹配。实验表明,使用该算法提取的音高轮廓进行音乐检索匹配时,有较好的搜索精度,对于一定程度的嘈杂坏境具有较强的适应性。本文的哼唱检索系统整体框架如图1所示。

图1 哼唱检索处理框架
1 音乐旋律提取算法
本文对哼唱信息处理的过程分成3步:预处理、基音提取、旋律匹配。
1.1 预处理
预处理部分包括预加重、加窗分帧和降噪等操作。
(1)预加重
对输入的语音信号进行预加重的目的主要是为了加重语音高频部分,去除声门激励和口鼻辐射的影响,使信号的频谱变得平坦。本文的预加重是在语音信号数字化后,在参数分析之前在计算机里用具有6dB/倍频程的提升高频特性的一阶FIR高通数字滤波器来实现[9],其表达式如式(1)所示:

其中u为预加重系数。
(2)加窗分帧
对于窗函数的选择,由于矩形窗的频谱泄露较严重,所以我们采用更加平滑的汉明窗,其表达式如式(1)所示(其中N为帧长)

(3)降噪
对语音信号中加性噪声的抑制方法有多种。本文采用最小均方误差估计语音增强方法,它是由Yariv Ephraim和David Malah[10]于1985年提出,是一种对特定的失真准则和后验概率不敏感的估计方法,能有效地降低音乐噪声的干扰。
1.2 基音提取
短时自相关函数是对信号进行短时相关分析时最常用到的特征函数。音乐信号s(m)经窗长为N的窗口截取为一段加窗信号Sn(m),对其进行分帧,Sn(m)为一帧内的信号,定义Sn(m)的自相关函数Rn(k)为:

由于信号的短时自相关函数在基音周期的整数倍位置上会出现峰值,因此可以通过检测峰值的位置来提取基音周期值。基于短时自相关法进行基音提取是目前比较常见的基音提取算法,但是这种方法有着很明显的缺陷:
(1)声道共振峰有时会严重影响激励信号的谐波结构。
(2)语音信号本身是准周期性的,而且其波形的峰值点或过零点受共振峰结构和噪声的影响。
鉴于此,我们提出一种改进的基于短时自相关法的基音周期提取算法,在传统方法的基础上,进行预处理,实现对基音周期的准确提取。本文对语音信号先进行中心削波处理,同时在中心削波法的基础上,再采用三电平削波法,从而大大节省了计算时间。
中心削波函数如式(4)所示:
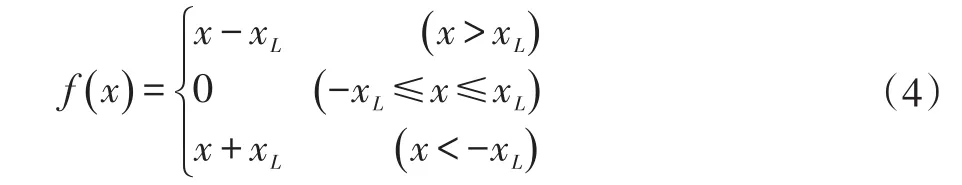
三电平削波函数如式(5)所示

