基于WFST的俄语字音转换算法研究
2018-04-16易绵竹马延周
冯 伟,易绵竹,马延周
(战略支援部队信息工程大学 洛阳校区,河南 洛阳471003)
0 引言
在俄语语音合成和语音识别系统中,发音词典是存储俄语单词发音的重要基础资源,其规模和质量直接影响系统的性能。俄语作为一种拼音文字,在语言发展中不断有新词和外来词产生,发音词典必然难以包括所有俄语单词的发音。然而,大规模词典会大量占用存储空间,降低系统的运行效率。因此,需要探寻一种方法对俄语单词及其变化形式进行自动注音。
字音转换(grapheme-to-phoneme conversion,G2P)是指利用计算机自动为单词标注音标,将字母拼写的单词文本转换为可供人或机器阅读和处理的单词发音。俄语字音转换技术可以为俄语发音词典的构建提供支持,并有效解决集外词(out-of-vocabulary,OOV)的自动注音问题。
字音转换方法可分为基于规则的方法和数据驱动的方法。基于规则的方法即通过对俄语正字法和发音规律的总结,人工制定俄语的字音转换规则,实现对单词发音的预测。在文献[1-3]中,俄罗斯圣彼得堡大学的Kipyatkova和Karpov等人在其俄语语音识别系统的开发过程中,根据俄语辅音变化和元音弱化等规则,借助俄语重音词典,实现了基于规则的俄语字音转换。算法共包含七个步骤,经过两个循环完成,但并没有对算法的准确率进行测试。由于俄语发音特征复杂多变,正字法的约束也在逐渐减弱,规则中难免会出现无法覆盖到的例外情况,这些都会对字音转换的准确率造成影响。
数据驱动的方法是在足够训练数据的支持下,利用概率统计和机器学习算法,建立发音模型,通过解码算法为任意单词进行标音。数据驱动的方法是目前主流的字音转换方法。在国外,Galescu等[4]提出了基于期望最大化(EM)算法实现字素,音素一对一的对齐,通过N-gram建立发音模型的字音转换方法,并在NetTalk和CMU的英语数据集上进行了测试。Jiampojamarn等[5]提出了字素音素多对多的对齐方式,并将隐马尔科夫模型(HMM)应用于发音模型建模。Bisani等[6]提出了联合序列模型的方法,并在英语、德语和法语测试集上进行了测试,该方法也是目前较为流行的字音转换方法。Rao等[7]还将最新的长短时记忆(LSTM)循环神经网络(RNN)应用于解决字音转换问题。在国内,王永生等[8]提出了一种动态有限泛化法(DFGA)的机器学习算法,用于进行英语字音转换规则的学习。李鹏等[9]实现了一个基于CART树(classification and regression tree)方法的英语字音转换系统。赵坤等[10]提出了一种通过有条件维数扩展(CMI)决策树算法解决英语字音转换的方法。综上所述,数据驱动的字音转换算法在国内外已有不少研究,但应用对象主要为英语,还没有俄语方面的有关研究和实验。因此,有必要以俄语语音学知识为基础,完善俄语语料资源,对俄语字音转换算法的实现与应用做进一步研究。
在数据驱动的方法中,加权有限状态转化器(WFST)是建立索引的一种有效手段,它具有完善的理论框架,实现简单,能够有效减少存储空间,加快解码速度。Yang等[11]最先提出将WFST应用于字音转换的任务,并在NetTalk英语测试集上与文献[6]算法进行了对比测试。结果表明,WFST框架可以大幅减少模型训练的时间,提高单词发音的预测效率。Novak等[12]对字素音素的对齐方法进行了改进,提出了基于WFST的“一对多”和“多对一”对齐方式,还对解码算法进行了优化,提出了基于循环神经网络语言模型(RNNLM)的N-best解码算法,以及最小贝叶斯风险词图(lattice minimum Bayes-Risk,LMBR)解码算法,并在三个英语测试集上进行了对比测试。
以上算法都以英语为主要研究目标,其模型训练的过程与俄语之间难免存在差异。本文根据俄语单词的发音特点,采用了基于EM算法的俄语字音“多对多”对齐方法,然后将对齐结果利用联合N-gram模型训练并转化为WFST发音模型,最后通过最短路径算法进行解码,实现基于WFST的俄语字音转换。WFST的实现以开源库OpenFst为支持。此外,本文还对原始SAMPA俄语音素集进行了改进,增加了四个元音音素和一个重音符号,设计了包含46个音素的俄语音素集。最后,依据新音素集构建了20 000词俄语发音词典,将其作为模型训练和测试的语料数据。
1 基于改进的SAMPA俄语音素集设计
音素集就是音素的集合。由于国际音标书写复杂、机读性差等缺点,在俄语语音处理系统中,需要依据计算机可读的SAMPA符号设计俄语音素集,从而构建俄语发音词典并训练俄语声学模型。俄语音素集中应尽可能地包括俄语全部的音素,但如果音素集过大,单词注音结果的不确定性将会显著增加,大大提高解码过程的计算复杂度。若音素集太小,则会降低单词标音的精确度,影响语音处理系统的性能。为了体现俄语重音变化和元音弱化现象,本文对原始SAMPA俄语音素集进行了改进,设计了新的俄语音素集。
目前国际上俄语音素集的设计有多种方案。IPA俄语音素集共包含55个音素,分为38个辅音和17个元音,元音又分为11个重读元音和六个非重读元音,另外包括一个重音符号[13]。SAMPA俄语音素集共包含42个音素,分为36个辅音和六个元音,其元音音素没有重读与弱化之分,仅仅将弱化的元音[e]和[o]分别用[i]和[a]表示[14];卡内基梅隆大学(Carnegie Mellon University,CMU)设计的俄语音素集共包含50个音素和一个无音符号,分为36个辅音和14个元音,并将元音分为六个重读元音和八个非重读元音[16]。
通过对以上三个俄语音素集的研究,结合俄语音素的发音规则,重点对元音音素从一级弱化和二级弱化的角度进行区分,本文在原有俄语SAMPA音素集的基础上,增加了四个弱化后的元音和一个重音符号“!”,设计了共包含46个音素的俄语音素集。其中音素用SAMPA符号表示,包括36个辅音和10个元音,元音又细分为六个重读元音和四个非重读元音。新增的四个元音如表1所示。

