中英文篇章依存树库构建与分析
2018-04-04吴永芃李素建秦沐坤王厚峰
吴永芃,李素建,秦沐坤,杨 安,王厚峰
(北京大学 计算语言学教育部重点实验室,北京 100871)
0 引言
自然语言处理领域中,目前已有较多在词与句子的层次上进行的研究,并取得了丰硕的成果。随着研究的深入,人们开始着眼于更高层次的自然语言分析——篇章层次。众所周知,篇章所独具的完整性和连贯性使得一个篇章与一段由若干句子随机组合而成的文本具有显著的不同。我们可以将篇章视为一系列连续的文本单元(如子句、句子或语段)构成的语言整体单位。任何文本单元都不可以被孤立地进行解读,而是需要根据其上下文来理解。篇章分析与标注,旨在对篇章内部的结构和关系进行分析,并在分析的基础上对其进行相应标注。篇章分析技术在自动文摘[1]、自动问答[2]、指代消解[3]等自然语言处理领域中,具有重要的意义。
当前两个有代表性的英语篇章树库为宾州篇章树库(penn discourse treebank,PDTB)和RST树库(rhetorical structure theory-discourse treebank,RST-DT)。PDTB由美国宾夕法尼亚大学创建,标记了约100万字的华尔街日报文章,最新版本为PDTB 2.0[4]。PDTB将语句看作论元(argument),主要标注论元对之间的篇章语义关系和可能的连接词,把一个大的篇章分解成平面化的论元对,篇章标注层次较浅,为浅层篇章标注[5]。RST-DT建立在修辞结构理论(rhetorical structure theory,RST)之上,由美国南加州大学和美国国防部共同创建,共计标记了385篇华尔街日报的文章,总字数超过176 000个[6]。RST理论通过修辞关系对语篇结构进行描写,将整个篇章构建成一棵有层次的RST树[7]。然而,有层次的RST树结构较为复杂,节点数目较多,不同层次的篇章单元有包含关系,难以构建一个统一的用于篇章分析的架构,给机器自动分析带来了困难。汉语篇章语料库的建设也取得了一些进展,哈工大参考PDTB的标准,并结合中文的特点,从分句、复句和句群三个层次标注显式和隐式关系,构建了篇章语料库HIT-CDTB[8]。苏州大学利用汉语依存句法分析技术构造了篇章结构语料库CDTB[9],该结构融合了PDTB和RST的优点,对每篇文档构建一棵篇章树,虽然篇章结构的信息量更加丰富,但也加大了自动分析的困难。
篇章依存分析结构的引入,一定程度上兼顾了深层篇章结构的标注和降低自动分析的难度。2014年,李素建等[10]首次提出利用依存结构进行篇章分析,不同于CDTB采用的句法依存,这里的依存指的是篇章层面的依存关系,并在已有的RST-DT的基础上进行转换,建立了一个英语篇章依存树库。二元非对称的依存结构解释了篇章的深层关系,保留了RST树中的大部分信息,又因其具有相对简单的结构,可以直接分析各个单元之间的关系,使机器自动分析工作能更容易地开展。但RST树转换而来的篇章依存树,可能存在一定的问题。例如,无法展现篇章依存树特有的非投射关系。到目前为止,较少有人工构建篇章依存树库的工作。基于这一背景,本文在篇章依存关系的基础上,建立了小规模中英文篇章依存树库,并针对多核心问题、依存关系的选择、长篇章与复杂篇章的标注、层次结构信息的损失等标注过程中遇到的困难进行了分析研究,给出了解决方案。同时,对篇章依存树库进行了简单的统计分析,针对中英文篇章的异同做了简单探索。
