基于网络购物评论的协同过滤推荐算法
2018-05-07徐文祥魏红芹
徐文祥,魏红芹
(东华大学旭日工商管理学院,上海 200051)
0 引言
Web2.0下,电子商务发生了翻天覆地的变化,传统的电子商务以企业为中心发布产品信息逐渐转变为企业与消费者的互动,网络购物评论作为口碑的一种新形式,指的是消费者对产品的质量和服务,通过短文本形式在网购平台评论系统中发表的评价。根据相关调查研究,网络购物评论对消费者的决策产生了重要的影响。而现有的电子商务只是简单地根据商品的好评和差评数量帮助用户进行快速决策,并没有考虑不同用户的情感倾向和偏好,基于此,本文在短文本观点抽取和推荐算法相关研究进入深入分析的基础上,通过挖掘评论信息中产品的特征和对应的用户观点,构建产品特征模型和用户偏好模型,结合修正的余弦相似度计算对传统的协同过滤算法进行改进,最终得到了融合网络购物评论的协同过滤推荐算法。
1 相关工作
协同过滤推荐算法可以分为基于内存(Memorybased)的方法和基于模型(Model-based)的方法[1]。其中基于内存[2]的方法根据研究对象的不同,又可以分为基于用户的推荐(User-based)和基于项目的推荐(Item-based)两种。基于用户的推荐是根据用户对项目打分等数据,计算目标用户与其他用户的相似度,再寻找与目标用户最为接近的Top-k个相似用户,对于目标用户未曾打分的物品用相似用户的历史打分数据进行加权打分,最后根据物品的打分进行排序得到一个推荐结果列表给目标用户。基于项目的协同过滤与基于用户的协同过滤相似,不同是将最近邻搜索从用户整体空间转换到项目空间上,大大地改善了传统基于用户算法的计算瓶颈,但是这两者都无法解决推荐系统冷启动问题。为了解决用户冷启动和项目冷启动问题,相关学者提出了基于模型的协同过滤推荐算法,其主要思想是用基础的协同过滤从历史数据中训练出一个模型,再通过训练出来的模型进行预测。
网络评论数据属于非结构化的文本信息,主要由评论者、评论的对象、评论内容、评价者观点四个部分组成。大部分的研究工作主要为产品特征提取和情感分析以及极性分析,涉及到的相关学科领域知识有信息检索知识、自然语言的处理、机器学习等。
挖掘评论信息中用户感兴趣的产品特征分为两种[3],一种是显性的特征,如:“整体用着还不错,开机速度挺快的,十几秒。”其中“整体”、“开机速度”可以自己从评论语句中提取出来的为显性特征;一类为隐形特征,如“机器颜色很好看,携带很方便,不过手部有油,留的痕迹也很明显。”其中“颜色”指的是手机的外观,而“携带很方便”讨论的是手机的尺寸,但是这些特征都不能够直接从评论语句中获得,只能根据上下文语境进行语义分析获取。产品的显性特征挖掘,常用的方法有监督式和非监督式算法[4]。隐性方面的特征词挖掘需要对评论语句进行深刻的语义理解[4]。观点挖掘的算法主要分为:基于规则的抽取、基于统计模型提取和基于深度模型的提取方法[4]。
在结合评论挖掘的推荐方面,蓝金炯[5]运用LDA模型挖掘评论主题分布,利用Rocchio算法得到了用户的主题分布向量,改进了协同过滤推荐。那日萨[6]等运用构建产品属性与推荐度模糊规则,实现了个性化产品推荐计算。扈中凯利用相似度传递技术环节了缓解了推荐系统中数据稀疏性问题。
