采用多尺度注意力机制的远程监督关系抽取
2018-04-04郝佳云李海生
蔡 强,郝佳云,曹 健,李海生
(1. 北京工商大学 计算机与信息工程学院,北京 100048;2. 北京工商大学 食品安全大数据技术北京市重点实验室,北京 100048)
0 引言
信息抽取技术在自然语言处理领域十分重要。关系抽取作为信息抽取的重要分支,用来识别文本中实体预先定义的语义关系[1]。即对于实体对e1和e2,二者之间相关关系可以形式化地表示为三元组形式
近年来,深度学习在很多自然语言处理任务中取得了较好效果,因此大量算法采用深度学习的方法进行特征提取以及关系抽取。2012年,Socher[2]提出使用递归神经网络来解决关系分类问题,通过递归神经网络得到句子向量表示,从而用于关系分类。之后,Zeng[3]等人采用卷积神经网络结合词向量及词语位置信息进行关系分类。虽然这些方法取得了较好效果,但是在对模型进行训练时需要大量标注数据,耗费了大量的人力物力。因此,本文重点研究远程监督方法。
远程监督关系抽取首次由Craven[4]等人提出,利用知识库信息来发现蛋白质与细胞/疾病/药物之间的关系。Mintz[5]等人通过将知识与文本集对齐来进行大规模关系抽取。但是,错误标签引入了大量噪声,因此文献[6]提出了使用多示例学习的远程抽取策略,大规模减少了人工标注数据的工作,但是由于在句子编码时未充分利用句子中重要的语义信息,抽取结果准确率并不高。针对这一不足,一些算法进行关系抽取时采用了注意力机制的方式,用于丰富编码的语义信息并且减少编码过程中的噪声问题。
注意力机制曾在序列到序列任务中大放异彩,在对句子进行建模中取得了较好效果。因此,2016年,Lin[7]等人提出了句子级别的注意力模型,用来降低远程监督关系抽取模型中错误标签带来的噪声问题。Zhou[8]等人在采用长短期记忆模型(long short-term memory,LSTM)得到句子高层语义之后,使用注意力权重矩阵进行高层语义表示,提高了句子表示的准确性。但是这些方法在表征句子的局部及全局信息时仍有不足。
Yang[9]等人曾将层次化的注意力机制应用到文本分类任务中,采用词语和句子层面的注意力模型对文本进行分类,并且取得了不错的效果。而在关系抽取任务中词语和句子的特征向量表示对分类效果同样有着重要影响。在生成句子向量时,用于分类的关系对于句子编码的重要程度不同。例如,在句子“The burst has been caused by water hammer pressure.”中,关系“cause”对句子中词语的相关程度要强于关系“location”。因此句子中各词语与关系之间的相关性影响着句子的向量表示。同时,在同一实体对对应的句子集合中,实体对在知识库中对应的关系对于不同句子的影响程度也不同。例如,实体对“Bill Gates”与“Microsoft”在知识库中对应的关系为“founder”,关系标签“founder”对于句子“Bill Gates is the founder of the Microsoft.”有较高的相关性,而对于句子“Bill Gates continues to serve on Microsoft’s Board as an advisor on key development projects.”相关性较低。所以,通过计算关系对不同句子的相关性,一方面可以降低错误标签带来的噪声问题,另一方面可以获得不同句子中丰富的语义信息。因此本文提出一种多尺度的注意力模型,采用注意力机制提取更加丰富的词语及句子特征。模型使用双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU)得到高层语义信息,在词语层面,通过在池化层采用权重矩阵来捕捉不同词语与关系之间的相关性;在句子层面,通过计算句子与知识库中对应的实体对之间预测关系的相关程度得到最终的句子向量表示。
1 多尺度注意力关系抽取模型
为了更好地利用句子语义信息,捕捉句子中较为重要的部分,并且降低错误标签带来的噪声问题,本文结合词语层面及句子层面的注意力机制,提出了多尺度注意力关系抽取模型,模型设计方式如图1所示:
(1) 输入映射层: 将词语与实体对之间位置向量作为神经网络模型输入。
(2) Bi-GRU层: 采用双向GRU得到高层语义信息。
(3) 注意力池化层: 通过计算句子中词语与所有关系之间的相关程度,建立词语层面权重矩阵进行池化,并且将词语水平的向量合并成为句子水平向量。
(4) 多示例注意力层: 计算实体对集合中句子向量和预测关系之间的相关程度,建立句子层面权重矩阵,得到最终的句子向量表示。
1.1 输入映射层
为了捕捉词语的句法和语义信息,需要将输入句子中的词语映射为词向量。对于包含m个词语的句子s={w1,w2,…,wm},其中每个词语wi均被表示为实值向量wi。
其中,Wwrd∈Rdw×|V|是由word2vec训练得到的向量矩阵,dw是词向量的维度,|V|是词典的大小,i是输入词语的词袋表示(one-hot形式)。由此得到一个向量序列w={w1,w2,…,wm}。
1.2 Bi-GRU层
GRU是Chung[10]等人提出的LSTM的一个变种,包含更新门和重置门二个门结构和一个隐藏状态。为了得到序列中过去和未来的上下文信息,本文采用双向GRU得到高层语义表示。根据文献[3]的假设,在关系抽取任务中,越靠近实体的词语包含抽取关系的信息越丰富,本文采用词向量及词语位置向量映射作为双向GRU的输入,因此对于第i个词语的输入为:

