一种基于用户属性和网站类型聚类的协同过滤推荐算法
2018-04-13高天迎张志钢李国燕陈亚东
高天迎,张志钢,李国燕,陈亚东
(天津城建大学 a.计算机与信息工程学院;b.信息化建设管理中心,天津 300384)
Web2.0与移动互联网的高速发展使得Web站点的数量迅速增加,搜索引擎成为快速找到目标网站与信息的有效途径.然而在某些情况下,用户需求很难用简单的关键词表述.相对于搜索引擎的局限性,推荐系统通过分析用户的兴趣爱好,进行个性化推荐,在一定程度上弥补了搜索引擎的不足.目前,高校校园网已经实行了实名认证,校园网的网络服务器中存在大量的实名Web Log数据.应用相关的聚类和推荐算法,对校园网Web Log数据进行分析计算,可以为校园网用户提供更加个性化的网站推荐服务,减少数据资源的浪费.
目前,经典的推荐策略主要包括基于内容的推荐、协同过滤推荐、基于模型的推荐、基于网络结构的推荐和组合推荐等[1-7].其中,协同过滤推荐在很多大型电子商务网站得到广泛应用.协同过滤推荐算法善于发现用户新的兴趣点,不需要专业知识即可进行推荐,推荐质量取决于历史数据集[8-12].然而,协同过滤算法以其他用户对项目的评价来预测目标用户对项目的喜好,忽略了用户和项目的属性信息,准确率不高;通过遍历所有用户去寻找最近邻,实时性不高;对用户评分矩阵的稀疏性敏感,当矩阵稀疏性较高时,算法准确率急剧下降[10,13].Sebastiani等[14]提出了基于贝叶斯网络模型的推荐方法,该方法的性能和精度都不错,但模型训练的代价太大,不适用于数据更新频繁的系统;Sarwar等[10]提出了基于近邻资源项的协同过滤算法,认为系统中的用户数目一般远大于资源数目,且资源的变化较小,从而预先建立资源项的近邻模型,以提高预测时的性能.
Rashid等[15]利用聚类技术,通过将相似的对象聚合成组,计算组内对象的相似度,可以提高算法实时性,降低数据稀疏性的影响;Adomavicius等[16]提出了一种个性化服务中基于用户聚类的协同过滤推荐算法,通过用户评分的相似性对用户聚类,根据聚类中的项目评价生成对应的聚类中心.该算法在一定程度上提高了推荐质量,但在用户评价数据高维稀疏性的情况下,该方法的可靠性不高;曾春等[17]提出了对所有资源进行分类,将用户对每项资源的打分转换为用户对某个资源类别的平均打分.这种方法降低了数据稀疏性,但相似度计算不准确.
笔者选取30天服务器WebLog文件作为研究的基础数据,提出了一种基于用户属性和网站类型聚类的协同过滤推荐算法(user website collaborative filtering,简称UWCF).通过将聚类分析与协同过滤推荐算法相结合,利用用户-网站类型评分矩阵聚类有共同兴趣特征的用户,将用户-网站评分矩阵转化为用户-网站类型评分矩阵,检索到当前用户的最近邻居用户集,降低冷启动和矩阵稀疏性的影响,同时降低网站推荐的时间和空间复杂度,为校园网用户进行网站推荐服务.最后,通过具体的实验数据与基于网站评分聚类的协同过滤算法(website rating collaborative filtering,简称WRCF)对比,验证本文算法的有效性.
1 研究方法
1.1 Web Log数据获取
服务器日志文件主要分两种:Web Log日志和session日志.这些文件中包含了大量的用户访问信息,如用户的IP、用户的访问时间、浏览过页面的URL、请求方法(GET或POST)等.本文使用的Web Log文件来源于笔者所在学校的校园网服务器,选取服务器上30天的Web Log文件作为数据源.表1列出了本文使用的Web Log日志记录中的主要信息.