2 整体框架
本节主要针对网络评论挖掘和改进的个性化推荐模型进行实验研究,实验思路和过程如图1所示,首先从收集评论数据;接着对收集的评论数据进行预处理;随后就是从评论语句中挖掘产品特征集、观点识别、极性判断和计算;然后对评论挖掘的结果进行分析,改进协同过滤推荐算法,构建产品特征模型和用户偏好模型,产生推荐。

图1 基于网络购物评论的产品推荐框架
3 融合用户评论挖掘的协同过滤推荐算法
3.1 评论数据预处理
(1)关键词过滤
网络评论数据充满着大量无用的垃圾信息,例如广告、推广等,例如评论中出现通知、公告、简讯、快讯等词语,可以通过建立关键词过滤词典,进行去噪。
(2)句式过滤
消费者发表的评论往往都带有一定的感情色彩,句型一般要不为感叹句,要不就是陈述语气,很少有疑问句或者反问句式对商品进行评价,针对于这种情况,可以判断如果评论语句中包含了“?”等表示疑问的标点符号,可以直接从评论集中过滤掉。
(3)冗余消除
另外,经常在购物网站中会发现有些评论是完全一模一样,基于某中原因,有的是出自同一个评论者,或者不同的评论者,对于研究是没有用处的,所以也可以去掉这些重复的评论,保证了评论的唯一性。
3.2 特征情感词语对提取
定义 1:用户评论数据集 R={r1,r2,…,rn},r={s1,s2,…,sm},评论数据集由所有的用户评论组成,每一条评论包含多个句子。
定义2:特征情感词语对由<Fword,Oword,Mword,Is⁃Neg>表示,其中Fword表示特征指示词语,一般为名词或名词词组,Oword表示情感词语,一般为形容词,Mword为情感修饰词语,一般为程度副词,IsNeg代表否定词,若句中含有否定词语,则情感的极性要取反。
本文基于词性抽取评论中的产品特征和用户观点,首先要对评论中的句子进行分词和词性标注(part of speech)。通过建立产品特征词语库FDict进行过滤,特征情感词语对提取步骤如下:
步骤1:迭代每条评论r,对r分句,分句后对每条句子s分词和标注词性;
步骤2:抽取句子s中的名词词语N,如N存在于FDict中,则将 N存入 Fword中,不存在,则 Fword置为NULL;
步骤3:抽取句子s中中的形容词ADJ,若包含一个或多个,则将 ADJ存入 Oword中,否则 Oword置为NULL;
步骤4:抽取句子中程度修饰副词ADV,若ADV不存在,则Mword置为NULL,否则将ADV存入Mword中;
步骤 5:寻找否定词语NEG,若存在,则IsNeg=true,否则,IsNeg=Flase;
步骤6:将抽取的结果按照<Rid,Sid,Fword,Oword,Mword,IsNeg>存放,其中Rid表示评论编号,Sid表示评论的句子编号。
3.3 情感极性计算
本文基于HowNet情感字典构建电子产品领域的极性字典。极性判定词典的词性分为3类:褒义(Posi⁃tive)、贬义(Negative)、中性(Neutral),这 3类词语极性的取值(Pvalue)为 positive、negative、neutral、unknown,其中Spos、Sneg和Sneu分别表示褒义词集合,贬义词集合和中性词集合。unk为未登录词,不在这3个集合中,需要通过一定的方法进行判断。本文计算未登录词的极性采用SO-PMI算法。
