可拓传导知识挖掘系统的设计与实现
2018-05-03叶广仔李卫华刘晓蔚
叶广仔 李卫华 刘晓蔚
1(东莞职业技术学院计算机工程系 广东 东莞 523808) 2(广东工业大学计算机学院 广东 广州 510006) 3(东莞职业技术学院管理科学系 广东 东莞 523808)
0 引 言
事物之间存在各种各样的相关关系,一个变换除了导致其作用对象产生改变外,由于传导作用,会导致与其相关的对象改变。这些变化有正面的,有助于决策者处理矛盾问题;也有负面的,影响决策者处理矛盾问题。
如果能从已有的数据库中挖掘到有关这些传导变换[1]的传导知识[2],就可以根据这些知识帮助决策者利用传导变换的正面作用,避免传导变换的负面作用。但是,单靠人力去挖掘传导知识,其效率低且难以实现及推广。因此,提出利用计算机技术协助人们完成这个任务。可拓传导知识挖掘系统结合可拓数据挖掘技术[3]、数据库技术、可视化技术而形成的人工智能系统,可挖掘动态的传导知识。
自从可拓学的创立者蔡文研究员1983年发表了处理不相容问题的首篇论文以后,逐步开始建立不相容问题求解的基础理论与方法,探索了一套形式化定量化方法处理不相容问题的规律和方法。并在2004年提出可拓数据挖掘[4],经过十多年的研究和探索,初步形成一套挖掘可拓知识的基本理论以及基本方法[5]。用可拓学的理论和方法,去挖掘数据库中与解决矛盾问题的变换有关的知识,包括可拓分类知识、传导知识以及其他有关变换的知识,统称可拓知识[6]。根据“中国知网”数据统计,2010年至今研究并发表的“可拓数据挖掘”相关文献共43篇,主要涉及可拓数据挖掘的理论研究、方法研究以及应用研究等领域。
近几年可拓数据挖掘的应用及其计算机实现逐渐引起学者重视,如文献[7]通过可拓数据挖掘方法实现了对黄河三角洲土地利用的评价;文献[8]以CPI指数的变换对产品销售数据的影响为例来研究传导知识的挖掘;文献[9]进行了客户价值可拓知识挖掘软件研究;文献[10]开展了可拓数据挖掘技术在煤矿瓦斯预警中的应用研究。上述文献主要通过可拓数据挖掘方法针对某个特定问题或领域进行独立的研究,未能形成具有通用性的可拓数据挖掘平台。为此,本文可拓数据挖掘系统开展以下三方面的创新性研究:
(1) 在可拓数据挖掘方法的基础上,设计传导知识以及可拓分类知识的挖掘流程及算法,研究传导知识以及可拓分类知识挖掘的计算机实现。
(2) 利用数据库技术,对不同领域的“原始数据库”,通过人机交互动态生成相应的“传导效应库”、“传导信息元库”、“可拓分类库”以及“可拓分类知识库”,提高系统的灵活性及通用型。
(3) 采用MVC架构模式,使用开源软件WAMP技术平台对系统进行开发及部署,提升用户交互能力及系统模块化程度,降低开发以及运维成本,有利于系统的应用推广。
此外,本文以某学院出台的科研绩效分配制度对教师工作影响程度进行定“量”和定“性”分析为应用案例。结果表明支持度及可信度较高的传导知识,有效地帮助院校管理层从量上了解某策略对教师科研及教学工作量产生正面或负面影响的程度。