表1 俄语弱化元音表
为了验证新音素集的有效性,本文从发音词典中随机抽取200个俄语单词,分别用原始SAMPA音素集和新音素集进行标音,交由俄语专家进行人工比对验证。验证结果证明,本文设计的新音素集能够清晰地标明俄语单词的重音位置,有效地区分元音一级弱化和二级弱化后的读音,相较于原始的SAMPA音素集标音更加准确,可读性更强。表2是改进的音素集与原始音素集标音的对比示例。
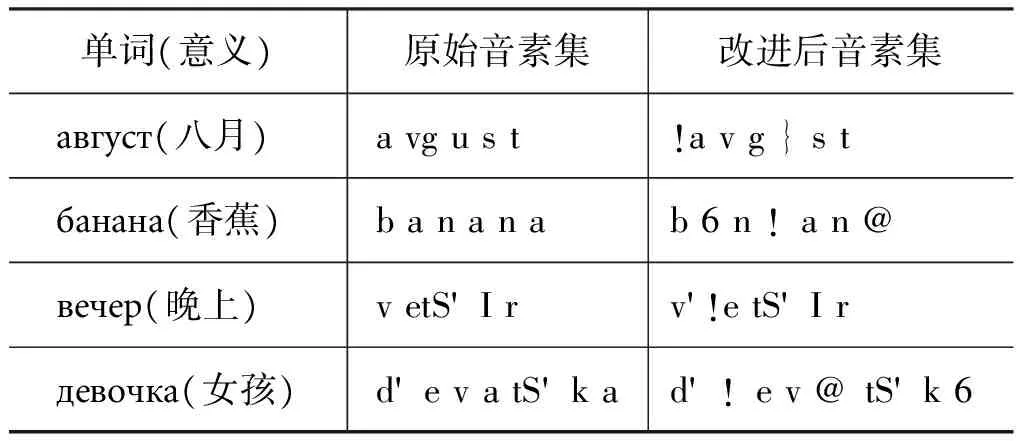
表2 音素集标音对比示例
2 加权有限状态转化器概述
加权有限状态转化器是一种基于半环代数理论的静态网络解码器,近年来被广泛应用于语音识别研究。语音识别系统涉及的HMM模型、发音词典、语言模型等,都可以转化为WFST模型的形式实现快速解码。WFST解码器具有实现简单、解码速度快的特点,对于知识源有统一的建模方式,具有完善的理论框架和成熟的优化算法,能够有效减少存储空间,提高系统的性能。
WFST可表示为定义在半环K上的八元组:T=(A,B,Q,I,F,E,λ,ρ)。其中,A表示输入符号集;B表示输出符号集;Q为有限状态集合;I⊆Q与F⊆Q,分别表示初始状态和终止状态子集;ε为空符号,E⊆Q×(A∪{ε})×(B∪{ε})×K×Q,表示状态转移集合,描述了WFST从某一状态接受输入后输出的符号与权重,并转移到下一状态;λ为初始状态权重对齐:I→K;ρ为终止状态权重对齐:F→K。WFST的权重为半环(K,⨁,⊗,0,1),通过二元函数⨁、⊗对权重进行操作,常用的半环有Log半环和 Tropical半环[15]。
WFST的解码网络是一个有向有环图,一个节点表示一个状态,由一个状态到下一个状态的有向弧描述了状态间的转移过程、符号间的映射关系以及转移的权重。以序列abc到序列абв的转移过程为例,WFST有向图如图1所示。

