基于大数据的分类算法研究-以乳腺癌TNM分期为例
2018-05-03王钟廉
王钟廉
(西安交通大学附属中学,陕西西安,710000)
0 前言
随着当今世界经济、文化、政治等的高速发展,计算机自20世纪50年代产生以来,便经历着一代又一代的革新前进,并很快的渗透到社会生活的方方面面,为人们的工作、学习带来了翻天覆地的变化,越来越成为了人们生活中不可分割的一部分。与此同时,近些年来,数据挖掘、大数据、云计算、机器学习,深度学习等最新技术越来越受到科研工作者的青睐[1],引起了广泛的研究兴趣,并在许多领域中得到不同程度的转化利用,成为促使我国经济发展与技术革新的一大驱动力量。我们每天被科学数据、医疗数据、金融数据、销售数据等各式各样的海量数据所淹没,如何从大量的、有噪声的、不完全的、模糊的实际应用数据中提取出隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识成为当前困扰着人们的一大难题。在此大背景之下,数据挖掘技术应运而生。
数据挖掘是20世纪末逐渐形成的一个多学科交叉领域,它是一个融合了人工智能、机器学习、统计学以及知识工程等诸多领域技术的一个多学科交叉领域。目前,已经成功地应用在金融、零售、医药、通讯、电子工程、航空等有大量数据和深度分析需求的领域,是当前数据库和信息决策领域的最前沿研究方向之一[2]。例如,数据挖掘技术在CRM(客户关系管理)中的应用,成功地将数据库中的海量数据转变为极具实用价值的分析依据,为生产新产品提供决策[3],帮助企业确定客户的特点,提供个性化的服务;利用数据挖掘技术研发的指纹、虹膜,人脸等生物特征识别技术,成功地应用到现实安全加密,人事考勤之中,促进了生产力的发展;分类算法在医学影像上应用,成功的鉴别出了精神疾病患者区别于健康人的生物标志,促进了医学研究的不断进步,在辅助医师做出正确的诊断,并及时的采取治疗措施上取得了巨大成功。在此热潮的推动下,各行各业都在加紧步伐利用数据挖掘技术发掘潜在价值,创造新的财富。
1 研究内容
中医药物治疗乳腺癌具有广泛的适应症和独特的优势。根据临床医生的经验,各项中医症素表现与乳腺癌不同分期阶段存在一定的关联关系,中医症状间的关联关系和诸多症状之间的规律性。但是这种单纯依靠经验的诊断方法缺乏统一的规范,难以做到诊断的标准化。其次,疾病的复杂性和体质的差异,造成病人是多种症素兼夹复合,有时临床医师可能会被自身的经验所误导。
因此,可以通过一定的规则,挖掘出各中医症素与乳腺癌TNM分期之间的关系。探索不同分期阶段的乳腺癌患者的中医症素分布规律,指导乳腺癌的中医临床治疗。数据挖掘技术发展较为成熟,具有坚实的理论基础,充分利用它在处理大数据方面的优势,通过尖端的算法充分分析复杂无序数据背后潜在的信息。本论文研究的意义在于,通过对临床医学数据的分析,以期得到影响乳腺癌不同分期阶段与各项中医症素的交互关系,并且依据规则分析病因、预测病情的发展以及为未来临床提供有效借鉴。同时,针对其他类型的实际问题,可以利用类似的研究思想进行分析[4]。
2 研究方法
本实验的主要目的是利用数据挖掘的算法对数据进行处理,得到六项中医症素(肝气郁结、热毒蕴含、冲任失调、气血两虚、脾胃虚弱、肝肾阴虚)得分与乳腺癌TNM(H1、H2、H3、H4)分期之间的关系。这是一个典型的分类问题,可以见四个乳腺癌TNM分期看作要划分的类别,六项中医症素当作属性特折,因此可以简化为利用特征进行分类的问题。在各种分类算法中,我们采取基于树的分类器方法。具体地,我们拟采用三种最常见的分类方法,分别是决策树,分类与回归树(CART),随机森林(randomforest)[5]。
■2.1 决策树
