融合个体兴趣与群体认知的音乐个性化推荐模型
2018-05-04胡昌平查梦娟
胡昌平 查梦娟 石 宇
(1.武汉大学信息资源研究中心,武汉,430072; 2.武汉大学信息管理学院,武汉,430072)
1 引言
为解决音乐资源急剧增长带来的信息过载问题,个性化推荐作为一种解决手段受到了广泛关注[ 1-3],并在实践中得到广泛应用,如last.fm、网易云音乐、虾米音乐等都提供了音乐个性化推荐服务。
在实现音乐个性化推荐上,协同过滤和基于项目的推荐是两种主流的实现方式,并且都取得了较好的效果[ 4-7]。在基于项目的个性化推荐中,音乐资源的特征描述是影响最终效果的一个核心问题,其方法主要包括声学特征描述方法和音乐元数据描述方法两类。其中,声学特征描述方法是指通过音频信号分析等技术方式获取音乐作品的底层声学特征进行音乐资源描述,据此进行基于内容的个性化推荐[ 8-9]。音乐元数据描述方法是指采用文本的方式对音乐的特征进行描述,如语种、创作者、时间等,具体实现上可以进一步细分为专家编辑和用户编辑两类,前一种是指由领域专家对音乐作品进行元数据添加[ 10-11],后一种是指由用户进行元数据添加,如基于社会化标签、评论挖掘进行元数据提取[ 12-13]。
纵观当前的研究,基于声学特征的音乐作品描述方法过于关注底层声学特征,与用户对音乐的认知存在语义鸿沟[ 14],从而难以准确地描述用户的兴趣偏好;基于专家编辑的元数据描述实现人力成本过高,而且与用户的音乐感知存在一定的差异,从而可能影响用户兴趣建模的准确性[ 1];基于用户编辑的元数据描述方法存在两个突出问题,一是部分特征仅为少量用户所关注,不能反映用户普遍关注的焦点;二是大量未反映用户共识的特征描述被用作资源的元数据。为解决以上几个方面的问题,本文拟首先基于用户对音乐作品的认知框架构建元数据体系,并以用户的共识为基础进行音乐作品的描述,进而构建融合群体认知与个人偏好的用户兴趣模型,优化个性化推荐的效果。
2 融合个体兴趣与群体认知的音乐个性化推荐模型
基于项目的个性化推荐中首先需要解决的问题是资源特征的描述,为实现资源描述的角度与用户决策时考虑的因素相匹配,需要首先建立用户认识音乐作品的认知框架。以此框架为元数据体系,进行基于群体认知的资源描述,从而保障资源标注的结果与用户的认识一致。在资源特征描述的基础上,可以基于用户感兴趣的音乐作品,进行融合其偏好与情境信息的兴趣建模,进而基于音乐作品与用户兴趣的相似度进行音乐推荐,各环节间的关联关系如图1所示。
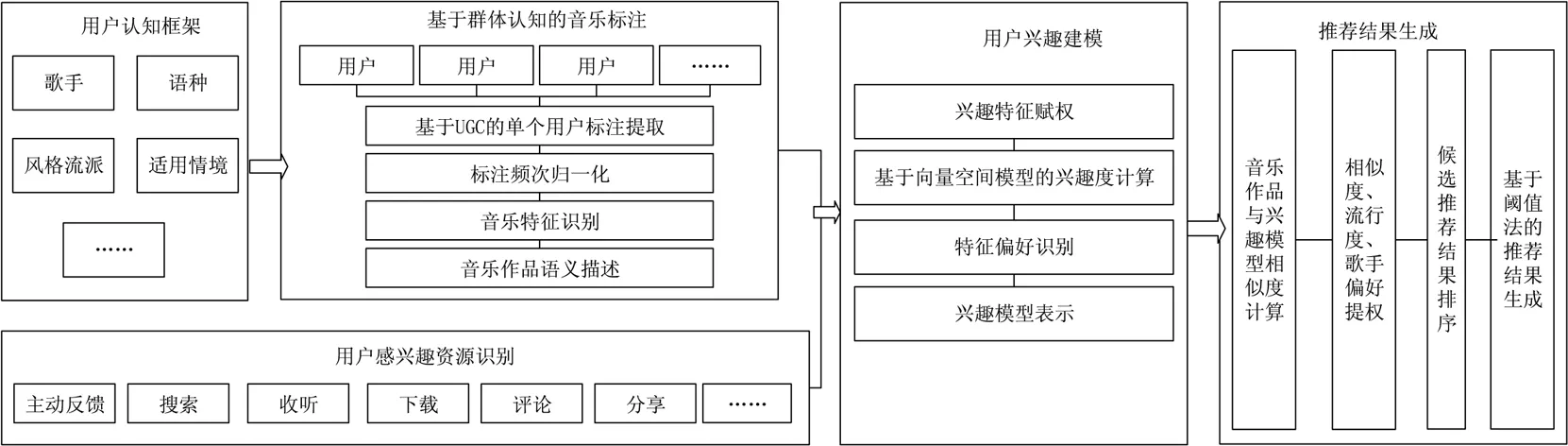
图1 基于个体兴趣与群体认知的音乐个性化推荐模型图
2.1 用户音乐作品认知框架构建
用户对音乐作品的认知框架反映了其音乐选择的因素,而基于项目的推荐中,只有依据用户的决策因素进行资源特征的选取,才能取得更好的推荐效果。基于此,需要进行用户音乐作品认知框架的构建,并将其作为面向个性化推荐的音乐作品标注的元数据体系。在实现用户认知框架构建上,可以采用社会调查法或日志分析法进行。其中,社会调查法是指通过访谈、问卷等形式对用户展开调查,判断用户认知过程中的共性特征,并将其作为认知框架;日志分析法是指通过对用户的评论、搜索、浏览、社会化标注等行为数据的分析,获得用户主要关注的资源特征,从而建立其对音乐作品的认知框架。