1 可拓传导知识挖掘系统的知识挖掘流程
可拓传导知识挖掘系统实现了从原始数据库挖掘出传导度知识及可拓分类知识[11]的功能,如图1所示。
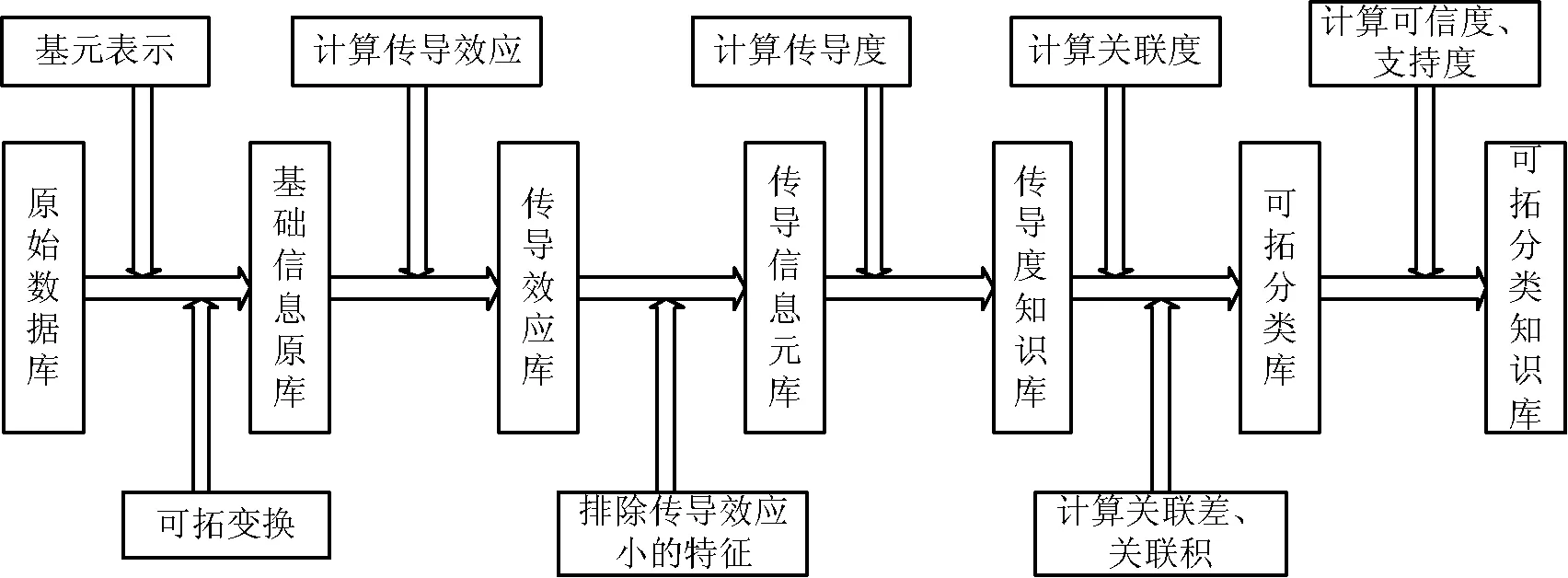
图1 可拓传导知识挖掘系统流程图
主要包含以下步骤:
(1) 对原始数据库中数据进行预处理,并对相关信息进行基元表示,根据变换前后的数据形成“基础信息元库”;
(2) 计算“基础信息元库”中信息元的传导效应[3],生成“传导效应库”,排除传导效应小的对象特征,形成“传导信息元库”;
(3) 计算传导信息元的传导度[3],获取变换关于信息元的传导度及传导度区间,形成“传导度知识库”;
(4) 建立关联函数[3]并计算传导信息元变换前后的关联度、关联差及关联积[3],生成“可拓分类库”;
(5) 计算各种可拓分类的支持度及可信度[3],挖掘出传导信息元的可拓分类知识,形成“可拓分类知识库”。
2 可拓传导知识挖掘系统的数据库及框架设计
可拓传导知识挖掘系统通过可拓传导知识挖掘方法,挖掘主动变换[12]的传导对象、传导特征量值变化、传导度以及可拓分类[13]等传导知识,为决策者提供更量化的参考依据。系统可根据不同的原始数据库,动态生成“传导效应库”、“传导信息元库”、“可拓分类库”以及“可拓分类知识库”,从而提高系统的灵活性及通用型。下面对系统的数据库及系统框架进行设计,以确定其数据库结构以及业务功能模块。
2.1 系统的数据库设计
可拓传导知识挖掘系统使用MySQL数据库管理系统对信息数据进行管理,主要包含原始数据库、基础信息元库、传导效应库、传导信息元库、传导度知识库、传导分类库以及可拓分类知识库等。其中,除原始数据库外,其他数据库通过可拓传导知识挖掘系统在可拓知识挖掘过程中通过人机交互动态生成,使系统具有良好的通用性。下面以基础信息元库及传导分类库为例介绍可拓传导知识挖掘系统的数据库设计:
(1) 基础信息元库:用于存储传导变换前后的信息元数据,其字段的个数、名称及类型来源于“原始数据库”,结构相对固定,如表1所示。
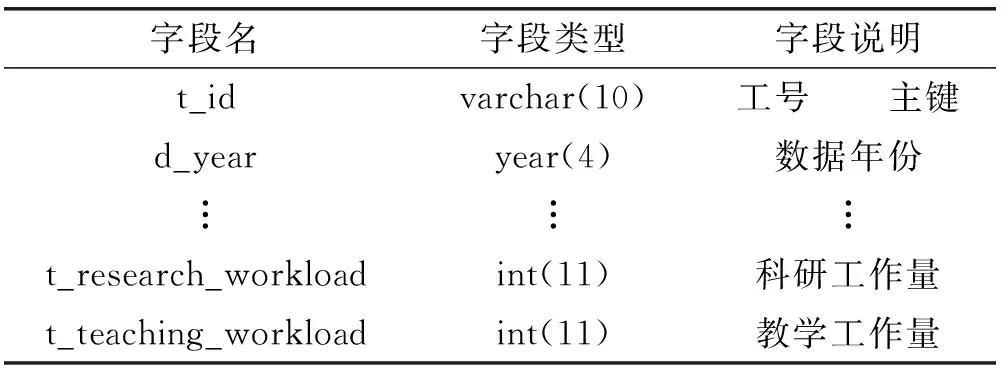
表1 教师基础信息元库结构
(2) 可拓分类库:如表2所示,“可拓分类库”的字段个数、名称及类型受“传导信息元库”影响,结构不固定。其中,t_id、d_year、t_research_workload、t_teaching_workload等4个字段来源于“基础信息元库”。其他字段通过可拓传导知识挖掘系统动态生成,用于存储传导信息元变换前后的关联度、关联差、关联积以及可拓分类等信息。
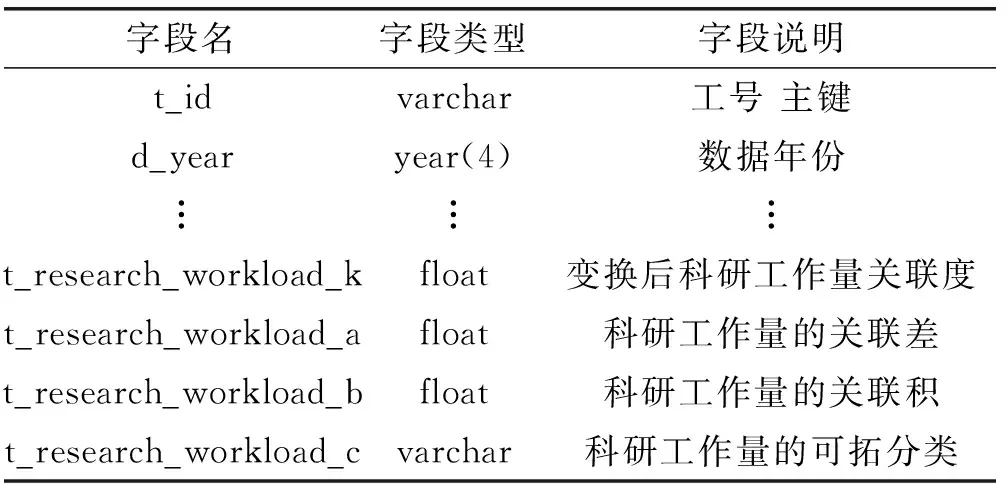
表2 教师工作量可拓分类库结构
2.2 系统的MVC框架模式设计