1 篇章依存树
1.1 篇章依存树的形式化表示
篇章依存分析思想认为,篇章由篇章单元(elementary discourse unit,EDU)构成。篇章单元之间由被称为依存关系的二元非对称关系连接。其中,我们称附属(subordinate)篇章单元为“附属单元”(dependent),称被依靠的篇章单元为“头部单元”(head)。利用篇章依存树表示篇章依存结构时,我们需要在篇章依存树起始位置插入一个人工篇章单元,称之为e0,并视之为该篇章的根(root),以此简化定义与计算过程。
记一含有n+1个篇章单元的篇章T为:T=e0e1e2…en,其中e0为根。记该篇章依存关系集为R,R为有限的功能关系集合,且R中的关系存在于两个篇章单元之间。记V为篇章的一系列节点,A为篇章的一系列有向标记弧。记篇章依存图为G,则:G=
(1)V={e0e1e2…en};
(2)A⊆V×R×V,其中
(3) 若
(4) 若
其中,条件(3)确保了每个篇章单元有且仅有一个头部单元。条件(4)确保了两个篇章单元之间,不能有多于一种的依存关系。
一般而言,对同一个篇章,篇章依存树的结构比RST树更加简单,节点数更少,复杂度更低。例如,3个单元的核心-辅助结构RST树新增了1个中间节点和1个根节点,而篇章依存树仅新增了1个根节点。可以看出,含有n个文本单元的核心-辅助结构RST树,共包含2n-1个节点;而含有n个文本篇章单元的篇章依存树,仅包含了n+1个节点。
1.2 依存关系
本文参考了1988年RST理论提出的修辞关系[7]。根据所标注中英文语言特点,删减与合并了部分关系,根据标注时遇到的情况新增了部分篇章关系,最终确定了如表1所示的26个篇章依存关系,由于篇幅限制,这里不再展开篇章关系的介绍。
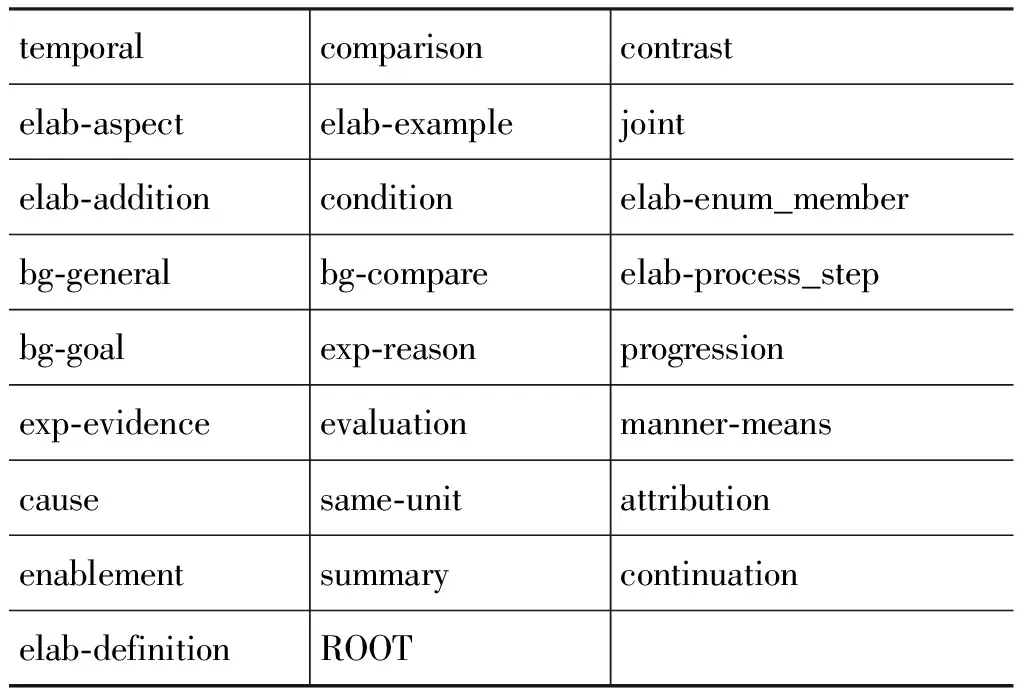
表1 本文采用的篇章依存关系
2 篇章依存树库构建
2.1 语料库的选择
由于短小但完整、连贯的篇章,可以推动篇章依存库的构建和分析,因此我们选择了科技论文摘要和新闻作为标注文本。科技论文摘要的写作一般结构清晰,逻辑性强,容易进行标注和分析。而我们选择人民网的时政要闻快讯作为语料库,是考虑到人民网作为国家权威媒体网站,其发布的新闻遣词造句较为严谨,结构清晰,逻辑性强,质量较高,不会给篇章依存分析带来困扰。该语料库新闻的平均字数较少,但每一篇新闻,都保持了其作为篇章的完整性和连贯性。
基于以上考虑,我们选用了ACL 2014会议的50篇英文论文摘要和EMNLP 2014会议的40篇论文摘要进行篇章依存关系标注,同时还标注了15篇英文经济短新闻,中文方面标注了33篇人民网新闻。文献[10]中篇章依存库是由RST-DT语料自动转换而成,依存关系的标注并不够准确,本文中的138篇文档均为人工标注和校对。
2.2 确定篇章单元的划分方式
确定划分篇章单元的标准是进行篇章分析的先决条件,也是一项较为独立的工作。在英文篇章的篇章单元确定中,涌现出了多种划分方法。修辞结构理论认为,除个别情况外,从句是最基本的单位[7]。Polanyi坚持自然句应为最基本的单元[11]。Grosz和Sindner[12]认为,篇章单元的确定应考虑到该单位在上下文中的位置,且能反映事物的一定状态。