PMI(Pointwise Mutual Information),中文全称点互信息,常用于机器学习领域,是计算两个事物之间的相关性,计算公式(1)如下:
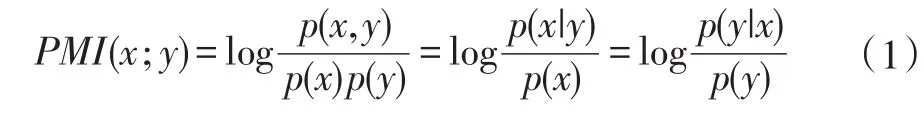
如果x与y不相关,则上式为零,若x与y相关性越大,则上式就越大。
本文通过建立极性词典,通过信息检索的方式,分别求出未登录词与极性词典里面的正向词和负向词的PMI,若正向的PMI值大,则未登录词判定为正向,否则判定为负向。SO-PMI计算公式(2)如下:

如果 SO(unk)为正,则极性为 Positive,否则,极性为Negative
极性强度strength(w)计算公式如公式(5)所示。
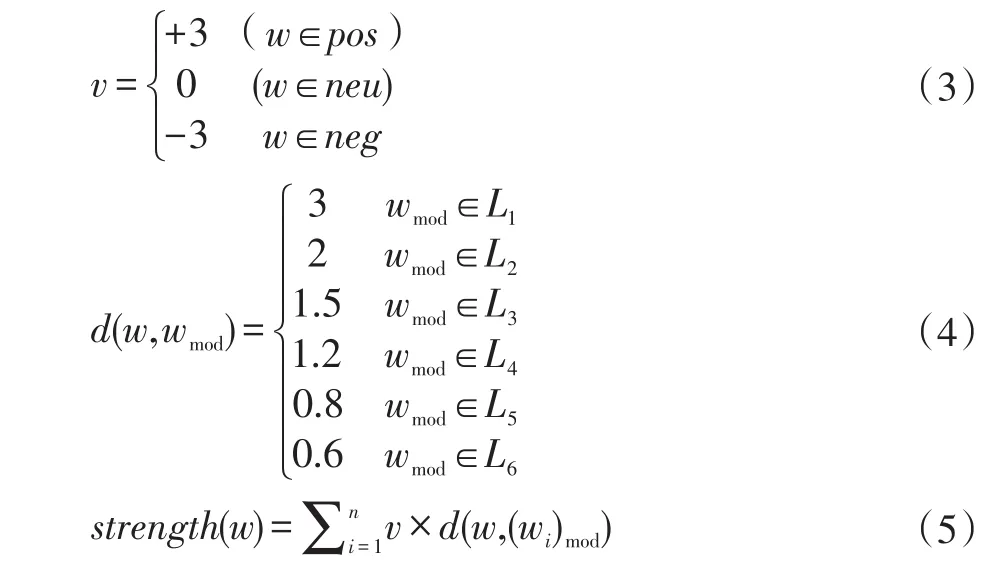
公式(3)中V表示情感词语原始极性,公式(4)中L1,L2,L3,L4,L5,L6分别代表 HowNet中程度修饰副词不同的六个等级。
3.4 用户偏好模型构建
传统的协同过滤推荐算法只考虑到了用户评分之间的相似性,本文通过抽取用户在产品特征层面的兴趣偏好,通过用户偏好来修正基于用户的协同过滤推荐算法。
定义:用户的关注偏好可以用向量来表示Pij={pij1,pij2,…,pijk},其中 pijk表示用户i对产品j的第K个特征的偏好程度。对于用户共同评价的项目可以用用户-产品特征矩阵如图2所示:

图2 用户-产品特征矩阵
传统的余弦相似度计算,不能反映出不同的用户对不同的产品的主观评价尺度,往往会导致没有相同的兴趣爱好的用户错误的聚类在一起,产生了不相关的推荐,为了克服不同用户主观差异带来的问题,本文在原来相似度的基础上,减去原来用户对所有项目的平均得分作为用户对产品的新评分,其改进的余弦相似度计算公式如下所示,其中-Ra和-Rb表示用户a和用户b对产品的所有属性的平均得分。
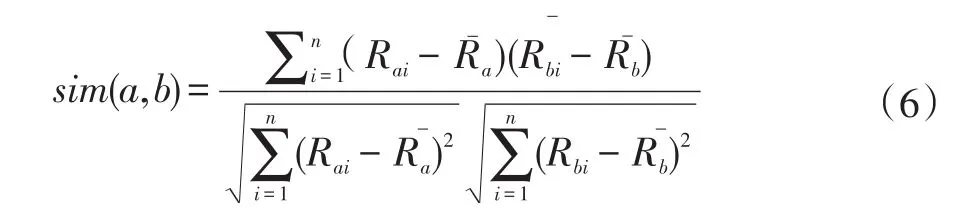
3.5 评分预测产生推荐
在协同过滤推荐算法中,通过K个最近邻用户预测目标用户对未评分的项目进行评分预测。
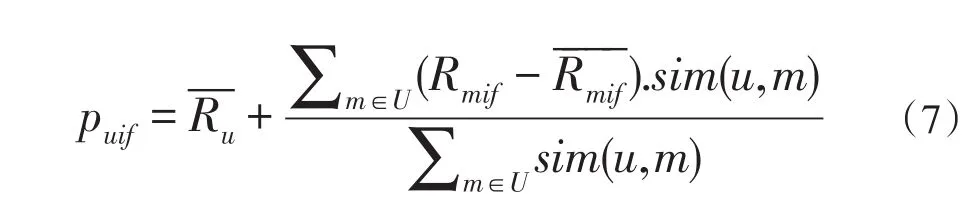
其中Puif表示用户u对产品i的第j个特征的预测评分,U表示K个相似用户集合,表示K个相似用户的平均评分。Sim(u,m)表示用户u和用户m的相似度。
根据上式对目标用户未评分的项目进行预测评分,再与用户的实际评分进行比较,最后可以得出该模型的精确,并将评分按照从大到小进行排序,产生推荐结果。
4 实验及结果分析
4.1 数据来源
本文数据来自于京东电子商务平台的手机评论数据,通过运用网页采集技术,一共爬取了100款手机共300,000评论数据。通过建立手机特征词语库和手机领域极性词典,经过数据清洗,一共提取了564个用户对57款手机的12,148条评论。
实验采用交叉验证,随机提取75%的数据作为训练集TrainSet,剩下的作为测试集TestSet,验证模型的精确度。
4.2 评价标准