决策树,其核心是ID3算法,它是最简单与基础的分类器。它将一个样本的属性特征进行层层分裂,最后得出其分类类别,因其上小下大的形状酷似一颗倒悬的树而得名。ID3算法就是在每次需要分裂时计算出每个属性的信息增益,然后选择信息增益率最大的属性进行分裂[6]。
所谓信息增益是针对一个一个特征而言的,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。计算信息增益首先要计算信息熵,信息上就是一个离散随机事件出现的概率,一个系统越有序。
假如有变量X其可能的取值有n种,每一种取到的概率为Pi,那么X的熵就定义为:
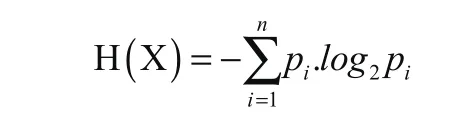
如果系统中存在m个变量X,那么总的信息熵为:
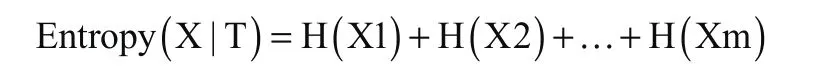
分裂X所带来的信息增益为:
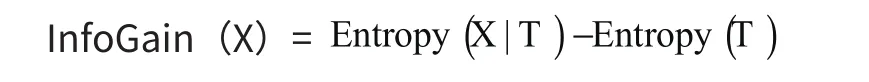
通过选取信息增益最大的属性结点,就可以完成决策树的构建。
■2.2 分类与回归树
分类与回归树的英文是Classi fi cation and regression tree,缩写是CART。分类与回归树与简单的决策树算法最大的不同在于,CART本质是对特征空间进行二元划分(即CART生成的决策树是一棵二叉树),内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。对于目标类别大于两个的实际问题而言,CART算法在进行树的构建的过程中通过考虑将目标类别合并成两个超类别,来进行二元划分。
具体地,CART是通过一种叫做Gini指数的指标进行最优特征的选取。
GINI指数是一种用来度量样本内分布差异大小的一项指标,最开始来源于经济学家对某地区的收入分配差异。Gini指数是介于0~1之间的数,0-完全相等,1-完全不相等;总体内包含的类别越杂乱,GINI指数就越大。基尼指数关注目标变量里最大的类,它试图找到一个划分把它和其他的类区分开来。
■2.3 随机森林
随机森林英文Random Forest顾名思义,Random就是随机抽取,Forest就是说这里不止一棵树,而由一群决策树组成的一片森林,连起来就是用随机抽取的方法训练出一群决策树来完成分类任务。
随机森林用了两次随机抽取,一次是对训练样本的随机抽取;另一次是对变量(特征)的随机抽取。对样本的随机抽取是指在对每一棵树的模型构建中,通过有放回的抽取与原始样本大小相等的样本来作为训练数据集[7]。一方面解决样本数量有限的问题,另一方面由于每次抽取的样本都是随机的,可以保证构建的树之间存在差异。而对样本的随机抽取,是指每次构建分类树的时候都从所有特征里抽取相同数量的部分特征,从而使得每棵树实际用到的特征都不是完全一样的。RF的核心是由弱变强思想的运用。每棵决策树由于只用了部分变量、部分样本训练而成,可能单个的分类准确率并不是很高。但是当一群这样的决策树组合起来分别对输入数据作出判断时,可以带来较高的准确率。有点类似于俗语“三个臭皮匠顶个诸葛亮”。由于构建了多颗决策树,每棵树都可以做出分类决策结果,根据少数服从多数的原则,最后的类别由所有树中票数较高的那个类别所决定。随机森林有两个重要的参数一是树节点预选的变量个数,二是随机森林中树的个数。随机森林相较于前两种分类器最大的特点是,随机建立了多棵分类树,通过投票决定最有优分类,这样做大大提高了分类的准确性但增大了运算量。
3 实验分析