本文英文语料库的篇章划分参考修辞结构理论,以从句层面的结构为最基本单位,因此to、that、since等引导从句的介词会成为划分标记,包括一些动词的现在分词作后置定语也会被划分为单独的篇章单元。
中文语料库的篇章单元,与英语中选择从句较为不同,汉语篇章的从句多为隐性。此外,在汉语中,逗号常常起着单句切分的作用,被隔开的单元通常以单句或类似于单句的结构出现。因此,本文选择使用标点符号作为划分的依据。本文汉语篇章的篇章单元由逗号、句号、分号、冒号、问号、叹号、破折号与省略号划分。括号、顿号、引号、连接号、书名号、间隔号等不作为划分依据。对于新闻语料,可能由多段组成,每个篇章单元起始位置用数字标识其段号和句号,表明其在文本中的位置。例如,“2.3”表示篇章第二自然段的第三个篇章单元。科技论文摘要通常由一段构成,不再区分其段落。
2.3 标注工具
本文使用篇章依存关系标注工具*http://123.56.88.210/demo/depannotate/为文本标注篇章依存关系。标注工具中,我们用白色文本框表示篇章单元;起始于头部单元并终止于相应附属单元的有向箭头表示依存关系;附属单元左侧写明该依存关系的种类;蓝色方框内的数字为相应篇章单元对应的头部单元编号。通过这种形式,我们将篇章依存关系表示成一个带标注的有向图。
具体使用时,我们首先对篇章进行篇章单元的划分,再使用该标注工具载入已完成篇章单元划分的文档和自定义标签,开始进行依存关系标注。在添加依存关系时,我们依次单击头部单元、附属单元,并在弹出的对话框中选择依存关系的种类,即可标注一个篇章依存关系。若出现关系标注错误,单击依存关系的附属单元后,通过“删除”功能可以删除该关系。标注工具还可以通过“撤销”功能取消之前的添加、删除与标注操作。“加标签”“删标签”功能则可增、删依存关系的种类。整篇标注完成后,单击“保存”,即可将结果存为后缀名为.dep的文档,以供进一步的分析。
3 标注难度与解决方法
篇章依存关系的直接标注,需要为每个篇章单元选择其头部单元,并确定关系的种类。表面看来,只需要逐一对每个篇章单元进行分析即可完成,但真正标注时并不容易。在分析每个篇章单元的时候,需要从全文去理解,帮助确定每个依存关系。下面,我们将介绍标注中遇到的问题,以及我们的解决方案。
3.1 多核心关系处理
篇章结构中存在涉及两个或多个单元、且各单元重要程度相等的多核心关系,如comparision、joint、same-unit等。然而,使用篇章依存关系表示多核心关系存在一定的困难: 多核心关系连接两个或多个单元,而依存关系仅存在于两个篇章单元之间;多核心关系的各个单元应当同等重要,而依存关系连接的篇章单元重要程度却不同。这使得多核心关系必须要进行变换才能在篇章依存树中得以表示。如图1所示。

图1 多核心关系(joint)的处理示例
我们的处理方式为: 选择多核心关系内部或附近的某一篇章单元作为其余篇章单元的头部单元,以表达多核心关系。头部单元的选择视情况而定——可以是多核心关系中相对较重要的一个篇章单元,可以是多核心关系中的第一个篇章单元,也可以是多核心关系前紧邻的一个篇章单元。图1中,我们选取了第一个篇章单元即图中第一句作为头部单元,和其他两个篇章单元(第三句和第五句)构成joint关系。这种方式很好地克服了多核心关系与依存结构的矛盾,使多核心关系得以在篇章依存树中得到表示。
