基于Hadoop的电梯安全大数据挖掘算法研究
2018-04-28常姗
常 姗
(西安理工大学,西安710048)
截至2016年底,我国电梯保有量已达到470万台。电梯成为继飞机、火车、汽车之后的第四大交通工具。在电梯数量快速增加的同时,电梯安全面临着生产质量下降、维保质量下降、安全意识不足的严峻形势[1]。2014年1月1日起施行的《中华人民共和国特种设备安全法》规定:电梯必须保持电梯紧急报警装置和通话装置完好,保证联络畅通。支持并鼓励建立电梯安全远程监管系统,实现电梯安全网络监控管理。[2]目前,电梯五方通话装置或电梯应急通信系统基本做到了国内全覆盖;全国已有20多个省、市、自治区建立了电梯安全监管系统。但是,电梯紧急报警装置属于被动呼救方式,只在乘客被困时才用;而电梯安全监管系统虽然可以实时主动报警,但并不能实现电梯事故的预警预报。本文以电梯安全远程监管系统数据库中的数据作为数据源构建电梯安全大数据挖掘平台,着重研究了聚类算法K-Means和关联算法Apriori,进而实现电梯安全事故的预警预报。
1 电梯安全大数据来源
电梯主要由三大部分组成:轿厢、曳引机和控制柜,其中曳引机和控制柜均安置在机房。[3]电梯安全大数据来源于电梯安全远程监管系统,该系统由硬件和软件两部分构成:硬件部分安装在电梯机房,从电梯控制板上实时提取电梯状态信号并利用GPRS网络推送到服务器,如图1所示;软件部分通过对电梯的运行数据进行分析,实时显示电梯运行状态。[3]故障发生时迅速将故障电梯位置、故障现象、人员被困信息等通过短信、互联网PC终端以及移动互联网终端等方式报告给值班室和维保人员,具有24小时电梯运行参数在线监测、电梯故障实时报警、电梯维保质量评估等功能。
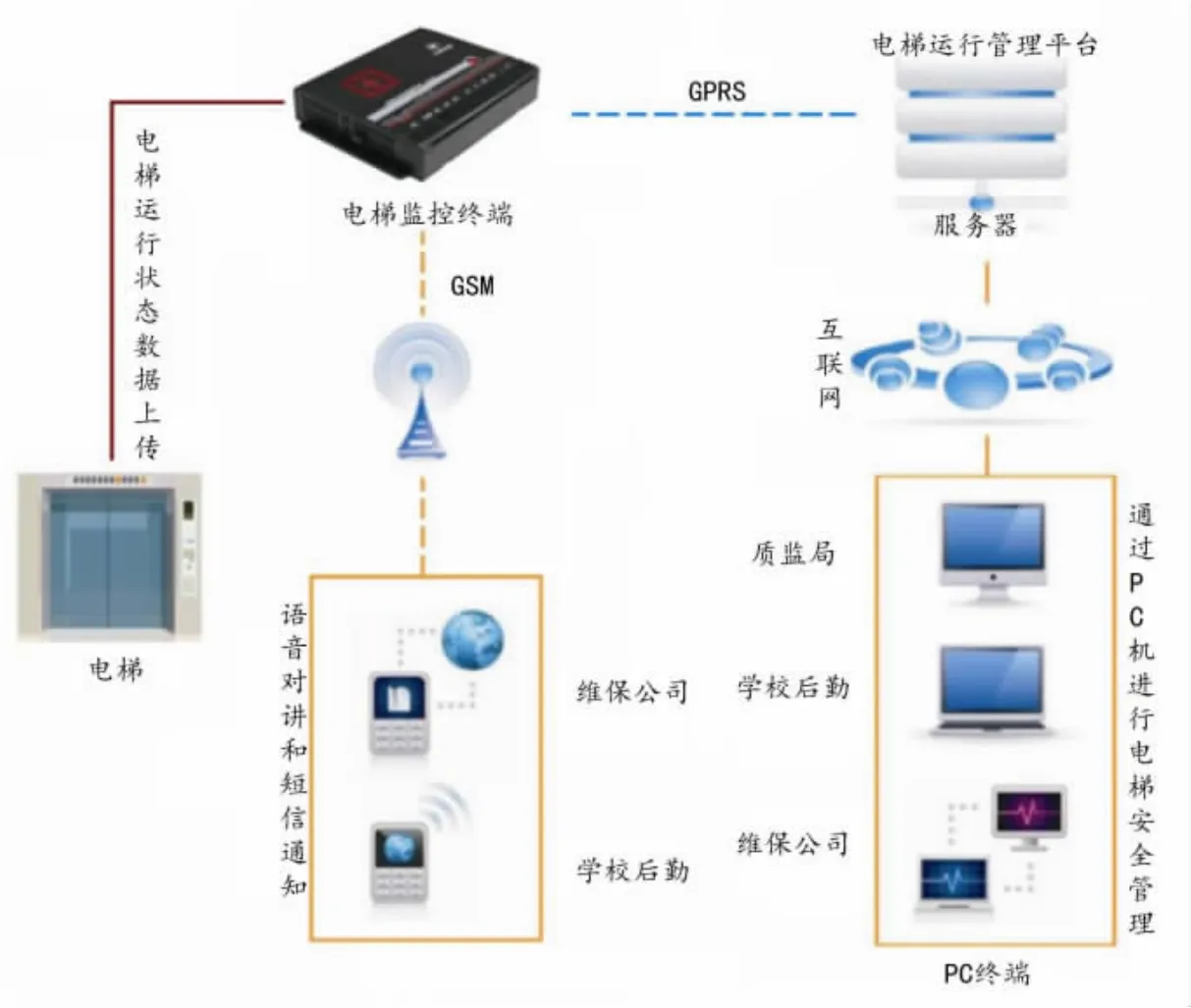
图1 电梯安全远程监管系统示意图