图1 WFST有向图示例
WFST解码过程中常用的算法有:合成(composition)算法、空转移消除(epsilon removal)算法、确定化(determinization)算法、最小化(minimization)算法等。
3 俄语字素、音素对齐方法
建立字素与音素的对齐是训练发音模型的第一步,一般的对齐方法是以“一对一”的方式进行对齐[9]。通过对俄语语音学的研究,本文使用基于期望最大化的“多对多”对齐方式解决俄语字音对齐问题。
3.1 多对多对齐
单词发音中经常出现字素序列和音素序列长度不一致的情况,有时多个字素对应一个音素,有时一个字素能够产生多个音素。通过研究俄语单词发音规律发现,大多数俄语字母与音素间以一对一的形式对应,但也存在以下两种例外:
(1) 一个字母对应两个音素,如ю—[j u]。
(2) 两个字母对应一个音素。这种情况主要由辅音字母与无音符号组合造成,如сь—[s’]。
以“юность(青年)”为例,一一对齐的结果如下:

ю⁃ность|||||||j!un@st'⁃
可以看出,音素“!u”和字母“ь”都产生了“空对齐”的情况。传统的用于解决这种问题的方法从本质上可以概括为:通过改变原有字母表或音素集,人工创造新的一一对齐。具体方案可分情况描述:
(1) 一个字母对应多个音素的情况有两种解决方法:一是在单词序列中加入“空”字母,对应空缺的音素;二是定义新音素,将多个音素组合后的整体视为一个音素。
(2) 与多个字母对应一个音素的解决方法类似,可以引入空音素,对应不发音的字母;或是将多个字母组合为一个新字素,对应一个发音。
以上方法从根本上讲仍然是一对一的对齐,只是从形式上达到了对齐的目的,并没有为每个字素找到其真正对应的发音,而且对原有字母表和音素集的修改,会改变语言的基本规则,由此造成发音模型的混乱。
为了避免一一对齐造成的局限性,文献[5]提出了基于期望最大化算法的“多对多”对齐方法。经实验验证,该方法相较于“一对一”的方法能够显著提高标音准确率, 在之后的文献中,也多次引用这一方法[6,11-12]。本文将这一方法应用于俄语字素、音素对齐问题,在维持原有字母表和音素集不变的情况下,避免了“一对一”方式造成的“空对齐”现象。该方法通过对所有对齐组合建立词图(Lattice),在WFST框架的支持下,利用期望最大化算法,可以准确地为每个字素找到其对应的发音。
仍以“юность”为例,多对多对齐的结果如下:

юность|||||j!un@st’
可以看出,对齐结果中没有产生“空对齐”的情况,“ю”和“ть”的发音对齐准确。
3.2 期望最大化算法
当给定样本中存在隐变量或缺失数据时,可以利用期望最大化算法求解模型参数的最大似然估计,实现概率建模。该问题的隐变量即可能的对齐结果。期望最大化算法分为两步,第一步是期望计算(expectation)过程,第二步是求解最大化(maximization)的过程,算法的整体流程如图2所示。
图2中,x、y分别表示当前输入的单词和发音序列;T、V分别表示x、y序列的长度;maxX和maxY为可赋值变量,分别表示x、y中子序列的最大长度,即字母和音素在对齐时的最多组合数,对于俄语来说,maxX和maxY的值都为2;γ为当前对齐结果的期望。
EM算法首先遍历单词和发音的每一个子序列xt、yv,根据每一个对齐组合生成有限状态接收机(FSA)词图,然后计算所有对齐的期望值,最后得出使期望最大化的对齐结果。
期望计算的算法利用WFST的相关操作实现。算法流程如下[12]:

算法:期望计算过程输入:AlignedLattices输出:γ1 foreachFSAalignmentlatticeFdo2 α←ShortestDistance(F)3 β←ShortestDistance(FR)4 foreach stateq∈Q[F] do5 foreach arce∈E[q]do6 v=((α[q]⊗w[e])⊗β[n[e]])β[0]7 γ[i[e]]⊕=v
算法的输入为FSA表示的对齐词图。首先为每条弧初始化一个权重w[e],通过WFST最短路径算法得到正向概率α和反向概率β;之后遍历每一个节点及节点上的每条弧,根据第6行的二元运算⊗计算每条弧的后验概率v,n[e]为下一节点状态;i[e]为当前输入符号,算法最后根据概率v更新当前的对齐的期望γ[i[e]]。
求解最大化的过程以期望γ为输入,经过多次迭代重新估计分布参数,得到每个对齐结果新的估计值γnew。 利用γnew更新词图中每条弧的权值,得出使期望实现最大化的路径和对齐结果。
以“юный(年轻的)”的第6格形式юном [j !u n @ m]为例,初始化的FSA模型如图3所示。

图3 初始化对齐FSA模型
图3中,每条路径上的字母音素组合为通往下一状态的对齐方式,每个节点表示当前已对齐的序列状态。0节点为初始状态,8节点为终止状态。每个节点已对齐的序列状态如表3所示。经过期望最大化算法计算,得出最终的路径为:0—1—4—5—8。

表3 节点状态表
4 联合N-gram发音模型
发音模型的构建利用N-gram语言模型对联合的字素、音素序列进行训练,得到音素序列出现的概率参数。再将N-gram模型转换为加权有限状态转化器,构成解码器的搜索空间。
N-gram语言模型是自然语言处理中被广泛应用的统计语言模型,在基于统计的语音识别、机器翻译、汉语分词等应用上都取得了成功。这种模型构建简单、灵活,尤其适用于序列型数据。因此,使用N-gram模型可以类似地为联合字音音素序列建立发音模型。
基于联合N-gram模型的计算原理为:对于一个俄语单词w,假设其对齐后的字素序列为γ(w)=g1g2…gn,音素序列为(w)=p1p2…pn,gi、pi(i=1,2,…,n)是第i个子序列,则联合概率可以表示为P(γ(w),(w))。设A为字素和音素所有可能的组合,每个组合可以表示为a=
基于联合N-gram算法和WFST框架的发音模型建立过程如下:
(1) 将对齐后的两个序列(g1,g2,…,gn)和(p1,p2,…,pn)合并为一个联合的对齐序列(g1:p1,g2:p2,…,gn:pn)。例如:
год |g !o t→г:g о:!o д:t
хорошо | x @ r 6 S !o→х:x о:@ р:r о:6 ш:S о:!o
(2) 采用联合N-gram模型算法对步骤(1)产生的联合序列结果进行训练。本文利用MIT语言模型(MITLM)工具包[17],设定N=8,采用Kneser-Ney平滑方法,得到了以ARPA格式存储的uni-gram至8-gram语言模型。
(3) 利用OpenFst开源库的支持[18-19],将联合N-gram模型转化为加权有限状态转换器。转化时,语言模型中对齐的字素和音素被重新分开,分别作为WFST的输入和输出符号,对应的概率作为路径的权值,转化后的WFST即发音模型的转换器。以字母序列абa[6 b a]为例,其WFST发音模型如图4所示。

