一种基于融合深度卷积神经网络与度量学习的人脸识别方法
2018-05-05吕璐蔡晓东曾燕梁晓曦
吕璐 蔡晓东 曾燕 梁晓曦


摘 要: 现有的卷积神经网络方法大多以增大类间距离为学习目标,而忽略类内距离的减小,这对于人脸识别来说,将导致一些非限制条件下(如姿态、光照等)的人脸无法被准确识别,为了解决此问题,提出一种基于融合度量学习算法和深度卷积神经网络的人脸识别方法。首先,提出一种基于多Inception结构的人脸特征提取网络,使用较少参数来提取特征;其次,提出一种联合损失的度量学习方法,将分类损失和中心损失进行加权联合;最后,将深度卷积神经网络和度量学习方法进行融合,在网络训练时,达到增大类间距离同时减小类内距离的学习目标。实验结果表明,该方法能提取出更具区分性的人脸特征,与分类损失方法及融合了其他度量学习方式的方法相比,提升了非限制条件下的人脸识别准确率。
关键词: 多Inception结构; 深度卷积神经网络; 度量学习方法; 深度人脸识别; 特征提取; 损失函数融合
中图分类号: TN711?34; TP391.41 文献标识码: A 文章编号: 1004?373X(2018)09?0058?04
Abstract: The current convolutional neural network (CNN) methods mostly take the increase of inter?class distance as the learning objective, but ignore the decrease of intra?class distance, which makes that the human face can′t be recognize accurately under some unrestricted conditions (such as posture and illumination). In order to eliminate the above problem, a face recognition method based on deep CNN and metric learning method is proposed. A face feature extraction network based on multi?Inception structure is presented to extract the feature with less parameters. A metric learning method based on joint loss is presented to perform the weighting joint for the softmax loss and center loss. The deep CNN and metric learning method are fused to reach the learning objective of inter?class distance increase and intra?class distance decrease. The experimental results indicate that the proposed method can extract the more discriminative facial features, and improve the more face recognition accuracy under unrestricted conditions than the Softmax loss method and methods fusing other metric learning modes.
Keywords: multi?Inception structure; deep CNN; metric learning method; deep face recognition; feature extraction; loss function fusion
0 引 言
近年来,基于卷积神经网络的方法在人脸验证识别领域取得了显著的成就,相对于基于手工提取特征的方法[1?2],卷积神经网络方法能获得更高的准确率。
目前,大部分基于CNN的特征提取网络使用分类损失(Softmax Loss)作为网络训练的监督信号,这些网络以分类为学习目标,在训练过程中不同类别之间的距离会逐渐增大。Deepface[3]使用分类网络方法,同时使用复杂的3D对齐方式和大量的训练数据。DeepID1[4]则是首先对人脸图片进行分块,然后使用多个分类网络对不同人脸块进行特征提取,最后使用联合贝叶斯算法对这些特征进行融合,此方法可以提取到包含丰富类别相关信息的人脸特征。
