基于央行视角的分布式大数据技术应用探析
2018-04-23李苏
李 苏
(中国人民银行衡阳市中心支行科技科,湖南 衡阳 421001)
0 引言
人民银行现代化支付系统已经发展到第二代,是银行资金汇划与资金清算的重要平台和核心枢纽,在国家经济发展中承担着重要作用、处于重要地位[1]。据统计,某省会中支清算中心2016年业务笔数达21380万笔,年均数据量超2亿条。支付清算数据体现着金融经济的运行情况,关系着宏观经济的发展状况,对其进行分析利用可以为总结和预测金融经济发展提供一定参考。其分析侧重点在于资金的流量流向分析、CCPC业务量分析、重点监测单位业务分析、区域业务分析、银行业务分析、行业业务分析等。
自支付系统上线运行迄今已超过 10年时间,面对年均2亿条的数据规模,积累数据将超过20亿条,采用传统关系型数据库将面临压力[2-5]。通过大数据分析平台,可以有效缓解该数据存储压力、汇总统计运算压力。支付清算数据是典型的结构化数据,关键字段包括交易序号、业务日期、业务类型、账号、名称、交易金额、归属区域、归属银行、归属行业等。在进行数据清洗后,以业务关键字作为key值、以相关属性作为列族,存储到列式数据库如 HBase[6]中;再通过建立区域、银行、行业维度,保存数据到事实表中,形成维度立方体,在前台即可进行各种维度分析、展示各种报表。大数据平台为此提供了完整的数据处理链条,工具化的展示模块,使得对数据的理解不再停留在过去以寻找数据发生原因为主的思路上,而是展示了数据发展的趋势、找出数据相关性,以历史数据去预测未来数据的走向。
本人参与的人民银行某省级数据中心大数据开发项目,利用开源的 hadoop、hdfs、hive、hbase、kylin、kettle等技术或工具搭建了一个分布式大数据分析平台,实现了海量支付清算数据的分析和统计。
1 平台物理架构
分布式大数据从萌芽开始到现在的蓬勃发展,涌现了许多的技术体系和技术框架。其中应用最为广泛的当属源于Google公司的Hadoop[7-9]分布式系统基础架构。本文中的分布式大数据平台,是以Hadoop架构为基础,选用其中部分组件进行搭建。
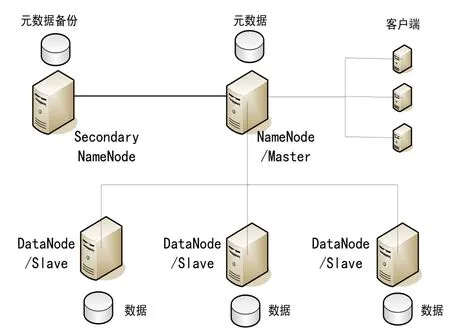
图1 基于HDFS的平台物理架构Fig.1 Physical architecture based on HDFS
构成该平台的 HDFS集群[10]的主要有两类节点,并以主从(Master/Slave)模式,或者说是管理者-工作组模式运行,即一个NameNode(管理者)和多个DataNode(工作者)。SecondaryNameNode是NameNode的镜像数据备份。对应到HDFS分布式文件系统,NameNode是主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;DataNode负责管理存储的数据。同时,Master主节点负责调度构成一个作业的所有任务,这些任务分布在不同的 Slave从节点上。Master主节点监控它们的执行情况,并且重新执行之前的失败任务;Slave从节点仅负责由主节点指派的任务。另外,主节点要在可靠性和性能上优于从节点,并且要保证NameNode和SecondaryNameNode节点在配置和环境上要一致,方便在 NameNode不可用的情况下,可以以最快的速度替换。由于 Hadoop的作业基本上都是数据密集型,在进行作业时,有大量的中间结果需要通过交换机进行传输,为了不让带宽成为瓶颈,建议使用万兆交换机。
2 平台软件架构
平台操作系统为Linux CenteOS 7.3.1611版本,Hadoop版本为CDH5.10,JDK版本1.8,YARN版本 2.8.0,Hive版本2.1.1,HBase版本 1.2.5。从业务系统导出的 XML半结构化的海量支付清算数据经过简单的清洗都存储到HDFS中。
Apache Hadoop Yarn是一种Hadoop集群环境的通用资源管理系统,通过它可以为上层应用提供统一的资源管理和调度,提高集群的资源利用率和数据共享能力。
HBase是一个高可靠性、面向列、可伸缩的分布式数据存储系统,与传统的基于行的关系型数据不同,它是基于列存储的。HBase利用 Hadoop HDFS作为其文件存储系统,Hadoop MapReduce[11]为HBase处理海量数据提供高性能的计算能力。
