基于Hadoop架构的电力企业数据共享模型研究
2018-04-09蒋雷雷代作松
蒋雷雷,代作松 ,秦 宾
(1. 国网临沂供电公司,山东 临沂 371300;2.南瑞集团,江苏 南京 210013)
0 引 言
随着智能电网、大数据技术以及物联网技术的发展,电力企业在生产运营过程中积累了海量的数据资源。由于这些数据具有结构多样、来源复杂、规模巨大、系统独立等特点,造成企业数据集成与共享难度加大,直接影响数据内在知识价值发现,降低电网运营监测效率[1,2]。数据共享是企业实现资源集中管控、提升数据应用价值以及完善信息化建设进程中首要考虑的问题,当前企业在实现数据共享中还存在许多问题:数据集成方式混乱、缺乏统一的数据标准、海量数据的存储与处理能力低等[3],传统的数据共享技术尚不具备完整解决这些问题的能力。目前的理论比较侧重于探索数据共享模式原理及机制,鲜有介绍数据共享技术在实际企业中的应用[4]。当前电网企业虽然已经建成面向不同应用需求的业务数据中心和运监数据中心,但是传统的企业服务总线(ESB)与数据交换平台(DXP)等数据集成方式在数据可扩展性、容错性和数据安全方面还略有不足,造成数据层面并未真正实现数据资源集中管控、综合治理和高度共享,因此,需要构建一套基于企业现状的、完善的及高性能的数据共享方案。
数据共享就是在逻辑上和物理上有机地实现异源异构数据的集中存储和统一访问。文献[5]分析了当前比较成熟的三种数据共享框架模式:基于联邦数据库的数据共享模式、基于中间件技术的数据共享模式和基于数据仓库的数据共享模式,国外也开展了许多类似的研究。基于联邦数据库的数据共享模式虽然构建了数据源视图与全局模式间的映射关系,并能够满足用户的全局查询请求,但是对于海量用户的并发查询以及节点容错问题还存在诸多不足;基于中间件技术的数据集成模式具有较强的融合异构系统的能力,通过中间件间接访问源系统,虽然提高了安全性能,但是随着应用系统增多,中间件性能效率大大降低;基于数据仓库的数据共享模式通过统一的标准对源数据副本进行统一存储,并提供统一访问接口,但是面对海量数据资源,数据仓库的扩展能力和容错性略显不足。Hadoop是一种对大规模数据进行高性能分布式处理的开源技术框架。文献[6]设计了基于Hadoop架构的电力数据中心云计算平台,保证了电力运营的高可靠性、高可用性和可伸缩性,但并未提及海量数据异源异构数据的接入技术。
鉴于以上分析,本文根据电网企业数据资源管理现状,针对海量数据的集成与共享问题,构建分析了基于Hadoop架构的电力企业数据共享模型,采用“editlog+fsimage”动态集成策略实现对元数据管理,增强数据共享的容错性和安全性,依据全局模式和节点模式之间的映射关系以及数据重建的方式,实现数据的共享交互,提高了模型的可扩展性和整体计算性能。
1 电力企业数据共享问题分析
针对国网公司实际业务情况和数据资产管理现状,企业数据集成共享方面的建设还存在以下挑战:
(1)数据异构严重。电力企业信息化在建设过程中,由于企业统推系统及各个自建系统建设的阶段性、技术性以及其它人为因素的影响,导致业务系统种类繁多、存储方式多样、信息编码和技术规范不统一及数据格式不一致等,造成信息资源集成和共享困难。
(2)数据存储低效。由于部署在电网企业中的信息系统比较庞杂,产生的数据包括智能设备实时数据、历史数据、日志数据、文本数据和多媒体数据等,元数据系统分布地域广泛,使得数据资源难于实现统一访问和管理,另外,“爆炸式”增长的海量电力数据对存储时间要求和IT基础设施提出了更高的要求[7]。