实验表明,将削波后的序列 f(x)用短时自相关函数估计基音周期,在周期位置的峰值更加尖锐,可以有效地减少倍频或半频错误,同时计算时间会大大缩短。
基于以上处理,即可较好地求出每一帧哼唱信号的基音频率,然后使用下式转换成半音单位:
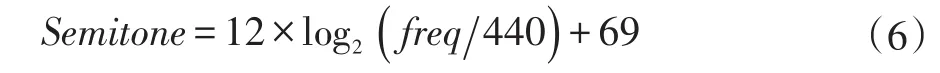
其中,freq是以Hz为单位的基频值。
一个音符总会延续若干帧,得到每一帧的音高之后,可采取加权求特征值的方式得到每个音符的音高。设一个音符由n帧构成,每帧的音高分别是P1,P2,…,Pn,则每一帧的权重定义如下:累加具有相同音高帧的权重,权重最大者即为整个音符的音高,进而得出音高轮廓,图2是作者哼唱的一段音乐的音高轮廓和时域波形。
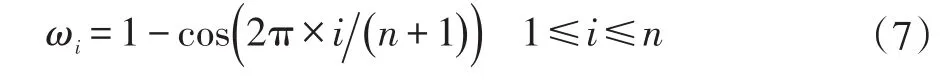
1.3 旋律匹配
得到音高轮廓后,我们就可以与音乐数据库中的歌曲进行旋律匹配,音乐数据库中的每一首歌曲也必须事先转换成音高轮廓的形式,旋律匹配的目的在于找到与我们哼唱片段最相似的目标音高轮廓。其中相似度的大小取决于我们所用到的距离函数,距离越小,则相似度越高。在计算两段音高的距离时,一些问题不可忽视:每个人唱歌的音高基准不一样,女生唱歌的key比较高,而男生比较低;每个人唱歌的速度也不一样,唱歌的快慢可能都与数据库中的歌曲速度不同。
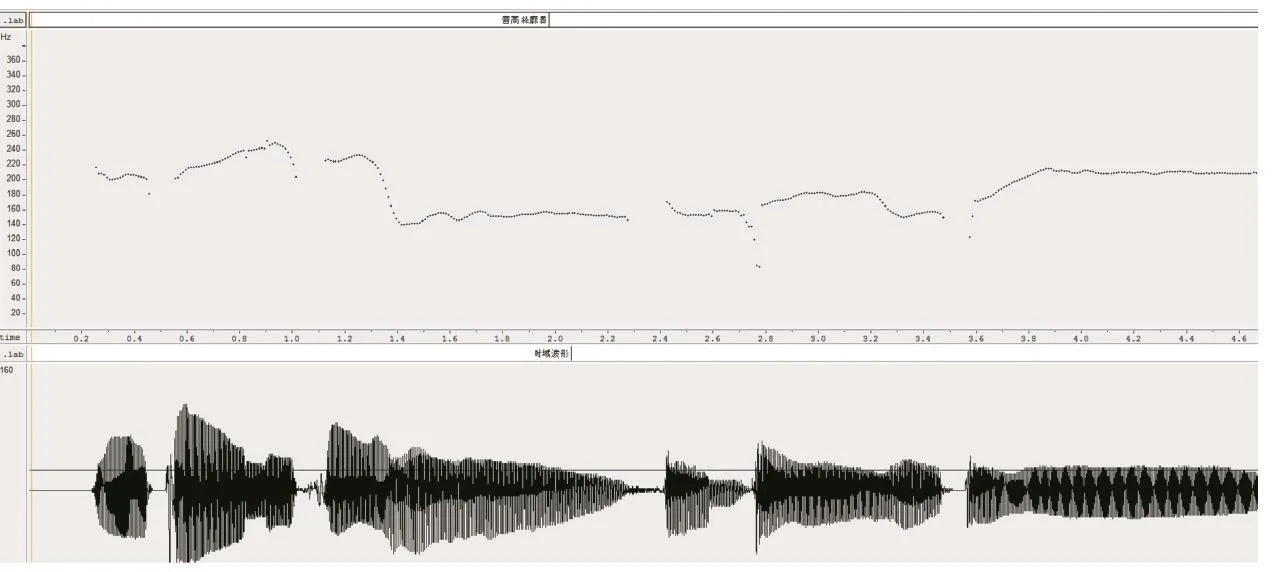
图2 哼唱片段的音高轮廓与时域波形
对于第一个问题,可以将两段音高都平移到同一个音高基准,再进行比对。对于第二个问题,假设速度的变化是均匀的,此时就可以采用线性伸缩算法来进行比对。
在不切音符情况下,最简单高效的匹配算法就是线性伸缩,其原理就是以线性方式伸展或收缩哼唱片段音高轮廓来搜索数据库中的歌曲,其算法过程如下:
(1)使用内插法,将哼唱片段的音高轮廓进行线性的伸展或收缩,例如伸缩比例可以是从0.5到1.5,跳距是0.25,共产生5个版本。
(2)将这5个处理过的音高轮廓和歌曲数据库中的一首歌曲的音高轮廓进行比对,得到了5个距离,取距离最小者,作为哼唱片段的音高轮廓和这首歌的距离。
(3)对歌曲库中的所有歌曲进行比较,距离最短的既是与哼唱片段的最佳匹配,匹配结果如图3所示。
从上面我们可以看出,线性收缩算法的匹配准确率在于伸缩系数的跳距,跳距越小,则匹配的准确度会随之上升,但是匹配的时间在到达一个阈值后会呈线性增长。同时当用户哼唱速度快慢不一时,线性伸缩的效果也会受到很大的影响。基于这两个问题,本文对线性伸缩的匹配准则做出了改进,提出了限定阈值的多分段式线性伸缩算法,当用户哼唱的速度快慢不一时,对哼唱速度发生明显变化的点进行分割,这样在短时间内分割出来的哼唱片段的速度变化可以看作是均匀的,同时我们需要限定一个阈值,用来限制分割的段数,分割的段数与跳距的大小选择呈反比关系。下面对限定阈值的多分段式线性伸缩算法的过程作具体阐述:
(1)给定阈值α,阈值的选择不应过大,应由哼唱片段的实际质量做出衡量。哼唱片段的质量越高阈值取值可越小,反之则越大。但不可过大,实验证明,一旦阈值选取过大,匹配时间会呈线性增长。
(2)根据阈值α将目标音高轮廓和哼唱片段音高轮廓切割成α段,先对第一段进行处理。
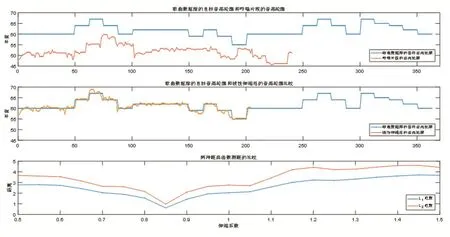
图3 线性伸缩的匹配结果示意
(3)使用线性内插将哼唱片段的音高轮廓线性伸展或收缩,跳距θ根据阈值的大小判断,跳距θ和阈值α总是呈现正反比关系。本文给出一种选择方法。

