全局模式下的深网数据抽取与挖掘
2018-04-18姚晓鹏高圣兴薛君志陆敏超
姚晓鹏 高圣兴 薛君志 陆敏超
1(上海申腾信息技术有限公司 上海 200040)2(上海市计算技术研究所 上海 200040)3(浙江工商大学统计与数学学院 浙江 杭州 310018)
0 引 言
深网是相对于表层网络而言的,不能被传统的搜索引擎索引到信息资源的,指的是互联网中可访问的在线数据库。其内容存储在真正的数据库中,但这些内容只有在递交查询后才会由Web服务器动态生成页面把结果返回给访问者的网站。
深网的研究目前主要分为两个方面:(1) 深网的规模、分布和结构的研究。美国Bright Planet公司,专门从事数据整合和企业信息分析,开发了深网检索平台工具DQM。此外,还对深网的规模和相关性进行了研究,并发布了调查白皮书。(2) 深网信息搜索中的关键技术的研究。目前主要的关键技术有Deep Web接口识别方法、信息提取算法、数据库选择算法、Deep Web集成查询接口生成方法等。
而深网的信息资源具有以下三个特点:(1) 信息资源量巨大。深网是Internet中信息最快的增长点,并且随着时间的推移,深网的信息量会越来越大。(2) 信息质量高。它与表层的一般网页相比,深网的内容都更加的专业和有深度,信息间的相关度也比较高,具有巨大的商业价值和潜在信息。(3) 信息便于处理。深网的信息多数容易使用一些统计软件处理,格式相对整齐。因此解析深网主要功能并研究其关键技术,从而采集深网的巨大信息资源,具有重要意义。
在深网的信息数据搜索中,用户可以按照自己的需求进行搜索,网络服务器将会自动检索后台数据库,生成满足条件的结果页面。该页面通常包含一个或几个数据区,每个数据区又包括若干数据记录,而这是一般的搜索引擎所做不到的。
如果能从结果页面中抽取出数据,进而通过数据挖掘发现其潜在的关联并整合,则可以为用户提供宝贵的信息。
由于从深网上搜索得到的数据是动态的,并不能被直接利用,所以必须把数据抽取到本地。基于上述问题,可建立一个包含各个概念的全局模式,并且搜索的属性与全局模式的概念一一对应。然后根据用户的需求动态地生成全局模式,从而有效地抽取用户所需的信息。最后进行数据挖掘,整合数据项,得到有效的数据集,避免冗余。
1 深网数据抽取方法研究