图1所示为四种乳腺癌TNM分期所包含的样本数量,图2表示的是六项中医症素中存在缺失值的情况。在实际应用中,由于各种不确定因素,数据极易受噪声、缺失值等因素的影响,导致数据的质量变低。对于样本量有限的数据而言,基于低质量的噪声数据构建的模型常常会偏离实际的情况,从而使得模型的通用性变低,不能很好的应用在其他场景之中。运用数据预处理技术,可以显著的提高挖掘模型的总体质量[8]。

图1 TNM分期的样本分布情况
在本试验中,分别采用了三种不同的分类器算法来对乳腺癌TNM分期阶段进行分类研究,并比价了三种算法的分类性能。在这里,分类性能好坏主要是通过分类准确率来进行衡量的。分类准确性即为所有通过算法正确分类的样本数占总样本量的比例即:
分类准确率=准确分类数÷参与分类样本总数×100%
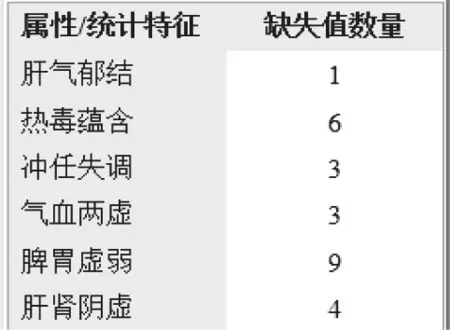
图2 属性缺失值的分布情况
为了对缺失值进行数据预处理操作,比较了两种不同的缺失值替换策略,分别是直接去掉含缺失值的样本以及利用对应属性特征的均值替换缺失值。表1所示即为实验结果,由表可知,三种分类算法中,随机森林取得了最高的分了性能,说明随机森林方法在该问题的研究中具有较大的优势;对于两种确实只替换策略,取得的结果比较接近,其中去掉缺失值策略稍微高于利用均值替换缺失值,这可能是由于本实验中包含的样本相对较多,去掉其中较少的包含缺失值的样本没有对构建的模型造成影响。

表1 基于三种分类器算法在不同缺失值替换策略下的分类性能比较

表2 随机森林中不同数量树对分类结果的影响
此外,由于随机森林是一种受包含树的个数影响较大的算法,因此在此基础之上,为了研究树的数量对其分类性能的影响,我们将树的个数分别设置为10,30,50,100,200,300,500,1000。由表2结果可知,随着森林所包含的树越来越多,分类性能由92.01%到96.12%逐渐升高。由此可见构建决策树的个数越多,分类的准确率也就越高。但是因此所带的是计算速度的降低。
4 总结
数据挖掘是一种针对海量数据进行处理分析的技术,能够发现隐藏在数据之中的潜在有价值信息,将数据挖掘的知识应用到临床实践当中是一次有意义的尝试过程。本论文主要利用数据挖掘中的分类算法对乳腺癌不同分期阶段进行分类研究,通过对决策树,分类与回归树以及随机森林三种方法的分析,我们发现随机森林的分类性能要明显的高于其他两种。此外,随机森林算法的性能受其所包含的树的个数影响较大,一般情况下树越多,分类结果越高。这可能是因为随着树的增多,随机采样的样本越均匀,最后构建的模型就越稳定,更具有代表性。
在现实生活中,数据挖掘技术处理可用于多种实际问题的分析处理之中,尤其是在医疗领域中的应用可以大大促进理论知识到临床实践的转化。
* [1]赵倩倩, 程国建, 冀乾宇. 大数据崛起与数据挖掘刍议[J]. 电脑知识与技术, 2014, 33): 7831—7833
* [2] 朱建平, 张润楚. 数据挖掘的发展及其特点[J]. 统计与决策,2002,( 07): 71—72.
* [3] 李宝东, 宋瀚涛. 数据挖掘在客户关系管理(CRM)中的应用[J]. 计算机应用研究, 2002, 19(10): 71—74.
* [4]彭丹, 谢鹏.大脑认知功能的神经影像学研究现状[J]. 中国临床康复 , 2006,38): 133—135.
* [5]赵紫奉,李韶斌,孔抗美.基于决策树算法的疾病诊断分析[J].中国卫生信息管理杂志,2011,8(05):67—69.
* [6]赵微,苏健民.基于ID3算法决策树的研究与改进[J].科技信息(科学教研),2008,(23):383+392.
* [7]方匡南,吴见彬,朱建平,谢邦昌. 随机森林方法研究综述[J].统计与信息论坛,2011,26(03):32—38.
* [8]李晓菲. 数据预处理算法的研究与应用[D].西南交通大学,2006.