Hive[12-14]被认为是 MapReduce2.0,它将用户从编写繁琐的map和reduce函数中解脱出来,采用类似 SQL语句方式进行数据运算,极大提高了应用部署效率。Hive可以将结构化文本文件映射到它自身的表结构中,然后将用户提交的QL查询语句自动转化为 MapReduce过程进行运算处理,返回结果。

图2 平台软件架构Fig.2 The software architecture of platform
3 数据处理流程
在完成大数据平台环境搭建后,针对具体的应用场景,我们设计了这样的处理流程:

图3 数据处理流程Fig.3 Data processing flow
① 来自各个渠道的大数据源,通过定时任务,以批量传递的方式,主动推送、被动采集到 Hadoop平台中,在HDFS分布式文件系统中进行保存。
② 通过 MapReduce/Hive对原始数据进行提取、分析、清洗,完成ETL过程,形成结构化的数据,以键值对的形式,保存到HBase列数据库中。
③ 对数据分析目标进行分析、建模,在MySQL中建立立方体结构,建立事实表、维度表;从HBase中读取键值对数据,抽取、运算得到立方体的数据并插入到MySQL立方体中。
④ 建立 Web应用,调用 HBase进行明细数据查询;调用Kylin立方体展示接口,对MySQL立方体数据进行展示,可供自定义行列、钻取、追溯;调用润乾等报表工具,建立常规固定格式报表。
4 总结
央行范一飞副行长在 2017年科技工作会议上指出,要“加强分布式架构转型研究与规划,构建以大数据为支撑的央行决策平台”[15]。目前,人民银行已经建成、运行了多个重要业务系统,基本实现了中央银行业务的全覆盖,但各个的业务系统之间的数据并未实现互联互通,数据利用水平较低,同时,传统的关系型数据库无法处理海量数据的存储和快速查询。因此,以云计算、大数据、分布式技术为基础,建立中央银行的大数据标准体系和金融大数据分析平台势在必行。本人参与开发的支付清算大数据分析平台是大数据技术在人民银行业务上应用的初步探索,通过对新技术架构的运用、与业务数据的结合,力争形成和打造出规模适中、应用广泛、架构灵活的分布式大数据平台,对金融系统开展大数据平台建设有一定借鉴意义。
[1] 高晴. 浅析人民银行支付系统在全国支付系统中的地位[J].时代金融, 2017(35): 137+142.
[2] 2016年支付体系运行总体情况[J].金融会计, 2017(03):23-26.
[3] 宋现锋. 基于Linux的高可用性集群管理系统的设计与实现[D].西安电子科技大学, 2012.
[4] 周彩冬,潘维民.大数据在商业银行反洗钱的应用[J]. 软件,2016, 37(2): 1-7.
[5] 王琪, 鄂海红, 宋美娜, 黄叒. 论大数据技术对保险行业的影响[J]. 软件, 2017, 38(5): 7-11.
[6] 冯晓普. HBase存储的研究与应用[D]. 北京邮电大学,2014.
[7] 马凯航, 高永明, 吴止锾, 李磊.大数据时代数据管理技术研究综述[J]. 软件, 2015, 36(10): 46-49+56.
[8] 张丹. HDFS中文件存储优化的相关技术研究[D]. 南京师范大学, 2013.
[9] Kambatla K, Pathak A, Pucha H. Towards optimizing hadoop provisioning in the cloud[C]//Proc. of the First Workshop on Hot Topics in Cloud Computing. 2009: 118.
[10] 蒋鸿斌. 基于HDFS的分布式存储的研究与优化[D]. 电子科技大学, 2017.
[11] Chu C T, Kim S K, Lin Y A, et al. Map-reduce for machine learning on multicore[C]//NIPS. 2006, 6: 281-288.
[12] 王正也, 李书芳. 一种基于Hive日志分析的大数据存储优化方法[J]. 软件, 2014, 35(11): 94-100.
[13] 江三锋, 王元亮. 基于Hive的海量web日志分析系统设计研究[J]. 软件, 2015, 36(4): 93-96.
[14] 陈慧, 龚婷雨. 大数据分析与Apache-Kylin应用[J].江西通信科技, 2016(4): 26-29.
[15] 张瑞怀. 构建以大数据为支撑的央行决策平台[J]. 金融电子化, 2017(5): 42-44.