深网在本质上与一般的网络不一样,从深网中抽取数据有以下几个制约因素:(1) 技术因素。深网多以数据库的形式贮存信息,根据用户的需求来动态的返回和库入口处设置的账号密码是一般搜索方法无法搜索的主要原因。(2) 利益因素。由于利益关系,一般的搜索引擎为了节约成本和时间,只对相对集中的网页进行搜索,而不会对每个网页进行深度搜索。(3) 法律因素。许多网站为了保护用户的隐私,设置成只对该网站的注册用户开放,因此使得一般的搜索引擎难以搜到相关的数据。
目前来看,从深网页面中抽取数据的方法主要有以下几种:(1) 手动抽取法。由工作人员根据网站属性一步步分类进去抽取。抽取规则由人工定义,时间比较久。(2) 封装器归纳法。一种由归纳式学习方法自动构造封装器的技术。用户在网站中标记出需要抽取的数据,再在这些例子上归纳出基于界定符的抽取规则。这是一种基于实例的方法,通过比较每一个新实例,抽取数据记录。(3) 自动抽取法。现在许多商用系统采用基于HTML的数据抽取方法。通过比较相似的网页归纳出使用正则表达式描述的网页模板,而该模板就是抽取规则。表1为上述3种网页数据抽取方法比较。
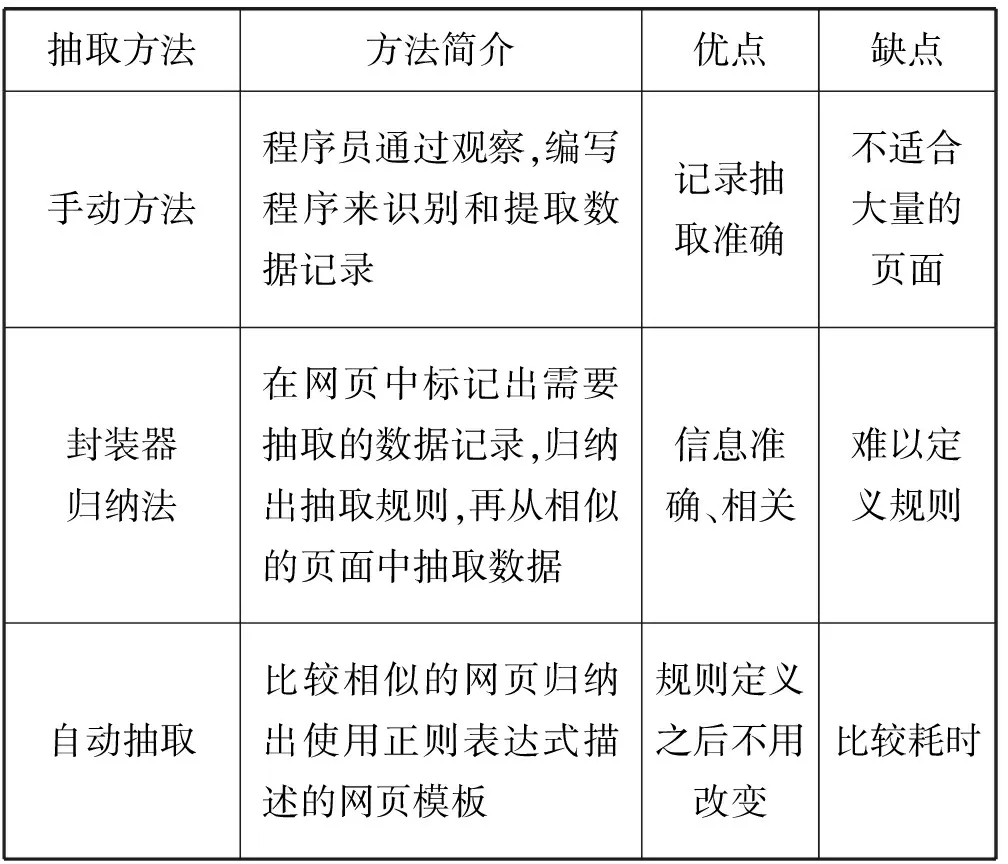
表1 数据抽取方法比较
在表1所示的几种数据抽取技术中,可以看出,性能较好的效率低(如手动方法,虽然准确率高,但是耗时很久,不适合目前信息量剧增的深网),而效率高的准确率和实用性又较差或是难以定义规则。故本文提出了一种新的全局模式下的深网数据抽取与挖掘方法。整体数据抽取流程分为两个模块:(1) 全局模式的生成。(2) 通过全局模式来进行数据抽取。图1是数据抽取的流程图。
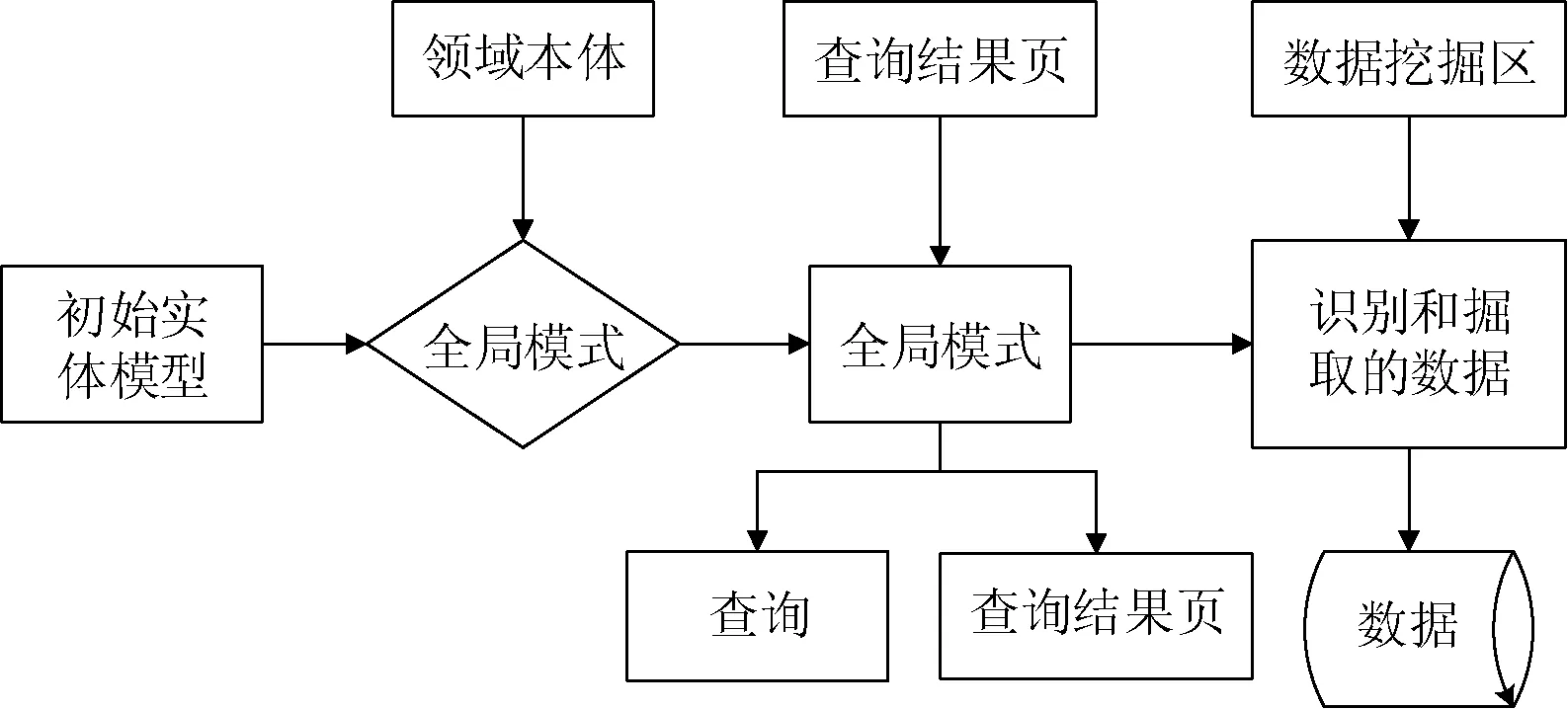
图1 全局模式下的数据抽取流程图
如图1所示,首先通过观察实体模型(实际例子)得到一个全局模式,再将全局模式的实体做成数据库表以便于数据的存储。而数据抽取模块也包含了两个部分内容:数据的挖掘、抽取和识别数据记录。
此外,对于一个网页尤其是未知的网页,还需考虑如何确保创建出全局模式。因此,在创建全局模式前,采用改进之后的贝叶斯信念网络对整个网页预先抽取重要的属性,再根据相应属性创建全局模式。
2 全局模式
2.1 改进贝叶斯信念网络