(3)缺乏统一标准体系。企业数据共享平台建设虽然依据国网公共信息模型(SG-CIM)标准要求,但是在实际的数据共享设计建设中还存在数据粒度大小多样、存储标准不一、执行效率低、数据规范不一致等问题,严重阻碍了企业数据共享、数据质量、数据安全和数据应用等方面工作的开展。
(4)企业在运营过程中积累了大量的数据资产,其中往往蕴含着各种各样有价值的知识,如何更好地将这些数据转换为实际价值成为了研究焦点。基于数据共享构建大数据分析平台,采用数据挖掘和智能技术能够有效地发现数据的内在知识价值,为企业的运营管理提供科学决策支持[8]。
企业当前数据共享模式主要是以统一数据中心为核心,采用传统的ESB/DXP/OGG/ETL等数据集成技术实现数据的抽取、转换和加载,并且采用传统关系型数据库进行数据存储,造成异构数据存储困难、可扩展性低、吞吐性能差等问题,为了不断提升数据的存储效率和性能,本文采用分布式存储技术和分布式计算技术实现海量数据的存储需求,构建了基于HBase的企业数据共享模型,引入Sqoop、Kafka、Flume等大数据集成技术进行数据的采集工作,并且进一步阐述了数据共享运行机制和保障机制,着力帮助企业构建一个坚实架构,实现企业资源高度共享,优化资源配置,提高管理效率和客户服务水平的一体化企业数据共享平台[9]。
2 基于Hadoop架构的电力企业数据共享平台总体架构
本文构建的企业数据共享平台总体架构严格遵循国网公司信息化建设总体思路以及SG-CIM公共信息模型结构,按照“统一管理、统一应用”的原则,开展企业数据资产管理建设工作,为总部、省市、地市三级中心各业务模块提供数据接入管理、数据集成与共享、数据分析以及数据应用的全寿命周期数据管理服务。企业数据共享平台总体架构包括数据源层、数据集成层(ODS)、数据仓库层、数据集市层和数据应用层。总体架构如图1所示。
(1)数据源层:由于公司数据管理具有业务庞杂、系统相互独立、数据量大、数据异构、数据质量低等特点,因此,根据数据类型和集成需求将其分为实时数据(传感器数据和智能电网设备数据)、非结构化数据(系统日志数据和文本、图像、视频文件)及数据中心数据。
(2)数据集成层:数据集成层是源数据层和数据仓库之间的数据缓冲区,主要负责临时存储业务系统数据,进行数据的初步清洗、加工和计算。本模型严格遵循公司现有的数据集成技术,一方面通过ESB/OGG/ETL/Webservice等方式实现与源数据业务系统之间的数据贯通;另一方面采用DXP/OGG等技术可实现上下级中心间的数据交换与共享;另外,实时数据通过Kafka消息队列接收来自不同源系统的实时数据,非结构化数据采用Flume组件实时的将分布在不同节点上的数据采集到数据仓库中,Flume也具有在线数据转换和直接消息的能力[10]。
(3)数据仓库层:数据仓库层的设计以国网SG-CIM公共信息模型主题域为前提,形成统一的数据视图实现数据共享交换。本文以开源的Hadoop框架为底层架构,构建基于HBase和Hive的数据仓库层,二者一般都是基于HDFS进行元数据管理和数据存储,通过Kafka、Sqoop、Flume、Mapreduce等技术实现异源异构数据、实时数据、日志数据、业务系统数据等的共享交换[11]。Hbase具有很强的实时高并发处理能力,Hive通过类SQL并转换成MapReduce程序,对于历史数据的统计分析更具优势,二者对于数据共享需求优势互补。
(4)数据集市:数据集市一般面向具体业务部门、专业、具体问题进行分析,动态组建所需的数据模型,基于数据仓库中的数据,进行数据灵活加载。数据集市层以公司的关键业务流程为基础,可从精准营销、客户管理、构建高级场景、专项分析、深度分析、业务扩展研究等方面开展,同时满足数据应用层的分析应用需求,数据集市层更加偏向于业务方面的战术性需求,目标在于满足企业特定应用分析的即时性和高效性。