图1 多注意机制关系抽取模型
其中,wi为第i个词语,pi,1,pi,2分别表示第i个词语与第一个实体和第二个实体间的位置关系。

更新门zi决定了过去隐含状态hi-1向下一个状态传递的程度:
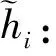
其中,V(n)、U(n)、V(m)、U(m)、V(s)、U(s)是在训练GRU时学习得到的参数。

1.3 注意力池化层
对于关系抽取任务,用于分类的关系集合对于句子中词语的重要程度不同。因此,本文采用词语层面的注意力权重矩阵捕捉句子中与目标关系更加密切的信息。不同于传统的池化操作,为了得到与分类任务更相关的特征,本文采用注意力机制的池化操作。将通过双向GRU层得到的句子向量与注意力权重矩阵相乘,之后采用最大池化的操作获得最显著的特征表示,从而将词向量转化为句子向量。

图2 注意力池化层权重矩阵
在1.2节得到的句子H(H∈Rd×t,d为经过双向GRU层后得到的表示单个词语向量的维度,t为句子的长度)表示为[h1,h2,…,ht]。所有关系组成的集合为Y(Y={r1,r2,…,rl},r是关系的向量表示,l是关系的数量),如图2所示,通过计算句子向量和关系向量的内积,得到句子及关系相关度权重矩阵U(0):
其中,参数矩阵V(0)(V(0)∈Rd×l)是在训练过程中更新得到。
通过将经双向GRU层得到的句子向量H与权重矩阵相乘,从而突出词语层面的重要部分。之后,采用文献[11]的策略,采用最大化的策略选择最显著的特征。因此,句子表示为:
1.4 多实例注意力层
在传统的远程监督抽取关系任务中,不可避免会引进错误标签,从而为关系抽取带来噪声。针对这一问题,本文采用多示例建模[7]的方式,对于实体对,考虑实体与预测关系之间的相关程度,建立注意力矩阵,降低噪声对正确关系的影响,并且充分利用这些句子中的语义信息得到最终句子向量表示。
对于包含相同实体对的句子集合S,假定其中包含句子的数目为n,即S={s1,s2…sn}。由1.3节得到的集合S中句子向量可以表示为s1,s2,…,sn,为了计算输入句子si与关系r之间的相关程度,通过计算句子集合中句子向量与知识库中实体对对应关系向量的内积,得到注意力矩阵。
权重矩阵的计算公式如下:
其中,A(A∈Rd×d)为加权对角矩阵,r是实体对在知识库中对应的预测关系r的向量表示,由于关系向量在测试过程中是未知的,因此,其在训练过程中为实体对在知识库中对应的预测关系,在测试过程中通过随机初始化得到。
为了使与关系向量更为相关的句子被赋予较高权重,因此,将实体对对应的句子表示为:
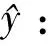
其中,b为偏置向量。
1.5 训练和优化策略
本文采用交叉熵代价函数作为目标函数,定义如下:
其中,θ表示模型中所有的参数,T代表句子集合数,本文使用Adam优化器进行参数更新。
为了防止模型过拟合,采用Dropout进行正则化约束。Dropout最先是由Hinton[12]等人提出,在每次前向传播时,随机地丢弃一些隐层节点特征,即权值更新不依赖于固定的节点共同作用。本文在双向GRU层采用Dropout。
另外,本文采用了L2正则化,在迭代时乘以一个小于1的因子λ,用于减小参数θ的值。正则化操作降低了数据偏移对结果的影响,增强了模型的抗扰动性,避免了过拟合现象。
2 实验结果及分析
2.1 数据集及评价准则
为了评估多尺度注意力关系抽取模型,采用2010年由Riedel[13]等人提出的数据集。该数据集是将知识库Freebase和文本集New York Times通过启发式的匹配对应生成的,并被广泛应用于远程抽取任务中。具体地,本文采用2005—2006年的句子作为训练示例,2007年的句子作为测试示例。数据集中包含53种关系(包含“NA”,表示实体对之间没有关系),其中训练集中包含实体对数目为281 270,测试集中包含实体对个数为96 678。
为了评价本文的方法是否有效,采用平均准确率(P@N)、准确率-召回率(PR)曲线来进行评价。通过对比前N项准确率以及PR曲线下的面积来评估算法的好坏。
2.2 参数设置
在实验过程中,采用交叉验证的方式进行模型调优,验证集从训练集中随机抽样获取。参数设置的过程参考文献[7]中的经验值,句子向量的维度取值范围为{50,60,…,300};关系向量的维度与句子向量一致;学习率的取值范围为{0.01,0.001,0.000 1};批大小的取值范围为{50,100,150,200}。经过实验,本文采取的参数设置如表1所示。