电梯安全远程监管系统使用的数据库是SQL Server 2005,包括以下数据类型:
(1)电梯状态数据:运行/检修模式、上行、下行、上平层、下平层、门锁、安全回路、电源等8路信号。[3]
(2)基础数据:电梯基本信息、注册登记信息、电梯厂家资料、使用单位资料、维保公司资料、安装信息、维保工人信息等。
(3)日常维保管理数据:维保时间、维保项目、维保公司、维保人员信息、年检记录等。
(4)故障数据:电梯位置、维保公司名称、电梯用户、电梯注册登记号、电梯故障状态等。
(5)违章数据:维保公司、维保人员信息的违章信息、违章类型、违章描述等。
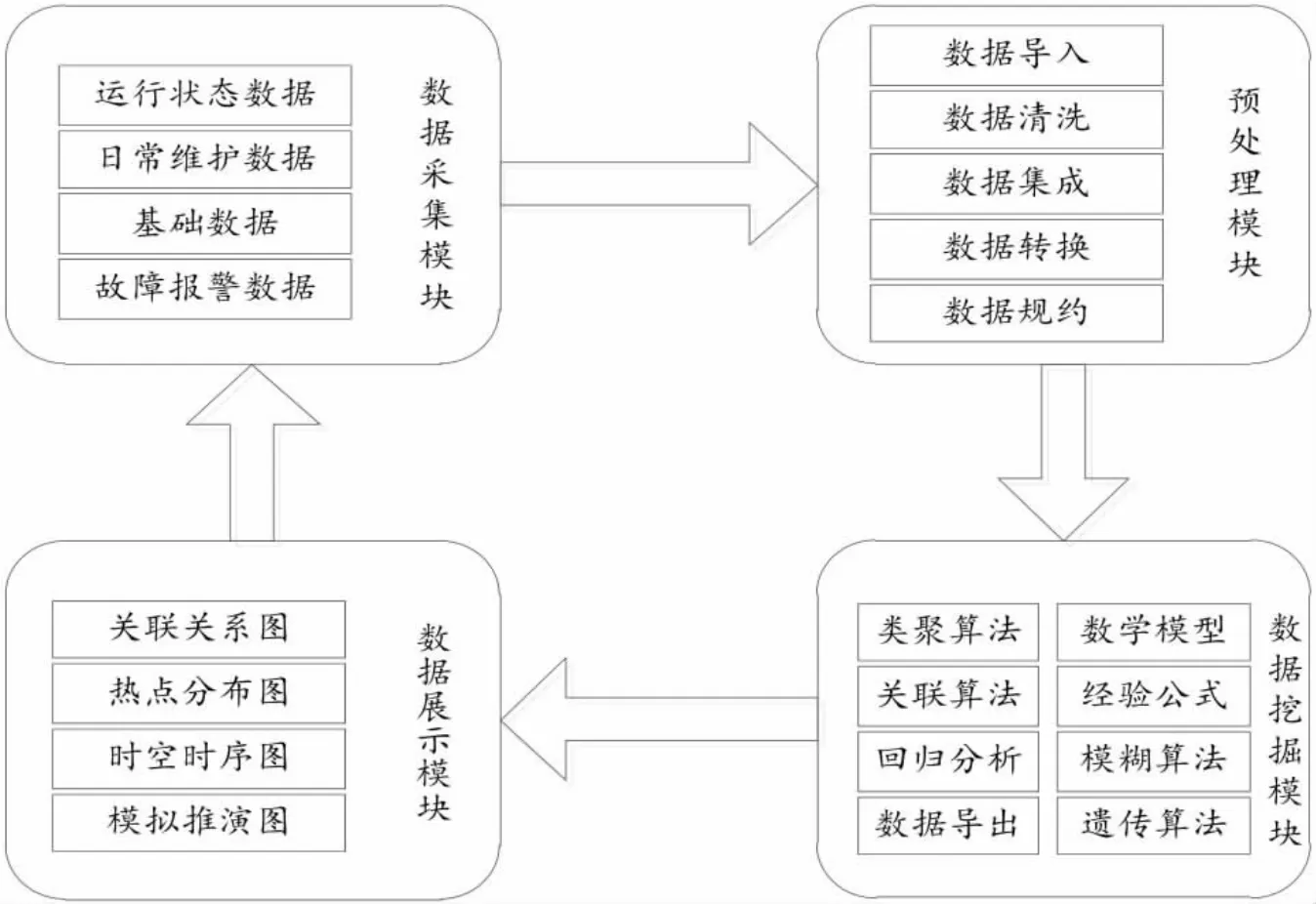
图2 电梯安全大数据平台构架图
2 电梯安全大数据平台
电梯安全大数据平台包括电梯安全大数据采集模块、预处理模块、数据挖掘模块及数据展示模块,其构架图如图2所示。
数据采集模块不间断地收集与电梯相关的运行状态、日常维保、基础、故障、报警、救援等数据,实现数据的大容量、多样性、真实性和快速性。预处理模块进行统一标准的整理,包括数据导入、数据清洗、数据集成、数据变换、数据规约等过程。数据挖掘模块主要通过数学模型、经验公式、聚类算法、相关算法、模糊算法、遗传算法、回归分析等方式对海量数据信息进行处理,实现从数据仓库获取有用信息,如:预测电梯故障多发期,评判电梯维保质量;通过电梯故障类型、频率、零部件更换情况等预测电梯的运行状况等。数据展示模块将大数据分析的结果用直观的方式展示出来,如:关联关系图、热点分布图、时空时序图、模拟推演图等,便于指导实际的电梯监管工作。由此形成一个“收集—分析—反馈—优化”的循环过程,在这个过程中维保人员不断地学习、优化,使电梯的安全管理工作真正做到事前预警准确、事中处理有效、事后分析合理[4-5]。
3 电梯安全大数据挖掘算法研究
