基于双向LSTM神经网络模型的中文分词
2018-04-16李维华金绪泽郭延哺
金 宸,李维华,姬 晨,金绪泽,郭延哺
(1.云南大学 信息学院,云南 昆明 650503;2.河南师范大学 教育学院,河南 新乡 453007)
0 引言
中文分词是指将连续的中文字符串按照一定的规范分割成词序列的过程。中文不同于英文,其自身的特点在于中文是以字为基本书写单位,句子和段落之间通过分界符来划界,但词语之间并没有一个形式上的分界符,而在自然语言处理中,词是最小的能够独立运用的有意义的语言成分,所以分词质量的好坏直接影响之后的自然语言处理任务[1]。
中文分词问题作为中文自然语言处理领域的重要基础研究,从20世纪80年代提出到现在,常用的研究方法可以分为以下四类:(1)基于字典的字符串匹配方法[2-3];(2)基于语言规则的方法[4-5];(3)基于传统概率统计机器学习模型的方法;(4)基于深度神经网络模型的方法。
随着SIGHAN国际中文分词评测Bakeoff的展开,将中文分词任务视为序列标注问题来解决逐渐成为主流。基于传统机器学习模型的方法主要为基于字标注的概率统计机器学习模型方法,在Bakeoff展开的初期,基于字标注的中文分词方法广泛应用,在评测中取得性能领先的系统均应用了此类思想[6]。基于统计的自然语言处理方法在消除歧义和句法分析等方面得到越来越广泛的应用,是近年来兴起的一种新的、也是最常使用的方法。对于给定的输入词串,该方法先确定其所有可能的词性串,选出得分最高的作为最佳输出。其中应用比较广泛的主要有隐马尔可夫模型(hidden markov model,HMM)[7]、最大熵模型(maximum entropy model,MEM)[8]和条件随机场(conditional random fields,CRF)[9-11]。以上基于传统机器学习模型的性能受限于特征的选择和提取,模型的训练是基于提取出的人为设定的特征。
为了尽可能避免特征工程的影响,深度学习网络模型逐渐应用到中文分词等自然语言处理任务中。2011年Collobert[12]将神经网络模型应用到自然语言处理中。2013年,Zheng等人[13]首先将神经网络模型应用到中文分词任务,同时还提出了一种感知器算法,在几乎不损失性能的前提下加速了训练过程。在此基础上,Pei等人[14]通过利用标签嵌入和基于张量的转换,提出了MMTNN的神经网络模型的方法,并用于中文分词任务。2015年,Chen等人[15]使用LSTM神经网络来解决中文分词问题,克服了传统神经网络无法长期依赖信息的问题,取得了很好的分词效果,同年,Chen等人[16]构造了一种基于栈结构的GRU神经网络模型,使用树形结构来捕捉长期依赖信息。这些方法都取得了非常不错的效果。
然而,单向LSTM神经网络只能记住过去的上文信息,但中文句子的结构较为复杂,有时需要联系下文的信息才能做出判断。2015年Huang[17]提出了一种双向LSTM-CRF模型,并把它用在了序列标注的任务上,取得了很好的效果。受此启发,在Chen[15]模型的基础上,本文提出使用双向的LSTM神经网络模型进行分词,在单向LSTM神经网络的基础上增加一层自后向前的LSTM神经网络层,并引入贡献率α对前传LSTM层和后传LSTM层输入隐藏层的权重矩阵进行调节,综合双向的记忆信息,实现更加准确的分词。
1 双向LSTM神经网络模型
1.1 LSTM神经网络模型
RNN(recurrent neural network)模型是Rumelhart等人[18]在1986年提出的具有循环结构的网络结构,具备保持信息的能力。RNN模型中的循环网络模块将信息从网络的上一层传输到下一层,网络模块的隐含层每个时刻的输出都依赖于以往时刻的信息。RNN模型的链式属性表明其与序列标注问题存在着紧密的联系,但在经典RNN模型的训练中,存在梯度爆炸和梯度消失的问题,且经典RNN模型很难处理长期依赖的问题。
LSTM神经网络(Long short-term memory neural network)模型[19]是RNN的扩展,专门设计用来处理长期依赖缺失的问题。与经典RNN网络不同,LSTM的循环单元模块具有不同的结构,存在四个以特殊方式相互影响的神经网络层。