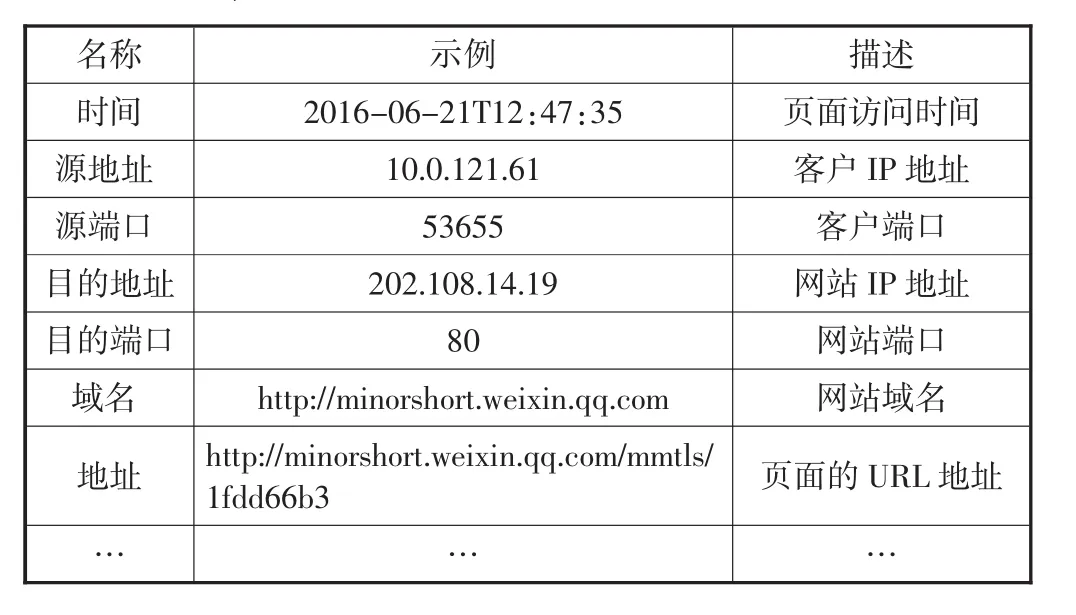
表1 Web Log文件主要信息
在将Web Log信息进行预处理基础上,对其进行分析挖掘,可以发现用户感兴趣的Web站点与用户上网行为偏好,结合相应的个性化推荐算法,可以对不同的用户进行个性化的网站推荐.因此,首先要对Web Log信息进行数据清洗与聚类分析.
1.2 数据预处理
由于本地缓存、代理服务器和防火墙的存在,使得直接在Web Log数据上进行分析变得十分困难和不准确.在实施数据分析之前,需要对Web Log文件进行数据预处理,将原始的Web Log数据转换成适合进行分析处理的可靠数据.本文的研究目的是为不同用户提供个性化的网站推荐信息,所以对原始的日志数据进行的预处理主要包括:
(1)删除与Web Log日志分析无关的记录.在数据清理时,通过检查域名和URL的后缀名,删除认为不相关的文件.
(2)删除错误的访问记录.当服务器对用户发出的请求响应失败时,Web Log同样会记录,但这对Web日志分析没有意义.所以在进行数据清理的时候,通过日志中的状态码删除服务器对请求响应失败的记录.
(3)合并同一用户同一域名不同URL的记录,对记录条数进行累加,记为用户访问同一站点的次数.
1.3 数据分类
协同过滤算法一般基于用户-项目评分矩阵进行项目推荐.本文的研究目标为网站推荐,需要基于经过预处理的Web Log数据构建用户-网站评分矩阵,矩阵的值可以设置为网站的访问次数.然而,由于网站数量巨大,而每个用户能够访问的网站数量有限,因此构建出的用户-网站评分矩阵必然是稀疏的.
相对于海量的网站数量,网站类型相对固定,本文参考hao.qq.com、www.hao123.com和https://hao.360.cn等网站的分类方法,建立网站类型表,并据此对Web Log文件中的网站进行类型标记,所构造的主要网站类型信息如表2所示.
