基于连词的维吾尔语情感词库扩展研究
2018-05-04刘若兰玛尔哈巴艾赛提
刘若兰,年 梅,玛尔哈巴·艾赛提
(1. 新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054;2. 新疆师范大学 文学院,新疆 乌鲁木齐 830054)
0 引言
移动互联网和社交软件的快速发展,使网络成为维吾尔族网民获取信息、共享资源、相互交流、发表观点的重要平台。随着基于维吾尔语的网站数量越来越多,带有情感色彩的维吾尔语网络文本逐渐增加,并以极快的速度广泛传播,如果不加控制,网络中消极无益信息的散布将给人们带来严重危害,错误舆论的扩散甚至会干扰社会、经济的正常发展。对网络文本倾向性的快速准确分析,能够实时有效地监控舆情动态,便于政府部门及时倡导正能量,同时有利于及时过滤网络有害信息,净化网络环境,避免人们受到此类信息的危害。网络文本倾向性分析的基础资源是情感词典,情感词典的完整性和准确性将直接影响文本情感分类的准确率。由于项目组在前期构建维吾尔语基础情感词典[1]时选用的候选情感词主要借助对中英文情感词典进行翻译和筛选形成,数量有限,尚未充分考虑网络中大量的新词和变形词。情感词的覆盖面不足,导致文本倾向性判别的精确度还不能完全满足信息过滤的需求。因此,本文在前期研究的基础上,开展基于网络语料的维吾尔语情感词库的自动扩展研究,为维吾尔语情感词的自动更新及扩展提供技术支持。
1 相关工作
通过对中英文情感词典构建的文献调研表明,现阶段情感词的获取技术主要有以下两种。
(1) 基于语义词典或知识库判别情感词,构建极性情感词典。这种方法的主要思路是: 选择极性确定且明显的一组褒义词和贬义词作为种子词集,利用HowNet、WordNet以及同义词词林等资源提供的语义关系,设计算法获取候选词与种子词的语义相似度,以此为据判断候选词的情感倾向。例如,Kamps等[2]提出利用WordNet中词汇间语义距离的概念,计算情感倾向待定词与表示褒贬态度的基准词(“good”和“bad”)的关联度来识别词汇的情感类别。朱嫣岚等[3]则利用HowNet中有关语义相似度和语义相关场的定义,设计算法得到词汇的语义倾向值,再根据语义倾向值判别词汇的褒贬倾向。黄硕等[4]提出基于知网和同义词词林信息融合的方法,进行词汇的语义倾向计算。金宇等[5]借助《现代汉语大词典》中词语的释义推出其他词的情感极性。
(2) 基于语料库的情感极性判别方法。该方法通过学习大规模语料中词语的搭配特征、共现和统计等特征得到一部情感词典。例如,文献[6]利用语句中“and”、“but”等连词衔接极性形容词的特性,从语料中识别通过连词相联系的形容词对,使用图的聚类算法将抽取的形容词聚集成褒贬两类,从而实现词汇的极性判断。王科等[7]利用语料中的连接关系,同时结合转折词和否定词对文本倾向的影响,将语料中的词汇划分成两个词集,再进一步确定各词集对应的情感类别。Turney等[8]借助统计学中逐点互信息的概念衡量目标词与种子情感词的相关性,利用搜索引擎返回的hits数,计算目标词与所有褒、贬种子词的SO—PMI值来判定目标词的情感指向。阳爱明等[9]借助Turney的思想构建中文情感词典,对三部开源情感词典合并去重形成基础情感词集,利用百度搜索引擎以及改进的PMI算法重新计算基础情感词集中全部词汇的情感权值。维吾尔语方面,文献[10]在维吾尔语情感词汇语言特征的分析之上,设计CRFS的特征模板用于自动识别维吾尔语情感词汇。