本研究基于对用户社会化标签数据的人工分析进行了认知框架的构建,并将大多数用户共同关注的音乐作品特征作为其认知框架。根据统计结果,用户音乐作品认知框架主要由4个要素构成:歌手、语种(地域)、风格流派、适用情境(如安静,悲伤)。
2.2 基于群体认知的音乐作品标注
在元数据体系构建的基础上,基于群体认知的音乐作品标注主要包括如下几个环节。第一,对于每一个用户,基于其围绕某部音乐作品的用户生成内容数据(User-generatedcontent,简称UGC,包括评论、分享时的描述、标签、收藏时的分类等)进行资源特征提取,从而获得用户的认知结果。第二,将每一个用户的认知结果整合到一起,并以特征词的频次为分子,贡献UGC数据的用户为分母,进行归一化处理。第三,设置阈值,获得基于用户认知的标注结果。需要指出的是,鉴于不同特征的认知难度不同[ 15],在阈值设置中需要针对不同的元数据设置差异化的阈值。第四,进行音乐作品标注结果的语义描述。鉴于用户进行音乐作品选择时,是在综合考虑多个元数据的基础上进行的,而每个元数据之间不具有完全的可替代性,因此为便于后续兴趣建模及推荐结果生成,需要对标注结果进行语义描述。
2.3 用户感兴趣资源识别
识别用户感兴趣的资源是构建用户兴趣模型的基础,其实现上既可以采取用户主动反馈的方式也可以采用基于用户行为的隐性反馈方式。其中,主动反馈是指用户将自己对哪些资源感兴趣或不感兴趣主动反馈给个性化推荐系统,这种方式下对感兴趣资源的识别准确率高,但用户成本较高,且不容易全面反馈其感兴趣的资源。隐性反馈是指系统通过用户的行为猜测其对哪些资源感兴趣、哪些资源不感兴趣,这是目前主流的方式。对于音乐来说,能够反映用户是否感兴趣的典型行为包括浏览、搜索、在线收听、下载、评论、分享等。但需要说明的是,不同类型的行为,其反映用户偏好的能力是不同的,如相比于浏览,用户更可能喜欢其分享了的音乐作品;同一个类型的行为,也需要综合其他因素进行判断,如在线收听了一次的音乐,用户不一定喜欢,但如果在线重复听了多遍的音乐,则一般认为比较喜欢;因此,需要综合考虑行为类型及相关影响因素进行用户感兴趣资源的识别。
2.4 融合用户偏好与情境的兴趣建模
用户的音乐需求与其所处的情境具有密切关系,如高兴与悲伤时、身处闹市与安静工作时所需要的音乐可能具有非常明显的差异。因此在构建用户需求时,除了需要考虑用户偏好之外,还需要考虑用户的即时情境。其中,偏好是根据用户较长一段时间内的历史行为计算的,而情境则是根据用户当时所处的环境、状态等信息决定的。由于用户决策时会考虑多个因素模型,因此,用户的偏好可以表征为一个二维向量,每一行都是用户认知框架中的一个要素,每个取值都是一个包含关键词和兴趣度的二元组,在计算方法上,可以采用常见的向量空间模型进行。此外,需要指出的是,用户兴趣模型中的每一个要素对用户决策的影响程度是不同的,因此为获得更好的推荐效果,还需要对每一个要素进行赋权,从而实现各要素作用程度的差异化。
2.5 基于音乐作品与用户兴趣相似度的推荐结果生成
