基于混合云储存的网关转储优化算法研究
2018-05-03李燕梅
李燕梅
(滇西科技师范学院,云南临沧,677000)
0 引言
在信息化爆炸的社会,从个人到组织对于存储空间的需求以及要求缺口得到进一步的扩大。对于维护大规模数据的成本也随之水涨船高,信息增长的速度日益加快,而本地存储却没有太大进步,因此,新的数据存储备份方案应运而生,其成本低廉,部署方便,不仅能够保证数据的安全性还能保证数据的私密性。目前的存储系统向着网络化、分布式方向发展,并最终催生了云存储服务。云存储改变了人们对存储的原有认知,这使得人们不必再单独组建和管理储存系统,而是存储在专业的供应商上面,通过支付一定的费用既可享受存储管理服务。云存储不需要进购存储设备也无须专人对其进行管理,因而大大降低了存储的成本,总而言之,云存储以低廉的价格贩售高效的存储服务,从而得到用户的肯定扩大了应用范围。
1 云储存中文件特征分析
文件的存储格式有许多种,这取决于不同企业的应用。要管理这些种类繁多、数量规模大、消耗存储空间大的混合数据,要以熟练掌握数据的特征及分部状况为前提,才能够提高管理者对数据进行处理的流畅度。
■1.1 数据量大
混合云存储能够容纳海量数据,因此,存储量大是云存储的一大特征。传统的文件大小通常来说不超过5000KB。而云存储容量具有足够的扩展能力,往往能够达到PB级别。在大规模类型不同的文件占存中能够体现出来。文档一般从几M到几G不等,占存如此大的文件通常需要依据其文件特征来决定转存对象。
■1.2 数据种类繁多
混合云存储可支持的文件存储种类较为多样。这是基于云存储所服务的客户具有多样性所决定的。客户基于其所处行业的差异性以及其个人特性,赋予了存储文件类型的多样性。尽管文件数据来自同一个公司,但是其所显示的数据信息也有所差异,由此,可看出云存储可支持类型众多的文件存储。目前为止使用较为频繁的文件类型有文本、表格、图片、动画、音视频、压缩文件、网页、地理位置信息等。
■1.3 价值密度低
混合云存储文件价值密度低。基于混合云储存文件的用户多样性以及其高效的存储服务所提供的海量数据存储容量,进一步削弱了文件的价值。海量的数据决定了用户对数据的访问频率是不会太高的,因此多数数据对于用户来说其价值比较低。监控的视频文件就是一个典型的例子。监控视频连续不断的运作,其所产生的视频文件中较为有价值的信息只是几个时刻,然而却无法将无用的部分删除,因此监控视频文件中无效的数据占比极大。根据GEO的统计分析所得结论,往往TB容量级别的海量数据中,有价值的数据通常不到一个GB。
2 原有算法的不足
传统的分类缓存算法是基于用户的时间及使用频次进行计算的,其通过机器的学习的人工智能算法的重点是在文件属性上,缺少了对用户的整体关注。另一方面文件的访问、转储行为都是基于用户的喜好、目的、特点而产生的,与混合云存储的用户建立友好的关系通过网络社交渠道共享文件是极为正常的,因此混合云存储系统中活跃用户所提供的共享文件通常是热点数据,有鉴于此,根据用户的网络关系对文件价值进行评估具有重要意义。
3 基于混合云储存的网关转储优化算法研究
■3.1 算法思想
人是社会的主体,若将人抽象的看作是网络社会的节点,这个网络节点则可以互换消息,节点与节点之间可以描述为承担着交流的通道。在这样的模型中,节点不仅仅是信息发送也是信息接收的主动者。研究发现,网络拓扑结构与传输机构是传播信息数据的主力。 可以得知,网络社会中的信息传播简易度则随着各节点的连接程度的提高而提高。广为流传的信息主要基于初始化连接程度高且社会影响力大的节点。各种信息通过网络节点得到散布。然而,信息数据该以缓存的权重来判定数据信息进行缓存或者转存。其中缓存权重的大小是依据文件被访问的频次所决定的,因为文件的访问频次能够体现出发布者在网络社会中的重要位置。
云存储的受众广,用户之间存在网络节点关系。通过使用SNA的方法,可以在特定的云存储系统中划分出活跃度高、影响辐射力广的用户。这样的用户所传输、共享的文件成为局部热点文件的可能性极大,更应该归纳到私有云存储当中,以提高他人访问的便捷度。然而至今为止,现有的算法尚未体现出这个元素。
■3.2 PRE-SN 算法设计
(1) 首先要了解用户节点基于网络的相对位置。因此需要进一步简化云存储用户的网络关系。假设用户A与用户B、C、D、E、F、G之间是朋友关系。那么就可以用图1来表示。

