应用于地理信息数据自动分类的高性能聚类算法
2018-05-03夏梦
夏 梦
(河北省地质调查院信息中心 河北 石家庄 050000)
0 引 言
在地质调查信息化[1-2]建设中,以大数据[3-4]、云计算[5]等为代表的现代计算技术在提高地理信息数据处理的深度、广度和效率中发挥着越来越重要的作用。现代地理信息数据由空间属性、特征属性和时间属性构成,并且三者紧密关联。其中,以文本形式出现的特征属性数据富含大量多种专题的知识信息。随着地理信息数据规模的增长,现有基于传统分类方法的处理方式不能体现地理信息数据的多类别归属交叉性,而且,未被识别过的、隐藏在数据中的内在类别和知识模式不能被传统方法有效挖掘出来。本文针对此问题,结合数据挖掘中的聚类技术和近几年兴起的基于NVIDIA的GPU+CUDA的并行计算技术,提出了一种应用于地理信息数据自动分类的高性能k-means聚类算法,以根据数据的文本特征属性对其进行自动分类,提高地理信息数据处理的深度和有效性。
在地质调查信息化研究中,聚类算法已经被用来分析处理地调数据,但相关研究仅限于采用已有领域软件中的传统聚类模块[6-7]。目前尚未有针对地理信息数据处理的高性能聚类算法。k-means算法是一种经典的自动聚类技术,已经有研究者利用基于NVIDIA的GPU+CUDA的并行计算技术优化k-means算法。已有的优化主要有两个研究方向,一是在CUDA线程和指令层级将算法和GPU计算架构更好结合,尽可能地最大化GPU的计算并行度和存储访问效率。戴涛等[8]提出利用访问速度最高的寄存器存储聚类中心点,以获得最低的存储访问延迟。然而,寄存器是CUDA线程存储程序自动变量的资源,单个线程最大可用数量不超过255。并且有限的寄存器均分到各个线程,程序并行度越高,线程越多,每个线程分到的寄存器资源越少。文本向量维度通常成百上千甚至上万的特点,决定了利用寄存器不能处理常规的文本数据。霍迎秋等[9]采用基于共享存储的多层级CUDA规约求和,以减少对全局存储的使用。在指令级,每个线程处理多个像素点,并利用寄存器计算这些像素点的和,即指令级别的局部和。该优化算法充分利用了共享存储和寄存器,但该优化算法仍然将单个数据记录映射到单个CUDA线程,线程并行度与数据记录数目绑定,而且处理比像素数据大得多的文本数据时,由于数据记录可能较大,不一定能载入并利用高效的GPU共享存储。二是采用适合并行的数据结构提高算法的并行度,如FANG等[10]采用bitmap表示和存储数据,不仅提高了线程并行度,而且压缩了需要载入存储的数据规模。但是此类方法需要大量的数据转换预处理开销,而且当数据稀疏时,大量的无效数据将填充到数据结构中,导致数据规模增大,降低存储访问效率。本文提出数据矩阵分割映射方案,将并行粒度由数据记录深入到数据记录中的单个属性,提高了k-means算法的线程并行度和存储访问效率。本文算法的良好性能和扩展性经由实验得到了验证。