在实现了基于用户认知框架的音乐作品标注和用户兴趣模型生成的基础上,可以通过各个音乐作品与用户兴趣模型相似度计算的结果生成推荐结果。相似度计算中,可以将音乐作品的标注结果同样表示为二维向量,然后通过其与用户兴趣向量的积来表征其与用户兴趣的相似度。鉴于网络口碑相关研究表明,高质量的及流行度高的音乐更容易获得用户的青睐[ 16-17],因此在相似度的基础上需要提高高质量和流行的音乐作品的权重。在计算各音乐作品相似度之后,对流行度、相似度进行权重计算,随后降序排列,以采用阈值法进行候选推荐结果的生成。在阈值设置上,既可以采用TopK方法,即选择相似度最高的K个或前K%个作为推荐结果;也可以设置一个相似度阈值,高于阈值则推荐给用户,否则不将该音乐作品推荐给用户。
3 实验
为验证模型的效果,选择了豆瓣音乐这一国内知名的音乐社区网站作为数据源。鉴于豆瓣音乐中难以获得用户听音乐时的情境信息,因此在实验中只考虑用户的长期偏好信息。
3.1 数据采集及预处理
实验目的是为了验证前文提出的融合个体兴趣与群体认知的音乐推荐策略,因此需要获取用户感兴趣的音乐作品、用户对感兴趣音乐作品的标注信息。实验数据集由从豆瓣音乐中抽取的36799位用户、以及这些用户收听的307929张音乐专辑的全部标注数据构成,数据集中的字段包括用户ID、用户标记为“听过”的歌曲专辑的URL、专辑名、用户收听该作品的时间、为作品添加的标签;在此基础上,获取这些音乐专辑的基本信息,包括专辑名、表演者、流派、专辑类型、介质、发行时间、豆瓣成员常用标签等。将用户围绕音乐作品添加的标签进行规范化处理,包括标签的规范化,复合标签的拆分,繁简体转换,中英文转换,同、近义词转换,并对各音乐作品特征的标注频次进行统计。
在完成以上步骤后,从所得规范化的数据集中随机抽取250名用户,其中59名用户标记“听过”的专辑数量在20张以下。为避免收听专辑的数量过少影响用户兴趣建模效果,在研究中剔除了这些收听数量在20张以下的用户,以剩余的191名用户作为研究样本。按用户收听时间将用户的收听记录排序,并将前60%的用户收听记录(记为α)用作训练集进行用户兴趣建模,随后的20%收听记录(记为β)作为确定各兴趣特征权重系数的训练集,最后20%的收听记录(记为γ)作为测试集用来检验音乐推荐的效果。
3.2 实验过程
用户感兴趣的资源可以有多种识别方式,多种方式综合识别能够更准确地收集用户感兴趣的资源,考虑到实现方式的复杂性,本实验以用户标注为听过的专辑作为用户感兴趣的资源。音乐作品特征描述框架的构建参照前文所述的用户认知框架即表演者(歌手)、语种、风格流派、适用场景和地域。其中适用场景主要用于匹配用户情境,本实验不考虑情境因素,因此适用场景暂不列入标注框架和用户兴趣建模中。对于国内用户来说,地域和语种具有很强的可替代性,因此这两个特征作同义转换合并为语种特征。
(1)基于群体认知的音乐特征标注
由于表演者是确定的,直接导入平台数据即可,因此,仅对语种、风格流派进行基于群体认知的特征标注。用户通过对专辑添加语种、风格流派等特征的标签完成音乐特征的识别。参与识别语种、风格流派的用户数量为所有添加了相关特征标签的用户数量,未对专辑添加相关特征标签的用户则默认其认同其他添加特征标签用户的观点,因此专辑的特征标签数量占参与标注用户数量的比例代表了用户群体对音乐专辑的认知。比值越高,说明专辑具有该特征的可能性越高。在不同阈值下音乐专辑语种、风格流派特征的识别结果存在差异,通过选取不同阈值进行预实验,结果表明当阈值为0.5时,实验效果最好。因此专辑在语种、风格流派相关特征上的特征标签标注占比超过50%时,说明专辑具有该特征。对照组的音乐专辑采用数据集中已有的特征(豆瓣平台提供的风格流派、语种等)识别结果。