(5)数据应用层:数据应用层的设计依据国网公司“三集五大”战略规划,根据业务需要以及分析决策需求,采用大数据技术进行数据挖掘分析及展示,对企业的关键业务流程进行专题分析,通过数据访问接口技术,实现企业人资集约化、财务集约化、物资集约化、大规划、大建设、大运行、大检修、大营销的战略发展目标。
3 模型的构成
当前比较成熟的数据共享模式主要有三种:基于联邦数据库的数据集成模式、基于中间件技术的数据集成模式、基于数据仓库的数据集成模式。本文在建立的数据共享平台总体架构的基础上,采用基于数据仓库的数据集成模式,构建了基于Hadoop架构的数据共享模型,并且研究分析了模型的运行机制,主要包括基于HDFS的元数据管理机制,基于“发布-订阅”的数据分发策略,基于HBase的数据共享运行机制以及数据共享模型容错机制[12]。
3.1 基于HDFS的元数据管理方案
本文研究的数据共享模型采用基于HDFS的元数据管理机制,HDFS采用的是Master/Slave模型,其对数据的存储以数据块(Block)为单位,由主元数据节点(Primary NameNode)、次元数据节点(Secondary NameNode)和数据节点(DataNode)构成。HDFS的元数据由Block的属性、从属关系和所在位置构成,其对元数据的管理策略采用“editlog+fsimage”动态集成方式,其中,editlog以操作日志的形式记录下元数据操作的历史信息,而fsimage是某时刻整个文件系统信息的映射文件,并且二者都支持多副本机制,保持系统运行的一致性。基于HDFS的元数据管理机制如图2所示。
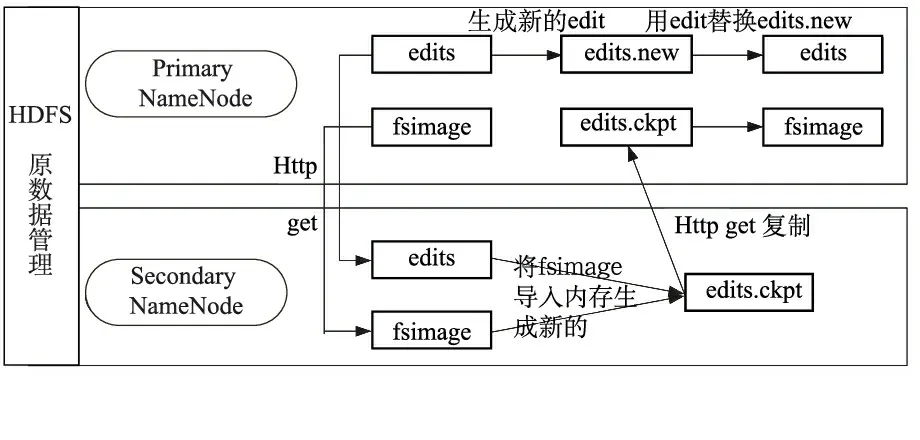
图2 基于HDFS的元数据管理方案
HDFS元数据管理机制:
(1)Primary NameNode通过Secondary NameNode的http post提交请求生成新的日志文件,并在edits.new文件中记录最新请求的操作日志记录;
(2)Secondary NameNode周期性的通过http get获取镜像文件fsimage和日志文件editlogs;
(3)Secondary NameNode加载fsimage文件到内存中,同时执行日志文件的操作,将二者合并为fsimage.ckpt文件;
(4)Secondary NameNode将fsimage.ckpt文件通过http post发送到Primary NameNode进行存储;
(5)Primary NameNode得到fsimage.ckpt文件后,对节点原有的镜像文件和日志文件进行更新,生成新的editlogs和fsimage;
(6)当系统发生故障时,Primary NameNode就可以从Secondary NameNode进行元数据更新,从而实现存储数据的恢复。
3.2 黑板模型思想
黑板模型思想最早由Newell提出,是一种常见的数据架构模式,针对需要解决的问题和不同的应用之间协作共同完成。其基本思想就是多个专家协同来解决黑板上的问题,每个专家根据自己的领域更新相应策略,然后其他专家在此基础上进一步不断更新,直至问题全部解决。在数据共享模型中,该模式能够实现信息的实时共享,并且可以并发地进行消息的更新,具有较高的独立性、可维护性和重用性[13]。