σ2和σ1分别表示伸缩比例,伸缩比例的一般在0到2之间选取,本文选取的伸缩比例范围是0.5至1.5。
(4)将n个伸缩后的哼唱片段与歌曲数据库中的一首歌曲的音高轮廓数据比较,获到n个距离,将其中的最小值作为目标音高轮廓和哼唱片段音高轮廓之间的最小距离Dist1。
(5)对于之后的 α-1段重复步骤(3)和步骤(4)的操作,得到α-1段的最小距离Dist2,Dist3,…,Distα。
(6)相加所有的独立最小距离得到最终距离 DistSum=Dist1+Dist2+…+Distα。
(7)与数据库中所有歌曲进行步骤(1)到步骤(6)的操作,为了哼唱片段匹配过程的一致性,应选择与以上操作相同的阈值α和跳距θ,进而得到m个DistSum。
(8)比较m个DistSum,最小者则是我们要检索的目标歌曲。
实验证明,该算法能很好地解决跳距的选择问题和哼唱速度不均的问题。
2 实验结果与分析
为了测试本文所提出的检索方法的有效性,本文基于MIR-QBSH数据集(MIREX竞赛用于QBSH任务的语料库)上进行了相关实验,MIR-QBSH数据集包含48个地面实况MIDI文件和约195个主题的4431个查询片段,测试片段都是频率为8kHz、8位的单声道WAV文件。所有实验均在主频为2.3GHz的Intel Core i5-6300HQ CPU、内存为 8GB、显示适配器为NVIDIA GeForce GTX 960M的PC上完成,使用的系统是Windows10,64位,编程语言采用C++。
2.1 限定阈值的多分段线性伸缩算法的效率实验
为了能更加客观地表示新算法的执行效率,我们选择了目前使用较多的两种旋律匹配算法:字符串匹配算法和DTW匹配算法作为比较,比较结果如图4所示。
从图中我们可以看到,三种旋律匹配算法中,DTW匹配算法作为当前最主流的匹配算法,其准确率达到了最高,限定阈值的多分段线性伸缩算法其次,字符串匹配算法排在最后,但是DTW算法却因为其繁杂的计算过程而在搜索时间上远落后于其他两种算法,如表1所示。新算法在匹配准确率上虽然稍逊于DTW匹配算法,但是在搜索时间上却取得了胜利,综合两方面考虑,新算法在现实生活中更加具有实用性。

表1 三种方法检索时间对比
2.2 哼唱系统的性能实验
同时我们选择了10位未经专业音乐训练的测试人员,男女各5人,每人随机哼唱数据库中的一首歌曲,哼唱片段的长度在7秒至15秒之间不等。对哼唱结果的成功率我们进行了统计,统计结果如表2所示。