目前,维吾尔语文本的倾向性分析研究尚处于起步阶段,缺乏完备齐全的维吾尔语语义资源。由于缺少可用的电子资源,基于语义词典或知识库的方法在现阶段仍难以实现。因此,本文采用基于网络文本语料库的方法,以项目组先前构建的维吾尔语情感词典资源为基础,获取包含情感词的维吾尔语情感句,分析归纳情感句中连词和程度副词与情感词的搭配特点,基于搭配关系利用网络语料抽取维吾尔语候选情感词,形成候选情感词库;最后将网络作为超大规模语料库,利用维吾尔语中并列连词联系极性相同或极性相反词汇的规律,设计了利用维吾尔语反义词词典以及Google搜索返回的页面结果数计算情感未知词与褒贬情感词集的相似度算法,依据计算结果判定情感类别后并入相应的褒贬词典,实现维吾尔语情感词库的不断扩展,为基于词典开展维吾尔语网络文本的倾向性分析研究提供重要工具。
2 维吾尔语情感词汇的特征
维吾尔语和其他语言相似,情感词主要聚集在名词、形容词以及它们的搭配关系中。因此,本文首先对维吾尔语情感句进行分析,总结维吾尔语中情感词的特点,然后基于连词衔接情感词、以及程度副词修饰情感词的规律从语料中抽取带有情感极性的词汇,再设计极性判别算法确定其情感类别。
2.1 连词的衔接特征
维吾尔语中,连词起衔接词与词、词组与词组、分句与分句、句群的作用。并且连词连接的大多数句子成分是相关的,即它们表达的情感色彩可能是相同的,也可能是相反的。其中转折连词连接的句子成分通常具有相反的情感倾向,而并列连词和递进连词在大多数情况下衔接情感极性相同的句子成分,但并列连词和递进连词有时也会连接一组表达相反意义和相反情感的反义词组。

2.2 程度副词的修饰特征

维吾尔语情感句中,还存在其他的上下文搭配关系,但由于受到现阶段维吾尔语资源和工具软件的限制,本文仅选择了上述两个特点鲜明、最易于实现的特征进行候选情感词的抽取,即连词、程度副词与情感词的搭配规则。
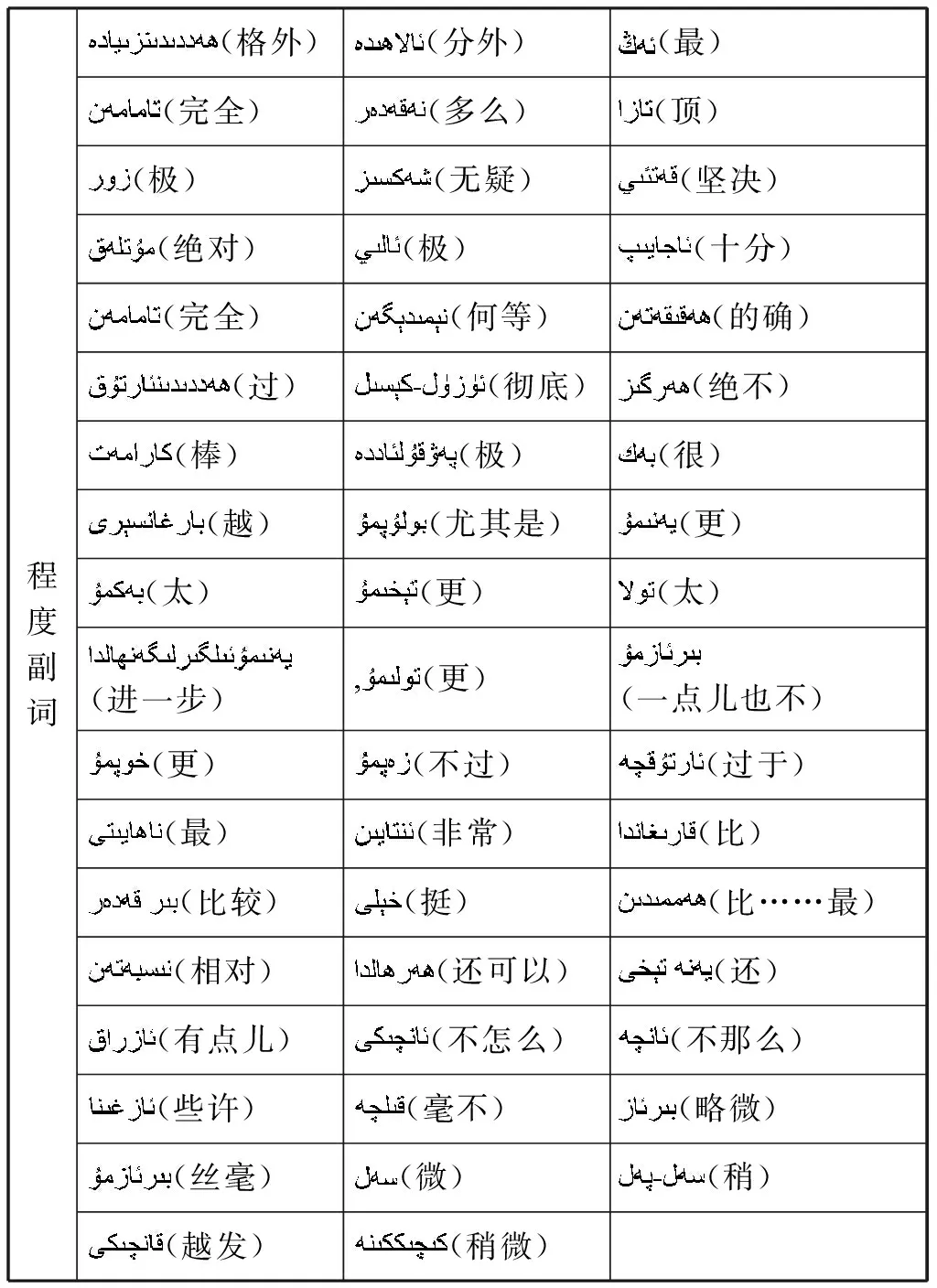
表1 维吾尔语中修饰情感词的常用程度副词
3 维吾尔语网络情感词的自动扩展
本文在已构建的褒贬情感词库的基础上,使用搜集的网络文本作为候选情感词的抽取语料,再以互联网丰富的数据资源作为词汇倾向性的判别语料,将语言特征和统计学方法相结合设计算法,实现维吾尔语情感词的自动扩展。
3.1 基础情感词集及其表示
本文利用项目组前期构建的维吾尔语褒贬情感词典,进行候选情感词的筛选和极性判别。目前该情感词集共包括褒义词2 042个,贬义词2 473个,对于其中的褒义词集本文用Pwords表示,贬义词集用Nwords表示,Bwords则代表基础情感词集。本研究在此词集的基础上,基于网络语料进行维吾尔语情感词的抽取和极性判别,扩展得到的新情感词则追加到该情感词典中,以不断扩展情感词库的词汇数量和覆盖面,为文本情感分析性能的提高提供支持资源。
3.2 候选情感词识别算法