基于网站类型信息,可以构建网站-类型矩阵,进而生成用户-网站类型评分矩阵,替代用户-网站评分矩阵.在进行聚类的过程中,一定程度上解决了网站访问数量巨大和评分矩阵数据稀疏的问题.同时,实名认证用户进入校园网时,需要提供相应的用户信息,如身份证号、学号等.因此,可以构建用户-属性矩阵,将用户性别、用户专业和年级信息融入用户相似度计算.本文选用的用户属性性别、专业、年级分别对应编号 1、2、3.
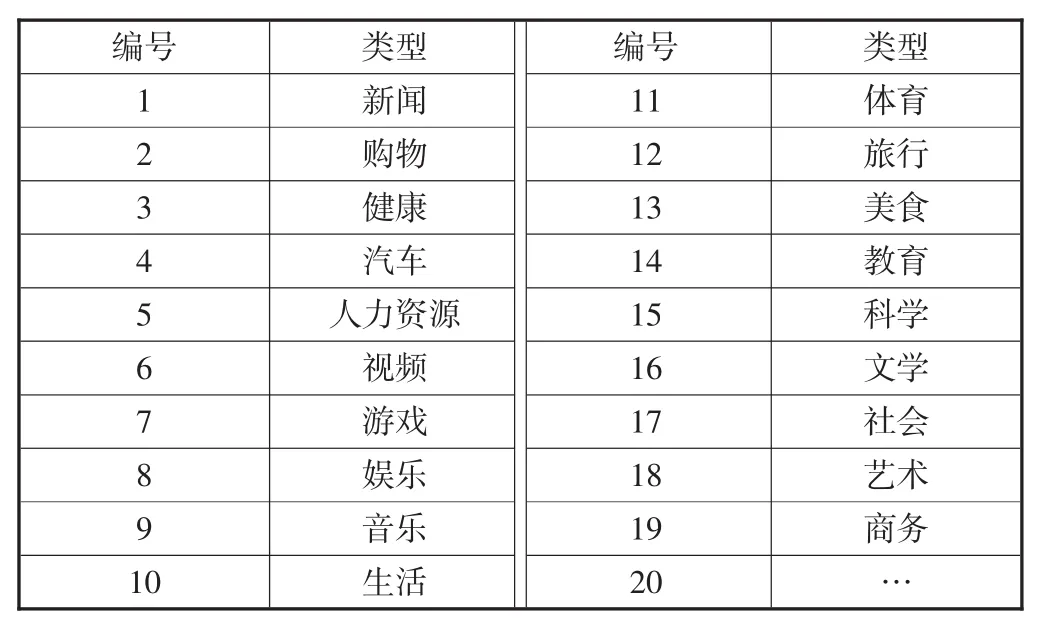
表2 网站类型
2 算法描述
2.1 基本思想
基于用户-网站评分矩阵的聚类推荐算法,计算量大,时间成本高,精度低.本算法基于用户-网站类型评分矩阵对用户聚类,算法基本流程如图1所示.算法主要步骤:①生成用户-网站类型评分矩阵,用户-网站类型评分矩阵聚类;②结合用户属性寻找目标用户近邻;③根据目标用户近邻计算产生推荐结果.