表1 参数设置
2.3 实验验证
为了验证多尺度注意力模型对关系抽取性能的提高,本文将单注意力机制及采用多尺度注意力机制对模型影响的效果进行了对比,结果如图3和表2所示,其中sentence表示仅采用句子层面的注意力模型,all表示本文提出的多尺度注意力模型;表2是这两种方法前100、200、300的准确率以及平均准确率。从图表中可以看出,相较于采 用 了 单 个注意力机制的模型,结合多尺度的注意力模型提高了关系抽取的准确性。

表2 句子层面注意力模型与多尺度注意力模型准确率表

图3 句子层面注意力模型与多尺度注意力模型对比曲线
另外,本文选取五种已经发表的方法进行对比,如图4所示。Mintz是由Mintz[5]等人提出,采用全部示例来抽取特征,Hoffmann[14]采用了多示例学习的方法,MIMLRE[15]采用多示例多标签的方法,CNN+ATT与PCNN+ATT是由Lin[7]等人提出,采用Zeng等人在文献[3,6]中的工作,增加句子注意力机制的方法所得到的模型。图4表明,相较于其他模型,我们提出的模型有相对较高的准确率和召回率。另外,本文采用GRU获得句子的向量表示,相较于CNN方式更能表征句子中的上下文信息,但同时对于局部特征的表征要弱于CNN,因此如图4所示,在获得较高召回率的同时,由于引入了更多的噪声,对句子的向量表示影响较大,所以本文方法在准确率上要弱于采用CNN的方法。未来我们也将尝试将CNN与GRU进行结合来表征句子向量,以获得更加丰富的特征。
3 结束语
在本文中,我们提出了一种采用多尺度注意力机制的模型。在词语层面及句子层面均采用了注意力机制。充分利用了关系对于句子中词语的影响,并且考虑到了同一实体对所在句子集合中预测关系对句子编码的影响。实验表明,本文提出的模型适用于远程实体关系抽取任务。未来工作将尝试采用多类模型表征句子向量;并且在句子注意力机制方面,探索不同的方式解决多示例带来的噪声问题。
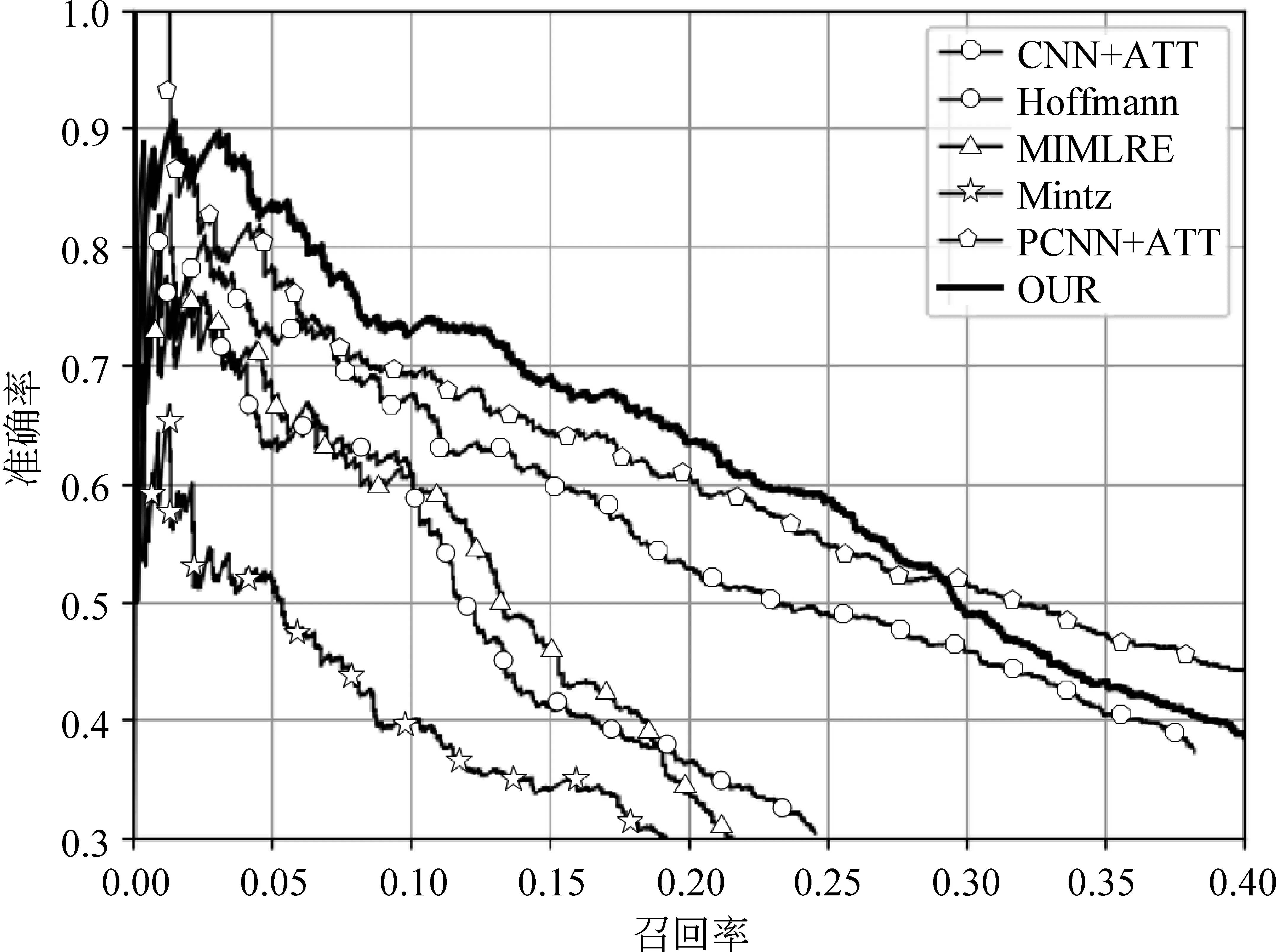
图4 本文方法与其他五种方法对比曲线
[1]Li J, Zhang Z, Li X, et al. Kernel-based learning for biomedical relation extraction[J]. Journal of the Association for Information Science and Technology, 2008, 59(5):756-769.
[2]Socher R, Huval B, Manning C D, et al. Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the EMNLP-CoNLL 2012. Korea, 2012:1201-1211.
[3]Zeng D, Liu K, Lai S, et al. Relation classification via convolutional deep neural network[C]//Proceedings of the COLING 2014. Ireland, 2014: 2335-2344.
[4]Craven M, Kumlien J. Constructing biological knowledge bases by extracting information from text sources[C]//Proceedings of the ISMB 1999. Heidelberg, 1999: 77-86.