1 相关理论
1.1 聚 类
聚类[11]是数据挖掘中的一类数据划分技术,它将物理或抽象对象集合划分为不同的数据簇,达到任一个簇中的数据彼此相似,不同簇中的数据相异的效果。作为一类重要分析技术,聚类可以产出数据的具体分布,发现数据背后蕴含的信息模式,结合簇的具体特征可对簇做更深度的分析操作。作为统计学的一个分支和一种无监督的学习方法 ,聚类提供了一种准确、细致的分析工具。
1.2 k-means算法
k-means算法是聚类研究中最受欢迎的数据划分算法,它通常以欧几里得距离作为相似度度量尺度。相关定义如下:
定义1K均值算法
以k为设定标准,将包含n个对象的集合分为k个簇,结果簇内的相似度高,簇间相似度低。
定义2欧几里得距离
式中:i=(xi1,xi2,…,xip)和j=(xj1,xj2,…,xjp)是两个p维数据对象。
定义3质心
簇及其附属对象的代表,通常以对簇中对象求平均得到的值作为质心。
定义4相似度
一个数据对象与另一个对象的相近程度,在k-means算法中定义为对象与簇质心的距离。如果同一个簇同时为两个对象距离最近的簇,则这两个对象相似;反之,则两个对象不相似。
k-means算法的基本思想为:首先从n个对象中任意选择k个对象作为初始簇的质心,根据与这些簇质心的距离相似度,将剩下的其他对象分配给最相似的簇。以求对象均值的方式重新计算每个新簇的质心,迭代此流程至度量函数收敛时终止。通常采用均方差作为度量函数,具体定义如下:
式中:E为全体数据对象的均方差之和;p代表数据空间中的某一对象;mi代表簇Ci的数据均值(p和mi为多维数据对象)。
1.3 NVIDIA并行计算架构
NVIDIA的GPU[12]是一种大量核心可高度并行运行的处理器,具有高出多核CPU一个数量级的强大计算能力和非常高的存储带宽,被广泛应用于加速数据密集型的科学计算。它由许多单指令多数据(SIMD)流多处理器构成,每个流多处理器有32 个流处理器。流多处理器内嵌容量有限,但快速的片上共享存储,其被同一流多处理器内的全体流处理器共用。延迟相对较高的全局存储可用于流多处理器之间通信。CUDA是建立在GPU之上的高容量线程并行模型。首先,线程被划分到线程网格内的不同线程块中。然后,线程块划分成一个个由32个连续线程构成的最小执行单元(线程warp)。一个线程块是任一时间在相同流多处理器上并行执行的线程warp集合。流多处理器在相同时间并发执行若干线程块。对于处理中的数据,线程通过索引与其建立映射关系。相同线程块内线程可经由共享存储互通数据。运行于GPU上的函数称为kernel函数。