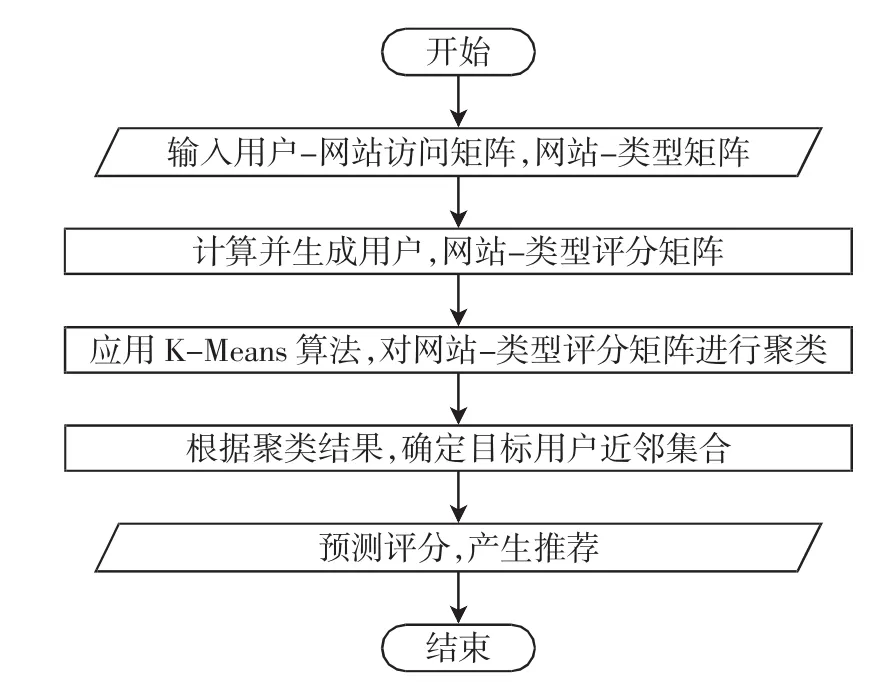
图1 算法主要流程
2.1.1 用户-网站类型评分矩阵
根据表2中的网站分类信息生成网站-类型矩阵,如表3所示.其中:T1表示新闻;T2表示购物;T3表示健康;W1、W2、W3分别表示3个不同的网站.一个网站属于某种类型,则矩阵取值为1,否则为0,一个网站可以同时具有多种类型.
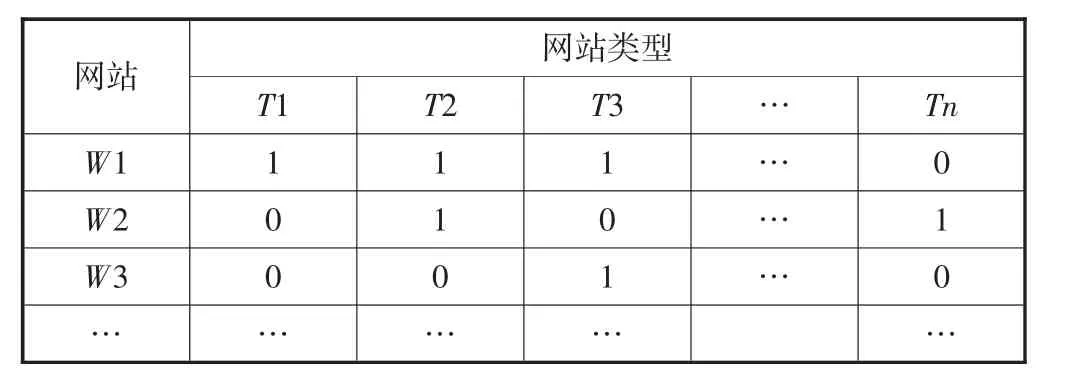
表3 网站-网站类型矩阵
根据Web Log文件中的用户访问信息,可以构建用户-网站评分矩阵,如表4所示.其中:W1、W2、W3分别表示3个不同的网站;U1、U2、U3分别表示3个不同的用户;矩阵取值为网站访问次数.
