基于全连接LSTM的心肺音分离方法
2018-04-18雷志彬陈骏霖
雷志彬 陈骏霖
基于全连接LSTM的心肺音分离方法
雷志彬 陈骏霖
(广东工业大学)

心肺音分离;非负矩阵分解;长短时记忆网络
0 引言
据世界卫生组织统计,2015年全球约有2160万(约55%)的非传染性疾病死亡与心肺疾病有关[1]。心肺疾病已成为严重威胁人类生命健康的主要疾病之一,而对心肺系统快速准确的诊断可及早发现病情,帮助患者早日康复。临床对心肺系统诊断的方式有心电图、胸透和听诊等。相较于其他诊断方式,听诊因具有快速、非侵入和低成本的优点而被广泛应用于心肺系统的早期诊断。然而,通过听诊器采集到的心音和肺音常混叠在一起,给临床诊断带来干扰。因此,从心肺音混合信号中分离出干净的心音和肺音,对提高听诊质量和协助临床诊断具有重要的现实意义。
由于心音和肺音在60 Hz~320 Hz频带存在相互干扰,传统的带通滤波[2]无法将它们完全分离。为解决这一问题,国内外学者提出许多方法,包括基于自适应滤波的方法[3-5]、基于小波滤波的方法[6-8]和盲源分离方法[9-12]等。

深度学习方法因具有出色的挖掘输入与目标之间非线性映射关系的能力而受到关注,广泛应用于语音识别[13]、语音增强[14]和语音分离[15]等领域。目前尚未有人采用深度学习方法来实现心肺音分离。长短时记忆(long short time memory,LSTM)神经网络具有学习输入数据时序相关性的能力,与心肺音信号的特性相符。本文提出一种基于LSTM的深度神经网络分离心肺音,同时为减少网络优化参数,提高网络收敛速度,在LSTM层中采用全连接网络结构。
1 心肺音混合模型
在安静环境下,通过电子听诊器采集到的心肺音混合信号可用以下线性混合模型表示[12]:
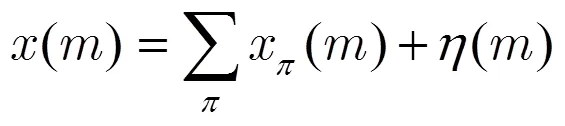
随着电子技术的发展,通过电子听诊器采集的信号中白噪声很弱,且可以通过预处理方法[16]去除。文献[12]认为预处理后的心肺音混合信号只含有心音和肺音,可用以下数学模型表示:
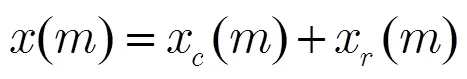

2 基于全连接LSTM的心肺音分离模型
本文提出的基于全连接LSTM的心肺音分离模型如图1所示。其中,心肺音混合信号的时频谱作为特征输入到全连接LSTM神经网络,网络输出心音和肺音的时频掩码。心音和肺音的时频掩码与混合信号的时频谱做点乘,从而获得分离出来的心音和肺音时频谱。分离的心音和肺音时频谱与原始真实的心音和肺音时频谱做比较,得到心音和肺音的分离误差项,这2个误差项的和即为全连接LSTM神经网络的代价函数。