LSTM网络的关键在于LSTM单元的细胞状态。在LSTM单元中,通过门(gates)结构来对细胞状态增加或删除信息,而门结构是选择性让信息通过的方式,如图1所示。LSTM单元具有输入门(input gates)、忘记门(forget gates)和输出门(output gates)三种门结构,用以保持和更新细胞状态,以下公式中it、ft、ot和Ct表示t时刻对应的三种门结构和细胞状态。
LSTM神经网络模型已经在许多应用中取得重大成功,诸如文本、情感分类[20-21]、机器翻译[22]、语意识别[23]、智能问答[24]和对图像进行文本描述[25]等自然语言处理任务中。由于LSTM神经网络模型通过记忆单元去学习从细胞状态中忘记信息、去更新细胞状态的信息,而且具有学习文本序列中远距离依赖的特性,很自然地想到可以使用LSTM神经网络模型进行中文分词的任务。

图1 LSTM结构图
1.2 双向LSTM神经网络模型
双向RNN(BRNN)模型是Schuster[26]在1997年提出的,目的是解决单向RNN无法处理后文信息的问题,单向的RNN只能在一个方向上处理数据,则双向循环神经网络的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。图2展示的是一个沿着时间展开的双向循环神经网络。
其中自前向后循环神经网络层的更新公式为:
(4)
自后向前循环神经网络层的更新公式为:
(5)
两层循环神经网络层叠加后输入隐藏层:
(6)

图2 双向RNN结构图
双向LSTM神经网络(Bi-direction long short-term memory neural network)模型是结合双向RNN和LSTM两个模型的优点形成的新模型,简单来说就是用LSTM单元替换掉经典双向RNN模型中的循环单元。2005年Graves[27]首次将双向LSTM神经网络模型应用于分类问题,并取得了较单向LSTM神经网络模型更为出色的结果。随后这个模型被推广到自然语言处理的各项任务中:2009年Wollmer[28]将双向LSTM模型应用于关键字提取;2013年Graves[29]将其应用于语音识别;2015年Wang[30]将其应用于字嵌入中;2015年Huang将其应用于词性标注[17];2016年Kiperwasser[31]将其应用于句法分析中。这些应用均取得了很好的效果。
2 基于双向LSTM神经网络的中文分词模型
中文分词可视为字符级别的序列标注问题,因此可以将分词过程视为对字符串中每一个字符标注的机器学习过程。目前,学术界使用最广泛的字符标注方法是四词位标注集{B,M,E,S},其中B(begin)代表标注词的开始字符,M(middle)代表标注词的中间字符,E(end)代表标注词的结束字符,S(single)代表标注词是单字字符。通过为字符序列中的每一个字符确定相应的标签,我们可将此问题转化为一个多分类的问题,然后通过神经网络模型的多分类层实现相关的标签分类。
基于神经网络的中文分词模型主要由三个部分组成:
(1) 文本向量化层;
(2) 神经网络层;
(3) 标签推断层。
基于双向LSTM神经网络的中文分词模型如图3所示。

图3 双向LSTM神经网络模型结构图
2.1 文本向量化层
使用神经网络模型来处理数据,需要先将输入的数据进行向量化处理。文本向量化的方式主要有两种。
(1) 独热表示(onehot representation):就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个1,其它全为0。1的位置对应该词在词典中的位置。但这种词表示有两个缺点:
① 会因为词典过大造成数据的维数非常大,而所构成的矩阵非常稀疏,不易进行训练,就是所谓的“维数灾难”问题;
② 不能很好地刻画词与词之间的相似性,也就是所谓的词汇鸿沟问题。
(2) 分布式表示(distributed representation)[32]是针对独热表示这两大缺点而提出的方法[31]。通过训练将某种语言中的每一个词映射成一个固定长度的短向量,将所有这些向量放在一起就形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间中引入“距离”,就可以根据词之间的距离来判断它们之间的语义相似性了。分布式表示通常又称embedding字嵌入(embedding)。