[5]Mintz M, Bills S, Snow R, et al. Distant supervision for relation extraction without labeled data[C]//Proceedings of the ACL-IJCNLP 2009. Singapore, 2009:1003-1011.
[6]Zeng D, Liu K, Chen Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks[C]//Proceedings of the EMNLP 2015. Lisbon, 2015: 1753-1762.
[7]Lin Y, Shen S, Liu Z, et al. Neural relation extraction with selective attention over instances[C]//Proceedings of the ACL 2016. Berlin, 2016: 2124-2133.
[8]Zhou P, Shi W, Tian J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]//Proceedings of the ACL 2016. Berlin, 2016:207-212.
[9]Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the NAACL 2016. San Diego, 2016:1480-1489.
[10]Chung J, Gulcehre C, Chol K H, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[J]. arXiv preprint arXiv:1412.3555, 2014.
[11]Santos C, Tan M, Xiang B, et al. Attentive pooling networks[J]. arXiv preprint arXiv:1602.03609, 2016.
[12]Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer Science, 2012, 3(4):212-223.
[13]Riedel S, Yao L, McCallum A. Modeling relations and their mentions without labeled text[J]. Machine Learning and Knowledge Discovery in Databases, 2010: 148-163.
[14]Hoffmann R, Zhang C, Ling X, et al. Knowledge-based weak supervision for information extraction of overlapping relations[C]//Proceedings of the ACL HLT 2011. Portland, Oregon, USA: DBLP, 2011:541-550.
[15]Surdeanu M, Tibshirani J, Nallapati R, et al. Multi-instance multi-label learning for relation extraction[C]//Proceedings of the EMNLP-CoNLL 2012. Korea, 2012:455-465.