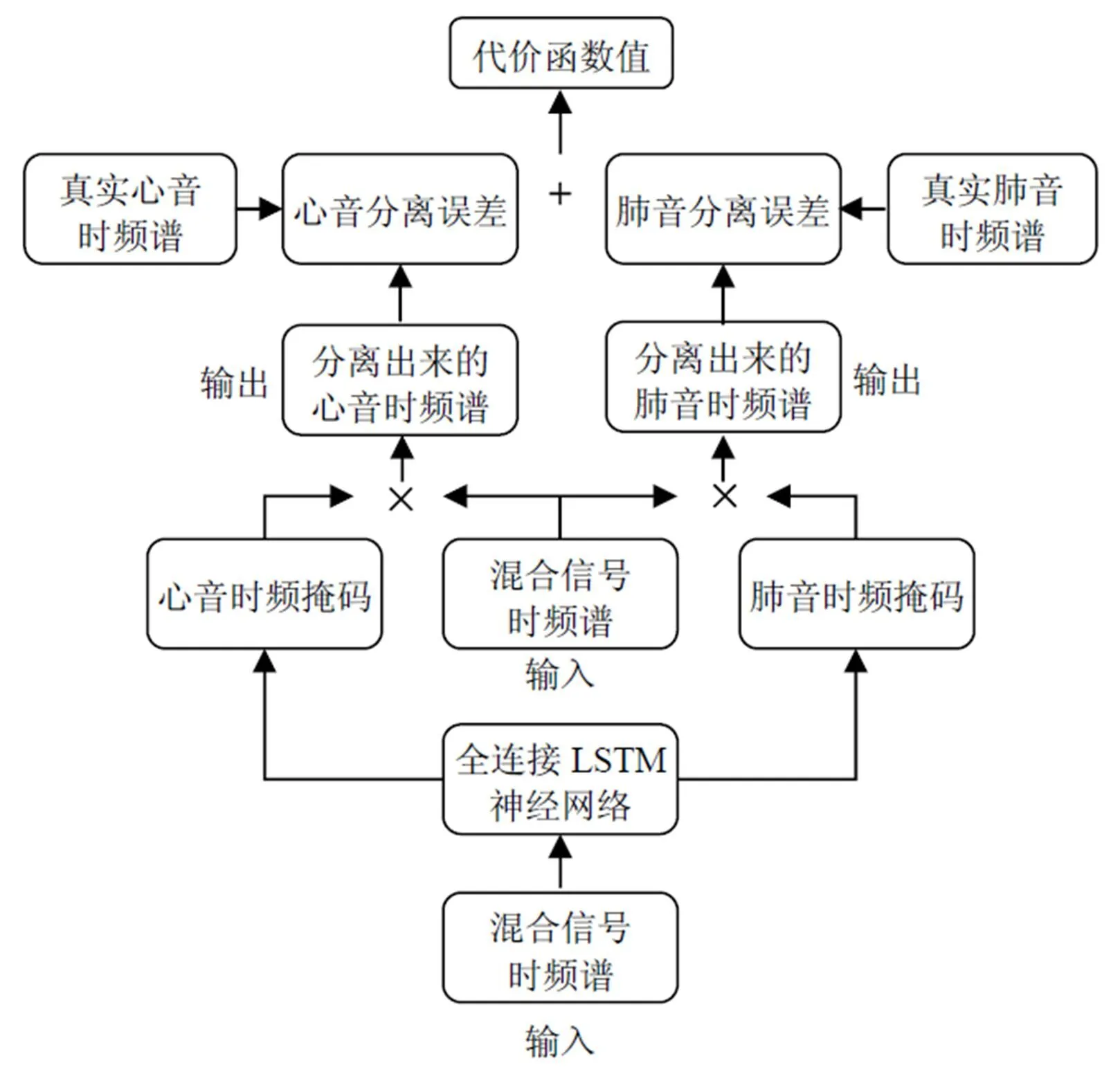
图1 基于全连接LSTM 的心肺音分离模型
2.1 全连接LSTM神经网络
在传统的神经网络中,用LSTM记忆块替换传统神经元组成LSTM网络。LSTM记忆块由1个记忆单元和3个门控单元组成,其结构如图2所示。记忆单元的状态受3个门控单元(输入门、遗忘门和输出门)的控制。输入门将当前数据选择性地输入到记忆单元;遗忘门调控历史信息对当前记忆单元状态值的影响;输出门用于选择性地输出记忆单元的状态值。3个门控单元和独立记忆单元的设计,使得LSTM网络具有学习输入信号时序相关性的能力,并且避免了网络训练过程中梯度消失和梯度爆炸的问题。
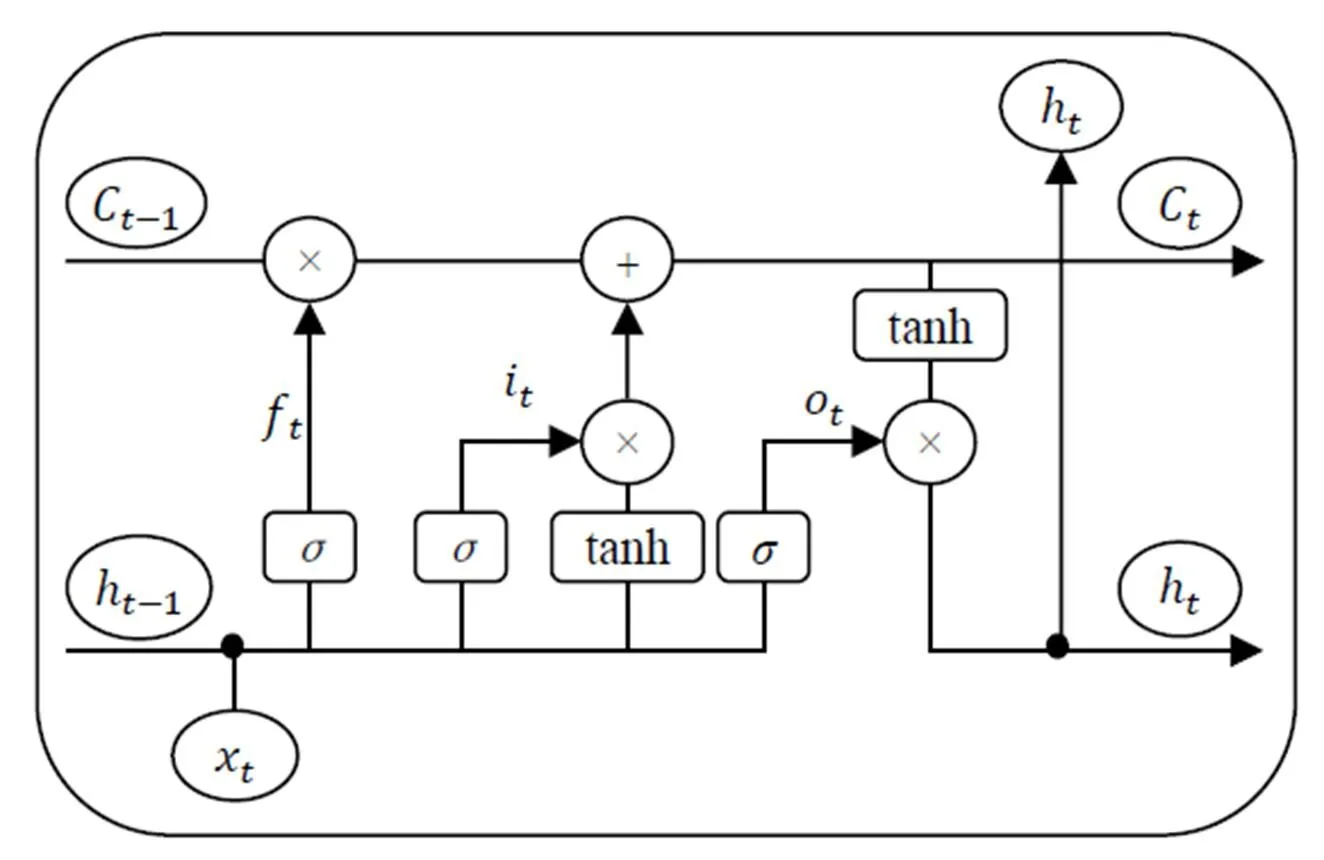
图2 LSTM记忆块[17]
在时刻,LSTM记忆块的状态通过以下3个步骤进行更新。
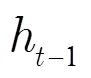
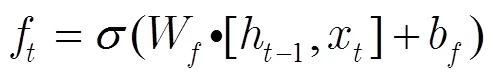

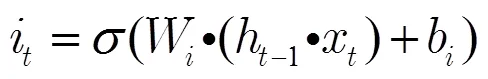

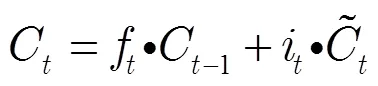
3)输出信息。由输出门控制信息输出,用Sigmoid函数决定要输出的记忆单元状态信息;用tanh函数处理记忆单元状态,2部分信息相乘得到输出值。
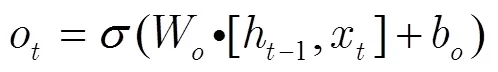

本文提出的基于全连接LSTM的神经网络框图如图3所示。

图3 基于全连接LSTM的神经网络框图
心肺音混合信号的时频谱作为网络的输入,经过一个全连接层的映射后,输出到一个具有3层全连接结构的LSTM网络中;全连接LSTM网络的输出再经过一个全连接层的映射输出心音和肺音的时频掩码。这里的全连接是指当前层的输入和输出拼接起来作为下一层的输入。通过全连接结构,可减少网络参数,加快网络收敛速度[18]。
2.2 时频掩码
在语音分离中,时频掩码常用作估计源信号时频谱的中间媒介。本文采用时频掩码为相位敏感掩码[19],定义为
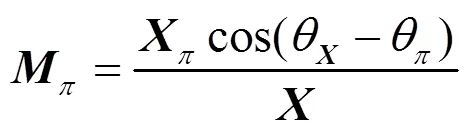
2.3 代价函数
基于全连接LSTM神经网络的代价函数[20]为
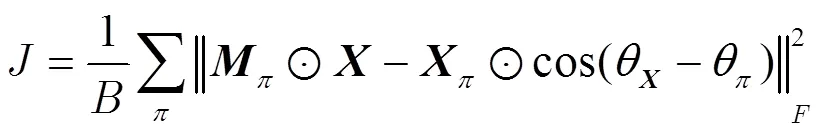
3 实验和结果分析
3.1 实验设置