然而,对于人脸识别来说,属于同一个人的不同环境条件下的人脸图片也会有较大的差别,单纯使用分类网络的方法已经无法对这些条件下的人脸进行有效的验证识别。所以,增大类间距离的同时减小类内距离成为深度人脸特征学习的一个重要目标。DeepID2[5]和CASIA[6]在网络中加入了验证损失(Contrastive Loss),它联合网络中的分类损失在网络训练时对网络进行反馈调节,这种方法需要生成大量的正、负样本对作为训练数据,正样本对用来减小类内距离,负样本对用来增大类间距离;然而,这些样本对的生成具有较大的随机性,容易导致网络性能不稳定。FaceNet[7]提出一种有效的三重损失函数(Triplet Loss),其训练数据为三元组数据,每一个三元组包含3个样本(anchor,positive,negative),其中样本anchor与样本positive属于同一类别,样本negative属于其他类别,在训练过程中,样本anchor与样本positive之间距离会被减小,样本anchor与样本negative之间的距离会被增加;然而,随机的三元组选择方式会降低网络的收敛速度和稳定性,虽然本文中提出了一种每批次内的线上生成三元组的方式,并对三元组的选择加上条件限制,但这样的方式增加了计算资源的消耗和网络训练的难度。
本文提出一种基于融合卷积神经网络与度量学习的人脸识别方法,将基于联合函数的度量学习方法融合到卷积神经网络方法中,使卷积神经网络在训练过程中以增大类间距和减小类内距为学习目标,最终本文方法使用较少的网络参数且不需要复杂的样本选择,提取到区分能力更强的深度人脸特征。
1 基于融合卷积神经网络与度量学习的特征提
取方法
1.1 基于多Inception结构的人脸特征提取网络
传统的卷积神经网络结构一般由卷积层、池化层和全连接层组成。为了能提取到鲁棒性更强的特征,一般的做法是对网络进行加深和加宽,具体是通过卷积层和池化层的堆叠,以及多个全连接层的使用来实现。然而,简单的增大网络的尺寸可能会导致以下几个问题:
1) 網络参数过多,在训练数据数量有限的情况下,网络容易产生过拟合现象;
2) 随着网络尺寸的增大,网络的计算复杂度也随之增加,这将消耗更多的计算资源;
3) 网络深度越深,越容易出现梯度弥散现象,这将导致网络模型参数难以被优化,增加了网络训练的难度。
解决上述几个问题的方法就是在加深加宽网络的同时,减少网络参数的数量。
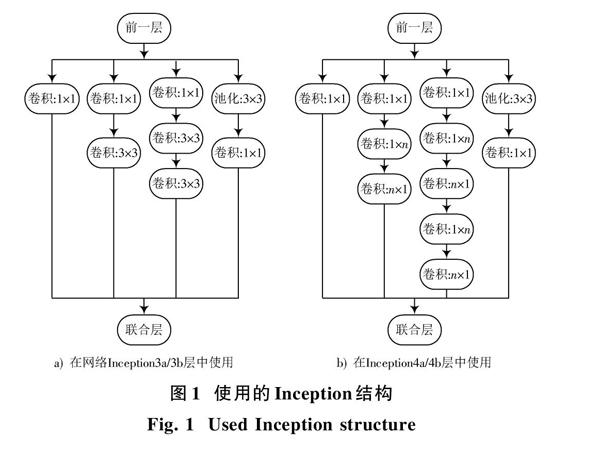
GoogleNet[8]提出Inception结构,这种结构能够有效地减少网络的参数数量,同时也能加深加宽网络,增加网络的特征提取能力。随着对卷积神经网络研究的深入,原始的Inception模型已经无法满足人脸特征提取的需要,文献[9]对Inception结构做了一些改进,其中一项重要的改进就是将Inception结构中大的卷积分解成多个小的卷积,在卷积层的输入与输出都保持不变的情况下,大量节约了计算资源,而且这种方法增加了网络的深度,也减少了参数的数量,具体结构如图1a)所示。随后,文献[9]又提出一种非对称卷积结构进一步增加网络深度和节约计算资源,即将[n×n]的卷积用一个[1×n]的卷积连接一个[n×1]的卷积来代替,如图1b)所示,而且这种结构应用在特征图大小在12×12~20×20之间的网络层时,表现很好。
本文基于文献[9]提出的Inception结构,提出一种基于多Inception结构的人脸特征提取网络,通过对每一个网络层的输入、输出尺寸和滤波器个数进行重新设计,达到提取人脸深度特征的目标。本文使用网络的具体细节如表1所示。首先,本文的网络输入是尺寸为112×96的RGB人脸图片;其次,网络中Inception3a层和Inception3b层中使用的Inception结构为图1a)的结构,而当特征图输入到Inception4a和Inception4b层时,其尺寸已经减小到14×12,所以这两层使用的Inception结构为图1b)的结构,本文经过实验取[n=5。]由于过多使用最大池化层对特征图尺寸进行减半,将损失大量的特征信息,所以本文网络使用三种方式对特征图进行减半:第一种,使用卷积核大小为3×3,步长为2的卷积层,如网络中的Conv13层;第二种,与图1a)的结构相似,其中去掉1×1卷积分支和池化分支中的1×1卷积层,并在与联合层相连的3×3卷积层以及3×3池化层中使用的步长为2,这种方式应用在网络中的Inception?Pool层中;第三种方式是池化核为3×3、步长为2的普通池化层,应用在网络中的Pool2和Pool4层中。最后,在网络的最后设置一个节点数为320的全连接层,作为人脸特征提取层,大幅压缩了最终人脸特征的维数。
1.2 基于联合损失的度量学习方法
基于CNN的特征提取网络大多数使用Softmax Loss函数作为网络的损失函数,在网络训练时,通过反馈其损失值来优化网络参数,随着迭代次数的增加,其损失值会逐渐降低,训练数据中的各个类别也会慢慢被分开。对于普通的类别分类任务来说,Softmax Loss函数已经可以满足需求。但对于人脸分类识别任务来说,由于人脸的复杂多变性,Softmax Loss只能增大不同类人脸间的距离,而无法减少同一类人脸间的距离,这将导致一些非限制条件下的人脸无法被准确识别。文献[10]提出一种中心损失函数(Center Loss),其主要作用是在网络训练时尽可能减小类内距离,具体计算如下:
式中:[N]为训练批次的大小;[xi]是此批次中第[i]个样本的特征向量,属于第[k]类;[ck]为第[k]类的中心特征向量。每经过一次迭代,都会对批次中样本对应的类别中心[ck]进行更新;这样可以在训练时有效地减小各个类别的样本与对应的类别中心的距离,达到减小类内距离的目标。
然而,在训练网络时,仅使用中心损失函数可以将类内距离变得很小,但是无法区分各个类别。所以,本文使用Softmax Loss和Center Loss对网络训练进行联合监督,以达到增大类间距离的同时减小类内距离的目标。使用方法为将两个损失函数进行加权,具体计算如下:
式中:公式的前半部分为Softmax Loss函数;[M]为训练数据类别总数;[w]为最后一个全连接层的权重集合;[b]为对应的偏置值;[λ]为Center Loss的权重值,用来平衡这两个损失,本文经过实验将其值设置为0.000 8。本文提出的网络,其中Softmax Loss层和Center Loss层在网络中的具体使用方式如图2所示。
2 实验结果及分析
本文实验平台的配置包括Intel i3?4130(4×3.4 GHz处理器)、8 GB内存、GTX1080Ti显卡以及Ubuntu 14.04操作系统,并使用基于C++编程语言的Caffe[11]深度学习开源框架。
2.1 训练样本
本文使用的训练样本是CASIA?WebFace[6]数据库,是一个大型公开数据库,它包含10 575个人,约49万张人脸图片,本文使用此数据库来训练网络。在经过人脸检测、关键点定位以及手工对一些标签错误的图片进行删减之后,最终可用的训练图片约有45万张。
2.2 测试库
本文使用公开人脸库LFW[12]数据库进行测试。LFW数据库有5 479个人,共13 233张人脸图片。本文的测试结果是基于LFW数据库的6 000对人脸验证任务,包括3 000对正样本和3 000对负样本。
2.3 实验细节
本文对所有训练和测试样本都做相同的预处理,首先,使用MTCNN[13]算法对每一张樣本做人脸检测和5个关键点定位(两只眼睛、一个鼻子和两个嘴角);然后根据定位出的5个关键点的位置做相似变换,最后将所有人脸裁剪成112×96大小的RGB图片。网络的训练参数设置如下:初始学习率设置为0.01,权重衰减设置为0.005,训练批次大小为48(由于GPU显存有限,所以iter_size设置为4),最大迭代次数为10万次。在测试时,提取测试图片原图和水平翻转图的特征作为最终的比对特征,并使用Cosine距离计算相似度。
2.4 参数[n]与[λ]的取值
参数[n]为图1b)Inception结构中的卷积核的大小,参数[λ]为本文网络使用的联合监督信号中Center Loss的权重值,本文测试不同的[n]和[λ]值在两种损失函数下对LFW库人脸验证准确率的影响,结果如表2所示。从结果中可以得出,当[n]值设置为5且[λ]设置为0.000 8时,本文所提出的网络性能表现相对较好。
2.5 LFW库测试结果及分析
本文使用表1中的网络模型做对比实验,其中一个使用Softmax Loss作为训练监督信号,另一个使用Softmax Loss和Center Loss联合作为训练监督信号;在LFW库6 000对非限制条件下的人脸验证任务上,当参数[n=5,λ=]0.000 8时,前者取得了96.08%的准确率,后者取得了98.30%的准确率;可以看出,使用Center Loss作为网络训练的监督信号,可以有效地减小类内距离,配合使用Softmax Loss,在训练时可以达到增大类间距离和减小类内距离的目标;最终,可使网络能提取出鲁棒性更强的特征。同时也与一些其他的方法做了对比,具体如表3所示。
首先,与传统算法High?dim LBP和Fisher vector faces相比,本文方法基于深度卷积神经网络对非限制条件下的人脸具有更高的识别准确率。其次,与一些分类网络方法DeepFace和DeepID1相比,本文方法融合了度量学习算法,能提取出区分能力更强的人脸特征。最后,与基于Contrastive Loss的方法WebFace相比,本文方法使用了更少的人脸关键点,且有更高的验证识别准确率。然而,与方法DeepID2相比,本文方法在准确率方面存在一定差距,但是本文方法仅使用了单个网络,远少于其使用的网络数量。
3 结 论
本文提出一种基于融合深度卷积神经网络与度量学习的人脸识别方法。首先,提出一种基于多Inception结构的有效卷积神经网络,仅使用1.05×107的参数数量来提取人脸特征;其次,将基于联合损失的度量学习算法融合到深度卷积神经网络中,使网络在训练过程中以增大类间距离及减小类内距离为学习目标;最后,在LFW库人脸验证任务上的实验结果证明,本文方法可以提取出更具区分能力的人脸特征,且达到了98.30%的验证准确率。
