基于改进内容分析算法的网页正文提取
2018-04-18陈婷婷
陈婷婷,严 华,2,臧 军
(1.四川大学 电子信息学院,四川 成都 610000;2.电子信息控制重点实验室,四川 成都 610000;3.中石化管道储运有限公司 荆门输油处,湖北 荆门 448000)
0 引 言
互联网上的网站由于某些商业原因,网页中的正文内容通常会被一些广告、版权信息、评论版块等网页噪音围绕,这无疑对精确抽取正文内容带来难度。另外,随着互联网网页的爆炸式增长,网页布局风格也是变化万千,不同类型网站网页样式通常大不相同。如何将正文提取方法适用于各种网站的网页布局,正确过滤网页噪音,使其具有通用性,仍是我们需要解决的问题。
1 相关研究
目前国内外对于网页正文提取的算法主要分为4大类:
(1)基于模板规则。这类算法从大量网页中生成模板,进而通过模板匹配来过滤网页噪音从而生成网页正文[1-3]。通常,不同的网站拥有不同的网页布局,同一网站下的网页拥有相似网页布局。基于模板规则的正文提取方法复杂度较低,但由于其主要针对一个或相似网页布局的网站,不具有通用性。
(2)基于视觉分块。这类算法根据网页中的位置视觉信息来确定正文区域块,虽然提取效果很好但其依赖于浏览器内核代码,耗时长,算法复杂度高[4,5]。
(3)基于启发式规则。这类算法首先将HTML解析成DOM树或某种特定格式,根据正文特征如文本长度、纯文本比率、标点,人为指定若干规则最终找到正文块并提取正文内容,复杂度较低,针对新闻、博客类网站有较好的正文提取效果[6-8]。
(4)基于机器学习。这类算法使用机器学习算法,如粒子群算法[9,10]、决策树算法[11],对网页正文特征,如文本特征密度、特征标签个数、标点个数或标点密度等确定其影响因子权值,根据目标函数最大值确定正文内容。该类算法适应性较高,但其运算量较大,算法复杂度较高。