已有的研究表明,加入预先训练的字嵌入向量可以提升自然语言处理任务的性能。Word2Vec[33-34]是Google公司于2013年开源推出的一个获取字向量的工具包,它简单、高效、易于使用。本文的实验部分用Word2Vec作为第一层,把输入数据预先处理成字嵌入向量。基于字标注的分词方法则基于一个局部滑动窗口,假设一个字的标签极大地依赖于其相邻位置的字。给定长度为n的文本序列c(1:n),大小为k的窗口从文本序列的第一个字c(1)滑动至最后一个字c(n)。对序列中每个字c(t),当窗口大小为5时,上下文信息(c(t-2),c(t-1),c(t)c(t+1)c(t+2))将被送入查询表中,当字的范围超过了序列边界时,将以诸如“start”和“end”等特殊标记来补充。然后,将查询表中提取的字向量连接成一个向量X(t)。
2.2 双向LSTM神经网络层
双向LSTM神经网络层由两个部分构成:(1)自前向后的单层LSTM; (2)自后向前的单层LSTM。
设窗口大小为k,字向量维度为d,窗口内的文本数据通过训练好的字嵌入查找表,得到一个分布式表示向量,将此分布式表示向量从前往后输入到一个独立的LSTM单元中;又从后往前将其逆序后输入到一个独立的LSTM单元中。同时我们引入贡献率变量α来调整两个独立的单向LSTM层对后续数据的贡献影响,加权之后输入隐藏层进行线性变换,得到一个与标签集维度相等的向量。
2.3 标签得分计算
中文分词问题可以转换成字符序列中字符的标签分类问题。对于字符序列中的每个字符,基于双向LSTM神经网络的中文分词模型都会给出一个它在每类标签的得分。
以一个输入序列c(1:n)为例,概率Ct,设窗口大小为k,字向量维度为d,则通过训练好的字嵌入查找表,从前往后在m时刻得到一个维度为k×d向量x(mk+1,(m+1)k),输入到一个独立的LSTM单元中;从后往前在m时刻得到一个维度为k×d向量x((n-m)k+1,(n-m+1)k),将其逆序后输入到一个独立的LSTM单元中。两个输入作为双向LSTM神经网络的输入。
通过常识我们判断,对于分词任务来说,自前文的信息量与自后文的信息量是不对等的,前者要大于后者,也就是说通过自前往后LSTM层获得的gf(x(t))与通过自后向前LSTM层获得的gb(x(t))贡献不同。因此,我们引入一个贡献率变量α,并且α≥0.5。在引入α的条件下,双向LSTM神经网络经过变换之后得到一个输出y(t),如式(7)所示。
y(t)=αgf(x(t))+(1-α)gb(x(t))
(7)
y(t)再经过隐藏层的线性变换,可以得到一个与标签集维度相等的向量y(t),表示ct属于各个标签的得分。
2.4 标签推断层
在{B,M,E,S}标签系统中,相邻标签的分布并不是相互独立的,如标签B之后出现标签B、S的概率为0,也就是说标签B之后只可能出现标签M、E。故本文使用Collobert[12]提出了标签转移权重矩阵A的方法表示这个依赖关系,其中Aij表示从标签i转移到标签j的权重大小。Aij的值越高,表示标签i转移到标签j的可能性越大。那么,对于训练数据集中的一个输入字符序列c(1:n),其标签序列为y(1:n),则将该字符标签序列的得分定义为s(c1:n,y1:n,θ),如式(8)所示。
(8)


(9)
其中,s(x,y,θ)来自式(8),是字符标签序列的得分。
2.5 模型训练

(10)
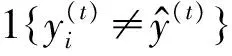
(11)
其中,
(12)
训练过程中用Dropout[35-36]来控制在模型训练时随机让网络中的某些隐藏层节点不工作,阻止了某些特征仅仅在其他特定特征下才有效果的情况。最后用小批量AdaGrad优化算法[37]对目标函数进行优化,其计算过程中采用误差反向传播[19]的方式逐层求出目标函数对神经网络各层权值的偏导数,并更新全部权值和偏置值。
3 实验
3.1 实验环境、数据集和评测指标
本文所用实验环境的主要参数为处理器:Intel(R)Core(TM)i7-6700k CPU @ 4.00GHz;图形加速卡:NVIDIA GeForce GTX 1060 6 GB;内存:16GB;操作系统:Ubuntu 16.04 LTS(64bit);使用Google开源深度学习框架TensorFlow 0.12构建所有神经网络模型进行训练和测试;使用Word2Vec对字向量进行训练预处理。