3.2 依存标注中的话题链问题
本文选择了26种依存关系用于篇章依存树库的标注。大多数关系都容易区分,但是也有一些特殊情况需要单独处理,比如汉语标注中遇到elab-addition和elab-aspect这两种关系,前者是对核心句主要内容的进一步阐述,后者则是对核心句提到的不同方面进行阐述。由于英文中存在从句结构,elab-addition和elab-aspect较为容易区分,但在汉语中,这两个标签有时难以区分,考虑表达的“重心”和篇章性,我们选择用话题链[13]来解决这个问题。关于话题的说明可以参考赵元任的《汉语口语语法》[14]。
若附属单元是头部单元的进一步阐述,且属于同一话题链,则关系标注为elab-addition,若不属于同一话题链则标注为elab-aspect。
如图2所示,1.2句的话题是作品展,2.1句的画展是作品展的回指,则1.2和2.1两句之间的关系属于同一话题,因而标注为elab-addition。而2.2句的话题是画作,则和2.1的关系标注为elab-aspect。

图2 话题链区别elab-addition和elab-aspect示例
需要说明的是,我们起初试图用汉语研究中的语句重心[15]来进行区别以上两种关系的标注,但当前汉语中语句重心的研究认为,类似1.2句的陈述句,其重心靠后,也就是“拉开帷幕”这一事实,但联系上下文不难发现,“作品展”才是串起篇章,联结上下文的关键,因此最后采用了篇章性更强的话题的概念对关系进行区分。
3.3 长篇章及复杂篇章的标注
与RST结构相比,篇章依存结构没有中间节点,复杂度相对较低。但本质上它仍然是一种层次结构,对每一个篇章关系的判断,都需要考虑到上下文信息,也就是其他篇章依存关系对它的影响。因此不能简单地从每个篇章单元独立地去考虑,也就不容易按线性顺序给每个篇章单元确定头部单元及关系。尤其是规模大、复杂度高的篇章,标注过程更为艰难。
对此,本文采用了“自顶向下”和“自底向上”相结合,并兼顾考虑篇章自然段划分的方法,标记长篇章及复杂篇章。在“自顶向下”的过程中,我们首先找到包含篇章中心思想的、最重要的篇章单元,令其头部单元为根节点。然后,找到包含各自然段中心思想的重要篇章单元,并标注它们之间的依存关系。接着,我们再去寻找包含更小范围篇章片段的中心思想的篇章单元,层层向下进行标注。在“自底向上”的过程中,我们运用层次结构的思想,从篇章结构底层的某一篇章单元着手,不断将其周围更多的篇章单元纳入考虑,层层向上进行标注。
标注过程中,篇章的自然段划分是重要的辅助参考指标。多数情况下,篇章是在自然段内部先形成依存关系后,再与自然段外部形成依存关系的。两个自然段间通常只存在一个依存关系。两种过程可以交替进行,在某一过程中遇到瓶颈难以继续时,则切换到另一标注过程中,继续标注。二者交替进行有助于对篇章进行分块、分层,能够增进对篇章的宏观把握,使依存关系标注更加快速、准确。
3.4 层次结构信息损失
篇章依存树在一定程度上对RST结构作了简化,这虽然降低了标注的难度,但也使其可能缺失了部分篇章层次信息。我们发现,当头部单元两侧各有一个附属单元时,依存树反映了两种可能的RST结构,参考论文[10],无法判断篇章单元e2与e1、e3中哪个的关系更为密切,一定程度上损失了篇章层次信息。