Readability内容分析算法作为一种启发式算法,以其高效过滤网页噪音,目前已被应用到多种浏览器的文本浏览应用中。该算法通过遍历DOM对象,结合标签和属性值对节点进行加权计分,根据分数和文本特性重新整合出页面内容。然而,在应用到不同风格的网页正文抽取中时,容易遗漏正文内部数据信息的问题显得尤为突出。针对该不足,从正文块生成和剪枝两个方面对Readability算法进行改进,在确保过滤网页噪音基础上有效地保留了正文数据信息。
2 网页正文提取
目前互联网上的网页主要分为3种类型,即导航型、主题型、图片型。导航型网页主要由各种超链接构成,例如各大网站的首页,主要目的是方便用户选择感兴趣的网页浏览;主题型网页主要由成段而连续的纯文本构成,以此来描述一个或多个主题,这些文字一般位于网页中心,被一些广告、相关链接块、版权说明信息等网页噪音围绕;图片型网页主要以图片的形式阐述内容,仅含有少量的文字说明。另外,在浏览网页过程中还发现一种类似于半导航半主题型的网页,即在导航链接下有部分不完整的文字描述链接主题。
本文提出的正文提取方法针对主题型网页,通过大量搜集各大网站主题型网页后,得到了关于正文特征的几点规律,即:
(1)正文信息紧密地集中分布于网页中的某一区域,其通常集中包含在一个容器标签中或者分散包含在多个同级容器标签中。
(2)网页中的正文与广告链接这类网页噪音均为文本内容,区别在于两者之间的文本特性,即正文内容文本长度较大、纯文本比率较高、标点符号较多。
(3)网页中还存在部分文本特性与正文相似的网页噪音,如版权信息,其纯文本比率较高。这类网页噪音通常与其它广告链接一起分布在正文四周,极少夹杂在正文内部。