可拓传导知识挖掘系统采用MVC[14]架构模式,提升用户交互能力及系统模块化程度。使用开源软件的WAMP技术平台进行开发及部署,在一定程度上降低了开发以及运维成本,有利于系统的应用推广。
可拓传导知识挖掘系统通过MVC[15]框架模式实现业务逻辑、数据、界面显示的有效分离,系统由视图层、控制层以及模型层等3层模块组成。如图2所示,其中视图层通过html5+css3+bootstrap技术实现数据显示及用户请求提交;控制层采用jQuery+Ajax技术获取视图层用户输入数据,并向调用模型层业务模型;模型层利用PHP技术完成业务逻辑处理及数据库存储。
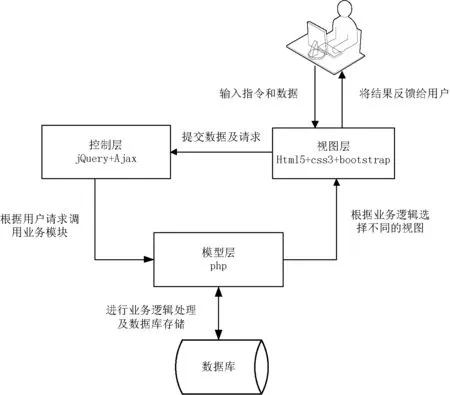
图2 MVC框架模式设计
3 可拓传导知识挖掘系统的原理介绍
下面通过某学院制定的科研绩效分配制度对教师工作量产生的传导变换为例,介绍可拓传导知识挖掘系统知识挖掘的相关原理。
3.1 数据记录的信息元表示
可拓传导知识挖掘系统通过信息元[16]表示数据库中的数据记录。利用教师信息元表示“基础信息元库”中教师1在t0年份的信息表示为:
同理,对于具有m个属性字段n位教师q年数据记录的“基础信息元库”通过信息元集合表示为:
{Iij(tp)}={(Oi(tp),cj,vij(tp)),i=1,2,…,n;j=1,2,…,m;p=1,2,q}
3.2 主动变换及传导变换
本案例中,科研信息元I0(t0)=(O0(t0),c,v(t0))=(科研(t0),分值,0元/分) ,发生主动变换φ,即实行科研绩效分配制度后,产生变化为:φI0(t0)=I0(tp)=(O0(tp),c,v(tp))=(科研(t0),分值,10元/分),p∈{1,2,3}。
其中,t0=2012,为主动变换前的年份,t1=2013,t2=2014,t3=2015为主动变换后的年份。
由于事物之间的相关性,科研信息元发生主动变换会导致与其相关的信息元产生传导变换。如教师信息元Iij(t)在科研信息元主动变换影响下,产生的变化属于传导变换,可表示为I0TIijIij(t0)=Iij(tp),i∈{1,2,…,n},j∈{1,2,…,m},p∈{1,2,…,q}。
3.3 传导效应计算
为了分析科研信息元I0(t0)发生主动变换φ是否导致教师信息元Iij(t0)产生传导变换I0TIij,需要计算教师信息元的各个特征cj是否发生变化,即是否产生传导效应。传导效应的计算机公式为:
Δvij=vij(tp)-vij(t0)tp>t0
(1)
以教师信息元t_research_workload特征为例,计算2013年的传导效应:
I17(t0)=(教师1(t0),c7,v17(t0))=(教师1(t0),t_research_workload,1 775),I17(t1)=(教师1(t1),c7,v17(t1))=(教师1(t1),t_research_workload,2 614),Δvij=vij(tp)-vij(t0)=2 614-1 775=839>0,可见,科研信息元发生主动变换后导致教师信息元产生传导变换。
