由粗到精的哈萨克语短语结构句法分析研究
2018-04-04梁金莲古丽拉阿东别克
梁金莲,古丽拉·阿东别克
(1. 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 2. 新疆多语种信息技术实验室,新疆大学,新疆 乌鲁木齐 830046;3. 国家语言资源监测与研究少数民族语言中心哈萨克和柯尔克孜语文基地,新疆大学,新疆 乌鲁木齐 830046)
0 引言
自然语言处理过程一般包含词性分析、句法分析和语义分析。句法分析是自然语言处理的核心技术之一[1]。目前句法分析的主要方法包括基于规则的方法和基于统计的方法。基于统计的句法分析方法在处理歧义等方面有较好的效果,相对也比较灵活。基于统计的方法在自然语言处理领域已逐渐成为主流[2]方法。
目前,哈萨克语的研究已经完成了词法分析[3]的研究,进行到句法分析阶段。其中,文献[4]中提出一种规则与最大熵结合的方法对哈萨克语基本动词短语进行识别;文献[5]提出了一种基于条件随机场模型的哈萨克语的基本短语自动识别方法;文献[6]采用基于规则自动识别及人工标注的方法建立基本名词短语标注语料库,在句法分析阶段也进行了相关的研究。文献[3]中采用PCFG方法,结合自底向下的Vitrtbi算法实现一种有自学能力的哈萨克语句法分析器: 文献[7]中根据概率上下文无关文法模型和Chart算法特点,将概率引入Chart算法,提出一种PChart算法,实现一种基于PChart算法的哈萨克语句法分析器。在句法分析研究中,无论是基于统计的方法还是基于规则的方法,都不能完全解决句法分析的问题,只有将两者结合起来,才有可能最大限度地解决句法分析中存在的问题。概率上下文无关文法(probabilistic context free grammars,PCFG),是统计与规则相结合的方法。PCFG只能捕捉到句子的结构和规则,不能捕捉到上下文的信息,因此对语言的描述是粗粒度的。本文提出一种PCFG[8]与感知机相结合的方法进行句法分析。感知机在进行训练过程中,可以捕获到句子的上下文信息。利用感知机捕获到的信息,对PCFG产生的解析候选树进行重排序,进一步提高哈萨克语句法分析的效果,进而弥补PCFG的不足之处。本文提出的方法分为两个阶段,在第一阶段,采用PCFG方法,对输入的每个待解析的句子,粗略地产生20个概率最高的句子候选集,由于句子长度的差异,有些句子的最佳候选集长度小于20。在感知机训练过程中,将训练得到的参数,以及提取特征得到的特征模板,对第一阶段生成的20个最佳候选集进行重排序。将重排序的结果和PCFG得到的结果按照一定比例选取,得到解析结果,将其作为重排序的最终解析结果。实验表明,使用PCFG和感知机相结合的方法,可以得到比较理想的句法分析结果。
1 PCFG和感知机