这种结构在各种篇章中十分常见。例如,图3所示4.1、4.2、4.3之间的依存结构,可能对应着图4和图4所示的两种RST结构: A和B。我们知道,因为4.1说明了4.2及4.3的引用来源,结构A反映了作者的写作意图和该篇章的篇章结构。然而,在没有额外知识和信息的情况下,我们根本无法做出上述判断。也就是说,用这种篇章依存树表示篇章结构出现了信息损失。在未来的工作中,我们将考虑如何处理这种情况。

图3 层次结构信息损失示例
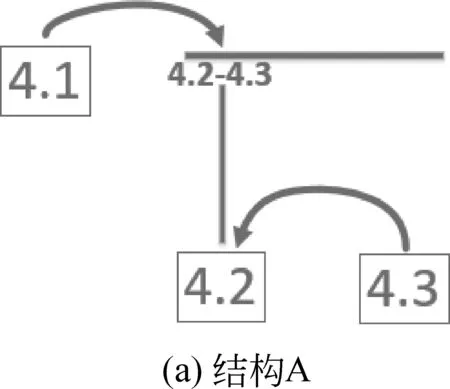
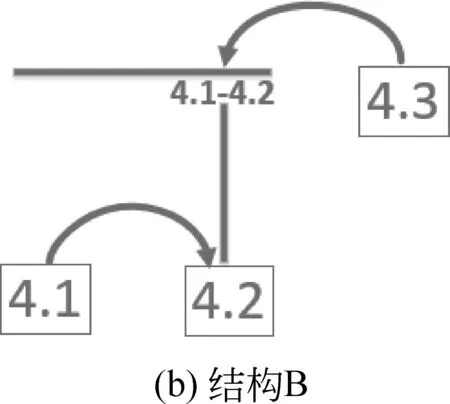
图4 RST结构
3.5 篇章单元划分错误
在使用标点符号作为划分篇章单元的标志时,若不进行特殊规定,在部分情况下会出现错误。篇章中出现的汉语冒号,在提起下文、引用话语或总结上文时,可作为篇章单元的划分标志。但在篇章撰写过程中,可能出现将冒号用为“比号”的情况。例如,“尼泊尔制宪会议16日晚以507: ”和“25的压倒性票数表决通过了新宪法草案”,由于根据标点符号划分篇章单元,则被错误地划分为了两个篇章单元。再例如,“9月16日21时08分在台湾宜兰县附近海域(北纬24.3度,”和“东经121.9度)发生5.4级地震”,括号中的逗号导致篇章单元划分得不合理,括号内的内容被分拆进了两个篇章单元中。更好的划分方式为分成一个篇章单元(即不划分)或三个篇章单元(括号前、括号及括号内、括号后)。
在现有的划分标准下,篇章单元的自动划分存在错误。本文选择的方法是: 在篇章单元自动划分后,再进行一遍人工修正与校对,以排除自动划分造成的问题。
3.6 一致性问题
本文篇章依存树库的构建及篇章依存关系的标注均只由一人完成。为了提高标注语料的一致性,标注者对每一篇语料均进行了两次标注。两次标注有一定的时间差。最后,再对两次的标注结果进行对比和分析,对不一致的标注进行修改,得到最终的标注结果。这一方法一定程度上弥补了单人标注的缺陷,提高了标注语料的一致性与篇章依存树库的质量。
4 篇章依存树库统计分析
此次标注的语料库总计138篇文献,共对2 044个篇章单元进行了依存关系标注。其中英文文献中最长的篇章单元有39个单词,平均长度为9个单词;中文新闻中最长的篇章单元有70个汉字,平均长度为13个汉字。由于每个依存树有且只有一个ROOT节点,且只有ROOT节点与文章核心句之间的关系被标注为ROOT,故表中ROOT标注的数量等同于依存树的数量。
图5为篇章关系在中英文和新闻、科技论文摘要两个领域上分布的折线图,虽然不同语料上的标注基数不同,但其起伏的趋势是类似的。只有个别依存关系的标注差别较大,接下来会就这些有代表性的关系标注频率情况做一些对比分析。由于目前篇章数量较少,和大规模数据统计相比,以上数据可能会出现一些偏差。
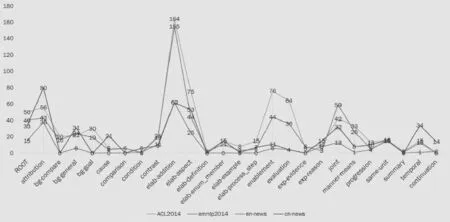
图5 篇章依存关系统计
4.1 中英文新闻标注
中文新闻来自人民网,总长度6 006字,平均长度为182字。英文新闻数据则来自华尔街见闻,全部都是经济领域,共计1 656个单词,平均长度为110个单词,且标注难度较大。
图6给出了中英文新闻上的篇章依存关系分布,其中折线图是依存关系的平均出现次数。