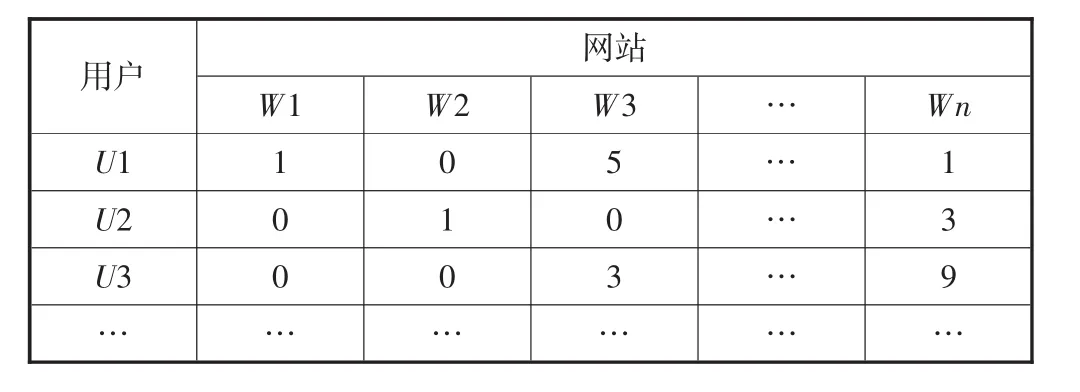
表4 用户-网站评分矩阵
基于网站-类型矩阵和用户-网站评分矩阵,可以计算用户对不同网站类型的兴趣度,并进一步构造出用户-网站类型评分矩阵,如表5所示.其中:U1、U2、U3分别表示3个不同的用户;T1、T2、T3分别表示3个不同的网站类型;矩阵取值为网站类型的评分.
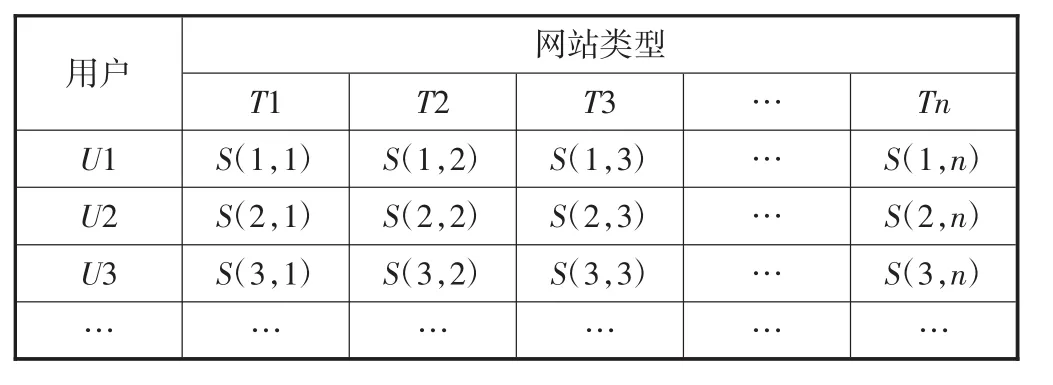
表5 用户-网站类型评分矩阵
借鉴词频-逆文档频率(TF-IDF)概念,用户u对网站类型 t的评分 S(u,t)定义为
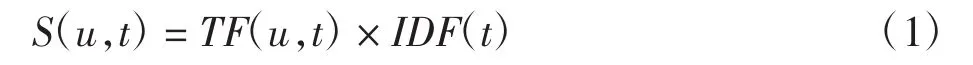
其中

式中:N为网站类型的个数;n为网站的个数;Nut为用户u访问的所有网站包含的类型t的总数目为用户u访问的所有网站包含的类型的总数目;nt为系统中包含类型t的网站数目;TF(u,t)为用户u访问的网站中含有类型t的数目占用户u访问的网站集合中含有的类型总和的比值,比值越高,则用户u对网站t越感兴趣;IDF(t)是根据网站类型在所有网站的分布情况,对用户u对网站类型t的兴趣进行调权.
2.1.2 目标用户近邻
基于用户-网站类型评分矩阵的用户相似度计算,只考虑用户对网站类型的兴趣度,不考虑用户的属性特征;而基于用户-属性矩阵的用户相似度计算,则只考虑用户属性的相似性,而不考虑用户对网站类型的兴趣.因此,采用单一方法在计算用户间相似度时,存在相应的缺陷,从而影响推荐精度.本文通过对两种相似度计算方法进行加权融合来提高推荐精度.
