PRETCO口试评分效度研究①
2018-04-09杨志强许吟雪
杨志强 许吟雪 全 冬
PRETCO口试评分效度研究①
杨志强 许吟雪 全 冬
(重庆科技学院外国语学院,重庆 401331)
采用多层面Rasch模型,通过分析PRETCO口试的评分结果以探究其评分效度。研究发现PRETCO口试评分效度较高,其评分结果能够有效区分考生的口语水平,评分员评分的自身一致性总体较好。研究同时发现PRETCO口试评分存在以下问题:评分员的宽严度差别显著,个别评分员的内部一致性较差;少数评分员和考生的交互作用存在显著差异;评分员和四项任务之间也出现了不同程度的偏差。
PRETCO;多层面Rasch模型;评分效度
高等学校英语应用能力考试(Practical English Test for College,简称PRETCO)是由PRETCO考试委员会设计的标准化考试,主要面向高职院校和成人高专院校的学生[1]。PRETCO口试(PRETCO-Oral)是PRETCO考试的组成部分,2005年开始试行。该考试为计算机辅助口语考试,报考对象不同于PRETCO考试,除了面向高等职业院校的学生外,还包括应用型高等院校的在校学生。由于PRETCO口试是主观性测试,其评分亦为主观行为,其间必然产生评分误差,影响测试的评分效度。为减少评分的主观性对考试整体效度的影响,本研究采用多层面Rasch模型(Multi-facets Rasch Model,以下简称MFRM),对PRETCO口语考试的评分进行研究,以期为该考试的评分或评分员的培训提供一些启示与建议。
一、研究背景
口语考试属于语言运用测试(Language Performance Assessment)[2],鉴于该类测试的主观题属性,评分需要人工完成,评分的质量对于语言运用测试而言极其重要[3]。国外基于多层面Rasch模型的语言测试研究主要是语言运用测试的评分研究(口语和写作测试评分)[4]。国内的相关研究处于起步阶段,内容涉及语用能力测试的评分[5]、CET和TEM-4作文/口语考试的评分信度[6]、评分员效应/偏差研究[7]和PRETCO口试评分标准的效度验证[8]等。使用多层面Rasch模型对语言运用测试的评分进行研究已得到广泛重视。但目前还没发现有关PRETCO口试评分效度的研究成果。为此,本研究拟采用多层面Rasch模型对PRETCO口试的评分结果进行分析,探讨其评分效度。
二、研究方法
(一)数据来源
PRETCO口试为计算机辅助口语测试,主要包括四个部分:朗读短文(Loud Reading)、提问—回答(Questions & Answers)、汉译英(Chinese-English Interpretation)以及看图讲话(Presentation)。本研究分析的对象为重庆市某PRETCO口试阅卷点2015年12月的评分结果,共有1 455名考生参加这次考试。考试同时使用四套平行试题,即sheet1、sheet2、sheet3和sheet4,参考的考生人数分别为645名、466名、237名和107名。参加阅卷的评分员(R1-R20)共有20名,来自11所不同的高校,他们分别对考生进行双评。PRETCO口试的总分为16分,每项任务为4分,评分时采用七个分数段,分别为0分,1分,2分,2.5分,3分,3.5分和4分。鉴于FACETS分析数据时需使用整数,因此本研究将七个分数段转换成七个等级(1,2,3,4,5,6,7)。
(二)MFRM模型中的主要概念
本研究采用的MFRM模型包括四个层面:考生能力、评分员、试题以及口语考试的四项任务。因为PRETCO口试的四套题为平行试题,所以本研究对试题层面进行锚定(anchoring),以消除估算过程中的歧义。此外,由于PRETCO各项任务的评分标准有其自身的特点,所以需采用多层面Rasch模型中分部记分模型(Partial Credit Model)[9]。
多层面Rasch模型的分析主要涉及以下概念:
1.度量值(Measure):每个层面的个体在统一标尺上的数值,以洛基单位(logit)呈现,从而便于比较各层面中个体能力的差异;
2.拟合统计量(Fit statistics):表示个体的实际观察值与Rasch模型预测值的拟合程度,包括加权均方拟合统计量(Infit Mean Square)和未加权均方拟合统计量(Out Mean Square);
3.分隔系数(Separation)和分隔指数信度(Reliability):衡量个体之间存在显著性差异的程度;
4.偏差(Bias)分析:多层面Rasch模型可以用来预测实际分数偏离模型的情况,显著性偏差比例可接受的范围在5%左右。
三、分析与讨论
本研究基于FACETS(3.71.3)软件,利用MFRM模型对PRETCO的口语评分进行总体分析,并从考生、评分者、任务和评分偏差四个方面展开讨论。
(一)总体分析
由图1可以看出,第一列为度量值,其统一单位为logit,该图显示的最大值约为5logits,最小值为-6logits,总跨度约为11logits。第二列为考生能力值,依据考生的能力从大到小进行排列,排位越靠上,考生能力越强,位于同一行的考生能力相同;其中,一个“*”代表16名考生,而“.”表示少于16名考生。根据图1我们可以得出结论:考生的能力总体上呈正态分布,排位靠上的考生比排位靠下的考生具备更高的英语口语表达能力。

图1 总体层面图(囿于篇幅,本图有所调整)
第三列为评分员评分的度量值,该值不受考生能力和试题难度的影响,能够反映出评分员的宽严度。由于评分员的宽严度是负向的(图中第一行“-Raters”),所以评分员的度量值越大,其评分越低,即越严厉。从图1可以看出,评分员R4最严厉,R18最宽松。
第四列为锚定的四套题,难度值均为“0”logit。
第五列为任务的难度。同样,由于任务的难度是负向的(-Tasks),所以每项任务的度量值越大,则表明该任务的得分越低,即越难。由图1可知,第二部分任务Question & Answer的难度最大,第一部分任务Reading难度最小,两项任务的度量值之差约为2Logits,远小于考生能力量度的跨度。
最后四列为四项任务评分标准各个分数段的使用情况,图中分数段之间的短横线“---”表示相邻两个等级的临界能力值。
(二)各层面分析
第一,表1是考生层面的统计数据。能力最强的考生度量值为4.18logits,能力最弱的考生度量值为-6.82logits,两者相差较大,达到11logits。多层面Rasch模型规定,如果实际观察值与模型预测值完全拟合,其拟合统计量(InfitMnSq)的值为1。由表1可知,考生层面InfitMnSq的均值为1.02,这表明考生的能力基本与模型一致。表1同样显示,考生个体能力的分隔系数为2.71,分隔指数的信度为0.88,卡方值为9 641.6(d.f.=1 454, p=0.00<0.01)从统计的角度分析被试能力的差异具有显著意义。

表1 考生层面数据
多层面Rasch模型并没有严格规定拟合度(fit)的取值范围,这需要根据考试的性质和目的来确定。一些研究认为拟合度在0.5-1.5之间是可接受的范围,0.7-1.3之间为高度拟合。但是,也有研究将考生层面InfitMnsq取值范围定为0.5-3之间。本研究主要参考了FACETS说明书中拟合度的取值范围(表2)。其中,fit<0.5表示过度拟合(overfit),即评分员对考生的各项评分的差异小于模型的预期值;而fit>2则表示非拟合(Misfit),即评分员对考生的各项评分超出了模型的预期。本研究中非拟合的考生数量为114,这可能是由于不同的评分员对同一考生评分不一致而造成。但由于考生层面的非拟合不是主要问题,而且非拟合的考生总数仅占总数的7.8%,因此这并不影响此次评分的效度。
表2拟合度分布

拟合度取值考生数百分比 Overfit: fit<0.531121.3% Less Acceptable1.5≦fit≦215710.8% Acceptable0.5≦fit<1.587360.0% Misfit fit >2114 7.8%