为识别维吾尔语候选情感词,本文首先根据维吾尔语情感词汇与并列连词和程度副词的上下文关系,利用收集的网络语料抽取维吾尔语候选情感词,然后借助基础情感词集从维吾尔语候选情感词集中删除极性已知的部分候选情感词。
3.2.1 语料获取及预处理
实现维吾尔语候选情感词的获取需要基于大规模的语料数据。为此,本文首先使用网络爬虫工具Hertrix从天山网等维吾尔语网站搜集了3 000篇语料,其中包括新闻语料2 580篇和论坛语料420篇。其次,使用网页解析工具HTMLParser对收集的语料文本进行去噪处理,去除HTML标签,剔除无关信息,保留所需的文本内容,形成候选情感词提取的初始语料集。最后根据维吾尔语句子的标识符,进行句子划分,最终获得由M个句子构成的候选词提取语料集S,S={s1,s2,s3,…,sM},本研究中M为41 176。
3.2.2 候选情感词构建算法


表2 候选情感词抽取模板
3.3 候选情感词的极性判断算法
句子中并列连词前后的词通常具有一致的情感极性[11],如果候选情感词经常与褒义词由并列连词衔接在一起,则该候选情感词是褒义词的可能性较大;反之,若候选情感词常跟贬义词并列相连,则候选情感词的贬义倾向强烈。但并列连词也有连接极性相反成分的例外情况,但仅限于连接一组反义词的情形,如果候选情感词的反义词大多数为褒义词,则候选情感词的贬义情感强烈,相反,若候选情感词的反义词大部分为贬义词,则候选情感词极可能是褒义情感词。
基于以上分析,本文利用已确定情感极性的基础情感词以及维吾尔语反义词词典,分以下两种情况计算候选情感词的倾向性。在计算中,以Bwords表示基础情感词集,Owords表示维吾尔语反义词词典,待判别的候选情感词为word,其在维吾尔语反义词词典中对应n个反义词Oword。
第一种情况: 当候选情感词word的反义词出现在基础情感词集中,则可使用基础情感词集Bwords统计其中正负情感词汇的数量,再对统计结果取反即可获得候选情感词的极性值。
设候选情感词word的反义词Oword有m(m≠0)个出现在基础情感词集中,则候选情感词的极性值SValue(word)的具体定义如式(1)所示,即累加这m个反义词的极值再取反。式(1)中F(oword)表示候选情感词的反义词的极性值,并按照式(2)对其进行赋值。
第二种情况: 当候选情感词word的反义词没有一个出现在基础情感词集中,则可以利用搜索引擎从互联网的海量数据中获取与候选情感词相联系的词汇Cword,然后利用基础情感词集获取词汇cword的情感极值再进行累加,所得结果即为候选情感词的情感极值。
设候选情感词word共与p个词汇Cword相联系,则候选情感词的极性值SValue(word)即为这p个词汇的极值之和,其计算方法如式(3)所示,Cword的极性值在式中用F(Cword)表示,并根据式(4)进行计算。
(4)

根据以上方法赋予候选情感词情感极值后,为确定候选情感词word的情感倾向类别,本文设定阈值0,按式(5)计算候选情感词word的情感类别。
(5)

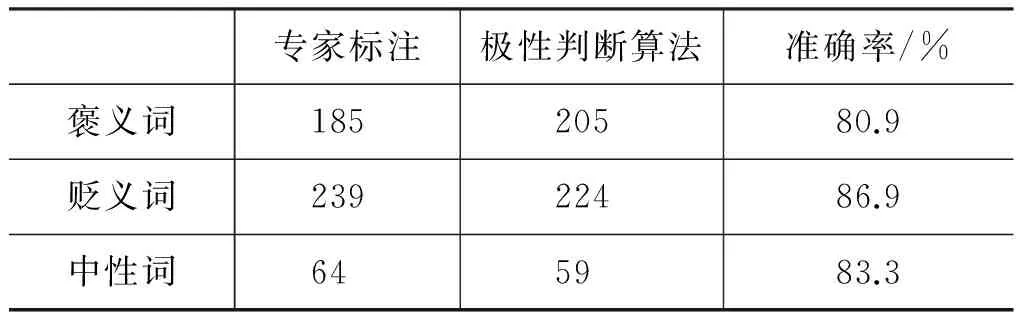
表3 专家标注、极性判断算法的候选情感词极性判别结果对比