电梯安全大数据挖掘时采用了分布式处理分析软件——Hadoop,它依靠“Map(映射)”和“Reduce(规约)”并行运算大数据集编程模型。[6]数据挖掘的分析方法有很多种,本文主要研究聚类算法K-Means和关联分析算法Apriori。
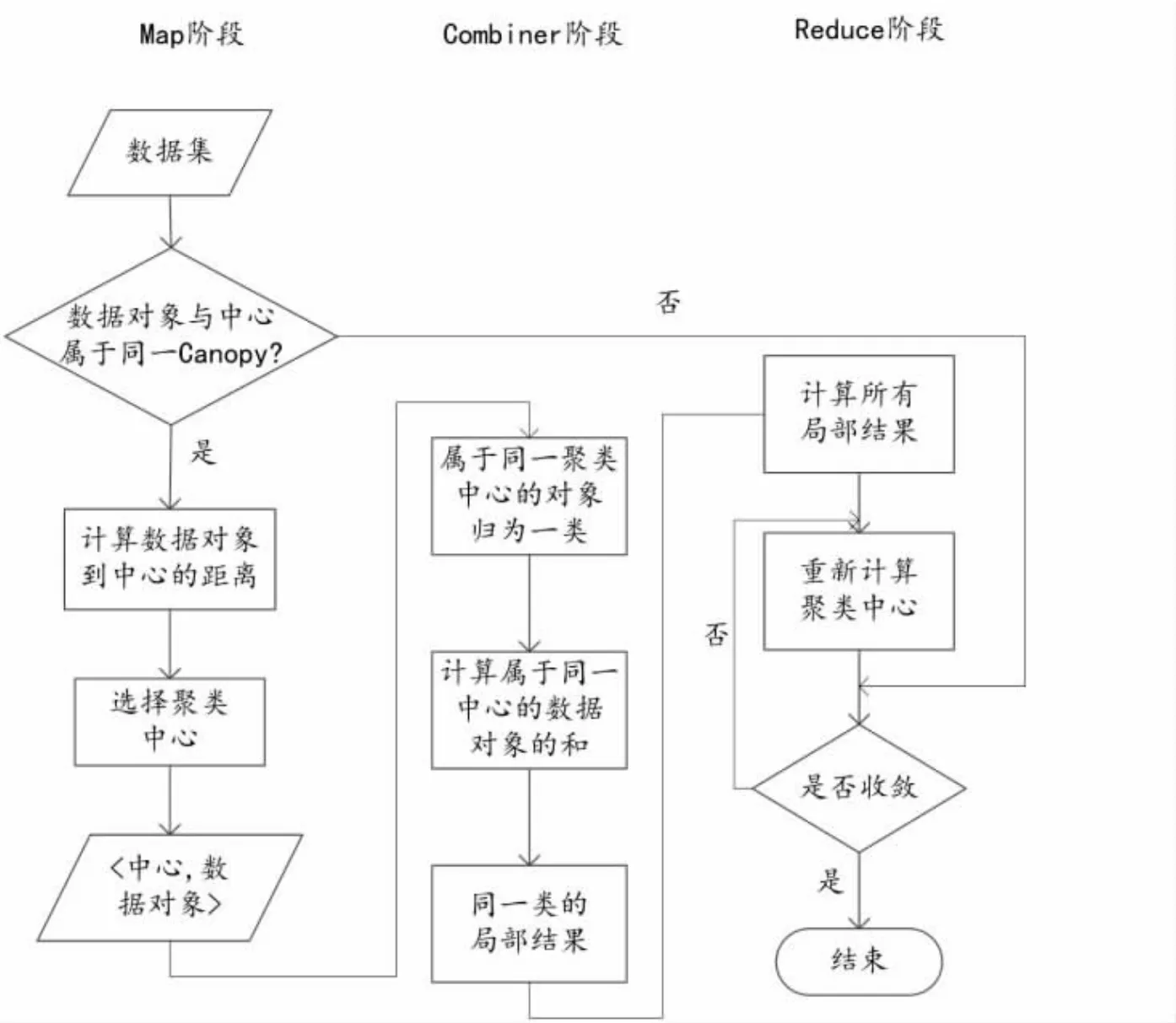
图3 改进的K-Means聚类算法过程流程图
3.1 一种改进的K-means聚类算法
K-means聚类算法需要实现确定k值和初始聚类中心,改进的K-means算法思想是Canopy聚类算法对数据集进行预处理,确定k值和去除离群点[7]。在初始聚类的选择问题上则放弃Canopy算法,依然使用了传统K-Means算法,即从数据集合中任意选择k个聚类中心,不同之处在于初始聚类中心由一组变成多组,再通过准则函数计算出最优的初始聚类中心。MapReduce并行化总体分为Canopy算法并行化和K-Means算法并行化,如图3所示,这两部分的共同点是对其在确定数据对象与聚类中心距离的阶段进行并行化操作[8]。
3.2 一种改进的Apriori关联算法
Apriori算法在计算时采用迭代的方法,简单易行,但其缺点是多次扫描事务数据库,需要很大的I/O负载,对每次k循环,候选集C[k]中的每个元素都必须通过扫描数据库来验证其是否加入L[k]。由此可能产生庞大的候选集,由L[k-1]产生k-候选集C[k]是指数增长。采用MapReduce分而治之的思想对传统的Apriori算法进行改进,减少算法的运行时间,将数据库划分为n个大小相同的数据块,分别发送不同的工作节点,并设每个数据块的最小支持度阈值不变;执行Map函数,数据块经过各自节点的扫描,产生局部频繁k-项集。