2 系统设计
本文使用高维文本向量建模和抽象表征地理信息数据的特征属性,以欧几里得距离为度量标准,计算任意两个数据之间的相似度。对于数据的类别划分,本文提出了基于GPU的高维数据规约方案及基于此规约方案的高性能并行k-means聚类算法,并设计了地理信息数据自动分类系统。
所有数据录入SPSS20.0统计学软件。计数资料以相对数表示,χ2检验。以P<0.05,为差异有统计学意义。
2.1 数学模型
本文采用经典的检索模型——向量空间模型建模地理信息数据。该模型抽取数据集合中表述数据类别特征的词汇作为词汇词典。数据由出现在其特征属性中、能体现其内在特征的词汇子集表示,并组成一个多维文本向量,看作向量空间中的一个点。文本特征向量表述为(T1,W1;T2,W2;T3,W3;…;Tn,Wn)。其中,Ti是词语项,Wi是Ti在数据特征属性中重要程度的描述。即将特征属性看作是由一组相互独立的词语组构成,把T1,T2…,Tn看成一个n维坐标系中的坐标轴,对于每一词语,根据其重要程度赋以一定的权重值Wi,作为对应坐标轴的坐标值。
权重Wi使用最为频繁的、文本相异度区分性能较好的相对词频TF×IDF。其中,tf(d,t) 表示词语t在特征属性d中的出现次数,df(t)表示词语t在文本集合中出现过的文本数目。公式如下:
2.2 系统架构
本文提出的地理信息数据自动分类系统主要由特征属性分词模块、特征属性向量构建模块和高性能并行k-means聚类模块构成。它以地理信息数据作为输入文件,以类别数目(k值)作为输入参数,经一系列处理和计算后,输出地理信息数据的分类信息。系统具体架构如图1所示。
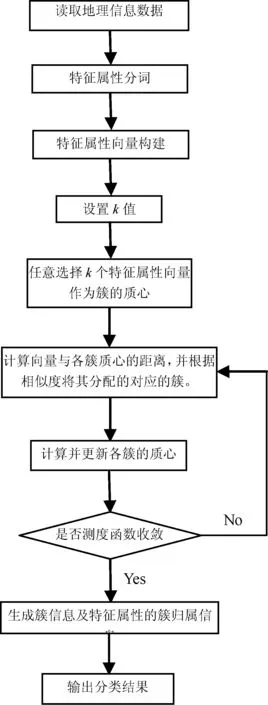
图1 系统架构
地理信息数据的特征属性以文本的形式承载地理数据的类别信息,因此本系统以体现特征属性内在特征的词汇作为类别区分的基础依据。首先,本系统采用中科院的分词系统ICTCLAS完成特征属性分词处理,该模块以单个特征属性为输入,智能识别特征属性中由一个或多个文字组成的词语,并将特征属性切分为由若干词语组成的词汇子集合。同时,该模块将“的”、“是”等不含有特征属性类别特征的常见词去除,以提高表述特征属性的词汇子集合的精炼性。然后,特征属性向量构建模块汇总整个特征属性集合中出现的词语的总集合,建立文本向量空间模型。对于每个特征属性,计算特征属性中出现词语的TF×IDF权重值,生成特征属性对应的文本向量。随后,运行于GPU上的并行k-means聚类模块读取文本向量数据,以用户凭借对数据的经验认识预估的类别数目作为输入参数(k值),进行文本集合的自动分类。最后,将特征属性分类结果(簇质心和每个特征属性的类别归属)输出。