3.4 传导度计算
在获取传导信息元集后,可通过可拓传导知识挖掘系统计算主动变换φ对传导信息元Iij的传导度,以了解科研信息元I0(t)的主动变换对教师信息元Iij(t)传导特征的影响程度。
传导度的计算公式:
(2)
根据I0(tp)=(科研(t),分值,v(tp)),有p=0时,v(tp)=0;p=1,2,3时,v(tp)=10。代入公式有:
(3)
3.5 关联度计算
可拓传导知识挖掘系统可通过计算传导变换前后传导特征的关联度,从而挖掘数据库中的可拓分类知识。以科研量c7及教学量c8两个特征为例,由于最优值为取值范围内的最大值,所以选取最优点为右端的简单关联函数计算关联度:
(4)
根据基础信息元库,变换前后科研量c7的取值范围:vi7∈[0,8 728],代入式(4)可得科研量c7关联度计算公式:
(5)
变换前后教师教学量c8的取值范围:vi8∈[60,1 015],代入式(4)可得科研量c8关联度计算公式:
(6)
3.6 可拓分类标准表
经过计算传导变换前后传导特征的关联度、关联差、关联积,可根据表3所示的传导信息元可拓分类标准对信息元进行分类,从而对信息元进行可拓分类。
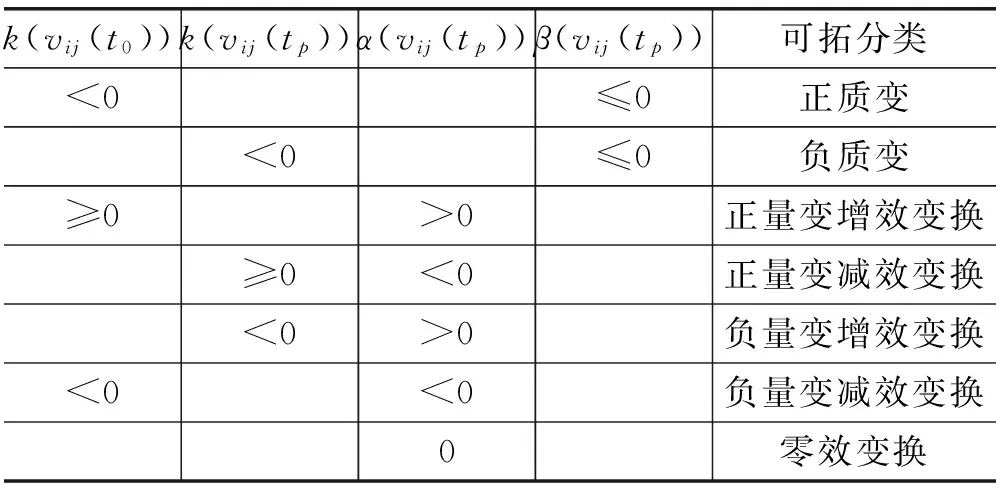
表3 传导信息元可拓分类标准表
表3中,k(vij(t0))为传导变换前传导特征关联度,k(vij(tp))为传导变换后传导特征关联度,α(vij(tp))为传导变换前后传导特征的关联差,β(vij(tp))为传导变换前后传导特征的关联积。例如:
当k(vij(t0))<0且β(vij(tp))≤0,表示传导信息元发生了正质变;
当k(vij(tp))<0且β(vij(tp))≤0,表示传导信息元发生了负质变。
3.7 支持度和可信度计算
可拓传导知识挖掘系统可通过支持度和可信度[17]计算来确定“正质变”、“负质变”等7种分类的重要程度和准确程度,从而挖掘出传导信息元的可拓分类知识。譬如,关于传导特征cj正量变增效变换的支持度和可信度计算公式为:
(7)
关于传导特征cj正量变减效变换知识支持度和可信度的计算公式:
(8)
式中:|{I}|为传导信息元总数,|E-|为负域内信息元的个数,|E+|为正域内信息元的个数,|E+(T)|为产生正量变增效变换信息元的个数,|E-(T)|为产生正量变减效变换信息元的个数。
4 可拓传导知识挖掘系统的案例实现
某学院2013年制定以下科研绩效分配制度:把科研成果按质量及数量折算为“分”,每年进行一次科研工作量统计。经考核,完成科研工作量者,按超出分数每1 分 10 元的标准给予奖励,否则扣发奖励津贴。在上述科研绩效分配制度的影响下,教师信息元产生怎样的传导变换,下面通过可拓传导知识挖掘系统进行相关知识挖掘。
4.1 数据预处理