根据前述的用户属性和校园网用户注册信息,可以构造用户-属性矩阵,如表6所示.性别男取值0,性别女取值1.按照校园网注册用户的不同专业取值1-77;年级取值1-8,分别为本科生1-5,硕士研究生6-8.
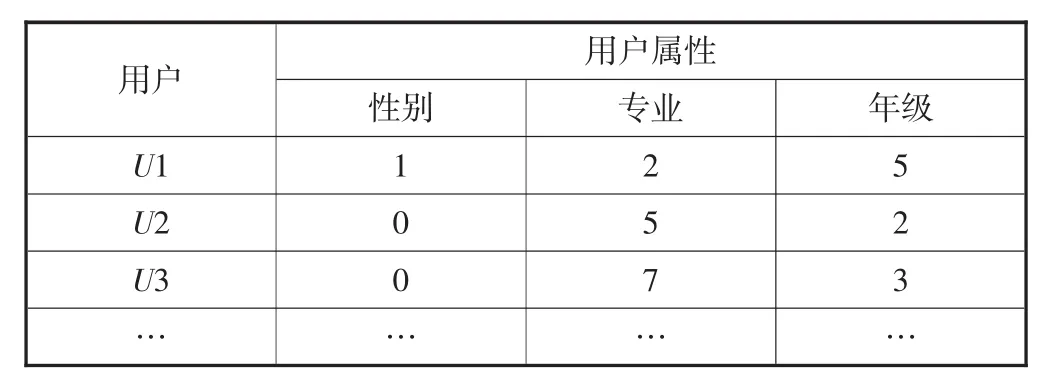
表6 用户-属性矩阵
设用户i和j通过用户-网站类型评分矩阵计算得到的相似度为 Sim(i,j)wt,通过用户-属性矩阵计算得到的相似度为 Sim(i,j)ua,融合后的相似度计算公式为
、
其中,λ为调权参数,针对不同的数据集,通过实验的方法可以得到其最优值.Sim(i,j)wt采用修正的余弦相似度计算,公式为
Sim(i,j)ua计算公式为
式中:Iij为用户i和用户j共同评分的网站类型集合;Ii、Ij分别为用户i和用户j评分的网站类型集合;Ri,c为用户 i对网站类型 c 的评分;i为用户 i评分的平均值;Gender(i,j)为用户i和用户j的性别相似度,若 i.gender=j.gender,则 Gender(i,j)=1,否则Gender(i,j)=0;Major(i,j)为用户 i和用户 j的专业相似度,若 i.major=j.major,则 Major(i,j)=1,否则Major(i,j)=0;Grade(i,j)为用户i和用户j的年级相似度,若|i.grade-j.grade|≤1,则Grade(i,j)=1,否则Grade(i,j)=0;α、β 分别为性别特征、年龄特征所占权重,可根据具体情况,结合传统协同过滤算法,经反复实验可获得适当的权重.
2.1.3 推荐结果
同一聚类内的成员之间具有较高的相似性,可以利用融合后的用户相似性计算公式计算用户的相似性,从而确定目标用户近邻集合.选取前K个预测评分最高的用户,进而对网站进行预测评分,前N个预测评分最高的网站即为推荐结果.
设用户u所属用户聚类为Cu,可以通过计算用户u与Cu中所有其他用户间的相似值来预测评分.为了进一步提升网站推荐的准确度,本文只计算Cu中对网站w进行评分的用户间的相似性.对于用户u,设其需要进行预测的网站集合用Wu表示,用户u对Wu中未评分网站i的预测评分Pu,i可以通过所有邻居用户对网站i评分的加权平均值获得.Pu,i的计算方法为
式中:Sim(u,j)为目标用户与最近邻居的相似度;R¯u、分别为用户u和用户j对网站评分的平均值.根据用户对所有网站的预测评分,按照评分由大到小排列,选取其中评分最高的N个网站即可.
