关于职业院校教学资源网络平台搭建的研究
2018-04-20张丽华
张丽华
(滨州市技术学院,山东 滨州 256601)
职业教育为新形的教育形式,它能够有效地推进大学教育的信息化和普遍化,是组建终生研习系统和大学教育的科学样式。目前,职业教育的重要任务是主动开拓教育培训的新方式,加速职业教育的发展,创建覆盖全国的教学培训网络,形成具有网络性、公开性与自主性的终生教学系统。当前,职业教育的发展已步入平稳的提升环节,运用一类新的构架组建职业教育平台,组建对策库,确保平台可以实时适于方针的改变,已成为这个课题新的研究热点。
1 相关技术概述
1.1 云计算概述
云计算是一种通过互联网来提供动态的、互动的、可伸缩的以及可扩展的虚拟化资源计算模型,这种计算模型主要是通过把应用程序部署在一个虚拟的环境下来执行相关的任务。近几年,随着云计算在教育领域的应用程度越来越广泛,出现的应用类别也越来越多,特别是针对海量教学资源存储方面,高校要解决当前教学资源存储方面的难题,就离不开云计算技术。当前高校教学资源云平台建设,主要有以下几个特点:1)设备利用率高,服务可靠性高;2)弹性的服务,以满足不同的用户需求;3)运营成本低且可扩展。
1.2 分布式文件系统概述
分布式文件系统主要有Google文件系统GFS、IBM的BlueCloud、亚马逊云计算、HDFS分布式文件系统。
Google文件系统(Google File System,GFS)是一个大型的分布式文件系统。它为谷歌云计算提供了强大的海量数据存储服务功能,并且紧密地结合了Chubby、MapReduce以及Bigtable等分布式计算技术,是Google所有数据存储服务的底层实现。IBM的“蓝云(BlueCloud)”计划为客户带来即可使用的云计算。它包括一系列的云计算产品,使计算不仅仅局限在本地计算机或远程服务器集群之上,它通过一个分布式的、可全球访问的资源结构,使得数据中心在类似互联网的环境下运行计算。亚马逊目前已经为全球100多个国家或地区的企业或者个人提供了云计算服务的支持。AWS的迅速发展使它逐渐成为云计算领域的一个真正的领导者,一旦AmazonAWS官方在中国建立起云服务之后,很多国内企业的云计算都将受到深刻的影响。
HDFS是Hadoop框架的分布式文件系统,它是Hadoop框架的存储系统,这个文件系统主要是由一个分布式文件系统在虚拟化平台上运行,同时能够与现有的分布式文件系统进行通讯。HDFS具有很高的容错性,能够轻松简便地部署在低成本的硬件设备之上。HDFS利用数据流媒体的方式来对文件进行访问,在访问分布式文件系统时通过主节点向从节点发出任务请求,最终返回客户端请求。
1.3 分布式系统基本算法
1.3.1BigTable算法
Bigtable是一种数据结构化的分布式存储系统,这个是Google公司提出的一个分布式的存储系统,是为了处理大量的数据存储而量身定做的,但是随着云计算以及分布式文件的发展,这个分布式存储系统的用处也在不断地得到提升,它通常分布在成千上万的普通PC机上,各个节点的数据通过主节点上的服务器访问。
Bigtable是一个稀疏的、分布式的、持久化的、多维的排序映射,Bigtable的键有三维,分别是行键、列键和时间戳。每个数据值的映射是一个未解析的字节数组。在谷歌的Bigtable主要包含了3个重要的组件:一个链接的客户端数据库,一个主服务器,最后一个就是平板电脑服务器。针对系统的工作负载问题,BigTable能够动态地添加或者是删除平板电脑的数据,并将其更新到集群服务器当中去。
1.3.2MapReduce
算法MapReduce的计算模型如图1所示。
Map阶段任务(job)是在输入数据之后,对数据进行分割,成为独立的数据块,通过Map任务完全并行处理的方法把数据进行分割,输入和输出的数据都是用MapReduce存储在文件系统中的。通常,MapReduce框架和分布式文件系统运行在相同的一组节点之上,也就是说,任务调度节点和主节点通常在一起。该配置允许框架上那些有良好节点的数据有效地调度任务,这可以使网络带宽非常有效地利用整个集群。
MapReduce框架由一个主JobTracker和每个集群节点的TaskTracker一起搭建,主要负责所有数据处理任务的调度,这些任务分布给不同的奴隶,主人监控执行,唯一负责执行任务分配的只能是主人节点。
2 基于Hadoop的职业院校教学资源网络平台搭建的研究
2.1 环境需求
所搭建环境具体需求如下:
1)硬件环境:Master(主节点)1台、Slave(子节点)3台;
2)软件环境:操作系统:CentOS6.5,集群的主要软件:Hadoop1.2.1、JDK1.6.0_22、Vmwareworkstation和Eclipse3.2。
2.2 Hadoop平台的搭建
由于实验条件有限,本文采用4台服务器来搭建Hadoop集群并部署存储模型,进行功能、性能等测试,主节点服务器(master)的IP地址为:192.168.1.185(下面简称master),子节点1:192.168.1.186(下面简称slave1),子节点2:192.168.1.187(下面简称slave2),子节点3:192.168.1.188(下面简称slave3),架构规化如下:
master作为NameNode,SecondaryNameNode,JobTracker;
slave1、slave2以及slave3用来作为DataNode,TaskTracker。
2.2.1设备网络设置
搭建集群网络分配时以4台小型机集群应用程序来搭建部署主网。主网络的服务器名称以TestHadoop为基础,后跟编号185~188。IP地址前3项不变,后面的项按照从1~4的编码方式进行编号,如218.196.248.1。然而test1用来作为Namenode,即master(主节点),其他都用来作为数据节点Datenode,即slave(子节点)。部署前4台机器之前都要能够相互ping通,如果失败了就得修改/etc/hosts文件,把其IP地址与机器的名称进行对应,例如218.196.248.2与TestHadoop2要相互ping通。还有子结点,统一采用CentOS6.5操作系统。这4台小型机搭建和部署的Hadoop的软件版本以及安装目录结构都得保持一致,并且用户名也要一样,所以,每台机器的用户名都统一设置为相同的用户名称。在默认路径/home/hadoop/下设置用户名为hadoop,密码为:hadoop。
2.2.2免密码SSH设置
SSH免密码设置这个步骤是很重要的,因为如果这一步成功,以后的步骤就会顺利多了。Linux通常只有Telnet。但Telnet缺点是沟通不能进行加密,这种方式只能在网络访问存在不安全因素的情况下可以采用。对于Hadoop集群来说,为了能够解决这个问题,就特别引入了一个加密的通信协议,即SSH(SecureShell)协议。这个协议通过使用非对称加密,使用rsa和dsa加密传输的内容,可以避免网络窃听。Hadoop过程与字母之间使用SSH,每次都需要输入一个密码。为了实现自动化,需要进行配置SSH免密码设置。
2.2.3Hadoop软件安装
通过Hadoop用户来登录系统,将安装软件解压到集群内的所有机器上,安装完成之后再来编辑conf/hadoop-env.sh文件,首先需将Java_HOME设置为Java安装根路径。用Hadoop_HOME指定安装的根路径。修改masters以及slaves配置这一步,主要就是通过对文件/usr/local/hadoop/conf/slaves以及/usr/local/hadoop/conf/masters文件进行修改,把数据节点的主机名添加到slaves的配置文件当中,同时也把名称节点主机名添加到masters的配置文件当中。添加的时候可以加多个,每行1个,机器的主机名必须已经在每个服务器的/etc/hosts中配置好。
2.3 初始化和启动Hadoop集群
2.3.1初始化集群环境
在对Hadoop集群进行安装部署完成后,在启动Hadoop集群之前对Hdaoop进行初始化操作,初始化namenode,为HDFS的第一次运行做好准备。
在Linux命令行执行hadoop namenode-format命令来初始化namenode节点。不必把这个format就和磁盘格式化联想到一起,它只是对hdfs来说的,不会格式化文件系统,namenode format只是初始化一些目录和文件而已。
2.3.2启动Hadoop集群
在对主节点master结点配置用户环境变量之后,通过在master主结点192.168.1.85上来执行命令,启动hadoop集群程序,具体在Linux命令行中来执行相关的命令启动Hadoop集群。执行bin目录下的start-all.sh,通过执行JPS命令来查看后台启动的进程,具体执行命令jps,如果执行命令之后出现如图2所示内容,则说明Hadoop启动成功。

图2 正常显示截图
3 实验结果及分析