对于教师原始信息表中34名教师4年共136条信息记录。为了避免干扰数据对知识挖掘的影响,首先去除2012年至2015年存在数据缺省或历年数据都为0的教师记录,形成图3主动变换前后“基础信息元库”。
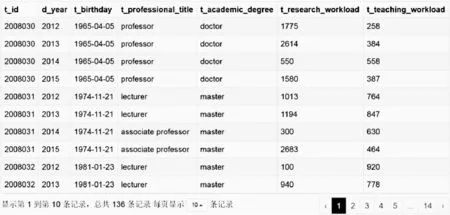
图3 基础信息元库
4.2 计算传导效应,获取传导信息元集
本案例中,特征t_id为教师工号,d_year为数据年份不进行传导效应计算,其余对象特征的传导效应根据式(1)计算结果如图4所示。
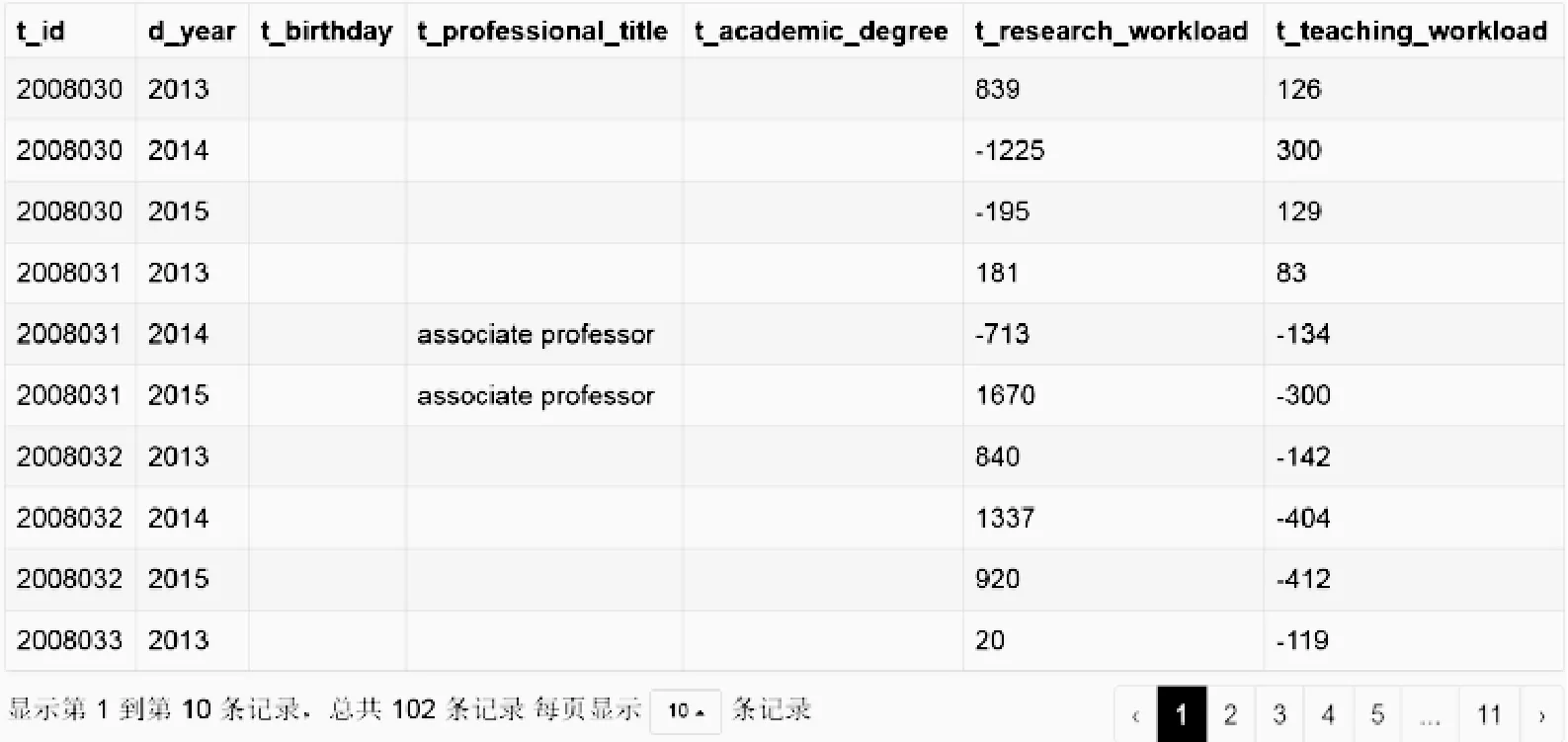
图4 传导效应库
图4中,t_name,t_gender,t_birthday与t_academic_degree共4个特征的传导效应为0,即2013年至2015年与2012年的特征量值没有发生变化。t_professional_title特征11个教师发生变化,支持度较低只有30%,因此上述5个特征为非传导特征。而科研工作量t_research_workload和教学工作量t_teaching_workload两个特征在主动变换φ影响下90%以上特征量值发生变化,称为传导特征。去除非传导特征,保留传导特征,生成如图5传导信息元库,称Iφ(Iij)={Iij(tp)}={(Oi(tp),cj,vij(tp)),i=1,2,…,34;j=7,8;p=1,2,3}为传导信息元集。

图5 传导信息元库
4.3 挖掘变换关于信息元的传导度知识
根据式(3),在图6界面中,输入科研工作原始分值0,主动变换后分值10。经传导度计算,获得如图7所示的教师信息元Iij(t)、科研工作量c7及教学工作量c8的传导度。如第1条记录所示,2013年教师1关于传导特征c7的传导度γ17(t1)为84,关于传导特征c8的传导度γ18(t1)为13。
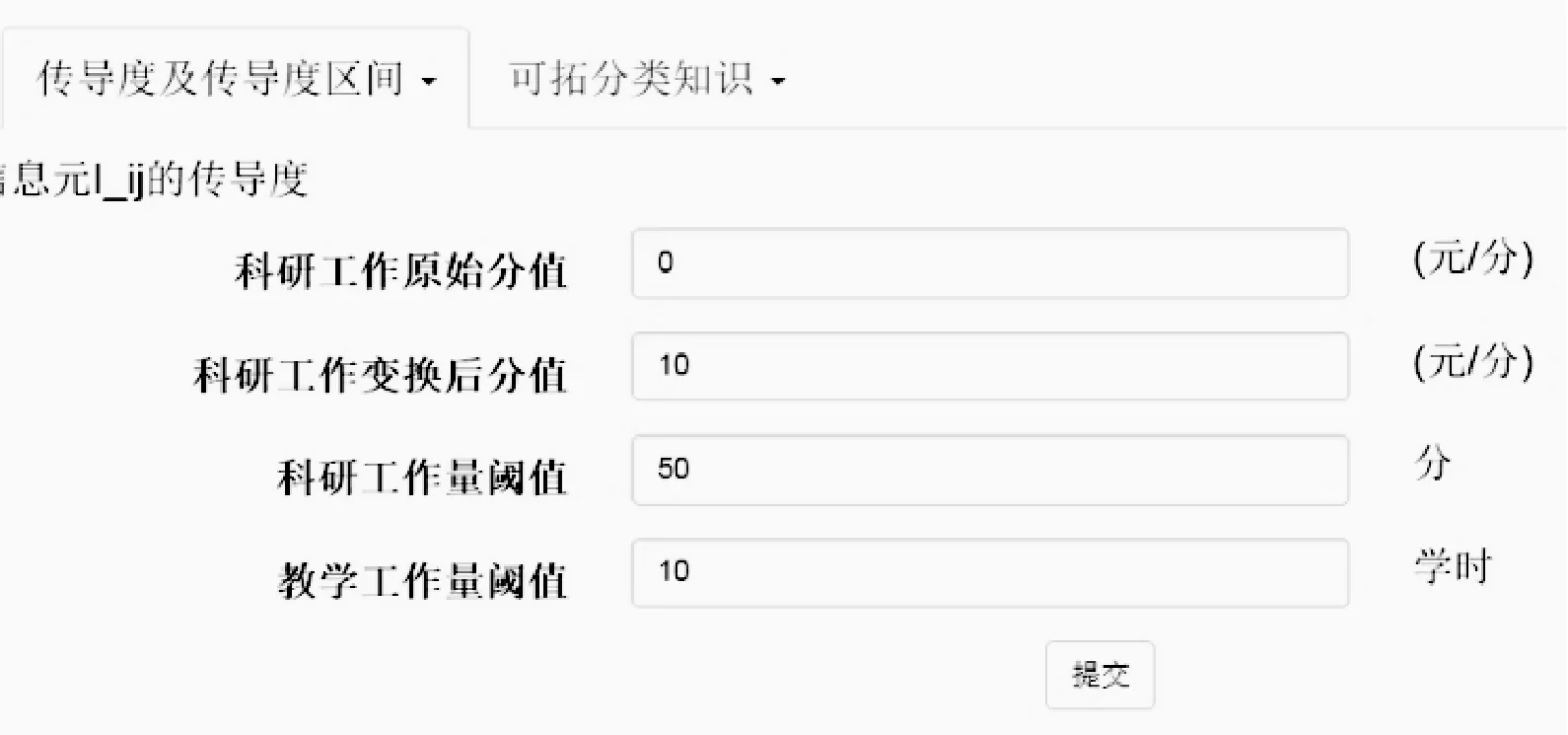
图6 传导度计算参数设置界面
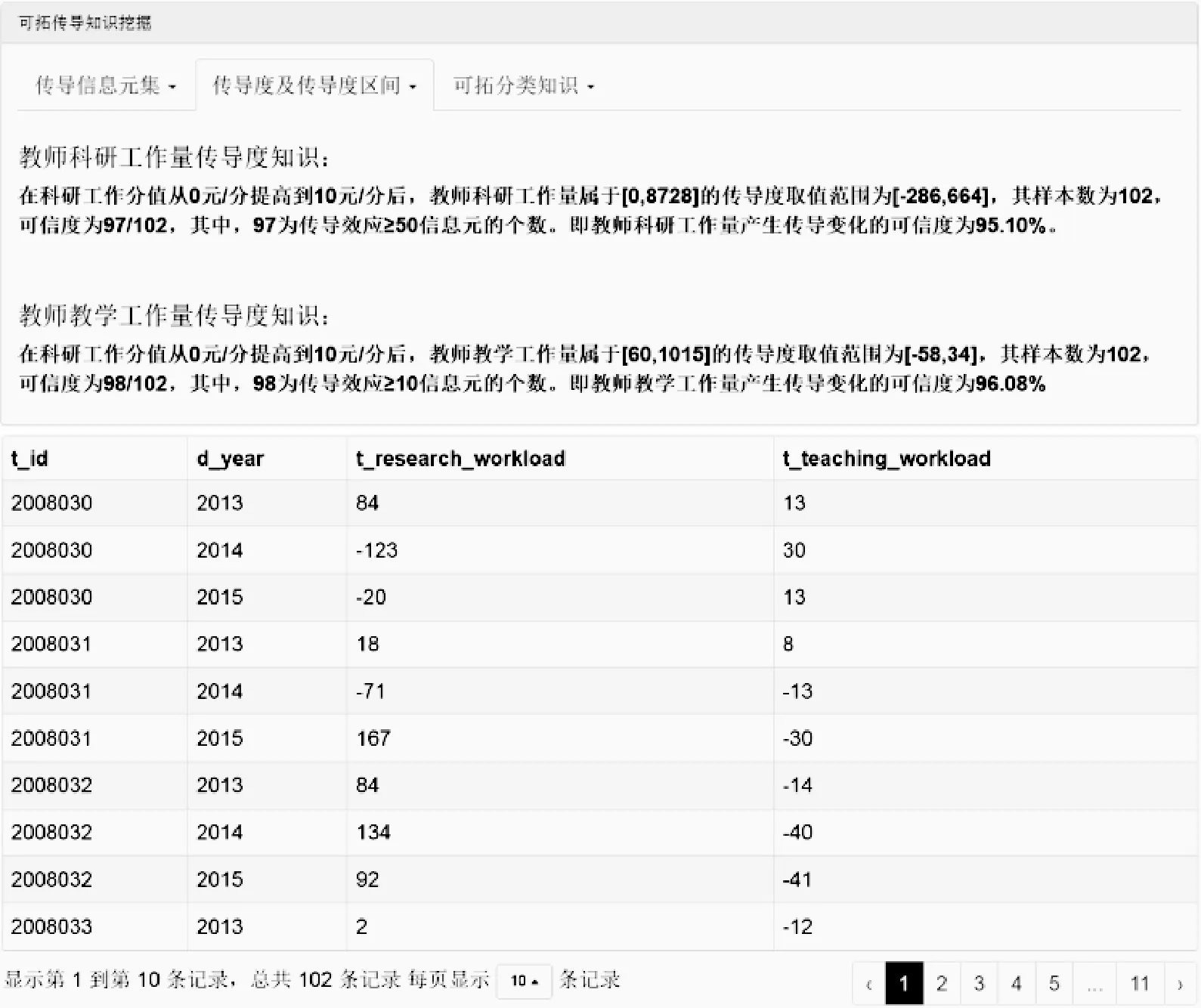
图7 传导度知识库
在图6中输入的科研工作量阈值δ7=50以及教学工作量阈值δ8=10,计算出集合{Ii7}={(Oi(tp),c7,vi7(tp)),i=1,2,…,34;p=1,2,3}中|{Ii7}|=|vi7(tp)-vi7(t0)|≥50信息元的个数为97,以及信息元{Ii8}={(Oi(tp),c8,vi8(tp)),i=1,2,…,34;p=1,2,3}中|{Ii8}|=|vi8(tp)-vi8(t0)|≥10信息元的个数为98。
结合图3基础信息元库,可获得图7传导知识库所示两条传导度知识:
(1) 若信息元Ii7,满足条件L:vi7∈[0,8 728],则有:
[φI0(t0)=I0(tp)]∧(Ii7L)⟹