Map函数先利用类似频率统计的方法产生局部频繁1项集,然后利用传统Apriori算法的方法产生频繁k-项集;利用Reduce函数合并所有的局部频繁k-项集,具体合并方法为计算所有数据块相同候选集的数目,得到全局候选频繁k-项集;对数据库进行第二次扫描,计算全局候选频繁项集的支持度并与最小支持度阈值进行比较,找出最后的全局频繁项集;不断迭代,直至算法结束,[9]如图4所示。改进后的算法进行的是并行运算,其优点是各节点之间的工作过程相互独立互不影响,而且对于数据库的扫描只需要2次,减少了算法执行的时间开销。
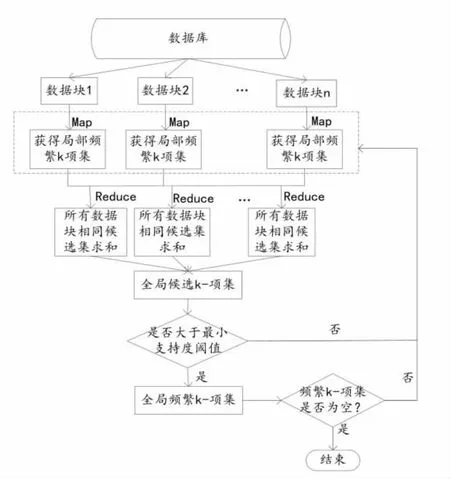
图4 改进的Apriori关联算法优化流程图
3.3 改进算法性能评估
分别从加速比与可扩展性两方面评估算法性能,实验数据来自电梯安全远程监管系统数据库中的故障数据。
(1)改进的K-Means算法加速比分析:体现并行算法性能的主要标准之一就是加速比,它所描述的算法性能是通过减少运行算法的时间而得到的[10]。若用S表示加速比,TS为单个节点聚类所用的时间,TP表示P个节点同时工作所用的时间,则S=TS/TP。分别在Hadoop测试环境3个节点上进行对比实验,结果如图5(a)所示[9]。由图5(a)可以直观地看出,改进后的K-Means算法加速比较大。同时,随着节点数的增加折线图有变缓的趋势,这是因为Hadoop平台各节点之间相互通信时的时间开销随着节点数的增加而增加,导致加速比的增长率减小。[11]
(2)改进的K-Means算法可扩展性分析:节点数的增加限制了加速比的增长,导致加速比无法很好地体现集群利用率,若用E代表扩展性,则E=S/P,其中S为上文提到的加速比,P为节点数目[12]。同样分别在Hadoop测试环境的3个节点上进行实验,结果如图5(b)所示。分析图5(b)可知,K-Means算法改进后的折线图整体呈下降趋势,但是改进后的算法效率要明显高于改进前的算法效率[13]。