图4 WFST发音模型示例图
5 发音预测
发音预测的过程首先将输入单词表示为FSA模型,然后将FSA与WFST发音模型合成,最后对合成后的WFST进行优化,通过最短路径算法找出最终的音素序列,可以用公式表示为:
(3)
在式(3)中,Hbest表示权重最高的发音预测序列,W表示输入单词 的FSA模 型,M表 示 由 联 合N-gram模型转化生成的WFST发音模型。其中,compose表示WFST的合成算法,合成算法将输入的FSA和WFST发音模型序列串联生成单一的WFST;projoutput表示输出符号映射运算,使生成的WFST保持与原WFST序列相同的输入输出映射关系;opt表示WFST的优化,包括确定化、空转移消除等操作;ShortestPath表示从WFST中检索最短路径的运算。最终的最短路径就是预测出的单词最优发音。
基于WFST的俄语字音转换方法,模型训练与测试流程如图5所示。

图5 基于WFST的俄语字音转换、测试方法流程图
6 实验测试
本文的原始语料主要来源于维基百科、CMU资源库及一些开源的俄语语料库,我们将原始样例的音素集映射到本文设计的基于SAMPA的俄语音素集,在映射过程中没有出现错误。通过对语料的归整,最终形成了包含20 000词条样例的俄语发音词典。
常用于衡量字音转换的评测指标分别是音素正确率和词形正确率,其计算公式如下:
音素正确率=正确转换的音素数/音素总数
词形正确率=正确标音的单词数/单词总数
本文对发音词典中的20 000个词进行了10轮交叉验证,每次选取90%为训练数据,10%为测试数据,结果如表4所示。