此知识表示:在主动变换科研工作分值从0元/分提高到10元/分后,属于[0,8 728]范围的教师科研工作量传导度取值范围为[-286,664],其样本数为102,可信度为97/102,即教师科研工作量产生传导变化的可信度为95.10%。
(2) 若信息元Ii8,满足条件L:vi8∈[60,1 015],则有:
[φI0(t0)=I0(tp)]∧(Ii8L)⟹
此知识表示:在主动变换科研工作分值从0元/分提高到10元/分后,属于[60,1 015]范围的教师教学工作量传导度取值范围为[-58,34],其样本数为102,可信度为98/102,即教师教学工作量产生传导变化的可信度为96.08%。
4.4 挖掘传导信息元的可拓分类知识
可拓传导知识挖掘系统除可挖掘教师信息元Iij(t)的传导度知识外,还可通过计算传导变换前后传导特征的关联度、关联差以及关联积,以划分传导信息元发生量变或质变变换的具体类型,及其支持度和可信度。
4.4.1 计算传导信息元的关联度
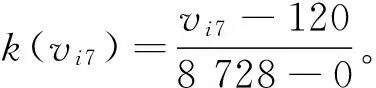
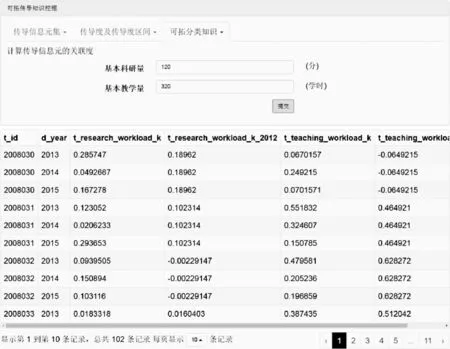
图8 关联度计算界面
经计算得出图8传导信息元Iij(t)变换前后的关联度情况。如第1条记录所示,教师1关于传导特征c7在2013年(变换后)的关联度为0.285 747,在2012年(变换前)的关联度为0.189 62;教师1关于传导特征c8在2013年(变换后)的关联度为0.067 015 7,在2012年(变换前)的关联度为-0.064 921 5。
4.4.2 计算传导信息元的关联差以及关联积
根据图8计算所得的关联度,可通过公式:α(vij)=k(vij(tp))-k(vij(t0))以及β(vij)=k(vij(tp))×k(vij(t0)),i∈{1,2,…,34},j∈{7,8},p∈{1,2,3}。分别计算教师信息元Iij(t)的关联差以及关联积。其中,图9第1条记录表示:教师1关于传导特征c7在2013年的关联差为0.096 127,关联积为0.054 183 3;关于传导特征c8在2013年的关联差为0.131 937,关联积为-0.004 350 76。
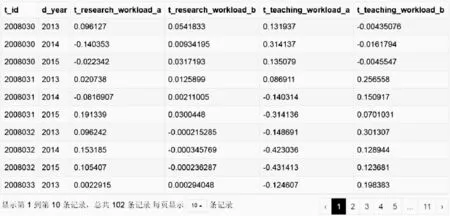
图9 传导关联差及关联积表
4.4.3 分析传导信息元的可拓分类
通过图8和图9所得的教师传导信息元的变换前关联度k(vij(t0))、变换后关联度k(vij(tp))、关联差α(vij(tp))以及关联积β(vij(tp))的取值,根据表3提供的可拓分类标准表,可对教师传导信息元进行可拓分类计算。
如图10所示,第1条记录表示:教师1关于传导特征c7在2013年的可拓分类为“正量变增效变换”,关于传导特征c8在2013年的可拓分类为“正质变”。

图10 可拓分类库
4.4.4 获取传导信息元的可拓分类知识