推荐算法的评价公式一般验证采用平均绝对误差,其公式(8)如下所示:

其中Ra表示用户的实际评分,pa表示预测得分。
4.3 结果分析
通过设定不同的相似用户的数量,比较本文算法同传统协同过滤算法的MAE比较。结果如图3所示。从图中可以,横坐标为相似用户选取数量,取值从15-30,纵坐标表示MAE值,系列1表示本文改进的协同过滤算法,系列2表示传统的协同过滤算法,结果表明,本文的算法评分预测精确度要高于传统的协同过滤推荐算法。

图3 本文算法与传统协同过滤算法MAE比较
5 结语
本文提出了融合网络购物评论的协同过滤推荐算法,通过对挖掘评论中的特征观点词对,得到了用户在产品特征层面的偏好程度,改善了用户的偏好模型的质量,同时,在用户相似度计算方面,修正了传统余弦相似度未考虑不同用户主观评价尺度不同的问题,通过减去用户的平均得分,得到用户的新评分,在一定程度上解决了用户主观评价带来的不足。最后通过预测用户的评分进行排序产生推荐结果,实验结果,表明,本文的推荐算法较传统的给予用户的推荐算法推荐精度有明显的提高。
本文的不足在于未考虑用户其他的历史行为数据,只将评论作为模型的数据源,在实际的推荐系统中,建模的数据会是来自多个层面的,推荐的数据源选取还有待更进一步的研究。在评论特征挖掘方面,本文只针对了显性特征的抽取,对于隐性特征的提取,本文没有涉及,隐形特征对于产品特征建模同样的重要,后期还有待进一步完善。
参考文献:
[1]Breese J S,Heckerman D,Kadie C.Empirical Analysis of Predictive Algorithms for Collaborative Filtering[C].Fourteenth Conference on Uncertainty in Artificial Intelligence.Morgan Kaufmann Publishers Inc,1998:43-52.
[2]Gong S J,Ye H W,Tan H S.Combining Memory-Based and Model-Based Collaborative Filtering in Recommender System[C].Circuits,Communications and Systems,2009.PACCS'09.Pacific-Asia Conference on.IEEE,2009:690-693.
[3]Hu M,Liu B.Mining and Summarizing Customer Reviews[C].Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Seattle,Washington,Usa,August.DBLP,2004:168-177.
[4]韩忠明,李梦琪,刘雯,张梦玫,段大高,于重重.网络评论方面级观点挖掘方法研究综述.软件学报[J].2017:1-23.
[5]蓝金炯.融合在线用户评论的协同过滤推荐研究[D].华南理工大学,2016.
[6]那日萨,钟佳丰,童强.基于情感词汇的在线评论产品个性化推荐方法研究[J].郑州大学学报(理学版),2011,43(2):48-51.