3 Readability算法原理
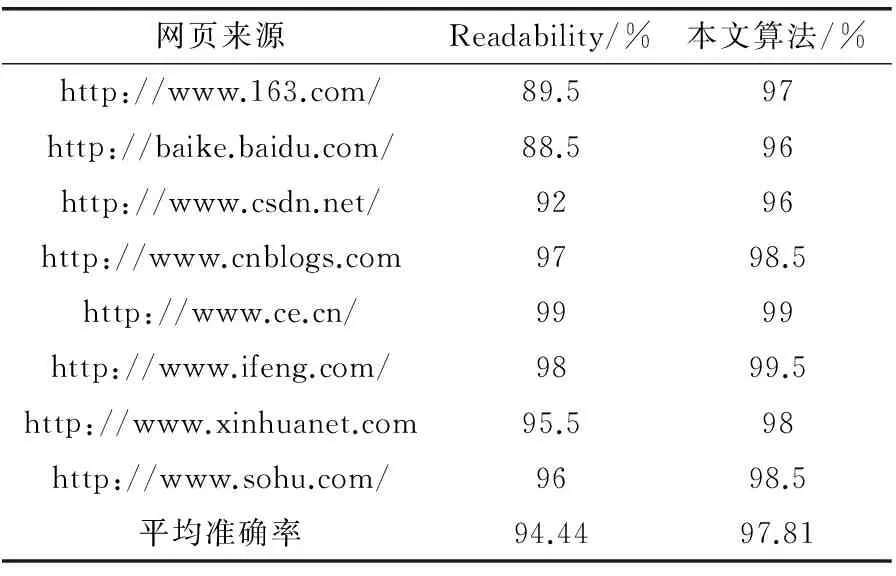
Readablitity算法主要通过p标签的文本特性以及定义的正则表达式对标签进行过滤和加权计分,从而进行内容分析。正则表达式见表1。

表1 正则表达匹配
算法步骤:
步骤1HTML解析。如图1所示,将HTML解析成一棵DOM树,通过遍历树节点,操作HTML标签。
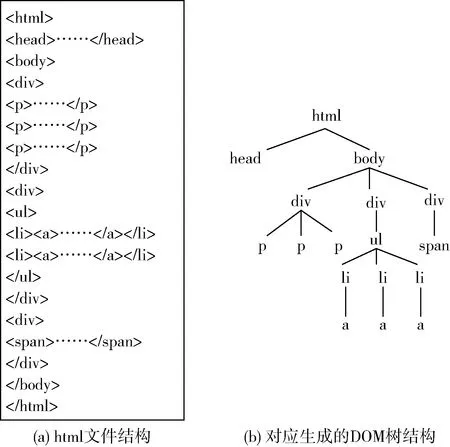
图1 构造DOM树
步骤2过滤。遍历标签节点,提取其class和id属性进行正则匹配。表1中,unlikely_Candidates用于节点的过滤,表示该节点内容不太可能是正文,仅当出现正文抽取结果为空时,选择不过滤这些节点进行二次提取操作。
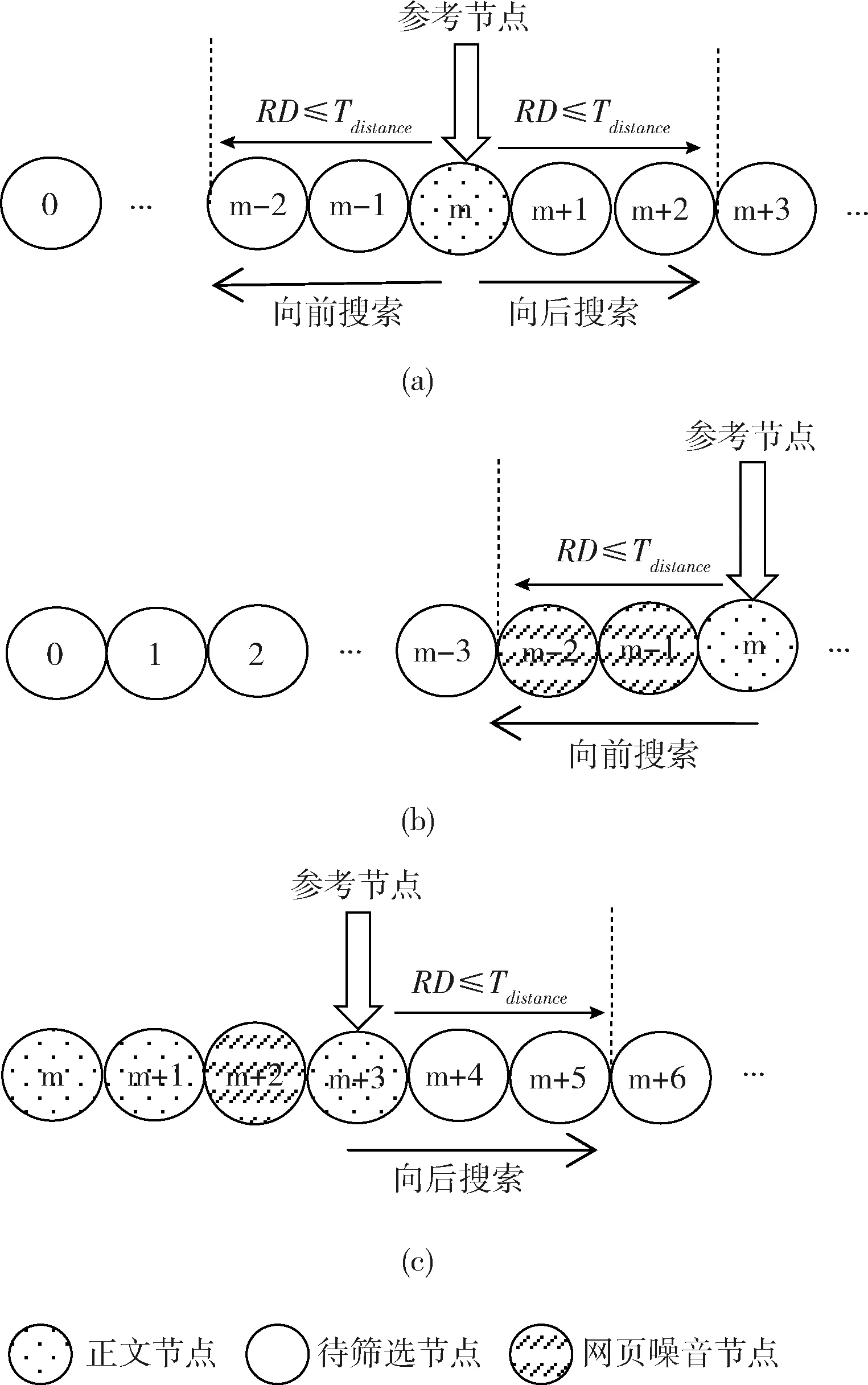
步骤3确定正文主块节点。针对段落标签,对其父节点和祖父节点进行计分。计分因子包括
标签所含文本长度、包含标点个数、节点标签名。若
标签文本长度达标(>25),将其父节点和祖父节点加入候选节点列表。最后通过遍历候选节点,结合纯文本比率选出最高分数的标签节点作为正文主块节点。步骤4正文块生成。遍历正文主块节点的同辈节点,判断其是否为正文节点。首先评估其节点分数,若节点分数达标则标注为正文节点,否则判断其是否为
标签节点,若为
标签节点且其文本特性达标则同样标注为正文节点。最后,创建一容器节点作为正文块节点,将筛选得到的正文节点与正文主块节点拼接到正文块节点中。
步骤5剪枝。对正文块节点中的特定标签进行清理,遍历其中的