依据系统架构,本文使用C++和CUDA实现了本文提出的地理信息数据自动分类系统。
2.3 CUDA高维数据归约优化方案
文本向量数据具有很高的维度,即一条记录可能包含成百上千个词语权重值,大到文本向量无法完整载入GPU高效的共享存储以获得好的运行性能。k-means算法计算量最大的核心部分是规约新簇归属的记录求其新的质心,常规的方法将一个文本向量划分为若干子向量处理,记录每参与一次计算需要一次向量划分与共享内存载入,需要大量控制数据和存储载入开销。
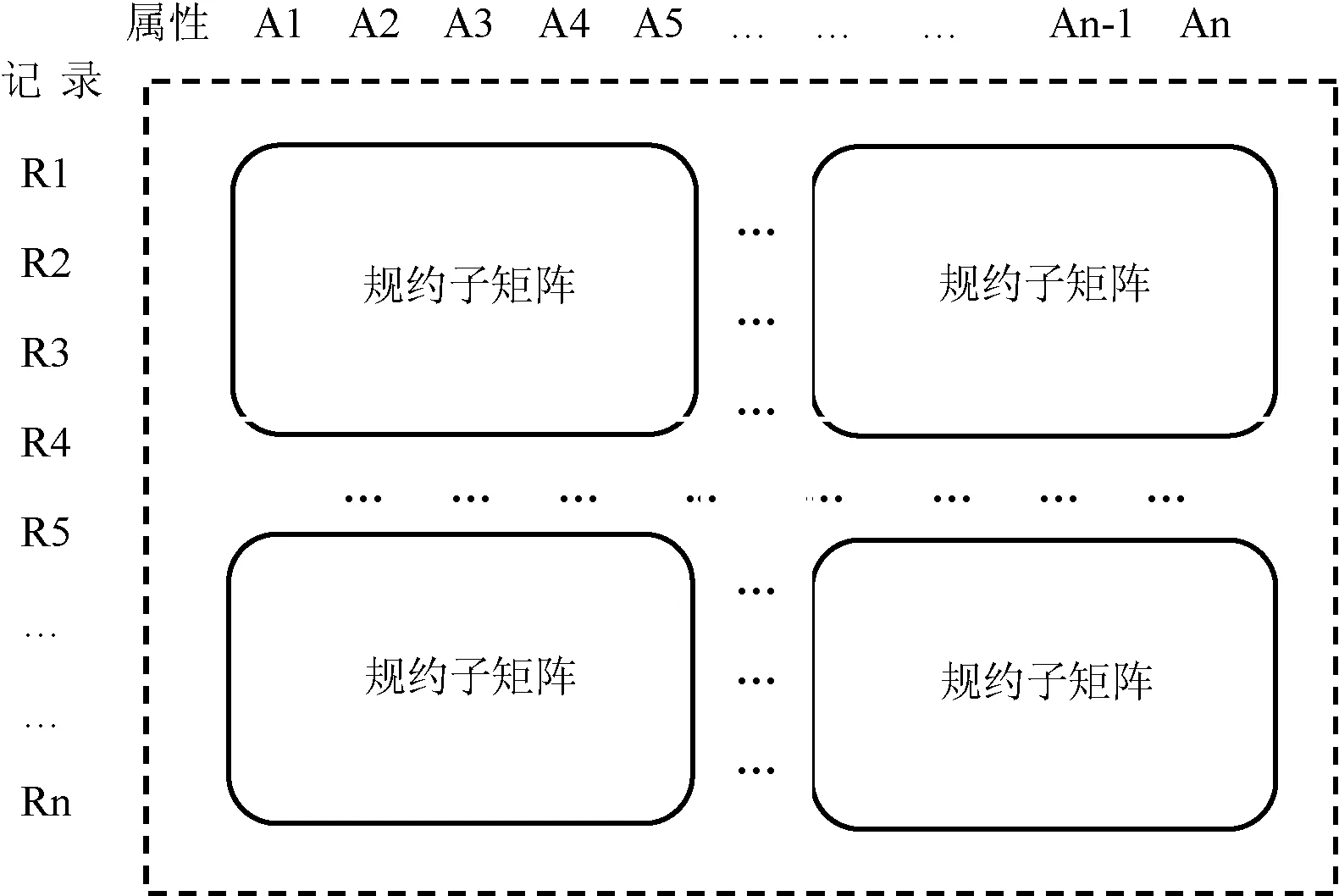
图2 层次矩阵规约优化方案
这样,对高维文本向量数据的归约可分解为大量独立的一维数据归约,而一维数据归约可采用高效的顺序取址归约。本文使用此高维数据归约方案最大化线程并行度,并削减控制和访问存储的开销。
2.4 基于GPU的并行k-means算法
k-means算法的大部分执行时间消耗在更新文本向量的簇标号、更新簇的质心和检测质心移动(迭代收敛判读)三部分计算上。因此,本文致力于优化并行这三个子计算。伪代码如下:

•更新文本向量簇标号采用一维线程块组织计算,每个线程对应一个文本向量,逐一计算该向量与全部簇质心的距离,在计算过程中以只记录当前最近簇的方式筛选出最近的簇作为该文本向量新的归属簇。簇质心以数据融合的方式读入共享存储,文本向量的词语权重值在共享存储允许的情况下也以数据融合的方式读入共享存储,并在计算过程中常驻共享存储,以达到最优的共享存储利用率。
•更新簇质心新簇的质心通过计算所有归属它的文本向量的平均值获得。在该处理中,本文使用两级归约,且每级归约均为线程块内归约。首先第一级规约采用层次规约矩阵优化方案,得到新簇质心各属性和归属向量计数的一系列局部归约和。在二级规约reduction()内,每一个线程块对应一个簇的词语权重值或归属向量计数,仍然使用高效的线程块内顺序取址归约获得最终的新簇词语权重值或归属向量计数总和。在同一个kernel函数内通过线程块索引控制,使得前大半部线程块计算对词语权重值归约,后小半部线程块对归属向量计数归约,从而减少kernel函数调用,扩大同一kernel函数的并行度。最后做除法得各簇新的质心。
•检测质心移动在本算法中,本文选择簇新旧质心是否移动作为迭代收敛判断条件,即在迭代过程中检测簇新旧质心的距离方差和是否小于一定的阈值。在该处理中,本文采用与更新簇质心类似的两级并行多维归约。首先,每个线程对应一个簇属性,计算其新旧值得方差。然后,线程块内归约求得局部的方差和。最后,鉴于数据量较小不适合GPU并行,本文将这些方差和传输回CPU内存,由CPU计算总的方差和,并用于决定是否终止迭代。