(3)改进的Apriori算法加速比分析:以1G、2G、4G的数据规模,使其分别运行在Hadoop测试环境的3个节点上,观察它们的运行时间[14],如图5(c)所示。图5(c)所示的结果是Hadoop平台分别对3个数据规模在1、2、3共3个节点上所做的9次实验的结果,[9]可以看出,节点数越多,Hadoop处理数据所用的时间就越少。由此可以说明改进后的Apriori算法在Hadoop平台上的加速比较好。[15]
(4)改进的Apriori算法可扩展性分析:若将1G数据用1个节点处理,2G数据用2个节点处理,3G数据用3个节点处理,结果如图5(d)所示。分析图5(d)中的运行时间发现,当数据量与节点数目按相同比例同时增加时,Hadoop运行所需要的时间相差无异,这说明改进后的Apriori算法在Hadoop平台上的扩展性很好[16]。
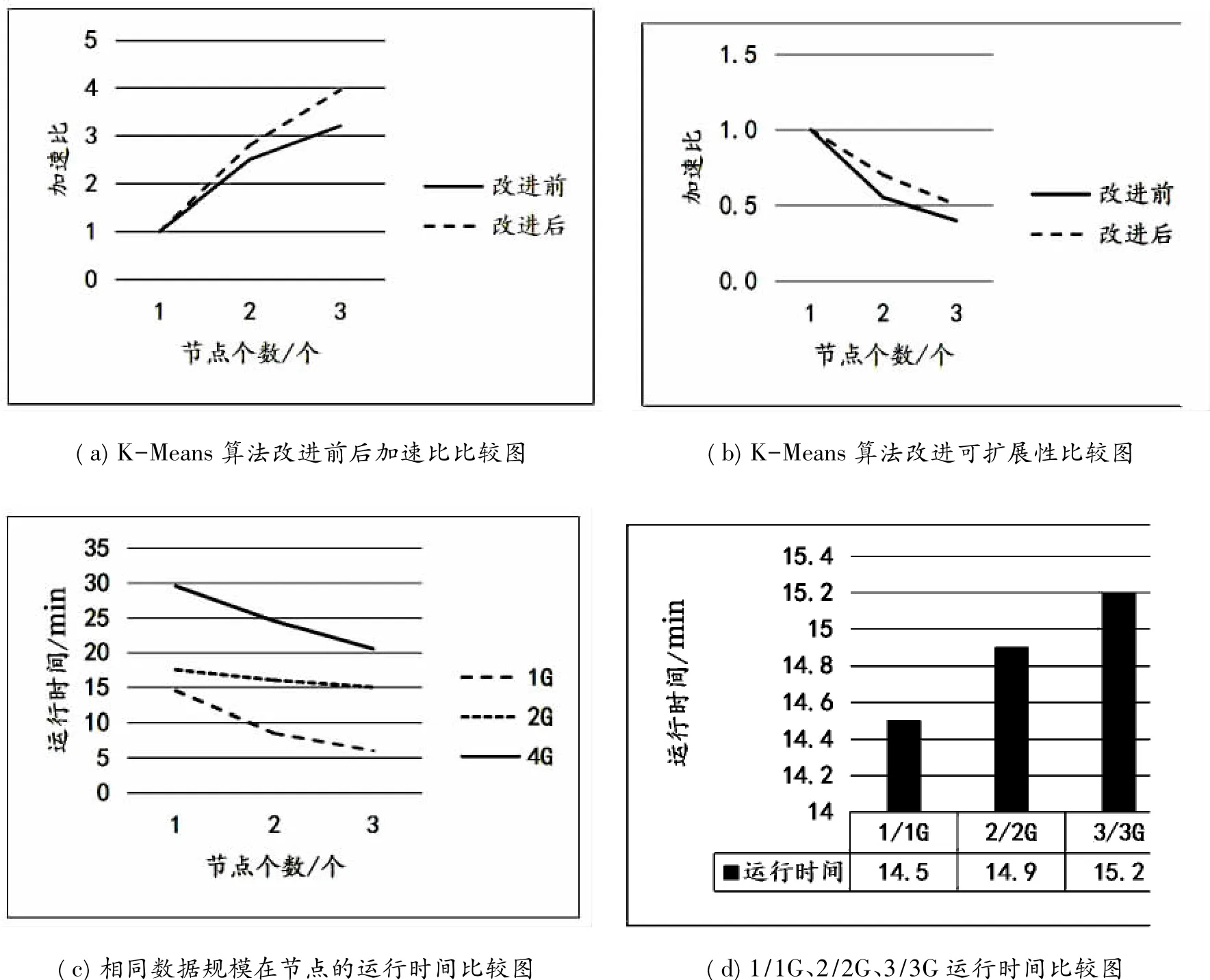
图5 改进算法性能比较图
综上所述,改进后的K-Means聚类算法和Apriori关联算法在大数据集的处理上具有更好的性能。
4 基于Hadoop的电梯安全大数据挖掘算法结果分析
用以下几个例子简要说明改进算法在电梯安全大数据平台中的应用。
(1)以小区为单位,各小区电梯故障情况分析:以每部电梯故障次数为观测值,其聚类结果如表1所示。由于数据量大,小区数量众多,本文只选取电梯数量较大的5个小区进行分析,其电梯数量分别为60、56、52、48、42。通过表1可以看出:对于每个小区来说,第1聚类中的电梯故障次数明显少于第2聚类和第3聚类,对于不同聚类中的电梯,维保人员可以有不同的维保策略,对于第3聚类中的电梯,维保人员应加强其检修频率,从而降低小区的电梯故障率。[9]