第二,评分员层面的数据显示(见表3),评分员评分宽严度的分隔指数为8.05,分隔指数的信度为0.98,卡方值为1 330.2(d.f.=19),显著性p=.00<0.01,这表明评分员评分的宽严度存在统计学意义上的显著性差异。其中,最严厉的评分员(R4)度量值为0.63logits,最宽松的评分员(R18)度量值为-.76logits,两者相差1.39logits,只占考生能力跨度(11 logits)的1/8。这从一定程度上表明,总体上来说考官的严厉度差异对考生成绩的影响不大。
PRETCO口试的考试规模较大,风险较高,因此本研究对于评分员层面拟合度(InfitMnSq)的取值较为谨慎,采用0.7–1.3高度拟合的取值范围。如果InfitMnSq大于1.3logits,说明评分员自身评分的一致性较差;如果InfitMnSq小于0.7logits,则说明评分员的评分比较接近,差异较小,可能会导致集中趋势。所谓集中趋势是指评分员的评分比较趋中,评分员过多地使用中间分数段,这样无益于区分考生的能力。虽然过度拟合和非拟合都表明评分员对考生的评分出现一定程度的偏差,但通常情况下,非拟合的问题较过度拟合而言更加严重。由表3可知,评分员层面的拟合度总体较好,有一位评分员的拟合度大于1.3logits(R5,1.68logits),出现了非拟合现象,表明这位评分员未能很好地使用各个分数段,评分的前后一致性较差。原因可能是评分员R5第一次参加PRETCO口试的评分,缺乏评分经验。此外,该评分员还兼顾教学和行政工作,这也可能会影响其评分质量。对于这位评分员,需要进行针对性的培训,从而提高其评分的一致性。本次阅卷所有评分员的拟合度均大于0.7logits,总体不存在集中趋势。
第三,表4是任务层面的分析数据。我们可以看出四项任务中,“提问—回答”最难,度量值为0.96logits,其次是“看图讲话”和“汉译英”,度量值分别为0.28logits和–0.08logits,“朗读短文”最简单(–1.15logits)。四项任务的难度分隔系数为36.36,分隔指数信度为1.00,卡方值5 221.8(d.f.=3),显著性p=.00<0.01,这表明四部分任务的难度差异具有统计意义上的显著性。虽然如此,由于四项任务的难度差异仅为2.11logits,所以总体上不影响考生的成绩。由任务层面的拟合度可知(表4倒数第二列数据),“提问—回答”“看图讲话”“汉译英”以及“朗读短文”的拟合度总体较好,分别为1.22logits、0.86logits、0.88logits和1.06logits,均位于0.7–1.3之间,这说明评分员对PRETCO口试各项任务的评分一致性较好。
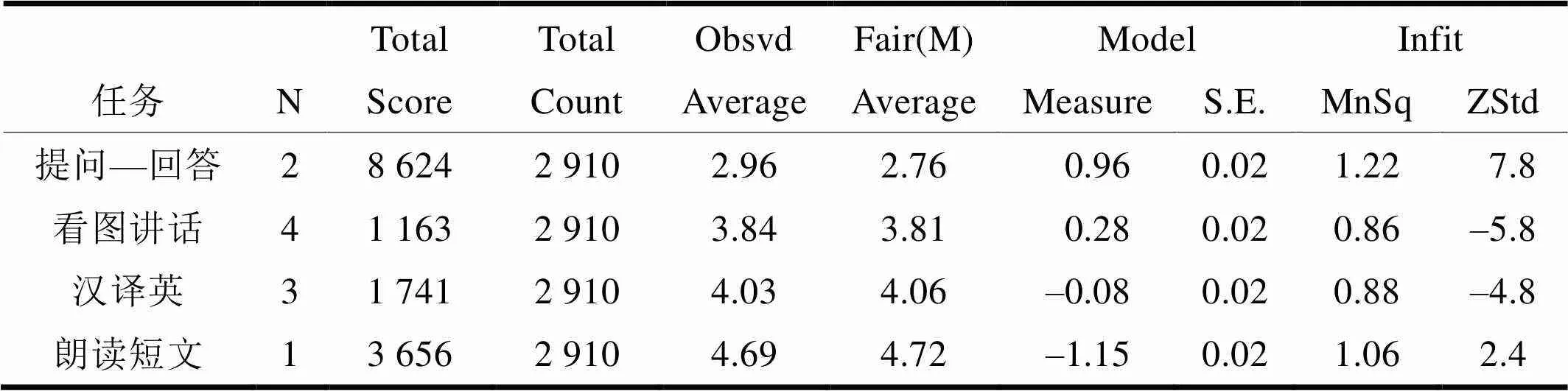
表4 任务层面

表5 四项任务各分数段评分分布统计
注:由于本次阅卷的数量较多,分数段使用不到10次的频率显示“0%”。
多层面Rasch模型对于评分标准各个分数段的使用情况有具体的要求。如果分数段的使用次数过低(低于10次),那么这个分数段有可能存在问题,需要采取一定措施,比如:改写其描述语,或者和相邻的分数段进行合并,甚至可以直接将该分数段删除。由表5可知,评分员使用了四项任务评分标准的所有分数段,但“陈述”任务分数段7的使用频次仅为8次,少于10次。该分数段的描述语要求考生除了能够用英语清楚、连贯地介绍题目中图画/图表所包含的信息外,还要对其进行评述,并做到英语表达符合规范。由于参加PRETCO口试的考生主要来自高职院校或应用技术型院校,“陈述”任务分数段7的描述语对此类考生的要求可能较高,多数考生的表现难以达到这个标准。当然,也有可能由于PRETCO口试评分培训时缺乏对该分数段的阐述,评分员的理解可能存在偏差,从而导致该分数段的使用次数过低。
(三)评分偏差