全局模式创建的好坏直接影响到最终的数据抽取的效果,而其中属性的数量又非常重要,过少的属性容易造成信息的不完整,会使得有用信息的丢失;而过多的属性,则会收集太多无意义的信息,造成冗余。因此可以运用贝叶斯信念网络的思路,对其进行改进,然后预先对网页抽取出重要的属性或概念,以确保做到全局模式。
首先,贝叶斯公式:
(1)
式中:X,Y是一对随机变量。
式(1)定理允许我们使用先验概率、类条件概率和证据概率来表示后验概率。
贝叶斯信念网络是联合概率分布,它提供一种因果关系的结构,并可以在此基础上进行学习。如果其网络结构和所有数值都是给定的,那可以直接进行计算。但如果数据是隐藏的,只是知道存在这样的依存关系,此时就需要进行条件概率的估算。
我们知道一个网页上会有许许多多的属性或概念,有许多属性之间相互存在关联,而且有的属性是出现频率较高,因此可以改进贝叶斯网络算出其概率。以下是改进贝叶斯信念网络的算法:
{(C1,C2,…,Cd)代表所有变量}
forj=1 toddo
令CG(j)表示G中第j个次序最高的变量;
令π(CG(j))={CG(1),…,CG(j-1)}是排在CG(j)前面的变量的集合;
从π(CG(j))中去除对Cj没有影响的变量(使用先验知识);
再计算概率公式,得出第j个变量的概率P(Cj),并以此抽取出作为全局模式的变量。
end for
然后根据
(2)
计算出最小支持概率Pmin。若所有变量相互间均没有任何联系影响,该值为0。
依据上述算法所得结果,保留相互联系紧密,即概率大于Pmin的属性变量,记为G= {(C1,C2,…,Ci,…,Cn}。然后我们从G中选取那些是先验概率的变量作为查询的属性,记为Q={A1,A2,…,Ai,…,An}。
2.2 全局模式的创建
通过上述方法预处理之后,我们还为每个实体的属性设置一定的权限,使得用户可以根据自身的需求,动态地实时生成全局模式。比如全局模式的属性个数并不固定,在通过算法得出相应的属性变量后,用户仍然可以根据自己需求人为的添加其他属性。
创建全局模式的过程如图2所示。

图2 创建全局模式流程图
从图2中可以看出,先要初始化4个集合L、I、P、M,令它们都为空。再创建一个查询集合,把输入的属性放入集合L中,把查询集里的元素放入输入属性中。接着把实体E放入集合I中。然后把所有相同属性的数据放入L中,并记录。依次重复上述步骤,直到得到一个全局模式。