在一个自构的心肺音数据集上评估本文提出的基于全连接LSTM的心肺音分离方法性能。该数据集来源于公开数据集[21-28],含有111条干净的心音信号和36条干净的肺音信号。由于从不同的公开数据集中筛选出来的信号具有不同的信号长度和采样频率,本文通过截取和降采样将信号调整为10 s,2 kHz采样频率。仿真实验的输入信号为0 dB信噪比的心肺音混合信号,其合成方法为将干净的心音和肺音信号按1:1能量比线性混合。通过计算分离得到的心音和肺音信号SNR来评估心肺音分离性能。SNR越高,表示心肺音分离性能越好。
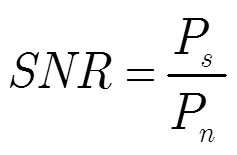
实验中,STFT采用窗长为128个采样点的汉宁窗,窗口的移动步长为32个采样点。心肺音混合信号经过STFT后得到的时频谱一帧一帧地输入到基于全连接LSTM的心肺音分离网络中,每一帧含有129个频率特征。网络第一层为含有64个神经元的全连接层;接着的3层全连接LSTM层分别含有64,128和256个神经元;最后一层为含有129个神经元的全连接层,网络输出心音和肺音每一帧的时频掩码。
本文使用三重交叉验证评估网络的心肺音分离性能。将111条心音信号和36条肺音信号平均分成3份,在每一重交叉验证中,其中1份用于测试,另2份用于训练,最后通过平均三重交叉验证结果获得最终的评估结果。为比较线性与非线性方法的心肺音分离性能,实验中监督非负矩阵分解法(SNMF)采用作基线方法。为了检验利用时序信息是否能够加强心肺音分离效果,本文设计了一个基于全连接的神经网络(F-NN),用全连接层替代F-LSTM网络中的LSTM层,并保持其他模型参数与F-LSTM网络一致。
3.2 实验结果和分析
表1比较了F-LSTM,F-NN和SNMF的心肺音分离性能。与SNMF相比,F-NN和F-LSTM具有更优的心肺音分离性能。F-LSTM分离出来的心音和肺音信噪比分别提高了1.69 dB和1.73 dB,验证了在心肺音分离中,非线性心肺音分离模型优于线性模型。与F-NN相比,F-LSTM分离出来的心音和肺音信噪比分别提高了0.67 dB和0.76 dB,验证了利用时序信息能够进一步加强心肺音分离效果。综上所述,本文提出的F-LSTM网络取得了较优的心肺音分离性能。
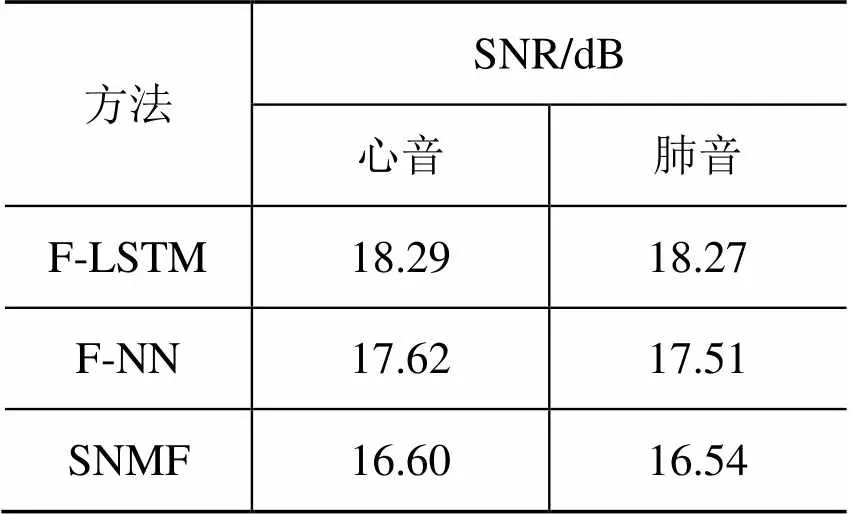
表1 实验结果对比
4 结语
本文将LSTM网络应用于心肺音分离,以处理心肺音成分的非线性混叠情况,并捕捉心肺音成分的时序相关性,加强分离效果。为了减少网络参数,提高训练收敛速度,文中LSTM网络采用了全连接网络结构。在公开心肺音数据集上的仿真结果表明:相较于线性心肺音分离模型,非线性分离模型取得更优的分离效果,并且利用心肺音成分的时序相关性能进一步提高心肺音分离的性能。