为避免极性判别不正确词汇影响情感词典的质量,对本文算法的极性判别结果进行人工校正,最终得到褒义词185个,贬义词239个,将所得褒义词和贬义词分别并入相应的褒贬情感词典,最终构建的维吾尔语网络情感词典包含词汇4 939个,其中褒义词2 227个,贬义词2 712个。
4 实验和测试
4.1 测试语料
为验证本文提出的情感词自动扩展算法的有效性,本文使用项目组前期构建维吾尔语褒贬情感词典时使用的测试语料进行实验,该测试语料共2 500句,其中正向句1 214句,负向句1 148句,无倾向性句138句。
4.2 测试结果
本文基于网络文本扩展维吾尔语情感词典的目的旨在提高维吾尔语文本情感分类的准确率。故使用本研究扩展的网络情感词典对测试语料的2 500个句子进行情感分类,通过累计组成句子的词汇倾向性来确定句子的情感倾向。句子的情感值最终由句中所有情感词的情感值加和确定,本文定义褒义词的情感值为1,贬义词的情感值为-1,为避免否定词改变句子极性对倾向性判断结果准确率的影响,记录句中否定词的出现次数,否定词出现奇数次时,句子的情感倾向值乘以-1,否定词出现偶数次时,句子的情感倾向值保持不变。最终句子的情感值大于0的判定为褒义,小于0的判定为贬义,等于0的则为中性。
本文通过准确率、召回率和F值三个指标评价测试结果。利用本文构建的网络情感词典和未扩展的维吾尔语褒贬情感词典进行维吾尔语句子极性判断的结果如表4所示。

表4 基于两种情感词典的维吾尔语句子极性判断结果对比
从表4可以看出,利用本文扩展的网络情感词典进行文本倾向性判别的准确率、召回率、F值均优于使用维吾尔语褒贬情感词典的实验结果,其主要原因是本文提出基于网络语料扩展维吾尔语情感词的算法,扩展了一部分维吾尔语网络情感词和专用情感词,从一定程度上丰富了维吾尔语情感词汇,而实验使用的测试语料又来自维吾尔语网站以及微博语料的维吾尔语翻译,因此明显提升了维吾尔语句子倾向性判别的分类性能,这充分证明了本文提出的基于连词扩展维吾尔语情感词算法的可行性和有效性。
5 结束语
情感词典作为文本倾向性分析的基础资源和重要工具,其词库的质量和数量直接影响着文本句子倾向性判别的性能。目前,维吾尔语的文本情感分析研究尚处于起步阶段,面临无任何可用维吾尔语情感词典资源的现状,项目组经过前期研究构建了维吾尔语褒贬情感词典,为了不断完善该词典,本文进行维吾尔语情感词的自动扩展研究。在总结维吾尔语情感句中搭配关系的基础上,首先依据句子中情感词与连词、程度副词的共现规律,设计候选情感词提取算法,利用搜集的网络文本语料进行候选情感词的抽取。然后继续运用维吾尔语并列连词衔接极性词汇的特征,借助已构建的褒贬情感词集、维吾尔语反义词词典和互联网的海量语料,提出利用搜索引擎获取候选词与褒贬义词的关联紧密度,并设计相应的得分算法获得候选情感词的极性值,最后根据得分判别词汇的褒贬类别。
经上述扩展算法,最终得到褒义词185个,贬义词239个,并通过实验证明了使用扩展后的情感词典进行句子倾向性判别的准确率、召回率以及F值均有所提高,说明本文提出的情感词扩展算法能够有效抽取并判别情感词,实现情感词的自动扩展,不断优化情感词典质量,为进行维吾尔语不同粒度的情感倾向性分析提供高质量的支撑资源。本文在情感词扩展过程中仅利用了维吾尔语情感词的连词和程度副词特征,后续将考虑运用维吾尔语感叹词以及派生词汇等多种特征进行情感词的扩展研究,进一步完善和提高情感词典的质量。