其中,实体E={Et,(t1,v1),(t2,v2),…,(ti,vi),…,(tn,vn)},其中Et是实体类型,ti和vi分别表示第i个属性的类型和值。
实体模型M={Et,L1,L2,…,Li,…,Ln},其中Et实体类型,Li是对应每一类型属性的一组标签。
全局变量G={(C1,C2,…,Ci,…,Cn},其中Ci是全局模式的概念;Q={A1,A2,…,Ai,…,An},其中Ai是查询接口待输入的属性。
输入属性Ai=(Ni,T),其中Ni是输入属性Ai的名称,T是Ai的数据类型。G和Q的映射关系f(C,A)。
结果模式R={(C1,P1),(C2,P2),…,(Ci,Pi),…,(Cn,Pn)},其中Ci是G的属性。
3 数据抽取与数据挖掘
3.1 数据抽取
在抽取数据之前,首先要对文档进行适当的整理,比如剔除无效的页面,通过使用jTidy工具对不标准的文档进行初步修正,确保其符合W3C DOM规范。接着创建HTML Dom树,其中包括:HTML标签,属性和文本。网页由标签树T表示,t是树T的根节点,Sub(t)表示一个树的子树。
因为结果页面一般是基于模板自动生成的,并且一个结果页面包含若干个相互独立的数据块。所以一个网页的抽取模式是相对固定的,只要创建了一个网页的抽取模式,其他网页就可以采取相同抽取模式。若现存的全局模式无法抽取到所需数据,则需生成新的模式。图3是数据抽取算法的整体流程。
图3中,以提取的结果模式的数量变化作为标志,若数量减少则说明已提取到所需的数据,则产生结果页面,并停止抽取;反之,说明还没有完全提取数据,则继续提取。
通过全局模式抽取的数据,还需要进行数据的识别。我们首先从结果页面的标签,把概率值最高的作为第一个已知属性,再运用改进多重比较法判断,并将结果页面的全部属性分为已知和未知的属性。
(3)
式中:ni,nj分别为第i、j个属性,Yi,Yj分别为第i、j个属性的概率,Sp为两个属性的标准差。若n1为已知属性,与n2去比较,若所求得的Q小于0.9,则n2为未知属性;反之n2为已知属性。然后对所有结果页面的属性进行比较,即可将结果页面的属性分为已知和未知的属性。
3.2 数据挖掘
通过全局模式直接抽取得到的数据中包含了许多无用、重复的信息,因此还要进行数据挖掘。
首先,遍历整个HTML Dom树找到之前输入的属性的关键词所在的节点,然后根据节点的特征,判断该节点是否有效。比如树的深度很小,那么该节点就很有可能是无效的;若节点附近的区域数据量较小,那么该节点也可能是无效的。