黑板模型主要由三部分构成:黑板、知识源(KS)和监控机构。黑板就相当于本数据共享模型的全局数据仓库,知识源为集成到数据仓库的各源数据库系统。黑板由输入数据、控制数据、部分解、最终解和备选方案等功能构成,能够对初始数据、部分解等进行共享处理。知识源是为黑板提供相应信息和解空间的途径,其通过“条件-动作”的形式进行数据状态的更新。监控结构通过监听黑板信息变化情况,然后通过相应的服务激活相应的数据库接口信息,并将该操作加入到调度队列中,紧接着调度程序会选择合适的知识源对黑板上的问题进行求解,根据其求解结果更新黑板状态,最终实现所有的数据更新共享[9]。
3.3 基于“发布—订阅”的数据分发策略
本文构建的基于HBase的数据共享模型,采用了基于“发布-订阅”的数据分发策略完成对数据的分发、接收操作。在该策略的模型中主要有三个角色,分别是消息发布者、消息订阅者和发布订阅服务器[10]。元数据库系统针对需要共享的数据信息服务进行注册,同时HBase数据仓库与发布订阅服务器之间完成发布服务注册以及配置好接口信息。当发布者向发布订阅服务器发布某条数据集成请求时,服务器就会自动匹配订阅服务信息,并且激活相应订阅者的相应操作,完成数据的集成共享过程。在实际应用中,为了尽可能提高数据分发性能及效率,应该部署专门的服务器负责接收和匹配对应的消息和订阅条件并完成数据的分发。该策略基于HBase的多副本机制和容灾机制,使得单个故障节点并不会影响整个数据仓库的数据集成。图3为“发布-订阅”数据分发模型示意图。
3.4 基于HBase的数据共享模式
本文在数据集成层和数据集市层之间,引入基于Hadoop架构的数据仓库层,针对各源系统数据,采用Sqoop、Flume、Kafka、ETL等集成技术实现数据集中管控、综合治理、智能分析、高度共享。基于HBase的数据共享模式主要包括6部分:共享接口、数据复制、订阅数据、共享数据管理器、数据源和元数据管理,将HBase作为数据仓库与源数据库系统之间的桥梁进行数据共享。
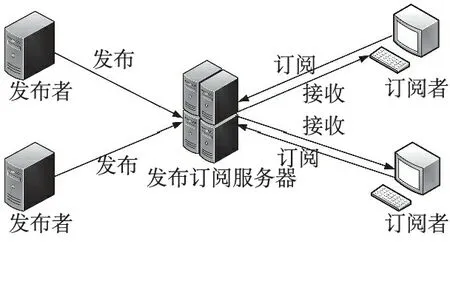
图3 “发布⁃订阅”数据分发模型
在基于HBase的数据共享模式中,作为“黑板”出现的HBase数据仓库与每个源数据库也就是各个“知识源”之间,是通过其HBase共享接口与节点共享接口的连接,实现数据重建和数据复制共享,其中对数据的重建是HBase数据库共享数据的方式,对于源系统数据通过数据重建的方式实现数据共享管理,并且对共享数据与系统数据之间进行分开存储,实现数据的集中管理,基于HDFS元数据管理的“监控机构”保证了整个数据共享机制的有序运行[14]。
基于HBase的数据共享模式主要是通过建立全局模式与节点模式之间的虚拟映射关系来实现的;HBase数据仓库与各元数据库之间通过映射配置接口信息实现通信;节点模式下的数据资源通过映射关系转换为全局模式视图;这样,HBase数据仓库就会根据元数据库的请求完成数据采集工作。如图4所示,基于HDFS元数据管理技术主要包括元数据的获取、元数据查询、元数据映射、元数据操作等。在元数据管理技术的前提下,节点数据源以审核发布的方式将数据以数据复制的方式被存储到HBase订阅数据组。然后,HBase共享数据管理器将这部分数据以全局视图模式存储到HBase数据库中。其次,通过元数据映射和模式信息管理机制,HBase数据库通过审核发布将数据以数据重建的方式抽取到节点数据订阅组,并通过节点共享数据管理器将数据存储到节点数据源中,实现二者之间的数据集成与共享。
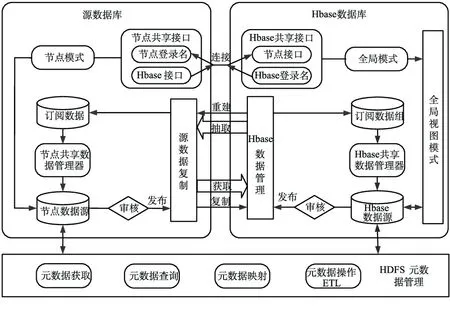
图4 基于HBase的数据共享运行机制
4 结束语