2.2 算法流程
步骤1:生成用户-网站类型评分矩阵.
输入:网站-类型矩阵WTmh,用户-网站评分矩阵UWnm
输出:用户-网站类型评分矩阵UTnh
初始化:用n维向量表示用户u,用k维向量表示网站w

end foreach
return用户-网站类型评分矩阵
步骤2:基于用户-网站类型评分矩阵的用户聚类.每个用户用一个N(网站类型个数)维向量u表示,在用户-网站类型评分矩阵上的聚类过程如下:
输入:用户-网站类型评分矩阵UTnh,聚类个数k输出:k个簇C和k个聚类中心CC
初始化:从用户集合U中随机选择k个用户向量作为初始聚类中心,记为集合

计算u与聚类中心CCi的相似度Sim(u,CCi)

计算簇cc所有用户向量空间上的均值,更新聚类中心cc
end foreach
until每个聚类中心不再变化
步骤3:寻找近邻,产生推荐.
输入:目标用户u,近邻个数K,k个聚类中心CC,k个簇C
输出:目标用户Top K近邻集合
foreach Cluster Center cc∈CC
结合用户-属性矩阵,计算目标用户与各个簇中心相似度 Sim(u,cc)
/*按照用户与各簇中心相似度降序排列*/

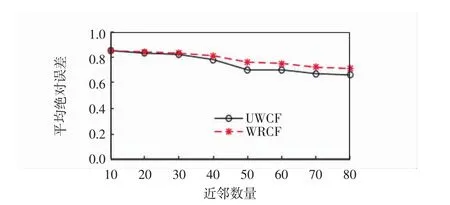
图2 两种推荐算法的性能对比
结合用户-属性矩阵,计算目标用户与其他用户间相似度Sim(u,ut)

return目标用户的Top K个近邻
3 实验结果
笔者选用所在学校网络服务器的Web Log日志文件作为实验基础数据,选取30天的日志记录,经过预处理后得到实验数据集.本实验的数据集包含校园网用户16 255个,Web Log记录约1.6亿条,其中网站的数量接近11万个,网站类型如表2所示.进行反复试验,确定计算公式中权重估计值:λ=0.6,α=0.5,β=0.3.
采用平均绝对误差(mean absolute error,简称MAE)指标度量预测准确度,将UWCF算法与WRCF算法进行对比.实验中最近邻居数从10增加到80,间隔为10,聚类k取值为150,实验获取的数据见表7.
图2为UWCF算法与WRCF算法的平均绝对误差的推荐性能比较.WRCF算法同样采用K-Means算法对用户进行聚类.与UWCF算法不同,WRCF算法基于用户-网站评分矩阵(见表4)对用户进行聚类分析,计算用户相似度,并预测用户对目标网站的偏好,不考虑用户属性和网站类型信息.由图2可以看出,当近邻数量在10~30之间时,两种算法预测准确度非常相近;随着近邻数量的增加,UWCF算法的平均绝对误差较传统的WRCF算法有一定的降低,相应的推荐精度有了一定的提高.