[1] World Health Statistics 2017: monitoring health for the SDGs, Sustainable Development Goals[R]. World Health Organization, Tech. Rep., 2017.
[2] Gavriely N, Palti Y, Alroy G. Spectral characteristics of normal breath sounds[J]. Journal of Applied Physiology, 1981,50(2): 307–314.
[3] Sathesh K, Muniraj N J R. Real time heart and lung sound separation using adaptive line enhancer with NLMS[J]. Journal of Theoretical and Applied Information Technology, 2014, 65(2):559–564.
[4] Ruban Nersisson, Mathew M Noel. Heart sound and lung sound separation algorithms: a review[J]. Journal of Medical Engineering and Technology, 2017,41(1):13–21.
[5] Ruban Nersisson, Mathew M. Noel. Hybrid Nelder-Mead search based optimal least mean square algorithms for heart and lung sound separation[J]. Engineering Science and Technology, 2017,20:1054–1065.
[6] Liu Feng, Wang Yutai, Wang Yanxiang. Research and implementation of heart sound denoising[J]. Physics Procedia, 2012,25:777–785.
[7] Gradolewski D, Redlarski G. Wavelet-based denoising method for real phonocardiography signal recorded by mobile devices in noisy environment[J]. Computers in Biology and Medicine, 2014,52:119–129.
[8] Mondal A, Saxena I, Tang H, et al. A noise reduction technique based on nonlinear kernel function for heart sound analysis[J]. IEEE Journal of Biomedical and Health Informatics, 2017, doi:10.1109/JBHI.2017.2667685.
[9] Chien J C, Huang M C, Lin Y D, et al. A study of heart sound and lung sound separation by independent component analysis technique[D]. in 28thAnnual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS’06). IEEE, 2006:5708–5711.
[10] Ayari F, Ksouri M, Alouani A T. Lung sound extraction from mixed lung and heart sounds FASTICA algorithm[D]. in 16th IEEE Mediterranean Electrotechnical Conference (MELECON). IEEE, 2012:339–342.
[11] Makkiabadi B, Jarchi D, Sanei S. A new time domain convolutive BSS of heart and lung sounds[D]. in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2012:605–608.
[12] Shah G, Koch P, Papadias C B. On the blind recovery of cardiac and respiratory sounds[J]. IEEE Journal of Biomedical and Health Informatics, 2015,19(1):151–157.