表4 测试结果表
从测试结果可以看出,本文的俄语字音转换算法在实验中取得了较好的效果,能够有效地应用于俄语发音词典构建。
7 结语
本文采用一种数据驱动的俄语字音转换方法,该方法以WFST为框架,基于期望最大化算法实现了俄语字素、音素的“多对多”对齐,并通过联合N-gram模型建立发音模型,利用WFST最短路径算法进行模型解码。另外设计了基于SAMPA的俄语音素集,在原音素集的基础上增加了重音符号及4个弱化元音,基于此音素集构建了包含20 000个词的俄语发音词典。在交叉验证中,平均词形正确率达到了62.9%,平均音素正确率达到了92.2%。
本研究表明,G2P技术能够为俄语语音合成和语音识别系统研制提供支持。在下一步工作中,我们将进一步扩充俄语发音词典的规模,探索用于解决G2P问题的机器学习算法,为提升俄语字音转换的正确率寻绎新途径。
[1]Karpov A,Markov K,Kipyatkova I,et al.Large vocabulary Russian speech recognition using syntactico-statistical language modeling[J].Speech Communication,2014,56(1):213-228.
[2]Kipyatkova I,Karpov A,Verkhodanova V,et al.Analysis of long-distance word dependencies and pronunciation variability at conversational Russian speech recognition[J].Computer Science and Information Systems,2012,11(6):719-725.
[3]Karpov A,Kipyatkova I,Ronzhin A.Very large vocabulary ASR for spoken Russian with syntactic and morphemic analysis[C]//Proceedings of Italy:INTERSPEECH 2011,Conference of the International Speech Communication Association,2011:3161-3164.
[4]Galescu L,Allen J F.Bi-directional conversion between graphemes and phonemes using a joint N-gram model[C]//Scotland:Proceedings ISCA Tutorial on TTS,2001.
[5]Jiampojamarn S,Kondrak G,Sherif T.Applying many-to-many alignments and hidden Markov models to Letter-to-phoneme conversion[C]//Proceedings of HLT-NAACL,2007:372-379.
[6]Bisani M,Ney H.Joint-sequence models for grapheme-to-phoneme conversion[J].Speech Communication,2008,50(5):434-451.
[7]Rao K,Peng F,Sak H,et al.Grapheme-to-phoneme conversion using long short-term memory recurrent neural networks[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing.IEEE,2015:4225-4229.
[8]王永生,柴佩琪,宣国荣.英语语音合成中基于DFGA的字音转换算法[J].计算机工程与应用,2006(13):158-161,190.
[9]李鹏,徐波.单词自动注音方法的研究[J].清华大学学报(自然科学版),2008(S1):735-740.
[10]赵坤,梁维谦,刘润生.面向字音转换的有条件维数扩展算法[J].清华大学学报(自然科学版),2008(10):1629-1631.
[11]Yang D,Dixon P R,Furui S.Rapid development of a grapheme-to-phoneme system based on weighted finite state transducer(WFST)framework[C]//Proceedings of ASJ Autumn Meeting,2009:111-112.
[12]Novak J R,Minematsu N,Hirose K.WFST-based grapheme-to-phoneme conversion:Open source tools for alignment,model-building and decoding[C]//Proceedings of FSMNLP,2012:45-49.
[13]Wikipedia.IPA symbol for Russian pronunciations [EB/OL].https://en.wikipedia.org/wiki/Help:IPA_for_Russian,2017-10-13/2017-10-17.
[14]Wells J C.SAMPA - computer readable phonetic alphabet[EB/OL].http://www.phon.ucl.ac.uk/home/sampa/,2005-10-25/2017-10-17.
[15]Mohri M,Pereira F,Riley M.Speech recognition with weighted finite-state transducers[M].Springer,Berlin Heidelberg,2008.
[16]Otander J.CMU Sphinx [EB/OL].https://cmusphinx.github.io/wiki/download/,2017-04-26/2017-10-17.
[17]Lehn M.,MIT Language Modeling Toolkit,https://github.com/mit-nlp/mitlm,2008-01-01/2017-10-18.
[18]Gorman K,OpenFst Library,http://www.openfst.org/twiki/bin/view/FST/WebHome,2017-07-05/2017-10-18.
[19]Allauzen C,Riley M,Schalkwyk J,et al.OpenFst:A general and efficient weighted finite-state transducer library[C]//Proceedings of International Conference on Implementation and Application of Automata.Springer-Verlag,2007:11-23.
[20]Povey D,Hannemann M,Boulianne G,et al.Generating exact lattices in the WFST framework[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing.IEEE,2012:4213-4216.
[21]Novak J R,Dixon P R,Minematsu N,et al.Improving WFST-based G2P Conversion with AlignmentConstraints and RNNLM N-best Rescoring[J].Booklist,2013.
[22]信德麟,张会森,华劭.《俄语语法》(第二版)[M].北京:外语教学与研究出版社,2009.
[23]Ронжин А.,Карпов А.,Лобанов Б.,Et al.Фонетико-морфологическая разметка речевых корпусов для распознавания и синтеза русской речи[J].Информационно-управляющие системы,2006,(6):24-35.
[24]Важенина Д.А.,Кипяткова И.С.,Марков К.П.,et al.Методика выбора фонемного набора для автоматического распознавания русской речи[J].Труды СПИИРАН,2014,5(36):92-113.

冯伟(1993—),硕士研究生,主要研究领域为自然语言处理。E-mail:303203093@qq.com

易绵竹(1964—),通信作者,教授,博士生导师,主要研究领域为计算语言学、语言信息处理。E-mail:mianzhuyi@gmail.com

马延周(1977—),博士,主要研究领域为计算语言学和语言信息处理。E-mail:myz827@126.com