由于PCFG句法分析不能捕捉到句子的上下文信息,消歧能力有限,而感知机可以通过自学习,捕捉到句子中的细粒度信息,可以弥补PCFG的不足。因此,本文采用PCFG和感知机相结合的方法,对哈萨克语进行句法分析。
1.1 PCFG模型
PCFG模型是句法分析中研究较广泛和充分的模型之一。它是一种统计和规则相结合的方法。CFG是获取语言中的句法规则,由非终结符、词汇表、开始字符及规则的产生式集合构成[9]。PCFG则是在此规则中增加了概率参数,通过计算概率,预测可能性最大的句法结构。
对于一个输入句子S,通过统计的方法得到解析树。其得到最优解Tbest如式(1)所示。
(1)
其中T表示候选树,P(T,S)是候选树T中所有规则的概率的乘积,如式(2)所示。
│LHSi)
(2)
通过计算句子S中所有可能的T中的概率P(T,S),选出概率最大的值。在计算概率时,需给定三个假设: 祖先无关性假设、位置不变性假设及上下文无关性假设。
1.2 感知机算法
神经网络由一个或者多个神经元组成。而一个神经元包括输入、输出和“内部处理器”。神经元从输入端接收信息,通过“内部处理器”将这些信息进行一定的处理,最后通过输出端输出。单层感知器(single layer perceptron)是最简单的神经网络。它包含输入层和输出层,而输入层和输出层是直接相连的。
康奈尔大学教授Frank Rosenblatt 1957年提出“感知机(perceptron)”,是第一个用算法来精确定义的神经网络,也是第一个具有自组织学习能力的数学模型,是目前许多新的神经网络模型的始祖。
单层感知机训练步骤如下:
第一步: 函数输出数量相等的感知机会以小的初始值开始。
第二步: 选取训练集中的一个例子作为输入,计算感知机的输出。
第三步: 对于每一个感知机,如果其结果和该例子的结果不匹配,调整初始值。
第四步: 继续采用训练集中的例子,重复输入,进行匹配,调整参数。
在本文中,重排序的训练过程及句法分析解码阶段都采用感知机算法。感知机算法[10-11]如表1所示:

表1 感知机算法

2 重排序
本文的句法分析主要分为两个阶段。第一阶段,采用PCFG的方法,为待分析的每个句子产生20个概率最高的候选解析列表。第二阶段,使用感知机重排序的方法,对第一阶段产生的20个概率最高的候选解析序列进行重排序,将两者得分按照比例相加,选出得分最高的候选树,作为句法分析最终的结果。本文中的句法分析流程如图1所示。

图1 句法分析流程图
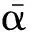
2.1 哈萨克语的20个最佳解析
在这个阶段,对于每个输入的字符串S,采用n-best解析算法[8],返回n个最高概率的解析Y(s)={y1(s),…,yn(s)},以及根据解析器产生概率模型的每个解析y的概率P(y)。本文的实验数量n为20。但是有些简单的句子,实际上得到的解析列表集少于20个。