本文的实验数据集来自当前学术界普遍采用的训练语料和测试语料,其中本文神经网络模型的训练语料和测试语料来自MSRA数据集和PKU 数据集,这个由SIGHAN举办的第二届国际中文分词评测Bakeoff 2005所提供的封闭语料。其中训练语料按照通常做法,取90%作为训练集,10%作为开发集,且用来训练词向量的语料混合了搜狗实验室提供的全网新闻数据(SogouCA)以及MSRA数据集和PKU数据集中的训练集。其语料规模如表1所示。
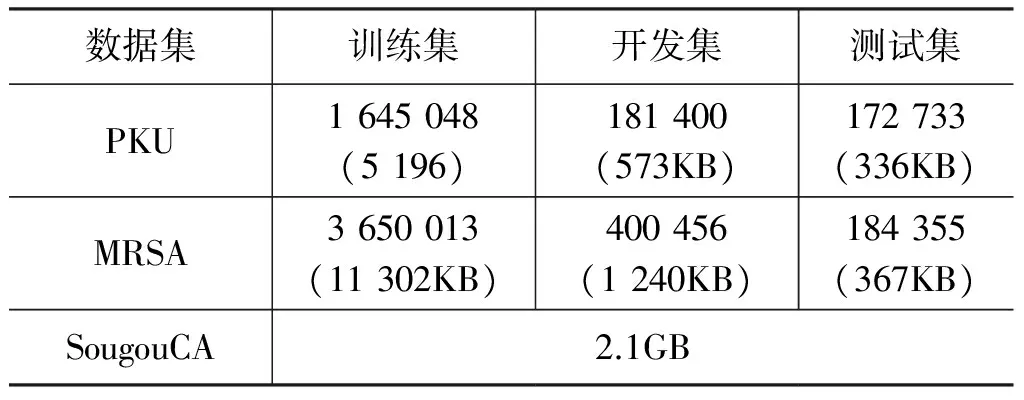
表1 实验所用语料库规模统计信息
在对中文分词性能的评估中,采用了Bakeoff 2005提供的评分脚本,其中包括分词评测常用的R(召回率)、P(准确率)和F1(召回率和准确率的调和平均值),以F1值作为评测的主要参考指标。
3.2 实验设计
本文设计了四个实验。
实验一为了验证文本向量化的必要性,设计了在其他条件都相同的情况下,实验得到通过未使用字嵌入层在PKU数据集中测试数据P、R、F1的值,以及不同维度下的字嵌入层在PKU数据集中测试数据的P、R、F1值,如表2所示。由于独热向量的“维数灾难”问题,故未使用字嵌入层的实验,只使用MSRA 数据集和PKU数据集中的训练集和开发集的数据,将其转化为独热表示。而使用字嵌入层的实验则混合使用SogouCA数据集以及MSRA、 PKU 数据集中训练集和开发集,通过Word2Vec转化为不同维度的词向量。

表2 随着字嵌入维度的变化,分词模型在PKU数据集上评测指标的变化
实验二为了验证Dropout的有效性,并确定合适的丢弃率,设计了不使用Dropout以及Dropout丢弃率为20%和Dropout丢弃率为50%的实验。在保证实验其他参数相同的条件下,测试在MSRA 数据集和PKU数据集中每一次迭代后的F1测试数据的变化情况。实验结果如图4所示。
实验三为了测试本文所构建的双向LSTM神经网络模型的效果,本文使用了如下几个基准模型:基于条件随机场模型的分词模型CRF++[38];Chen[15]提出的单向LSTM分词模型;双向RNN分词模型。对基准模型与本文使用的双向LSTM分词模型在MSRA数据集和PKU数据集下进行实验对比,在确保其他变量都一致的情况下(如使用相同维度的字嵌入,在输出层均使用丢弃率相同的Dropout),记录得到P、R、F1测试数据,对比模型参数均基于原作者给出的参数设置,实验统计数据均使用在可信范围内的最佳数据。实验结果如表3所示。
实验四为了验证本文提出的贡献率α是否会影响到实验效果,并确定效果最佳的贡献率α,本文设计了六个α取值,从0.5到1.00,相邻单位取值相差为0.1。以六个α值为基础构建了本文设计的双向LSTM神经网络模型,并保证其他参数都相同的条件下,在MSRA 数据集和PKU数据集下进行分词实验,并得到在不同的贡献率α下的测试数据P、R、F1,并进行对比。实验结果如表4所示。

表4 随着α的增长,分词模型评测指标的变化
3.3 实验参数设置
通过多次实验优化参数,我们最终把各项参数设置如下:初始学习率设置为0.2,最小批处理尺寸设置为20,隐藏层节点数设置为150,字嵌入向量的维度为100。对于输入窗口,我们将窗口分为左右两边,左窗口设置为0,右窗口设置为2。即将t到t+2的三个字符同时输入。为防止神经网络过拟合,我们采用l2正则化,参数设置成10-4,同时采用Dropout,并设置Dropout的丢弃率为0.2。
3.4 实验结果分析
实验一通过对比表2第2行和第3、4、5行数据可知,文本向量化的处理是非常必要的,加入字嵌入层会极大地提高模型的正确率。由使用大数据集SougouCA转化独热表示失败可知:只能在较小的规模下使用独热表示,若训练数据集较大,会导致词典过大而造成数据的维数非常大,且构成的矩阵非常稀疏,不易进行训练。其次,通过对比表2第3、4、5行数据可知:文本向量化使用的维度也会对结果有一定的影响,故本文采用结果相对较好的100维作为字嵌入向量的维度。