根据图10可拓分类库,关于传导特征c7的传导信息元总数|{Ii7(tp)}|为102,其中负域|E-|的信息元个数为27,正域|E+|的信息元个数为75。通过可拓传导知识挖掘系统的统计及分析,可得图11所示的科研工作量可拓分类知识库。以第3条记录为例,在传导变换T作用下,关于特征c7的传导信息元中发生正量变增效变换|E+(T)|的个数为51,代入式(7)计算其产生正量变增效变换的支持度和可信度:
(73.53%,68.00%)
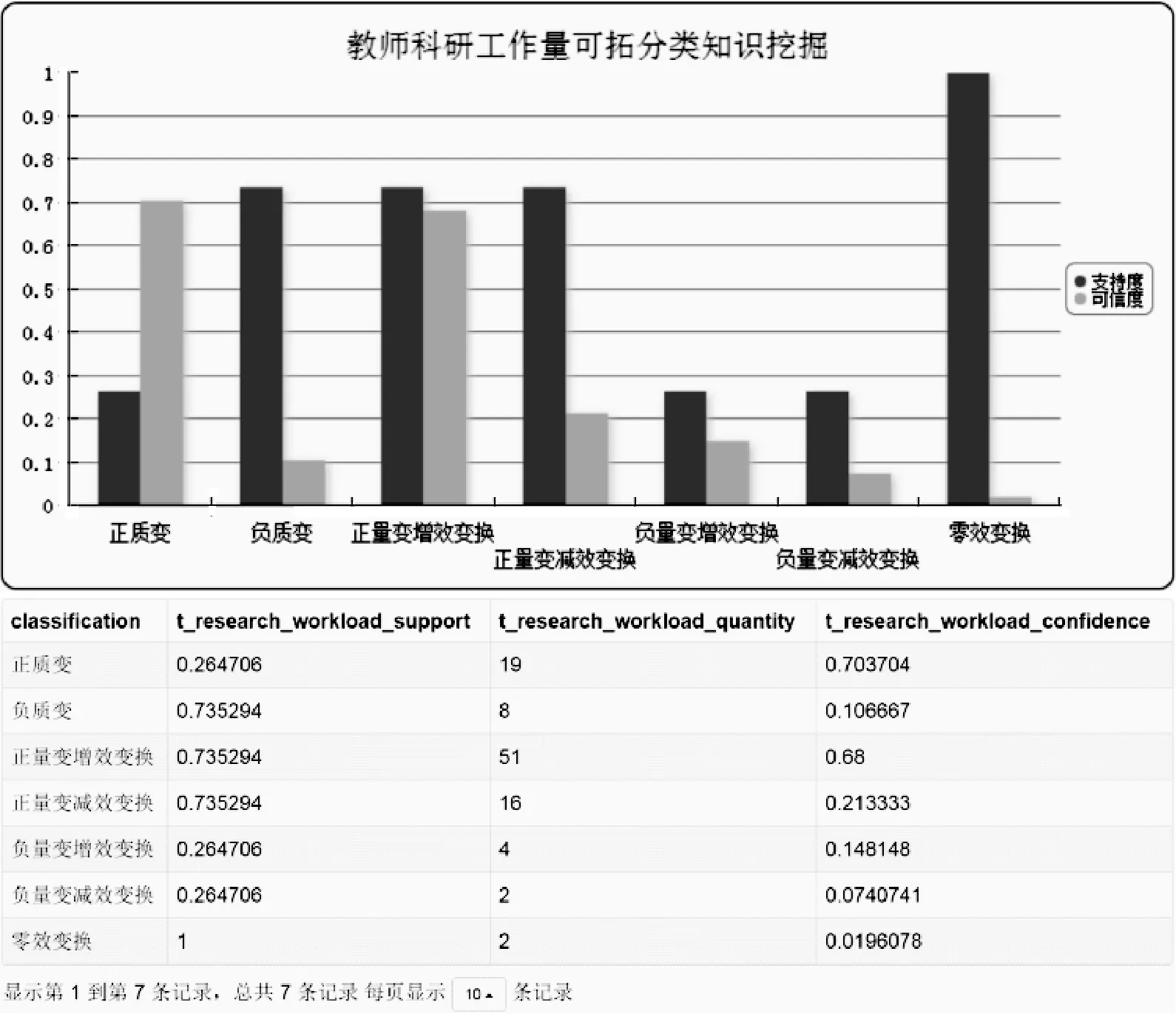
图11 科研工作量可拓分类知识库
此可拓分类知识表示:科研绩效分配制度出台前教师能够完成科研基本工作量120分。在科研绩效分配制度出台后科研工作量有了进一步的提升,此规则的支持度与可信度分别为73.53%与68.00%。这条知识是7种可拓分类知识中重要程度和准确程度综合最高的一条知识。同理,可计算其他6种可拓分类知识。
根据图10可拓分类库,关于传导特征c8的传导信息元中总数|{Ii8(tp)}|为102,其中负域|E-|的信息元个数为15,正域|E+|的信息元个数为87。通过可拓传导知识挖掘系统的数据挖掘可得图12所示的科研工作量可拓分类知识库。以第4条记录为例,在传导变换T作用下,关于特征c8的传导信息元中发生正量变减效变换|E-(T)|的个数为68,代入式(8)计算其产生正量变减效变换的支持度和可信度:
(85.29%,78.16%)
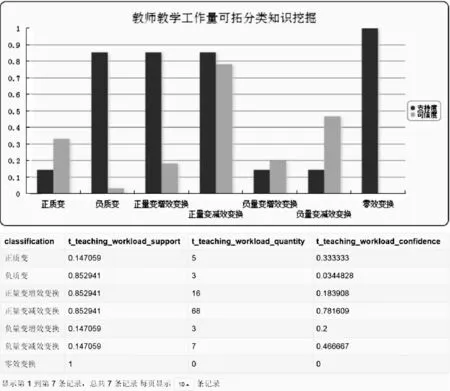
图12 教学工作量可拓分类知识库
此可拓分类知识表示:科研绩效分配制度出台前,教师能够完成教学基本工作量320分。在科研绩效分配制度出台后,虽然仍然能够完成教学基本工作量,但工作量有所减少,此规则的支持度与可信度分别为85.29%与78.16%。这条知识是7种可拓分类知识中重要程度和准确程度综合最高的一条知识。同理,可计算其他6种可拓分类知识。
综合上述可拓传导知识挖掘系统获得的传导度知识及可拓分类知识,可得出在科研绩效分配制度这一主动变换影响下,教师科研工作量有了明显的提升,但教师教学工作量却出现一定程度的下降,教师的工作重心由教学向科研工作倾斜。
5 结 语
本文实现的可拓传导知识挖掘系统在设计上,引入jQuery及bootstrap技术实现Web前端开发提升了用户交互体验。通过MVC框架模式有效地分离业务逻辑、数据、界面显示,提升系统开发及维护的效率。在系统功能上,对原始数据库的信息进行基元表示,计算传导效应,生成“传导效应库”;计算传导度,生成“传导知识库”; 计算关联度、关联差、关联积,生成“可拓分类库”;计算支持度及可信度,生成“可拓分类知识库”。设计的可拓传导知识以及可拓分类知识挖掘流程及算法,具有良好的通用性,为可拓数据挖掘在数据挖掘领域的进一步发展打下良好基础。