由于学校基础实验条件的限制,在搭建Hadoop分布式集群的时候,选用一台PC机用来作为NameNode主服务器,剩余3台PC机用来作为子节点服务器,通过对Linux集群环境进行相关验证。本次实验测试的数据源来自学校的一些教学资源,以及在CSDN网站和网易公开课等教学资源平台上收集而来的数据,本次测试所用数据为50 G的教学资源。
3.1 不同数据块大小处理速度测试
把所要测试文件分割成不同大小的Block进行存储,然后测试对于不同节点处理速度有什么影响,结果见表1。
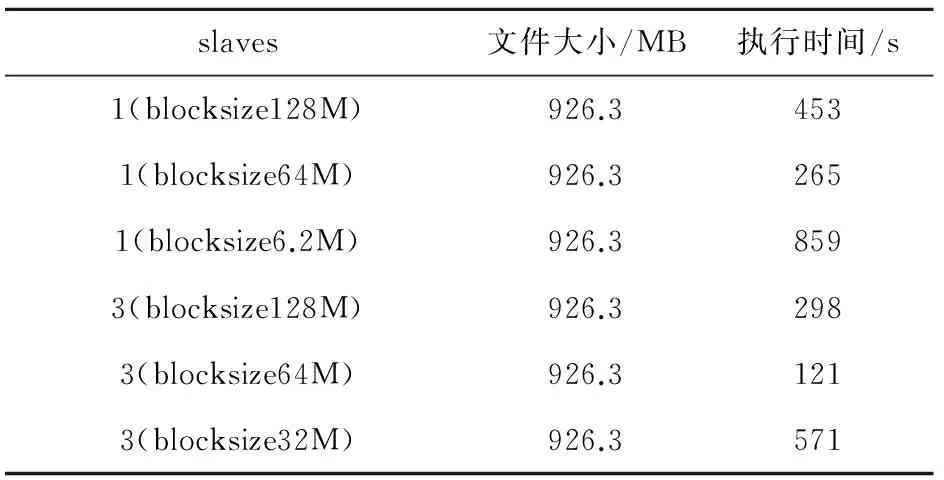
表1 不同数据块大小处理速度测试结果
从测试结果可以看出,blocksize(数据块大小)对于性能具有比较大的影响,如果将block设置得太小,就会增加job任务的个数,这样就同时也加大了任务之间协作的通讯代价,从而降低整体的性能,如果把数据库block设置得过大同样也会阻碍job任务的并行处理机制。因此,这个数据值的大小需要根据数据大小以及数据量来综合考虑。
3.2 不同节点数的处理速度比较测试
为了测试集群中节点数对处理速度的影响,本测试采用了不同大小的文件分别在1个节点和3个节点之上进行了测试,具体的测试结果见表2。

表2 两节点和四节点进行测试结果
从表2的测试结果可以看出,3个节点的明显比1个节点的处理速度更快,随着文件的增大,测试效果更加明显。从这个测试结果可以得出,在进行集群建设的时候,应该考虑集群节点的数量,同时,节点数的集群中处理数据的设置对于数据资源的存储和处理性能有明显影响。在设置过程中应综合考虑节点数和文件大小之间的关系。
3.3 应用改进型MapReduce算法的性能测试
在做这个测试之前,首先,要对原始测试数据文件进行设置,设置好相应的文件权值,同时还要设置集群中的NameNode主节点数为1个,DataNode数据节点为3个,Job子任务数为10个,然后运行,并通过测试对应用MapReduce算法改进前后的执行速度进行比较并记录,然后通过分析得出测试结果比较改进前后的优势和劣势,具体的结果见表3。

表3 应用改进型MapReduce算法的性能测试结果
表3的测试结果可以说明,在Hadoop集群中,应用基于改进型的MapReduce算法模型可以明显提升数据访问的速度以及处理性能。通过这个测试可以说明,基于改进型的MapReduce算法在基于云计算环境下的高校海量数据存储模型中的应用是成功的,使用这种改进型的算法可以提升存储模型的访问速度以及数据处理性能。
4 结语
本文详细介绍了云计算环境下Hadoop平台的搭建过程以及集群的配置方法。还介绍了集群的初始化以及启动关闭集群的步骤,最后通过对不同数据块、不同节点数以及应用改进型MapReduce算法模型前后的数据访问处理速度和性能进行了详细的分析。在部署和搭建Hadoop集群中,根据学校现有的实验条件,搭建和部署了Hadoop完全分布式集群,并进行存储模型的测试。实验结果表明,基于云计算的海量教学资源数据存储模型是高效且可行的。
[1] 李小龙,张宸瑞,耿斌,等.高职院校混合式教学模式改革:“MOOCs时代”的探索与启示[J].电化教育研究,2015,36(12):52-58.
[2] 闫广芬,张栋科.“互联网+职业教育”体系架构与创新应用[J].中国电化教育,2016(8):7-13.
[3] 龚健.高职数字化教学资源体系的建设与应用[J].计算机与网络,2015,41(7):42-44.
[4] 徐国庆.职业教育教学资源库开发:问题、原理与方法[J].泰州职业技术学院学报,2015,15(2):1-7.
[5] 王伟,钟绍春,尚建新.中职示范校数字化资源体系建设及推进策略研究[J].中国电化教育,2014(5):113-120.
[6] 周惠,曾红,陈剑利,等.基于云计算的职业教育教学资源的研究——以“世界大学城”中湖南职教教学资源建设为例[J].职教通讯,2014(17):1-3.
[7] 魏民.提高职业教育信息化水平加快推进现代职业教育体系建设[J].中国职业技术教育,2014(21):221-226.
[8] 申剑飞.基于云平台的职业教育资源库构建研究[J].湖南大众传媒职业技术学院学报,2013,13(6):53-55.
[9] 尹导.职业教育数字化教育教学资源平台浅析[J].中国职业技术教育,2012(17):70-75.
[10] 尹导.关于职教数字化教育教学资源平台的调查[J].职教论坛,2012(30):82-87.