(2)用户兴趣建模
为保证用户兴趣模型与音乐作品的匹配,用户兴趣模型构建也采用音乐作品特征标注的框架即表演者(歌手)、语种(地域)、风格流派。加权统计用户感兴趣专辑的风格流派、语种频次即可获得用户对不同语种、风格流派的偏好,即含有某类特征的专辑数量越高代表用户对具有该特征的专辑越感兴趣。用户对于歌手的偏好在本次实验中,分为4个层级:0级,用户对该歌手不感兴趣,用户听过的专辑中不包含该歌手的专辑;1级,用户听过的专辑中包含该歌手的1张专辑;2级,用户听过的专辑中包含该歌手的2张专辑;3级,用户听过的专辑中包含该歌手的3张及以上数量专辑。用户对于这4个层级歌手的偏好程度有很大的差异。通过对β集合的训练,发现当0,1,2,3级的权重分别为0,0.3,0.6,1时表现效果最好。因此,以该比例作为用户对歌手的兴趣度计算方式。
(3)用户兴趣模型与音乐作品相似度计算
在获取用户兴趣向量和音乐专辑歌手、语种、风格流派构成的描述模型向量的基础上,计算初始候选集(即全部用户听过的专辑减去α)中每一张专辑与用户兴趣向量的相似度,并将相似度大于0的专辑作为候选推荐专辑。由于歌手、语种、流派的类型维度过于繁杂,本文分别计算用户兴趣向量与专辑描述模型在歌手、语种和风格流派特征上的相似度。歌手偏好相似度采取用户对该专辑歌手的兴趣度中分级统计的方法计算,相似度计算公式如(1)所示。语种经统计有国语、英文、粤语、日语、韩语、法语、其他等7种类型,风格流派有流行、民谣、爵士、摇滚、电子、布鲁斯、古典、金属、独立音乐、纯音乐、OST、说唱、治愈、清新、乡村共15种类型,因此语种、风格流派的相似度计算如公式(2)所示。
(1)
(2)
其中,Sim1(ui,sj)表示用户ui与专辑mj在歌手维度的相似度,R1表示用户ui喜欢的专辑中统计频数大于等于3的歌手集合,R2表示用户ui喜欢的专辑中统计频数等于2的歌手集合,R3表示用户ui喜欢的专辑中统计频数等于1的歌手集合,R4表示没有出现在用户ui喜欢的专辑中的歌手的集合,sk表示专辑mj中的歌手。Sim2(ui,mj)表示用户ui与专辑mj在语种、风格流派维度的相似度,Fu(ui,tk)表示ui的兴趣向量tk的权重,Fm(mj,tk)表示专辑mj的语种、风格流派tk的权重。需要说明的是,一部音乐专辑中可能有多个用户喜欢的歌手,但对每一个歌手,可以用其最喜欢的歌手的兴趣度来表征专辑与用户兴趣的匹配度。
(4)各特征维度相似度、流行度权重确定及推荐结果生成
专辑流行度与该专辑被多少用户感兴趣有关,以该专辑被标记为听过的用户数与被标记为听过的用户数最高的专辑的比值作为该专辑的流行度计算方式。专辑语种、风格流派向量与用户语种、风格流派兴趣向量间的相似度、以及歌手偏好相似度、流行度对于用户选择感兴趣专辑时的权重是不完全相等的。利用β集合训练出语种、风格流派相似度、歌手偏好相似度、流行度对于用户选择的权重系数。训练得出各权重系数为0.2,0.4,0.4时效果最好,因此以专辑语种、风格流派相似度权重系数为0.2,歌手偏好相似度权重系数为0.4,流行度权重系数为0.4的权重分布进行后续实验。得到每张专辑与用户兴趣相似度值之后,计算在以上权重分布下,待推荐候选专辑中每张专辑对应的综合待推荐值,降序生成推荐结果。