本研究对于评分误差分析主要通过Rasch模型中的偏差交互作用分析(bias interaction analysis)进行,如评分员与考生的偏差、评分员与各项任务的偏差等。本研究根据FACETS的分析结果,认为p<0.05为显著偏差。
一方面,本文通过MFRM对评分员和考生偏差分析。结果显示评分员与考生之间的交互作用出现显著偏差(详见表6,p<0.05),偏差的总数为14次。其中,评分员R1、R3、R13和R16分别出现两次偏差,评分员R4、R8、R9、R14、R15和R19分别出现一次偏差。以评分员R3为例,该评分员给考生s641的评分为24分(该分数为转化后的等级分数,下同),而MFRM模型的期望分数为17.06分,评分过于宽松;然而对考生s1350的评分却较为严厉,实际评分为9分,MFRM模型的期望分数为17.37分。

表6 评分员与考生偏差分析
由于本次阅卷的总量较大,而且实行双评,所以14次的显著性偏差对总体评分效度影响不大。此外,以考生s1350为例(同见表6),虽然评分员R3对其评分较严,实际评分为9分,但评分员R4对其评分则较为宽松,实际评分为24分,两者相差悬殊。对于阅卷过程中的此类评分偏差,由第三方阅卷员重新进行评阅(仲裁),以此消除偏差现象。
另一方面,本文分析评分员与任务的偏差。数据分析显示20位评分员与任务的交互作用均产生了显著性偏差(p<0.05),偏差的次数为59,占所有交互作用组合(21×4=84)的70.2%。这些偏差表明,在四项任务评分标准的认识和把握上评分员的一致性较差。评分员在各项任务上的偏差或偏松的次数相当,说明他们在各项任务上的评分尺度不一致。
产生上述偏差的原因可能是评分员对各项任务的评分标准理解不一致,也有可能是评分标准或评分尺度存在问题,让评分员难以把握,比如“陈述”任务的最后一个分数段。这两方面原因可能导致评分员出现了评分偏差。
四、结论与建议
本研究通过使用多层面Rasch模型(MFRM)对PRETCO口试的评分效度进行研究,得出如下结论:PRETCO口试的评分结果能够有效地区分考生的口语水平,评分效度较高,评分员评分的自身一致性总体较好。然而,评分员的宽严度有着显著差别,个别评分员的内部一致性较差;少数评分员和考生的交互作用差异显著;评分员和四项任务之间也出现了不同程度的评分偏差。为了减少评分偏差,本研究拟对PRETCO口试的评分以及评分培训提出以下建议:
(一)进一步加强对评分员的培训
虽然PRETCO口试阅卷前对所有的评分员都进行了培训,而且多数评分员评分的内部一致性把握较好,但评分员外部一致性差异显著。这表明原有评分员的培训可能对提升评分员自身的一致性有一定的帮助,而对提高评分员外部一致性的作用不明显[33]。因此,本研究建议进一步加强对评分员的培训,除了评分前的培训外,评分过程中也可以进行适当的暂停,增加培训和评分员的讨论等环节,从而减少实际评分中的误差。
(二)尽量使用有经验的老评分员
通常而言,老评分员阅卷经验丰富,评分质量较高,而且阅卷的效率也高于新评分员,因此,在实际条件允许的情况下,尽量使用老评分员。如果确有新评分员参与评分,则需要对新评分员进行针对性的培训,比如对评分标准进行详尽的解释,选用各个评分段所对应的典型作文进行多次试评等。同时,阅卷过程中也可以邀请优秀的老评分员交流其评分经验,以帮助新评分员提高阅卷质量和效率。
(三)减少阅卷过程中的评分偏差
为了减少阅卷过程中的评分偏差,阅卷中心需要及时丰富和更新阅卷的数据,加强阅卷组长的监督力度。阅卷组长在阅卷过程中应不间断查看评分员的阅卷数据,比如总体评分的均值、标准差以及评分员各自的均值、标准差等,及时告知阅卷员的评分情况。如果个别阅卷员出现明显偏差,则应及时提醒并督促纠正,如果情况仍然没有改观,则有必要对其进行培训。
当然,本研究只采用定量的方法对PRETCO口试的单次评分结果进行了分析,还存在两点不足:未采用定性的方法探究评分偏差深层次的原因;未对历次的评分偏差进行历时分析,这两方面需要在以后的研究中进一步完善。