(2)各品牌电梯的电梯故障次数聚类结果分析:本文所使用的数据中,三菱、芬兰通力、巨人通力和日立电梯占所有品牌电梯的70%以上,故着重对这4个品牌电梯进行分析[17]。以品牌电梯为单位,以每部电梯故障次数为观测值,观测结果见表2。[9]通过表2可以看出,对于各品牌电梯来说,每个聚类中的电梯故障率均不相同,第3聚类中的电梯故障率明显高于前两个聚类,各品牌电梯应着重排查故障率较高的电梯,发现电梯自身潜在的危险性。
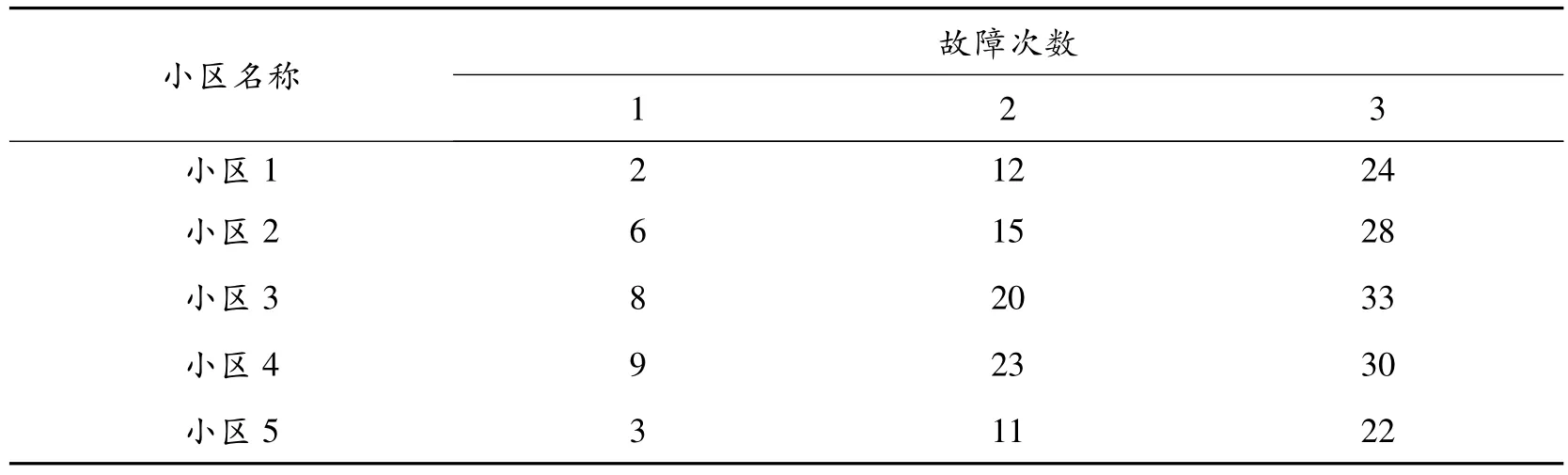
表1 各小区每部电梯故障次数聚类结果

表2 各品牌电梯每部电梯故障次数最终聚类结果

表3 各故障类型与小区之间的关联规则表
(3)各故障类型与小区之间的关联规则结果分析:将最小置信度设置为30%,最小支持度设置为10%,得出的故障类型与小区之间的关联规则见表3。通过表3的关联规则能够发现某特定小区的频发故障,如小区3最可能发生的故障为冲顶或蹲底,概率超过了54%。结合聚类分析的结果,小区3的第3聚类中的电梯故障率最高,维保人员应该重点检修故障率较高的电梯的冲顶或蹲底故障,排除故障原因,确保电梯安全运行[18]。
(4)各品牌电梯与故障类型之间的关联规则结果分析:将最小置信度设置为10%,最小支持度同样设置为10%,得出的故障类型与品牌电梯之间的关联规则见表4。从表4关联规则的结果能够发现某品牌电梯的常见故障,如三菱电梯有20%的可能性发生短接门锁运行故障,同样结合聚类分析的结果,三菱电梯的第3聚类电梯故障高发,应着重对这些电梯进行短接门锁运行故障原因分析。

表4 各故障类型与电梯品牌之间的关联规则表
5 结语
本文以电梯安全远程监管系统数据库中的数据作为数据源构建电梯安全大数据平台,着重研究了改进后的K-Means聚类算法和Apriori关联算法,同时根据电梯故障数据对改进前后的算法进行了实验验证,结果表明两种改进算法的加速比与可扩展性更好。利用改进的聚类算法分析了各小区、各电梯品牌的电梯故障情况以及各维保公司的故障修复率,利用关联算法分析了小区及品牌电梯的特定频发故障,对电梯安全管理及事故预警预报有指导意义。