实验二通过观察图4中数据点的分布和走向有如下三个方面的结论。(1)不设置Dropout的模型在迭代前几次表现得较好,但随着迭代次数的增加,模型评测数据趋于稳定后,Dropout丢弃率为20%的模型表现优于不设置Dropout的模型; (2)Dropout丢弃率设置为50%的模型在整个迭代过程中都表现得比较糟糕,说明Dropout的丢弃率不宜过大,过大后可能会丢失重要信息; (3)无论是在MSRA数据集还是在PKU数据集,二者的趋势都较为接近,说明本文模型在不同数据集上表现较为一致,可以使用相同的参数设置。
实验三通过对比表3第6行和第4、5行数据可知:本文模型在MSRA数据集上实验结果F1,较单向LSTM提升0.72%,较双向RNN提升1.67%;在PKU数据集上的实验结果F1,较单向LSTM提升1.04%,较双向RNN提升2.76%。通过数据的分析比较,说明文本所提出的模型在分词的准确度上确有提高。
实验四通过对表4的各项数据的比较可知:(1)贡献率α对实际分词表现作用比较明显,P、R、F1的值随着α的增长,先变大后变小,在0.8处到达峰值。(2)无论是在MSRA数据集还是PKU数据集,二者的趋势都较为接近,这说明本文模型在不同数据集上表现较为一致,可以使用相同的参数设置。
4 结束语
本文的工作主要有两点:(1)将双向的LSTM神经网络模型运用到中文分词任务中,并构建了完整的模型;(2)创新地引入了贡献率α,通过α对前传LSTM层和后传LSTM层输入隐藏层的权重矩阵进行调节,设计了四个实验,实验结果证明:①使用文本向量化的字嵌入和在输入层设置Dropout会对实验结果带来影响; ②本文构建的双向LSTM神经网络中文分词模型在正确率上要优于其他基准模型; ③本文提出的贡献率α的确会对实验结果带来影响。
本文模型还存在着以下不足:(1)双向LSTM模型较单向LSTM模型在模型结构上更为复杂,从而在模型训练和测试的时候效率不如单向LSTM模型;(2)由于条件所限,本文实验在设置精度上比较粗糙,并没有优化到最理想的参数设置。
接下来值得研究改进的方向:(1)使用GRU等LSTM的变种单元替换传统LSTM,使得模型进一步简化,在效率上进行提升;(2)引入注意力机制完善模型,争取在正确率上进一步提升;(3)将本文所用的分词模型和贡献率α进一步套用在其他序列标注的相关问题(如词性标注、命名实体识别)上。
[1]黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3):8-19.
[2]梁南元.书面汉语自动分词系统——CDWS[J].中文信息学报,1987,1(2):46-54.
[3]赵海,揭春雨.基于有效子串标注的中文分词[J].中文信息学报,2007,21(5):8-13.
[4]Wu A,Jiang Z.Word segmentation in sentence analysis[C]// Proceedings of the 1998 International Conference on Chinese Information Processing,1998:169-180.
[5]Sui Z,Chen Y.The research on the automatic term extraction in the domain of information science and technology[C]//Proceedings of the 5th East Asia Forum of the Terminology,2002.
[6]任智慧,徐浩煜,封松林,等.基于LSTM网络的序列标注中文分词法[J].计算机应用研究,2017,34(5):1321-1324.
[7]李月伦,常宝宝.基于最大间隔马尔可夫网模型的汉语分词方法[J].中文信息学报,2010,24(1):8-14.
[8]Xue N,Converse S P.Combining classifiers for Chinese word segmentation[C]//Proceedings of the first SIGHAN workshop on Chinese language processing-Volume 18.Association for Computational Linguistics,2002:1-7.