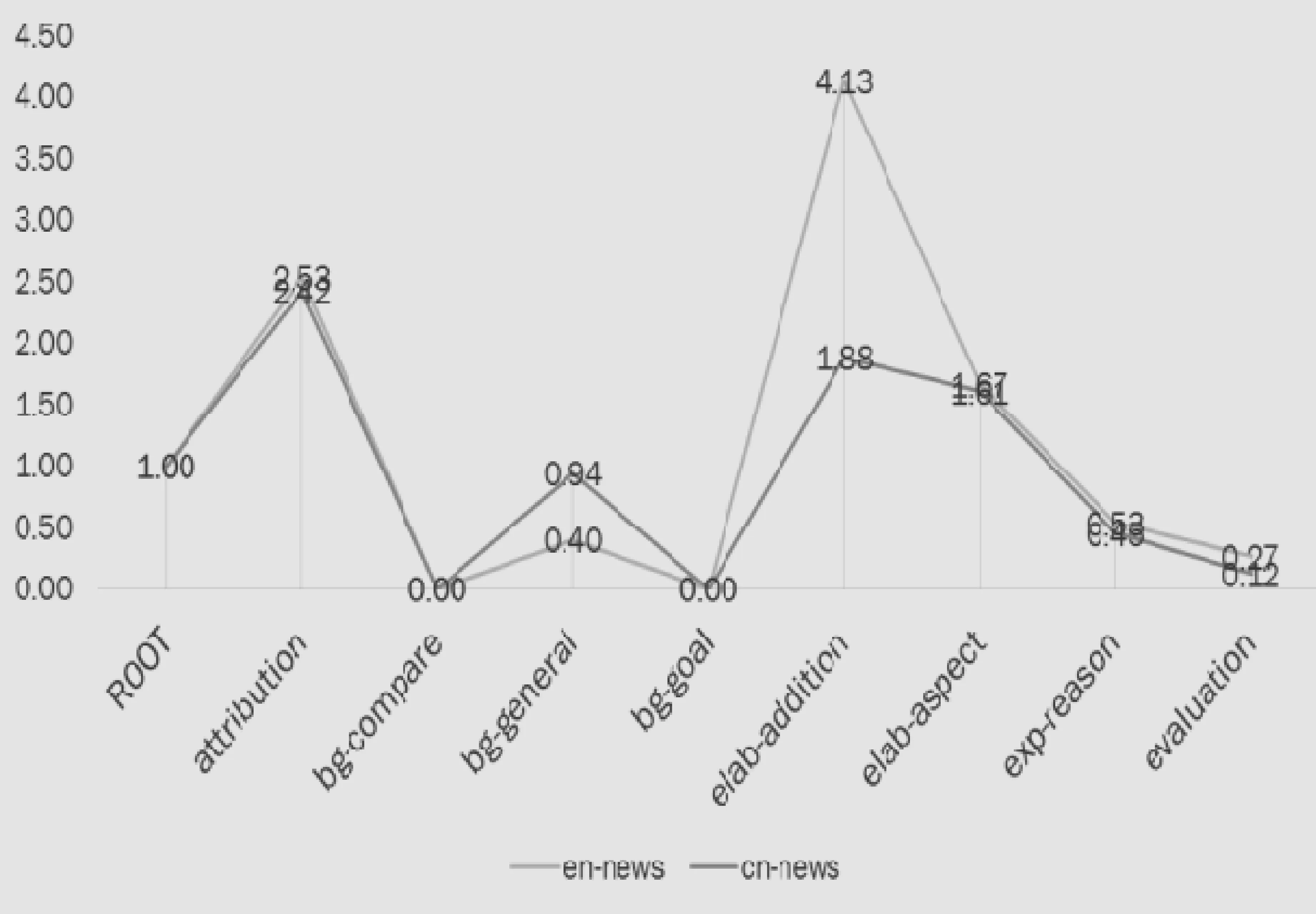
图6 中英文新闻部分篇章依存关系分布
在新闻标注中,中文新闻中一般性背景介绍的bg-general关系使用频率比英文新闻高;而英文的elaboration关系使用得较多,其中比例上更侧重于elab-addition,中文的elab-addition和elab-aspect比例较为均匀,也就是说在对核心的阐述方面,英文更倾向于深入说明,中文则更倾向于泛泛说明。对整个篇章来说,英文新闻的核心与附属单元之间联系相对更紧密。另外中英文新闻中出现了较多的attribution关系,对此我们在标注过程中也有直观感受,新闻常常会引用或者转述权威的分析、看法或者报道。
尽管使用频率有区别,但可以看到不管中文还是英文,其整体的篇章结构还是以bg-general—attribution—elaboration这样的结构为主。
4.2 英文科技文献摘要标注
英文论文摘要包括ACL2014的50篇和Emnlp2014的40篇,共计12 300个单词,平均每个文档的长度约为130个单词。
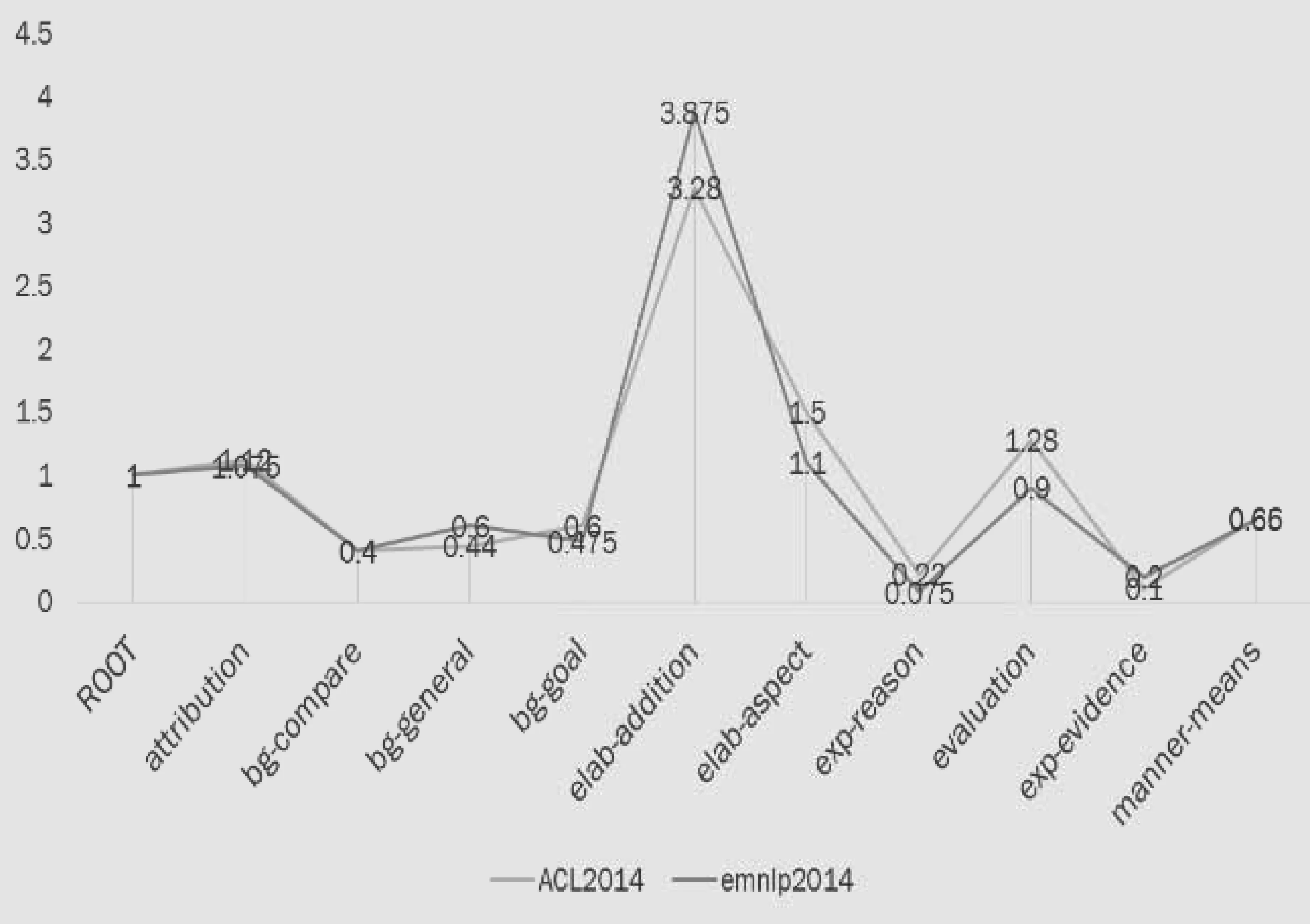
图7 中英文科技文献篇章依存关系分布
图7给出了中英文科技文献篇章依存关系的分布情况,其中折线图是依存关系的平均出现次数。可以看到这些标签的使用情况基本相同,说明英文科技文献摘要在写作上基本有比较统一的规范。其中三个背景关系使用比较平均,还可以看到大量的elab-addition关系,用于说明其算法或是方案。evaluation关系用于标示出摘要的评测部分,这些依存关系的使用情况也符合论文摘要的写作目的和要求。
4.3 新闻与科技文献摘要对比
综合考虑新闻和科技文献摘要的依存关系出现频率可以发现一些明显的区别,图8是所有科技文献摘要和中英文新闻中依存关系平均出现次数的对比。
首先是新闻中出现的attribution要远多于论文摘要,正如之前提到的,一篇新闻中常有多次转述和引用,而论文摘要的attribution多数情况下只会在evaluation部分出现一次。在科技文献中background关系的使用更为丰富,为了某种目的提出全新的方法,则用bg-goal关系;和旧方法进行比较,则用bg-compare关系,而新闻中的背景内容相对单一,主要采用bg-general关系,目的或比较的背景信息较少。我们还可以看到英文论文摘要和英文新闻的elaboration关系出现频率相当一致,而与在中文新闻中的使用存在区别,这意味着该关系的使用差别并非文体原因而是语言原因。大量的elab-addition表示解释或说明一个话题,而英文又相当依赖其从句结构。论文摘要与新闻的第一个显著区别表现在enablement和evaluation关系的频率上,科技文献摘要中告诉读者某项措施、某种方案的采用,其目的是什么,而之后基本也一定会对文献提出的方法进行一个评价或是评测,因此科技文献中对于enablement和evaluation这两种关系的使用更为频繁。
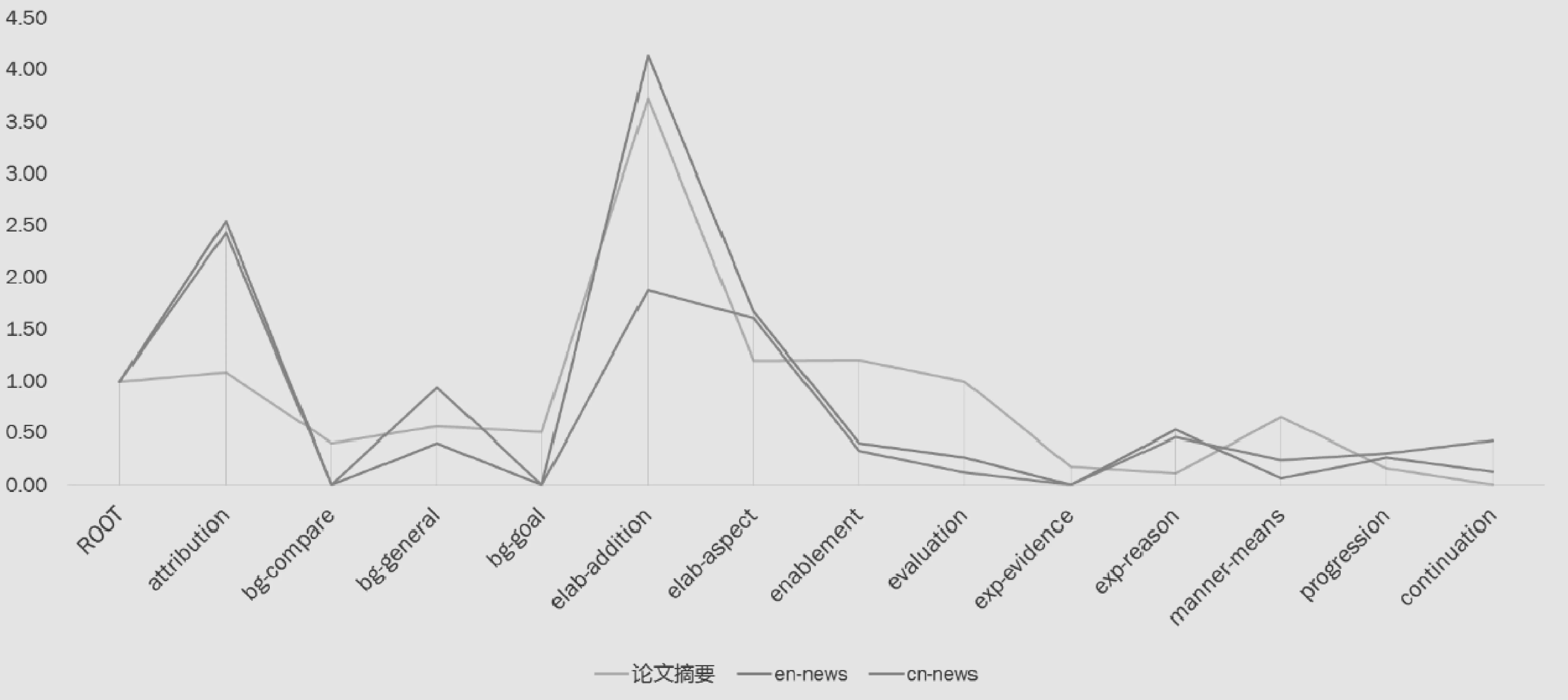
图8 新闻与论文摘要部分篇章依存关系分布