[1] 《高等学校英语应用能力考试大纲》修订组.高等学校英语应用能力考试(口试)大纲和样题[M].2版.北京:高等教育出版社,2016.
[2] McNamara,Tim. F.Measuring Second Language Performance[M].London: Longman, 1996.
[3] 刘建达,杨满珍.做事测试评卷中的质量控制[J].外语电化教学,2010(1):26-32.
[4] Wind, Stefanie. A. & Peterson, Meghan. E. A systematic review of methods for evaluating rating quality in language assessment[J].Language Testing, 2017(1):1-32.doi: 10.1177/0265532216686999.
[5] 刘建达.话语填充测试方法的多层面Rasch模型分析[J].现代外语,2005(2):157-169
[6] 王跃武,朱正才、杨惠中.作文网上评分信度的多面Rasch测量分析[J].外语界,2006(1):69-76.
[7] 刘建达.评卷人效应的多层面Rasch模型研究[J].现代外语,2010(2):185-193.
[8] 杨志强,全冬.PRETCO 口试评分标准效度验证[J].外语测试与教学,2016(1):13-21+31.
[9] 戴朝晖,尤其达.大学英语计算机口语考试评分者偏差分析[J].外语界,2010(5):87-95.
(责任编辑:郑宗荣)
①传统意义上,评分研究主要是“信度”研究,即评分的一致性和可靠性。由于“信度”只是整体效度中的一部分,因此使用“评分效度”更加贴切[4]。
A Study on the Scoring Validity of PRETCO-Oral
YANG Zhiqiang XU Yinxue QUAN Dong
This study explores the scoring validity of PRETCO-Oral through a many-facet Rasch analysis. Results show that the scoring of PRETCO-Oral is valid in that examinees’ oral English proficiency can be screened by the test, raters’ scorings are reliable and raters are self-consistent in general; However, results also demonstrate that there are significant differences in raters’ leniency/severity; few raters exhibit self-inconsistency; there exists bias between several raters and examinees and bias between raters and the four tasks.
PRETCO; many-facet Rasch model; scoring validity
G642.475
A
1009-8135(2018)02-0121-08
杨志强(1982—),男,河南安阳人,重庆科技学院外国语学院讲师,硕士,主要研究语言测试。
许吟雪(1983—),女,重庆人,重庆科技学院外国语学院讲师,硕士,主要研究应用语言学。
全 冬(1972—),男,四川金堂人,重庆科技学院外国语学院教授,主要研究现代教育技术。
重庆市教育委员会人文社会科学研究规划项目“基于证据的PRETCO口试效度研究”(17SKG201)和重庆科技学院校内科研基金项目“基于证据的PRETCO口试效度研究”(CK2016Z35)阶段性研究成果。