目前哈萨克语中有10种词性标注和5种短语标注集[7],如表2所示。
对于给定的哈萨克语的句子S,通过PCFG得到20个候选集,例如,输入句子形如:
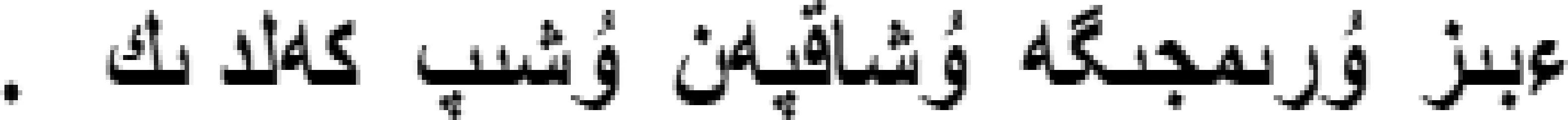
则该句子中的一个候选树如图2所示。
表2 哈萨克语标注集
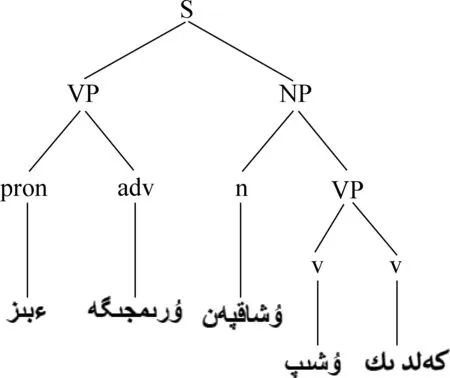
图2 哈萨克语句法树
2.2 训练
在重排序阶段,首先使用感知机算法对语料进行训练,再将PCFG阶段每个句子产生的20个候选解析树进行解码,解码的过程就是对每个节点进行重新算分,重新排序。
在用感知计算法进行训练的过程,对输入x∈χ有一个映射y∈у,在句法分析中χ是一个未处理的句子集合,у是一个χ句子中的标准句法树的集合。下面首先给出如下四个假设:
假设一: 训练样本(xi,yi),i=1,…,n
假设二: 定义函数GEN,GEN(x)是列举了输入x所有可能的句法树集合
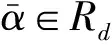
(3)
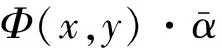
在感知机训练中需要特征模板,特征模板[8]如表3所示。

表3 感知机训练特征模板
其中,W0表示当前节点的词,Tf表示父节点的词性,Wf表示父节点的词,Wc表示子节点的词,Tc表示子节点的词性,Wb表示兄弟节点的词,Tb表示兄弟节点的词性。
2.3 重排序
在PCFG阶段,对于给定一个句子S,可以产生20个最佳解析的候选集,将这20个候选树作为感知机重排序的输入。在重排序阶段,感知机重新计算每个父节点的分数,最后将每个父节点的分数相乘,得到每个候选树的得分[13]。最终的句法分析的结果,以PCFG的结果和重排序的结果按照一定比例,选出最佳的句法分析。图3显示了一个候选树计算节点的例子。
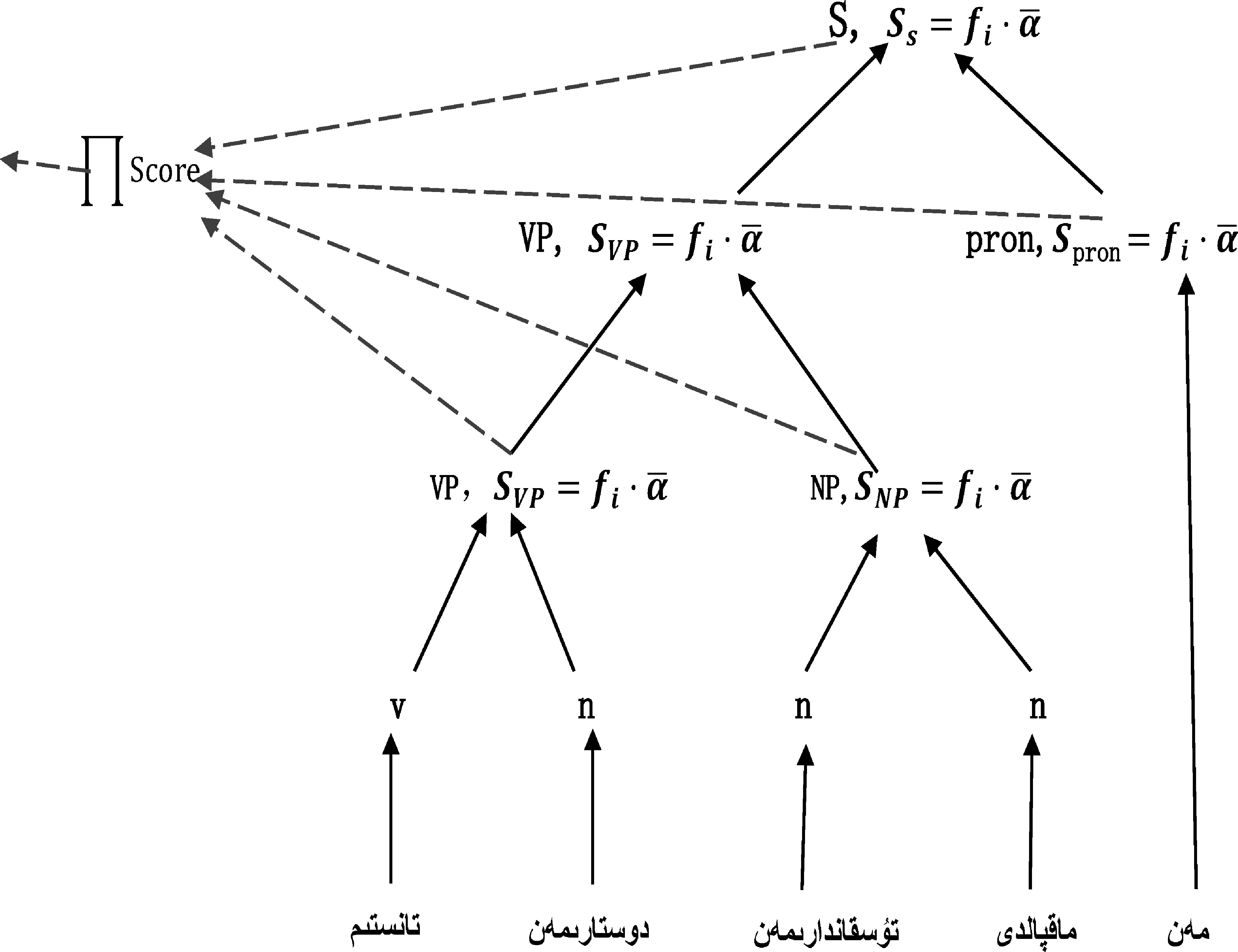
图3 感知机计算节点示意图
计算父节点得分如式(4)所示。
(4)
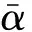
S=∑S(p)
(5)
最终的评分参考PCFG和感知机重排序之后的两者的得分,按照一定的比例求和,如式(6)所示。
S=SPCFG+t·SP
(6)
其中SPCFG是PCFG的得分,SP是感知机重排序之后的得分,t是权重系数。
3 实验
本文的数据来源于新疆中小学哈萨克语文课文。这些原始语料以短语形式标注过,例如名词短语标注为NP,动词短语标注为VP等,本语料中哈萨克语的短语标注分为五类,分别为名词短语、动词短语、形容词短语、数词短语和副词短语。
3.1 实验设置
使用的原始语料及语料中的句法树的形式,如下所示。
原始语料:
句法树形式:
(S
(..))