表2 哼唱检索实验结果
实验结果表明,该系统能够很好地对哼唱片段进行识别,并能给出满意的结果。
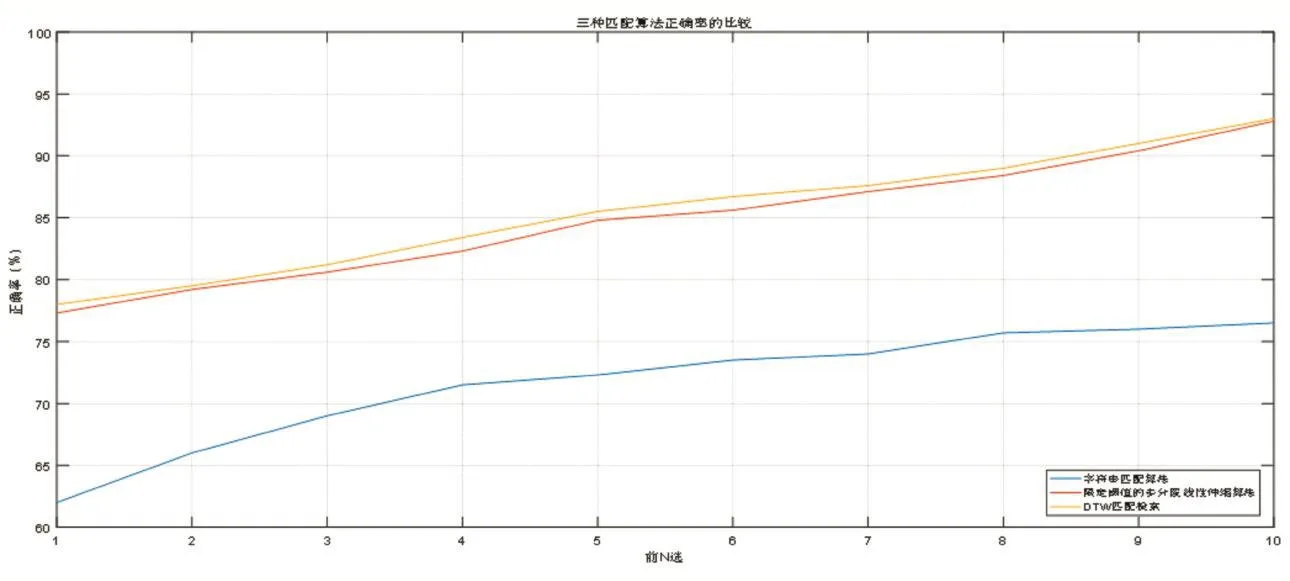
图4 三种不同的匹配算法比较
3 结语
本文在分析现有的基音提取算法的基础上,提出了当前算法的不足,并加以改进,使其能够更好地为旋律匹配提供支持。同时在旋律匹配算法的选择上,提出了新的限定阈值额多分段线性伸缩算法,在提升匹配准确率的同时降低了计算量,在匹配正确率和搜索时间两者之间做出了平衡。接下来如何在不牺牲搜索时间的基础上进一步提升匹配准确率,需要进一步深入的研究。
参考文献:
[1]Ghias A,Logan J,Chamberlin D,et al.Query By Humming:Musical Information Retrieval in an Audio Database[C].ACM International Conference on Multimedia.ACM,1995:231-236.
[2]Mcnab R J,Smith L A,Witten I H,et al.Towards the Digital Music Library:Tune Retrieval From Acoustic Input[J],1996:11-18.
[3]Mcnab R J,Smith L A,Witten I H,et al.Tune Retrieval in the Multimedia Library[J].Multimedia Tools&Applications,2000,10(2-3):113-132.
[4]Blackburn S,Deroure D.A Tool for Content Based Navigation of Music[C].ACM International Conference on Multimedia.ACM,1998:361-368.
[5]Rolland P Y,Raskins G,Ganascia J G.Music Content-based Retrieval:an Overview of Melodiscoc Approach And Systems[C].ACM Multimedia Conference,1999.
[6]Shih H H,Zhang T,Kuo C C J.Real-Time Retrieval of Songs from Musical Databases with Query-by-Humming[J].
[7]Shih H H,Narayanan S S,Kuo C C J.An HMM-based Approach to Humming Transcription[C].IEEE International Conference on Multimedia and Expo,2002.ICME'02.Proceedings.IEEE,2002:337-340 vol.1.
[8]Zhu Y,Shasha D.Warping Indexes with Envelope Transforms fFor Query by Humming[C].Proceedings of the 2003 ACM SIGMOD International Conference on Management of data.ACM,2003:181-192.
[9]周明全,耿国华,王小凤,李鹏.基于内容的音频检索技术[M].北京:科学出版社,2014:29-29
[10]Ephraim Y,Malah D.D Malah,Speech Enhancement Using a Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator[J].IEEE Trans.Acoust.Speech Signal Process 32,1109-1121[J].IEEE Transactions on Acoustics Speech&Signal Processing,1985,32(6):1109-1121.