本系统通过在高校教师工作量中的具体应用,挖掘支持度及可信度较高的传导知识,帮助管理层从量上了解某策略对教师科研及教学工作量产生正面或负面影响的程度,以便制定出有效的调控策略。下一步将对可拓聚类知识挖掘、基于知识库的可拓知识挖掘[12]、基于可拓数据挖掘的可拓策略生成[18-19]等问题展开深入研究。
[1] 李小妹,杨春燕,李卫华.成品油税费改革对股票市场影响的传导知识挖掘[J].计算机应用研究,2010,27(8):2865-2868.
[2] 李忠,陈新房,于国卿,等.基于可拓数据挖掘的黄河开河日期预测模型[J].水电能源科学,2013,31(9):1-3,19.
[3] 蔡文,杨春燕,陈文伟,等.可拓集与可拓数据挖掘[M].北京:科学出版社,2008.
[4] 李立希,李铧汶,杨春燕.可拓学在数据挖掘中的应用初探[J].中国工程科学,2004,6(7):53-59.
[5] 杨春燕,蔡文.基于可拓集的可拓分类知识获取研究[J].数学的实践与认识,2008,38(16):184-191.
[6] 杨春燕,蔡文.可拓数据挖掘研究进展[J].数学的实践与认识,2009,39(4):134-141.
[7] 王建林,杨印生,王学玲.基于可拓数据挖掘的黄河三角洲土地利用评价[J].吉林大学学报(工学版),2012,43(1):479-483.
[8] 李小妹.CPI指数变换对产品销售影响的可拓数据挖掘[J].数学的实践与认识,2009,39(4):178-183.
[9] 朱伶俐,李卫华,李小妹.客户价值可拓知识挖掘软件研究[J].广东工业大学学报,2012,29(4):7-13.
[10] 王志光.可拓数据挖掘技术在煤矿瓦斯预警中的应用[J].中州煤炭,2013(4):90-92.
[11] 叶广仔,李卫华,刘晓蔚.可拓分类知识挖掘系统的设计与实现[J].计算机应用与软件,2017,34(1):328-333.
[12] 方耀楣,何万篷.可拓数据挖掘在高校教学质量评价中的应用[J].数学的实践与认识,2009,39(4):82-87.
[13] 杨春燕,李小妹,陈文伟,等.可拓数据挖掘方法及其计算机实现[M].北京:科学出版社,2010.
[14] 李志,贾克斌,李真真,等.基于.NET MVC架构的网上珠宝销售系统的设计与实现[J].计算机应用与软件,2013,30(3):186-192.
[15] 唐永瑞,张达敏.基于Ajax与MVC模式的信息系统的研究与设计[J].电子技术应用,2014,40(2):128-131.
[16] 杨春燕,蔡文.可拓学[M].北京:科学出版社,2014.
[17] 叶广仔,李卫华.可拓数据挖掘在教师科研考核评价中的应用[J].数学的实践与认识,2015,45(12):53-59.
[18] 叶广仔,李卫华,李淑飞.可拓策略生成系统的构件化设计与实现[J].智能系统学报,2010,4(4):366-371.
[19] 李卫华,杨春燕.结合HowNet的可拓策略生成软件研制[J].科技导报,2014,32(36):32-36.