(5)推荐效果评价指标
为评价该策略的效果,需要将其转化为在对应个性化推荐中的应用效果进行评估,即通过以上步骤形成个性化推荐结果在测试集中的进行测试;对比实验仅采用数据集中豆瓣平台给出的流派及语种划分结果,风格流派有流行、民谣、爵士、摇滚、电子、布鲁斯、古典、轻音乐、说唱、原声共10种类型,语种则采用系统提供的7种语种进行实验,通过统计用户历史记录中感兴趣流派频次形成兴趣向量,同时采用相同的相似度计算及排序策略。
在评价指标上,由于用户更为关心推荐排序靠前的项目,因此选取P@N指标进行推荐效果评价,即统计推荐的前N条项目中,用户喜欢的项目占比[ 18]。其计算方法如公式(3)所示:
(3)
其中,P@Nitem指推荐的前Nr条项目中用户喜欢的项目占比,Nr是指推荐列表的长度,Nri指该推荐列表中用户喜欢的项目数量。
3.3 实验结果及分析
通过验证实验组与对照组在推荐准确度方面的差异,来评价该策略的效果。本文根据评价指标设定与计算方式,统计了在不同长度的推荐列表(N值)下推荐的P@N值,由于卡方检验可以用于检验两组变量是否具有关联性,本文选取卡方检验进行实验组和对照组在推荐准确率方面的差异性检验。如表1所示。

表1 不同N值下实验组与对照组的P@N值
注:*表示p<0.05,**表示p<0.01,***表示p<0.001
结果显示,实验组与对照组在不同N值下的推荐准确率方面均存在显著差异,证明实验组与对照组之间存在显著性差异。表1可以看出,不同N值下,实验组准确率始终比对照组高。随着N值增大,实验组、对照组的准确率均呈现下滑趋势,但实验组的准确率始终高于对照组的准确率。因此,实验组推荐效果明显优于对照组推荐效果。
通过对比可以看出,融合个体兴趣与群体认知的个性化推荐策略能更好地反映用户兴趣偏好,其原因有两点:①实验组基于群体认知框架进行兴趣建模,把握了用户选择感兴趣资源时的关键影响因素;②基于群体认知的流派识别结果更符合用户的认知习惯,因而基于其进行的用户兴趣建模更加准确。
4 结语
本文提出融合个体兴趣与群体认知的音乐个性化推荐策略,从用户对音乐资源的认知框架构建出发,基于群体认知识别音乐资源特征,进行个性化的音乐推荐。结果表明,本策略与未基于群体认知的个性化推荐相比准确度更高。本文提出的个性化推荐策略阐明了用户认知在资源选择中的重要性,而且证明了群体认知对于个性化推荐的辅助作用,为音乐资源个性化推荐提出了一种可行的方案,对相关的推荐研究和实践具有一定的参考意义。
同时,本文也存在一些局限性,主要表现在以下两个方面:①由于平台难以获得与情境相关的信息,因此实验未考虑情境因素;②用户音乐作品认知框架的构建上,只考虑了普遍认可的资源特征(歌手、风格流派等),未能全面反映用户在选择感兴趣资源时决策的维度特征,应建立更为全面的认知框架。
[1] 谭学清,何珊.音乐个性化推荐系统研究综述[J].现代图书情报技术,2014,(09):22-32.