3 实验结果
实验使用一台联想工作站,CPU主频为2.93 GHz,8 GB主机内存,主频为1.15 GHz 的NVIDIA Tesla C2070 GPU(14 个流多处理器,共448 个流处理器),6 GB全局存储。操作系统为X86_64版本的CentOS Linux 7.0。实验采用河北省地质调查院的真实数据集,该数据集包括历年来地质勘查的多种信息,每条记录对应一个特征属性。收敛参数设为0.000 01。为了减小实验中的随机波动影响,本文测试每个实验10次,然后取实验数据的平均值。
实验从两方面来检验本文提出的地理信息数据自动分类的聚类算法:一方面通过变化聚类的簇数和CUDA线程块大小探索调优算法;另一方面通过该算法与其他算法的对比测试算法的扩展性。其中,Matrix k-means为本文提出的算法,Bitmap k-means代表基于bitmap数据结构的算法,鉴于霍迎秋等[9]对算法的优化较为充分,本文采用其作为Optimized k-means进行比较。
采用大小为100 000的数据集,图3展示了变化CUDA线程块大小和聚类簇的大小(k值)情况下本文提出的k-means算法的执行时间。对于同一个k值,线程块大小为256时,算法获得最佳性能。这是由于小的线程块导致其对应的高效共享存储上的数据被较少线程共享,数据共享度低;太大的线程块导致共享存储不能有效载入线程块内线程对应的数据。线程块大小为256时,算法在线程内并行度和共享存储访存效率之间取得了好的平衡。
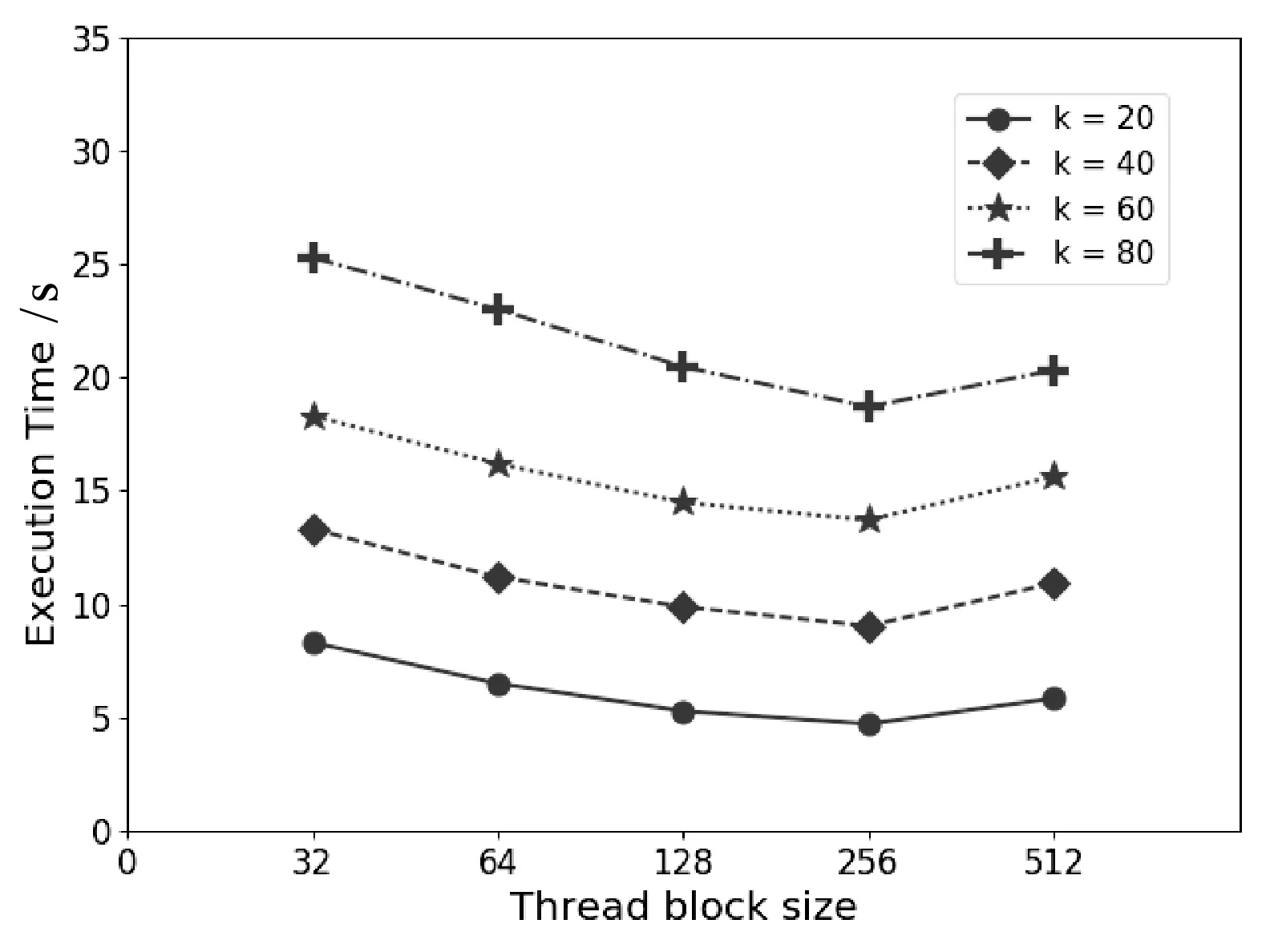
图3 执行时间随CUDA线程块大小和k值变化情况
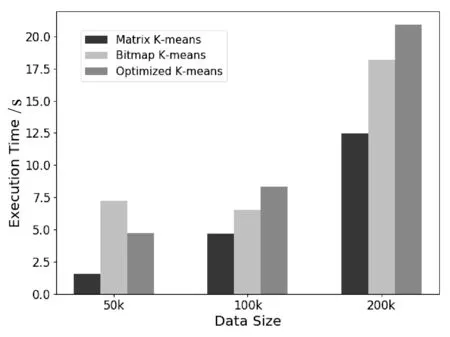
图4 执行时间随数据集大小变化情况
实验中的簇数,即k值设为24,图4为算法执行时间随实验中文本向量数据集大小变化的时间开销情况。本算法的高并行度线程调度方案最大化了程序在GPU架构上的并行执行。实验表明本文提出的并行聚类算法在各个数据集上均表现出良好的性能优势。它在两个较大数据集上执行时间不大于其他两个算法的2/3,在包含50 000个数据对象的小数据集上获得了最大5倍的加速比。同时,实验表明,算法执行时间随数据对象增加呈线性增长,而基于Bitmap数据结构的算法没有表现出这样的特性。由于Bitmap导致稀疏矩阵的产生,在小数据集上,其对应算法运行较慢。
4 结 语