在剩余的节点中,再根据基于密度的离群点来检测并剔除其中的无效信息。
基于密度的离群点指的是一个对象的离群点得分是该对象周围密度的逆,其逆距离表达式为:
(4)
式中:N(x,k)是包含x的k-最近邻的集合,|N(x,k)|是该集合的大小,而y是一个最近邻。
基于密度的离群点检测与基于邻近度的离群点检测密切相关,所以密度通常用邻近度定义。
以下是基于密度的离群点的算法:
{k是最近邻的个数}
需要标明的是,这一点极其重要,他在一定程度上回应了上一个部分提出的必然性难题。对人类理性来说,因果性存在于时间序列当中,囿于这一点,自由意志才是与上帝预知相矛盾。实际上,神的领域在永恒当中,所以神意根本不像人一样被限定在时间序列。既然“永恒当下”敉平了人类时间的三个向度——过去现在未来,那么因果序列在神意那里便完全失效。这也呼应到前文对神意与命运关系的辨析,整个逻辑显得十分缜密。
for all对象xdo
确定x的k-最近邻N(x,k)
使用x的最近邻(即N(x,k)中的对象)
确定x的密度density(x,k)
end for
for all 对象xdo
若结果大于1,则视为无效信息并剔除x
end for
接着用Fk-1×Fk-1方法进行关联挖掘,用函数apriori-gen(挖掘布尔关联规则频繁项集的算法)候选过程合并一对频繁(k-1)-项集的时候,所需要满足条件——仅当它们的前k-2项集相同。
令A={a1,a2,…,ak-1}和B={b1,b2,…,bk-1}是一对频繁集,若它们满足:
ai=bi(i=1,2,…,k-2)且ak-1≠bk-1
则可合并A与B。
如果都是在最好的情况下,那么每一次合并都可以产生一个可行的候选k-项集;如果每一次都是最坏的情况下,则每一次都必须合并前一次迭代发现的每一对频繁(k-1)-项集。
因此,合并频繁项集的总开销为:
(5)
所花费的时间是:
(6)
式中:w为频繁项集总数,k等于树的最大的深度。
最终,通过该方法合并所得到的数据内部存在一定关联,即结果满足大于或等于最小置信度阈值(该值默认75%,也可以人为取值),并且可以使得最后结果的数据项更加简洁。
4 实验验证与结果