[9]Peng F,Feng F,McCallum A.Chinese segmentation and new word detection using conditional random fields[C]//Proceedings of the 20th International Conference on Computational Linguistics.Association for Computational Linguistics,2004:562.
[10]罗彦彦,黄德根.基于CRFs边缘概率的中文分词[J].中文信息学报,2009,23(5):3-8.
[11]方艳,周国栋.基于层叠CRF模型的词结构分析[J].中文信息学报,2015,29(4):1-7.
[12]Collobert R,Weston J,Bottou L,et al.Natural language processing(almost)from scratch[J].Journal of Machine Learning Research,2011,12(1):2493-2537.
[13]Zheng X,Chen H,Xu T.Deep learning for Chineseword segmentation and POS tagging[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,2013:647-657.
[14]Pei W,Ge T,Chang B.Max-margin tensor neural network for Chinese word segmentation[C]//Proceedings of the Meeting of the Association for Computational Linguistics,2014:293-303.
[15]Chen X,Qiu X,Zhu C,et al.Long short-term memory neural networks for Chinese word segmentation[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,2015:1197-1206.
[16]Chen X,Qiu X,Zhu C,et al.Gated recursive neural network for Chinese word segmentation[C]//Proceedings of the ACL(1),2015:1744-1753.
[17]Huang Z,Xu W,Yu K.Bidirectional LSTM-CRF models for sequence tagging[J].arXiv preprint arXiv:1508.01991,2015.
[18]Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536
[19]Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[20]Liu P,Qiu X,Chen X,et al.Multi-timescale long short-term memory neural network for modelling sentences and documents[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing:2326-2335.
[21]Wang X,Liu Y,Sun C,et al.Predicting polarities of tweets by composing word embeddings with Long Short-Term Memory[C]//Proceedings of Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing,2015:1343-1353.
[22]Sutskever I,Vinyals O,Le Q V.Sequence to sequence learning with neural networks[C]//Proceedings of the 20th NIPS,2014:3104-3112.
[23]Graves A,Mohamed AR,Hinton G.Speech recognition with deep recurrent neural networks[C]//Proceedings of IEEE International Confenence on Acoustics,2013,38(2003):6645-6649.
[24]Wang D,Nyberg E.A long short-term memory model for answer sentence selection in question answering[C]// Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing,2015:707-712.
[25]Vinyals O,Toshev A,Bengio S,et al.Show and tell:A neural image caption generator[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,2015:3156-3164.
[26]Schuster M,Paliwal K K.Bidirectional recurrent neural networks[J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[27]Graves A,Schmidhuber J.Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J].Neural Networks,2005,18(5):602-610.
[28]Wollmer M,Eyben F,Keshet J,et al.Robust discriminative keyword spotting for emotionally colored spontaneous speech using bidirectional LSTM networks[C]//Proceedings of the ICASSP 2009.International Conference on IEEE,2009:3949-3952.
[29]Graves A,Jaitly N,Mohamed A.Hybrid speech recognition with deep bidirectional LSTM[C]//Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding(ASRU).IEEE,2013:273-278.
[30]Wang P,Qian Y,Soong F K,et al.A unified tagging solution:Bidirectional LSTM recurrent neural network with word embedding[J].arXiv preprint arXiv:1511.00215,2015.
[31]Kiperwasser E,Goldberg Y.Simple and accurate dependency parsing using bidirectional LSTM feature representations[J].arXiv preprint arXiv:1603.04351,2016.
[32]Hinton G E.Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society.1986:1-12.
[33]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[C]//Proceedings of International Conference on Learning Representation,2013:1-12.
[34]Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013(26):3111-3119.
[35]Hinton G E,Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[36]Srivastava N,Hinton G,Krizhevsky A,et al.Dropout:a simple way to prevent neural networks from overfitting[J].Journal of Machine Learning Research,2014,15(1):1929-1958.
[37]Duchi J,Hazan E,Singer Y.Adaptive subgradient methods for online learning and stochastic optimization[J].Journal of Machine Learning Research,2011,12(7):2121-2159.
[38]Taku.CRF++:Yet Another CRF toolkit[CP10L].http://taku910.github.io/crtpp/2005.

金宸(1991—),硕士研究生,主要研究领域为自然语言处理、机器学习。E-mail:chenjin0721@gmail.com

李维华(1977—),通信作者,博士,副教授,主要研究领域为数据与知识工程。E-mail:lywey@163.com

姬晨(1993—),硕士研究生,主要研究领域为自然语言处理。E-mail:418445839@qq.com