综合来说,英文科技文献摘要内容更丰富,逻辑性也比新闻更好,基本上有一个结构bg-goal/bg-compare—(elaboration—enablement)—evaluation,即大致分成三个部分: 背景,说明和评测。结合4.1节对新闻的分析来看的话,英文科技文献摘要更倾向于“线性”叙述,即围绕说明部分,说清其前因(背景)和后果(评测),中文新闻则倾向于叙述事件所涉及的多个方面。
5 结语和未来工作
本文建立了一个小规模的中英文篇章依存树库,并针对标注过程中遇到的困难进行了分析研究,给出了解决方案。其中对于多核心关系在篇章依存树中表示的问题,设立了依存关系选择的规范,采用了“自顶向下”与“自底向上”相结合的标注方法,研究了层次结构信息损失和非投射结构,对篇章单元的错误划分进行了人工修正与校对,并提高了单人标注语料的一致性。同时通过统计已构建的中英文篇章依存树库中的关系分布,简单分析中英文在科技文献摘要和新闻两个领域上的篇章现象
本文的探索,为未来篇章依存关系分析与标记的研究,指出了一些可供研究或改进的方向,其中包括: (1) 扩充语料库的篇章数及篇章平均字数。现有的语料库规模较小,得到的结果在统计学视角下意义有限。(2) 扩充语料库的种类。标注除新闻外的其他语料类型,例如书信、小说、广告、剧本等。(3)研究如何解决篇章依存树略简化的层次结构带来的层次结构信息损失。(4) 增强标注的一致性。标注数据的人员由一人改为两人或多人,相互对照与校对,提高标注的一致性与准确率。
[1]Louis A, Joshi A, Nenkova A. Discourse indicators for content selection in summarization[C]//Proceedings of SIGDIAL 2010:the 11th Annual Meeting of the Special Interest Group on Discourse and Dialogue. Tokyo, Japan: Association for Computational Linguistics, 2010: 147-156.
[2]Verberne S, Boves L, Oostdijk N, et al. Discourse-based answering of why-questions[J]. Traitement Automatique des Langues, Discours et document: traitements automatiques, 2007, 47(2): 21-41.
[3]Webber B, Stone M, Joshi A, et al. Anaphora and discourse structure[J]. Computational Linguistics, 2003, 29(4): 545-587.
[4]Prasad R, Dinesh N, Lee A, et al. The Penn Discourse TreeBank 2.0[C]//Proceedings of the International Conference on Language Resources & Evaluation.Marrakech, Morocco:LREC,2008: 2961-2968