为了验证该深网数据抽取与挖掘方法的实际效果,本文选取了多个网站作为实践对象来验证该方法的通用性。由于受限于篇幅,故这里仅以抽取http:// thebookery.com/网站的结果进行效果展示。
进入该网站,运用改进贝叶斯信念网络的算法,计算出Pmin=0.3,得出查询的属性为4个:Author、Title、Keyword、ISBN,记为Q={A1,A2,A3,A4},然后输入相应的查询属性,并获得返回结果。
通过比较几种不同的方法的时间、正确率等,得到的实验结果如表2所示。
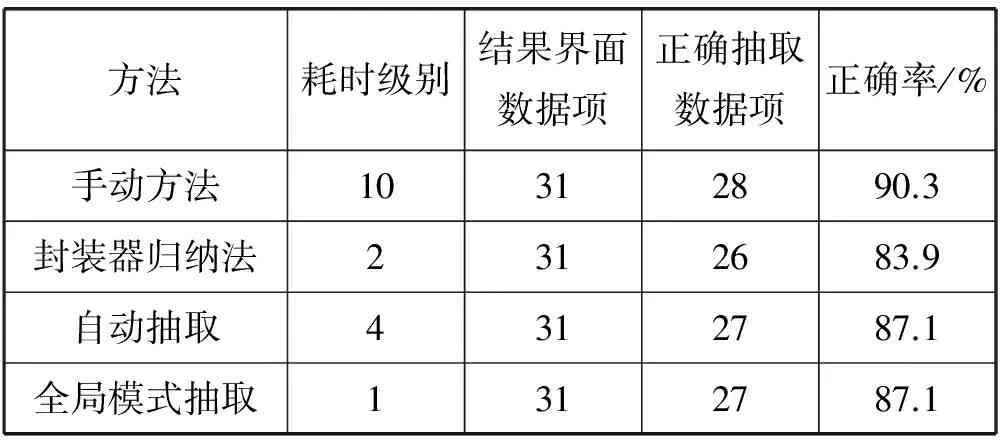
表2 数据抽取方法实验对比
由表2可知,耗时从级别1到级别10,所用时间越来越多,尤其是手动方法需要几小时甚至几天才能全部收取数据,并且手动抽取方法因人而异,有的人正确率可以达到100%,而有的的却低于80%,因此在实际抽取中不适用。全局模式抽取相对于自动抽取耗时更少。封装器归纳法由于规则难以定义,使得抽取到的数据的正确率相对较低。因此全局模式下的数据抽取方法相对于其他方法最省时,正确率又相对较高。
接着,对抽取好之后的数据运用统计学关联分析的方法进行数据关联挖掘,并且取最小置信度阈值为75%,得到数据挖掘后的树状图如图4所示。
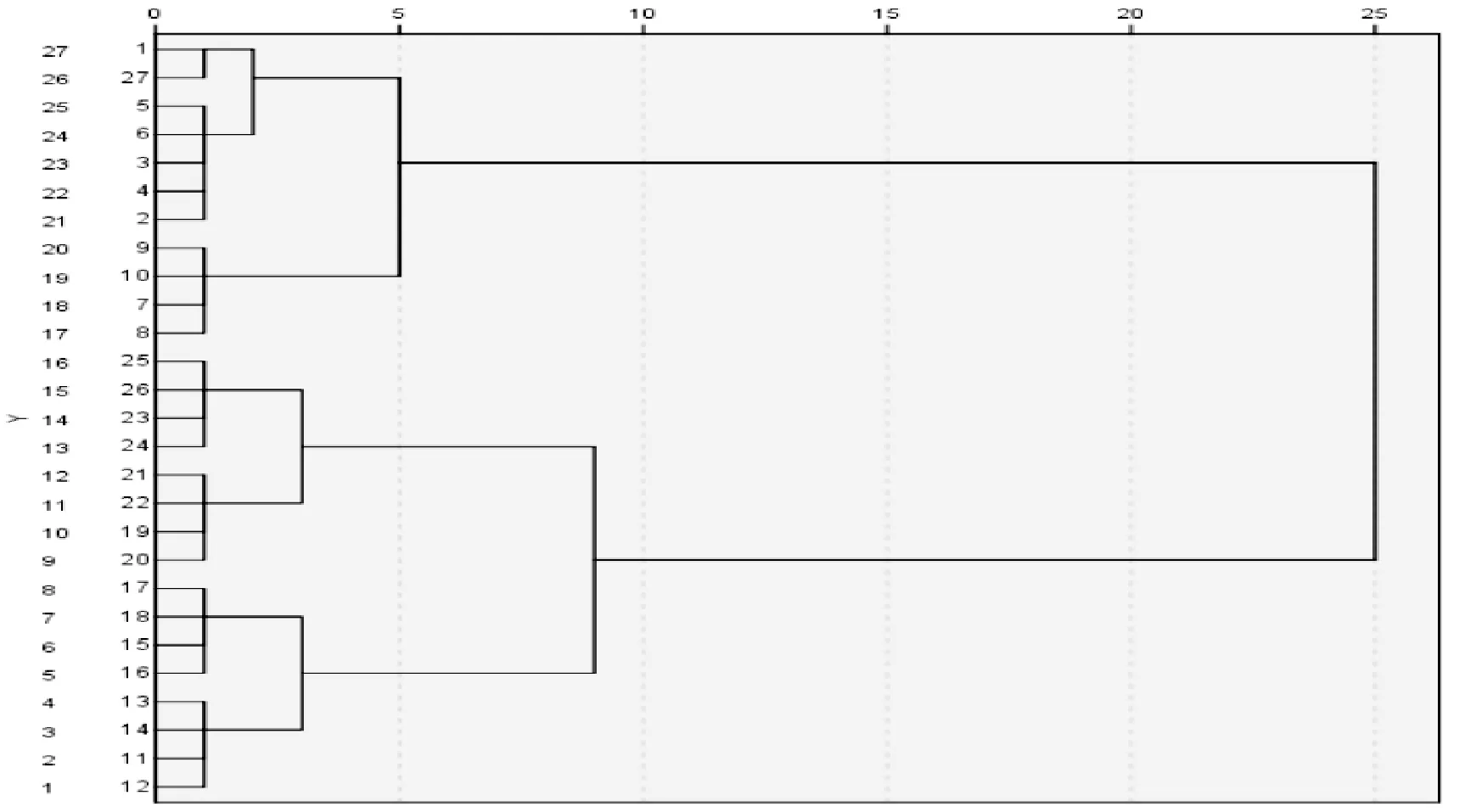
图4 数据合并树状图
由图4可知,27项数据项经过1次关联挖掘后变成了7项数据项,大大简化了原有的数据量,使得原有数据项中的无效信息减少。
5 结 语
深网中数据的抽取,不同于一般搜索引擎的搜索。本文提出了一种全局模式下的深网数据抽取和数据挖掘方法。该方法首先分析实际例子的属性,运用改进贝叶斯信念网络算法,确定相应的属性标签,构建一个动态的全局模式。接着抽取并识别结果页面中的数据,根据基于密度的离群点来检测并剔除其中的无用信息。最后运用挖掘布尔关联规则频繁项集的算法进行关联挖掘,整合数据项。实验结果表明:该方法相对于其他几种数据抽取方法,可以快速、有效、正确地抽取数据,并且通过数据挖掘后的数据项更简洁,无效信息更少。
[1] 范明,范宏建.数据挖掘导论(完整版)[M].北京:人民邮电出版社,2011.
[2] 杨道玲.深网信息资源采集初探[J].图书馆杂志,2006,25(12):19-22.
[3] 束长波,施化吉.基于动态数据源的DeepWeb信息集成框架研究[J].无线通信技术,2015,24(1):48-52.