[2]SerizawaK,KameiS,HayashiS,etal.Personalizedwebpagerecommendationbasedonpreferencefootprinttobrowsedpages[J].IeiceTransactionsonInformationandSystems,2016,99(11):2705-2715.
[3]IgnatovDI,NikolenkoSI,AbaevT,etal.Onlinerecommendersystemforradiostationhostingbasedoninformationfusionandadaptivetag-awareprofiling[J].ExpertSystemswithApplications,2016,55:546-558.
[4]Sánchez-MorenoD,GonzálezABG,VicenteMDM,etal.Acollaborativefilteringmethodformusicrecommendationusingplayingcoefficientsforartistsandusers[J].ExpertSystemswithApplications,2016,66:234-244.
[5] 鲁凯,张冠元,王斌.CICF:一种基于上下文信息的协同过滤推荐算法[J].中文信息学报,2014(2):122-128.
[6]VandenOordA,DielemanS,SchrauwenB.Deepcontent-basedmusicrecommendation[C]//NZPS’13Proceedingsofthe26thInternationalNeuralInformationProcessingSystems.RedHook,NY,USA:CurranAssociatesInc,2013:2643-2651.
[7]SuJH,ChangWY,TsengVS.Effectivesocialcontent-basedcollaborativefilteringformusicrecommendation[J].IntelligentDataAnalysis,2017,21(S1):S195-S216.
[8]SiddiqueeMMR,RahmanMS,ChowdhurySUI,etal.Associationruleminingandaudiosignalprocessingformusicdiscoveryandrecommendation[J].InternationalJournalofSoftwareInnovation(IJSI),2016,4(2):71-87.
[9]BogdanovD,HaroMN,FuhrmannF,etal.Semanticaudiocontent-basedmusicrecommendationandvisualizationbasedonuserpreferenceexamples[J].InformationProcessing&Management,2013,49(1):13-33.
[10]SchedlM,LiemCCS,PeetersG,etal.Aprofessionallyannotatedandenrichedmultimodaldatasetonpopularmusic[C]//Proceedingsofthe4thACMMultimediaSystemsConference.ACM,2013:78-83.
[11]ChenYS,ChengCH,ChenDR,etal.Amood-andsituation-basedmodelfordevelopingintuitivepopmusicrecommendationsystems[J/OL].ExpertSystems,2015,33(1).Doi:10.1111/exsy.12132.[2017-05-25].https://www.researchgate.net/publication/282790667_A_mood-_and_situation-based_model_for_developing_intuitive_Pop_music_recommendation_systems.
[12] 闫俊,刘文飞,林鸿飞.基于标签混合语义空间的音乐推荐方法研究[J].中文信息学报,2014(4):117-122.
[13] 李瑞敏,林鸿飞,闫俊.基于用户-标签-项目语义挖掘的个性化音乐推荐[J].计算机研究与发展,2014(10):2270-2276.
[14]ZhangJL,HuangXL,YangL,etal.Bridgethesemanticgapbetweenpopmusicacousticfeatureandemotion:Buildaninterpretablemodel[J].Neurocomputing,2016,208:333-341.
[15] 林鑫,周知.用户认知对标签使用行为的影响分析[J].情报理论与实践,2015,38(10):85-88.
[16] 龚艳萍,张晓丹,张琴.行为视角下的网络口碑国外研究综述与展望[J].情报杂志,2016,35(5):161-166.
[17]ZhangX,KoM,CarpenterD.Developmentofascaletomeasureskepticismtowardelectronicword-of-mouth[J].ComputersinHumanBehavior,2016,56:198-208.
[18] 仲兆满,管燕,胡云,等.基于背景和内容的微博用户兴趣挖掘[J].软件学报,2017,28(2):278-291.