针对地理信息数据的类别归档,本文提出了一种基于GPU的高性能并行k-means自动分类算法,并设计和实现了软件系统。本文采用文本向量建模和抽取表述特征属性的类别特征,数学化现实问题,然后采用并行k-means算法自动划分特征属性的类别。实验分析表明算法合理有效,体现了特征属性归属的多类别交叉特性,同时具有较好的运行性能优势,能提高地理信息数据处理的办公自动化水平。
[1] 李丰丹,李健强,吕霞,等.基于中国地质调查信息网格的“立体一张图”服务构建与应用[J].中国地质,2014,41(3):1028-1036.
[2] 周家寰.地质调查信息化建设成果及思路[J].国土资源信息化,2005(5):2-4.
[3] 韩媛,张红英,粱楠.大数据在地质资料管理与服务中“落地”问题分析[J].中国地质调查,2016,3(3):67-70.
[4] 郑啸,李景朝,王翔,等.大数据背景下的国家地质信息服务系统建设[J].地质通报,2015,34(7):1316-1322.
[5] 汪新庆,康承旭.云计算在地质调查信息化工作中的应用研究[C]//全国数学地质与地学信息学术研讨会.2014.
[6] 于湛,姚舜禹,刘雅彦.地质调查成果发布与传播机制研究[J].中国国土资源经济,2015(2):55-59.
[7] 袁建飞,邓国仕,徐芬,等.毕节市北部岩溶地下水水化学特征及影响因素的多元统计分析[J].中国地质,2016,43(4):1446-1456.
[8] 戴涛,杨洲,方勇,等.基于CUDA的k-means文档聚类算法并行优化[J].计算机工程与设计,2013,34(11):4032-4036.
[9] 霍迎秋,秦仁波,邢彩燕,等.基于CUDA的并行k-means聚类图像分割算法优化[J].农业机械学报,2014,45(11):47-53.
[10] Fang W B,Lau K K,Lu M,et al.Parallel datamining on graphics processors[R/OL].Technical Report HKUST-CS08-07,2008.http://code.google.com/p/gpuminer/.
[11] 伍育红.聚类算法综述[J].计算机科学,2015,42(6A):491-499,524.
[12] Kirk D.NVIDIA cuda software and gpu parallel computing architecture[C]//International Symposium on Memory Management,Ismm 2007,Montreal,Quebec,Canada,October.2007:103-104.