[13] 张舸,张鹏远,潘接林,等.基于递归神经网络的语音识别快速解码算法[J]. 电子与信息学报, 2017, 39(4): 930-937.
[14] 韩伟,张雄伟,闵刚,等.基于感知掩蔽深度神经网络的单通道语音增强方法[J].自动化学报,2017,43(2):248-258.
[15] 王燕南.基于深度学习的说话人无关单通道语音分离[D]. 合肥:中国科学技术大学,2017.
[16] Chen P Y, Selesnick I W. Translation-invariant shrinkage/ thresholding of group sparse signals[J]. Signal Process, 2014,94:476–489.
[17] 任智慧,徐浩煜,封松林,等.基于LSTM网络的序列标注中文分词法[J].计算机应用研究,2017,34(5):1321-1324,1341.
[18] Huang G, Liu Z, Maaten L V D, et al. Densely connected convolutional networks[J]. IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2017: 2261–2269.
[19] Erdogan H, Hershey J R, Watanabe S, et al. Deep recurrent networks for separation and recognition of single channel speech in non-stationary background audio[J]. New Era for Robust Speech Recognition: Exploiting Deep Learning. Berlin, Germany: Springer, 2017.
[20] Kolbaek M , Yu D , Tan Z H , et al. Multi-talker speech separation with utterance-level permutation invariant training of deep recurrent neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017,25 (10): 1901–1913.
[21] Bentley P, Nordehn G, Coimbra M, et al. The PASCAL Classifying heart sounds challenge[DB/OL]. (2011-11-01) [2018-12-20]. http://www.peterjbentley.com/heartchallenge.
[22] PhysioNet. Classification of normal/abnormal heart sound recordings: the physionet/computing in cardiology challenge 2016[DB/OL]. (2018-08-13) [2018-12-20]. https://physionet. org/challenge/2016.
[23] Welch Allyn. Student clinical learning[DB/OL]. (2018-12-20) [2018-12-20].https://www.welchallyn.com/content/welchallyn/ americas/en/students.html.
[24] Easy Auscultation. Heart and lung sounds reference guide[DB/OL]. (2018-12-20) [2018-12-20]. https://www. easyauscultation.com/heart-sounds.
[25] Open Michigan. Heart sound and murmur library[DB/OL]. (2015-04-14) [2018-12-20]. https://open.umich.edu/find/open- educational-resources/medical/heart-sound-murmur-library.
[26] East Tennessee State University. Pulmonary breath sounds[DB/OL]. (2002-11-25) [2018-12-20]. http://faculty. etsu.edu/arnall/www/public_html/heartlung/breathsounds/contents.html.
[27] Medical Training and Simulation LLC. Breath sounds reference guide[DB/OL]. (2018-12-20) [2018-12-20]. https://www.practicalclinicalskills.com/breath-sounds-reference-guide.
[28] PixSoft. The R.A.L.E. Repository[DB/OL]. (2018-12-20) [2018-12-20]. http://www.rale.ca.
Cardiorespiratory Sound Separation Method Based on Fully Connected Long Short-Time Memory Network
Lei Zhibin Chen Junlin
(Guangdong University of Technology)
In order to address the interference of cardiac sounds and respiratory sounds, researchers proposed a method for separating the cardiorespiratory sound based on non-negative matrix factorization (NMF). However, this method assumes that the cardiac sounds and respiratory sounds are mixed in a linear method in the time-frequency domain, and it didn’t utilize the temporal correlation of cardiorespiratory sounds. Therefore, in this paper we applied the long short-time memory (LSTM) network to the separation of cardiorespiratory sounds to deal with the nonlinear mixing of cardiorespiratory sounds and capture the temporal correlation to enhance the separation performances. In order to reduce the network parameters and improve speed of training, LSTM were constructed in a fully connected structure. The experimental results show that the LSTM network achieves better performances of cardiorespiratory sound separation than the supervised NMF method.
Cardiorespiratory Sound Separation; Non-Negative Matrix Factorization; Long Short-Time Memory Network
雷志彬,男,1994年生,硕士研究生,主要研究领域:模式识别,机器学习,生物信号处理。E-mail:leizhibin_er@163.com