参考文献:
[1]张贞贞,檀吴.基于大数据的电梯监管新模式[J].电子技术与软件工程,2017(22):164-165.
[2]全国人民代表大会常务委员会公报.中华人民共和国特种设备安全法[M].北京:法律出版社,2014.
[3]李文峰,李志华,韩非.基于GSM网络的电梯五方通话技术研究[J].电子器件,2013,36(1):76-79.
[4]刘荣灿.电梯安全远程监管系统终端的研制[D].西安:西安科技大学硕士学位论文,2014.
[5]Dean J,Ghemawat S.MapReduce:Simplified data processingon large Clusters[J].Communication of the Acm,2008,51(1):107-113.
[6]徐斌,李琳,钟珞.面向大数据的智慧电梯分析预警平台[J].武汉理工大学学报(交通科学与工程版),2017,41(2):359-362.
[7]周仁,任海鹏.复杂网络系统的拓扑结构辨识方法[J].西安理工大学学报,2017,33(1):80-85.
[8]丁梓恒.电梯安全管理浅见[J].管理观察,2016(33):62-63.
[9]冯永明.基于Hadoop的电梯安全大数据挖掘研究[D].西安:西安科技大学硕士学位论文,2017.
[10]陈吉荣,乐嘉锦.基于Hadoop生态系统的大数据解决方案综述[J].计算机工程与科学,2013,35(10):25-35.
[11]张伟.电梯安全评价探析[J].现代商贸工业,2014,26(9):175.
[12]苏蓉.基于Hadoop平台的安全日志聚类挖掘算法研究与应用[D].西安:西北大学硕士学位论文,2015.
[13]Jiang Q S,Ye J P,Zhang J F.Research on Car-Rail Coupling Dynamics of Ascending Hatchway of Elevator Safety Device Test Tower[J].Advanced Materials Research,2014,978:135-138.
[14]Zarikas V,Loupls M,Papanikolaou N,et al.Statistical survey of elevator accidents in Greece[J].Safety Science,2013,59:98-102.
[15]Mcconnell N C,Boyce K E,Shields J,et al.The UK 9/11 evacuation study:Analysis of survivors’recognition and response phase in WTC1[J].Fire Safety Journal,2010,45(1):21-34.
[16]陈兆芳,张岐山.基于熵权和灰色关联方法的电梯安全评价及其应用[J].安全与环境工程,2016,23(4):109-112.
[17]Hieu D V,Meesad P.Fast K-Means Clustering for Very Large Datasets Based on MapReduce Combined with a New Cutting Method[J].Knowledge and Systems Engineering,2015,326:287-298.
[18]赵莉,候兴哲,胡君,等.基于改进 K-means算法的海量智能用电数据分析[J].电网技术,2014,38(10):2715-2720.