[5]Miltsakaki E, Prasad R, Joshi A K, et al. The Penn Discourse TreeBank[C]//Proceedings of the International Conference on Language Resources & Evaluation. Lisbon,Portugal:LREC,2004.
[6]Carlson L, Marcu D, Okurowski M. Building a discourse-tagged corpus in the framework of rhetorical structure theory[J]. Sigdial Workshop on Discourse & Dialogue, 2001, 18(18):1-10.
[7]Mann W C, Thompson S A. Rhetorical structure theory: Toward a functional theory of text organization[J]. Text-Interdisciplinary Journal for the Study of Discourse, 1988, 8(3): 243-281.
[8]张牧宇, 秦兵, 刘挺. 中文篇章级关系体系及类型标注[J]. 中文信息学报, 2014, 28(2): 28-36.
[9]Li Y, Feng W, Kong F, et al. Building Chinese discourse corpus with connective-driven dependency tree structure[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar:EMNLP,2014: 2105-2114.
[10]Li S, Wang L, Cao Z, et al. Text-level discourse dependency parsing[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics(Volume 1: Long Papers). Baltimore, USA: Association for Computational Linguistics, 2014: 25-35.
[11]Polanyi L. A formal model of the structure of discourse[J]. Journal of Pragmatics, 1988, 12(5): 601-638.
[12]Grosz B J, Sidner C L. Attention, intentions, and the structure of discourse[J]. Computational Linguistics, 1986, 12(3): 175-204.
[13]屈承熹. 汉语篇章语法[M]. 潘文国,译. 北京: 北京语言大学出版社, 2006: 248-249.
[14]赵元任. 汉语口语语法[M]. 吕叔湘,译. 北京: 商务印书馆, 1979: 45-47.
[15]杨晓宇. 句子的表达重心及其与相关概念的关联[J]. 宁夏大学学报(人文社会科学版), 2015, 37(4): 8-13.