[4] 张忠占,傅莺莺.统计推断(翻译版)[M].北京:机械工业出版社,2010.
[5] 何广达.DeepWeb查询表单属性模式匹配的研究[J].数字技术与应用,2015(6):104-104.
[6] 顾韵华,高原,高宝,等.基于模板和领域本体的Deep Web信息抽取研究[J].计算机工程与设计,2014,35(1):327-332.
[7] 杰夫·霍金斯.智能时代[M].北京:中信出版社,2015.
[8] 王喜平,于国槐,宋晶.ASP.NET程序开发范例宝典[M].北京:人民邮电出版社,2015.
[9] Ozsu M T,Valduriez P.分布式数据库系统原理[M].周立柱,范举,吴昊,等译.北京:清华大学出版社,2015.
[10] Wang Qiuyue,Cao Wei,Shi Shaochen.Deep Web resource selection using topic model[J].Journal of Computer Applications,2015,35(9):2553-2559.
[11] Saissi Y,Zellou A,Idri A.Extraction of relational schema from deep web sources:a form driven approach[C]//2014 Second World Conference on Complex Systems (WCCS).IEEE,2015:178-182.
[12] Barrio P,Gravano L,Develder C.Ranking Deep Web Text Collections for Scalable Information Extraction[C]//ACM International on Conference on Information and Knowledge Management.ACM,2015:153-162.
[13] Witten I H,Frank E.Data Mining:Pratical Machine Learning Tools and Techniques[J].Acm Sigmod Record,2005,31(1):76-77.