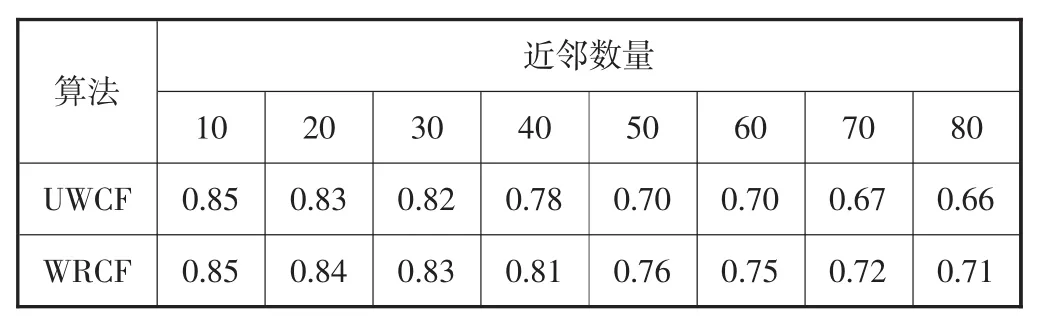
表7 实验数据对比
4 结语
随着网络日志数据量、用户数量和数据需求等的不断增加,网络日志分析变得越来越有价值.本文针对传统的协同过滤推荐算法面临的数据集稀疏性和冷启动问题,提出了基于用户属性和网站类型聚类的协同过滤推荐算法,利用不同用户对于不同类型网站的喜爱程度,构造用户-网站类型评分矩阵,降低数据集的稀疏性,然后结合用户-属性矩阵,寻找近邻用户,为目标用户推荐个性化的网站.实验结果表明,该算法可以有效地降低数据集的稀疏性和系统的开销,一定程度缓解了数据冷启动问题,提高了网站推荐的准确性.
参考文献:
[1]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[2]WU Yan,SHEN Jie,GU Tianzhu,et al.Algorithm for sparse problem in collaborative filtering[J].Application Research of Computers,2007,24(6):94-97.
[3]许海玲,吴 潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[4]PAVLOV D Y,PENNOCK D M.A maximum entropy approach to collaborative filtering in dynamic,sparse,high-dimensional domains[C]//BECKERS,THRUNS,OBERMAYERK.Proceedings of the 15th Annual Conference on Neural Information Processing Systems(NIPS’02).Vancouver:MIT Press Cambridge,2002:1 465-1 472.
[5]ZHOU T,REN J,MEDO M,et al.Bipartite network projection and personal recommendation[J].Phys Rev E,2007,76(2):70-80.
[6]ZHOU T,JING L L,SU R Q,et al.Effect of initial configuration on network-based recommendation[J].Europhysics Letters,2007,81(5):15-18.
[7]WANG Zhimei,YANG Fan.P2P recommendation algorithm based on hebbian consistency learning[J].Computer Engineering and Applications,2006,42(36):110-113.
[8]WANG Weiping,LIU Ying.Recommendation algorithm based on customer behavior locus[J].Computer Systems&Applications,2006,15(9):35-38.
[9]KIM B M,LI Q,PARK C S,et al.A new approach for combining content-based and collaborative filters[J].Journal of Intelligent Information System,2006,27(1):79-91.
[10]SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C]//New York Association for Computing Machinery.Proc of the 10th International Conference on World Wide Web.Hong Kong:New York Association for Computing Machinery,2001:285-295.
[11]YOU Wen,YE Shuisheng.A survey of collaborative filtering algorithm applied in E-commerce recommender system[J].Computer Technology and Development,2006,16(9):70-72.
[12]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1 621-1 628.
[13]DESHPANDE M,KARYPIS G.Item-based top-n recommendation algorithms[J].ACM Transaction on Information System,2004,22(1):143-177.
[14]SEBASTIANI P,RAMONI M,CREA A.Profiling your customers using bayesian networks[J].ACM Sigkdd Explorations Newsletter,2000,1(2):91-96.
[15]RASHID A M,LAM S K,LAPITZ A,et al.Towards a scalable kNN CF algorithm:exploring effective applications of clustering[C]//NASRAOUI O,SPILIOUPOULOU M,SRIVASTAVA J.Knowledge Discovery on the Web International Conference on Advances in Web Mining&Web Usage Analysis.Philadelphia:Springe,2006:147-166.
[16]ADOMAVICIUS G,TUZHILIN A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Trans on Knowledge and Data Engineering,2005,17(6):734-749.
[17]曾 春,邢春晓,周立柱.基于内容过滤的个性化搜索算法[J].软件学报,2003,14(5):999-1 004.