[1] 年梅,范祖奎,刘若兰. 维吾尔语褒贬情感词典构建研究[J]. 计算机工程与应用,2017(04): 152-155,162.
[2] Kamps J,Marx M,Mokken R J.Words with attitude[C]//Proeeedings of the 1st International Conference on Global Wordnetl.2002: 332-341.
[3] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报,2006(01): 14-20.
[4] 黄硕,周延泉. 基于知网和同义词词林的词汇语义倾向计算[J]. 软件,2013(02): 73-74,94.
[5] 金宇,朱洪波,王亚强,等. 基于直推式学习的中文情感词极性判别[J]. 计算机工程与应用,2011,(34): 164-167.
[6] Hatzivassilglou V,Mc Keown K R.Predicting the semantic orientation of adjectives[C]//Proceedings of ACL-97,the 35th AnnualMeeting of the Association for Computational Linguistics,Ma-drid,ES,1997: 174-181.
[7] 王科,夏睿.一种基于连接关系的中文情感词典构建方法[C].第十四届全国计算语言学学术会议,2015.
[8] Turney P D,Michael L L.Measuring praise and criticism: Inference of semantic orientation from association[J].ACM Transactions on Information System,2003,21(4): 315-346.
[9] 阳爱民,林江豪,周咏梅. 中文文本情感词典构建方法[J]. 计算机科学与探索,2013(11): 1033-1039.
[10] 禹龙,田生伟,冯冠军. 维吾尔语情感词汇自动识别[J]. 计算机工程,2011(07): 213-215.
[11] Hatzivassiloglou V, McKeown K R. Predicting the semantic orientation of adjectives[C]//Proceedings of the 35th annual meeting of the association for computational linguistics and eighth conference of the European chapter of the association for computational linguistics. Association for Computational Linguistics, 1997: 174-181.