参考文献
[1] CHEN Dong, CAO Xudong, WEN Fang, et al. Blessing of dimensionality: high?dimensional feature and its efficient compression for face verification [C]// Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland: IEEE, 2013: 3025?3032.
[2] SIMONYAN K, PARKHI O, VEDALDI A, et al. Fisher vector faces in the wild [C]// Proceedings of 2013 British Machine Vision Conference. British: [s.n.], 2013: 1?11.
[3] TAIGMAN Y, YANG M, RANZATO M, et al. DeepFace: closing the gap to human?level performance in face verification [C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 1701?1708.
[4] SUN Yi, WANG Xiaogang, TANG Xiaoou. Deep learning face representation from predicting 10 000 classes [C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 1891?1898.
[5] SUN Yi, WANG Xiaogang, TANG Xiaoou. Deep learning face representation by joint identification?verification [J]. Advances in neural information processing systems, 2014, 27: 1988?1996.
[6] YI Dong, LEI Zhen, LIAO Shengcai, et al. Learning face representation from scratch [J]. Computer science, 2014(11): 1?9.
[7] SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 815?823.
[8] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// 2014 IEEE Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2014: 1?9.
[9] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// 2016 IEEE Conference on Computer Science and Pattern Recognition. Las Vegas: IEEE, 2015: 2818?2826.
[10] WEN Yandong, ZHANG Kaipeng, LI Zhifeng, et al. A discriminative feature learning approach for deep face recognition [J]. Computers & operations research, 2016, 47(9): 11?26.
[11] JIA Yangqing, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding [J]. Computer science, 2014(3): 675?678.
[12] HUANG G B, MATTAR M, BERG T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments [J/OL]. [2008?10?03]. http://www.tamaraberg.com/papers/Huang_eccv2008?lfw.pdf.
[13] ZHANG Kaipeng, ZHANG Zhanpeng, LI Zhifeng, et al. Joint face detection and alignment using multi?task cascaded convolutional networks [J]. IEEE signal processing letters, 2016, 23(10): 1499?1503.