本文在电网企业现有信息化建设及数据管理现状的基础上,研究分析了基于Hadoop架构的电网企业数据共享模型,包括基于HDFS的元数据管理方案和基于Hbase的数据共享模式。该模型针对海量异源异构数据的集成和处理有一定优势,有效地解决了电网企业数据共享中存在的扩展能力低、低效容错、数据安全等问题。结合电网企业构建了基于该模型的数据共享平台总体架构,为电网企业实现数据资源集中管控、数据信息高度共享、数据价值深度挖掘提供一定的借鉴,促进公司各业务数据的全面集成和深度融合,帮助企业更好发掘数据的内在价值,为企业的运营管理提供科学决策和应用价值。该模型有望为电网企业统一数据中心建设、全寿命周期数据治理体系构建、大数据分析挖掘领域等提供数据层支持。此外,本文仅研究分析了电网企业数据共享建设框架思路,但是具体的数据移植、数据集成方案、硬件支撑等实施方案还需认真深入研究。
参考文献:
[1]王玮,刘荫,于展鹏,等.电力大数据环境下大数据中心架构体系设计[J].电力信息与通信技术,2016,14(1):31-36.
[2]张东霞,苗新,刘丽平.智能电网大数据技术发展研究[J].中国电机工程学报,2015,35(1):22-34.
[3]王相伟,史玉良,张建林,等.基于Hadoop的用电信息大数据计算服务及应用[J].电网技术,2015,39(11):3128-3133.
[4]苏学能,刘天琪,曹鸿谦,等.基于Hadoop架构的多重分布式BP神经网络的短期负荷预测方法[J].中国电机工程学报,2016,23(8):43-53.
[5]王海豹.基于Hadoop架构的数据共享模型研究[D].北京:北京工业大学,2013.
[6]王德文.基于云计算的电力数据中心基础架构及其关键技术[J].电力系统自动化,2012,36(11):67-71.
[7]刘友波,刘洋,刘俊勇,等.基于Hadoop架构的电力系统连锁故障分布式计算技术[J].电力系统自动化,2016,40(07):90-97.
[8]Silberstein A E, Sears R, Zhou W,etal. A batch of PNUTS: experiences connecting cloud batch and serving systems[C].Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data. Athens: ACM SIGMOD/PODS, 2011:1101-1112.
[9]Baliga J, Ayre R W A, Hinton K,etal. Green cloud computing: balancing energy in processing, storage, and transport[J]. Proceedings of the IEEE, 2011: 149-167.
[10] 齐林海,艾明浩,王金浩.基于Hadoop架构的电能质量监测云模型研究[J].电力信息与通信技术,2014,12(2):10-14.
[11] 刁柏青.智能电网框架下智能运营系统的构建[J].智能电网,2014,2(04):1-7.
[12] 王逸飞,张行,何迪,等.基于大数据平台的电网防灾调度系统功能设计与系统架构[J].电网技术,2016,40(10):11-14.
[13] 宋亚奇,周国亮,朱永利.智能电网大数据处理技术现状与挑战[J].电网技术,2013,37(4):927-935.
[14] 彭小圣,邓迪元,程时杰,等.面向智能电网应用的电力大数据关键技术[J].中国电机工程学报,2015,35(3),503-511.