图1 用户网络关系简化图
节点A 的相对网络中心度可以用Crd(x) 来表示:

n表示网络大小的取值范围,也可以说是网络用户的总数量。上图所显示的网络存储中总共有7个节点,那么n就取值为7,其中,节点A的度为6,因此可得出Crd(X)=6/(7-1)=1的结果。
(2)将用户所能访问的数据的集合以O示之,这里的O也可以看作是云存储中的文件数据量,文件对象为d,那么文件对象的取值范围是d∈O,文件的大小以Sd来表示,而C是缓存数据的大小,用户所发送的请求队列则可以通过集合R={R1.R2...R3}来表示,那么缓存文件则可以用S={S0,S1..Sm}的集合来表示,其中S0表示的是初始化缓存的大小,则对于每一个Sk(k=0,1,...m )可以得出如下式子:
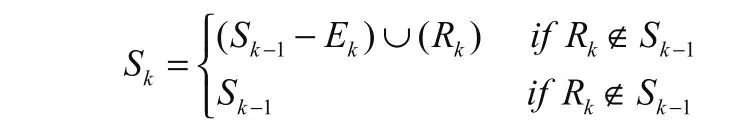
Ek的取值意义是本地缓存中即将要被删除的文件的大小,则其Ek∈Sk-1。需要通过用户的读取模型来制定转储替换的策略。
主要过程:
①初始化预测模型:基于用户的网络位置,得出用户网络中心Crd。
②建立预测模型:通过网络中心度来评价用户所发出的请求,并以Q来代表所构建的预测集合。Q包含了活跃用户发送与接收数据的hash。
③寻找合适的对象进行替换:利用传统的算法寻找有替换价值的对象。
④如果Rk∉Q,则表示没有缓存可以被替换,那么就重复步骤三,直到在有充足的空间容纳新请求的同时寻找到符合的替换对象。
⑤替换缓存。
■3.3 算法实现
(1)初始化预测模型
预测模型的建立就是构建一个包含用户节点相对中心的映射的过程。
输入:SN网络
输出:用户i相对中心度
用1,2....n标记每一个用户节点
计算每一个用户节点的度和相对网络中心度Crd(x),并建立一个映射表(≺ nodenumber, Crd(x ))
返回
(2)预测
预测对象集合涵盖了所预测范围内的对象以及具有确定性的阀值。进行预测第一步要做的是跟进用户节点所传输的信息与所设定信息的最小关联度的比较研究,其结果若显示其在Q的取值未超出预定值的前提下超过了最小关联度,那么就将Q写入新的数据请求hash。若前提条件不成立则需要遵循所制定的策略来清空Q值,最后将Q写入新的请求对象hash,并调整Cmin的取值为请求信息所属用户的关联度。
输入:用户Crd映射表,用户请求队列,阀值,设置Cmin=0
输出:预测对象集合Q
(3)PRE-SN初始化和得到预测集合Q之后,利用预测集合和请求序列构造出一个新的缓存S。
输出S可以作为本地私有云储存,也可以结合其他算法使用,用作传统缓存算法优化的一个策略。

图2 预测对象集合Q

图3 预测缓存S
■3.4 算法评价
结果显示基于网络关系的对象预测算法比之现行的缓存算法转存策略有较好的效果。从另一方面看,基于用户的网络关系,以所划分出用户网络关系度高的用户所发布的内容作为预测对象,大大提高了转存算法的效率。
4 结语
本文鉴于现行算法中忽略了社会网络关系因此设计了新型转储算法,并建立了具有社会化特征的缓存行为模型,并创建对象预测集,大大提升了缓存命中率。该算法体现出了适用性广的优势—一般系统都可以使用,其兼容性较强。需要注意的是,PRE-SN的算法优点有所局限,其局限性体现在其会随着系统缓存能力的增大而逐渐减小。因为系统缓存增大就意味着允许各种请求,那么用户网络关系的预测效用就会减弱,这时候应用PRE-SN算法并没有很明显的提升转储性能的作用。
* [1]申彤.云存储网关的分布式缓存系统的研究与实现[D].国防科学技术大学,2012.
* [2]程勇.云存储中密文访问控制机制性能优化关键技术研究[D].国防科学技术大学,2013.
* [3]李苗在.混合“云存储”的前景展望[J].电脑知识与技术.2011(29).
* [4]夏桂丹.云存储网关协议适配器和缓存管理的研究[D].华中科技大学,2013.
* [5]赵铁柱,邓见光.面向大规模数据备份的云存储网关研究[J],计算机光盘.2013.12