评价指标采用常用的PARSEVAL评价体系评测句法分析,标记正确率(labeled precision, LP)、标记召回率(labeled recall, LR)、F1 值作为评价标准。PARSEVAL 是应用比较广泛的短语结构分析器性能评价方法,标记正确率是句法分析结果中正确短语数占结果中短语总数的比例,如式(7)所示;标记召回率是句法分析结果中正确短语数占标准树中短语总数的比例,如式(8)所示;F1 值是综合正确率和召回率两者的综合指标,如式(9)所示。
3.2 实验结果
首先利用PCFG对句子进行解析。其中以一个句子的五个候选树为例进行说明,如图4所示。

图4 5个句法解析候选树
文中先用PCFG句法分析器产生最佳候选解析树,再用感知机对训练语料进行训练,并将训练得到的参数用于感知机句法重排序,重新计算PCFG句法解析器生成的候选树的总分。在感知机重排序阶段,感知机不对PCFG生成的句法结构做任何改动,仅通过训练得到的特征模板和参数对PCFG生成的句法结构的每个节点重新计算得分。在表4中显示的是由PCFG句法分析器的准确率,召回率和F1值,以及感知机重排序之后,和PCFG句法分析器的结果,按照一定比例的解析最终的句法分析的准确率(LP)、召回率(LR)和F1值。
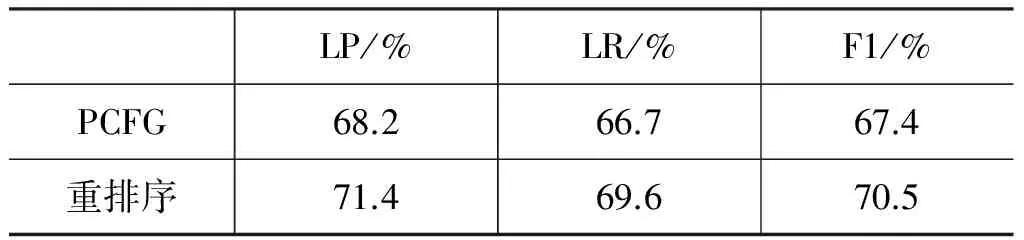
表4 句法分析实验结果
表5显示的是将测试语料根据不同的句子长度进行测试的实验结果。该文将句子长度分为三种类型,分别是长度为1~5的句子;长度为6~15句子和长度大于15的句子。
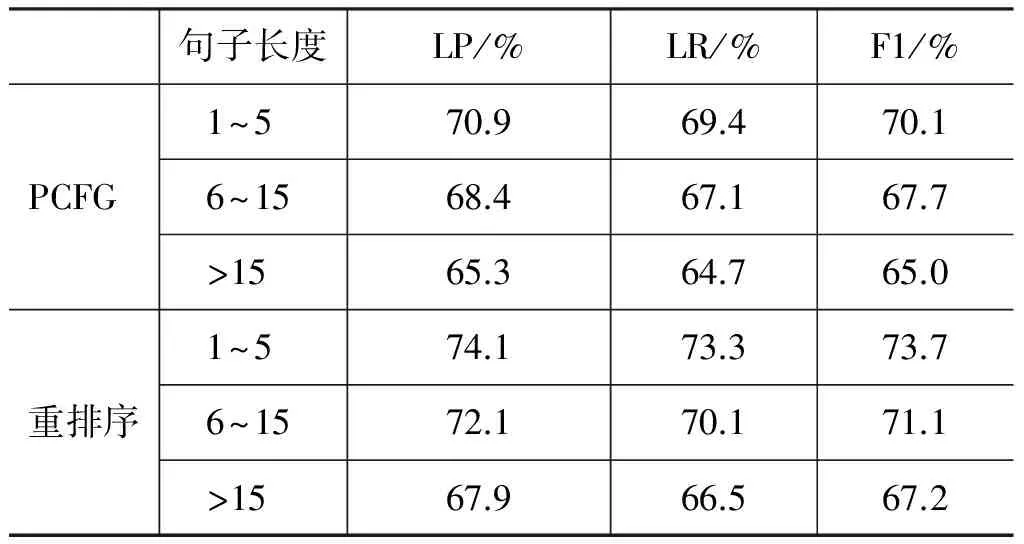
表5 不同句长实验结果
3.3 实验结果分析
从表4中的实验结果可以看出,经过感知机重排序之后的句法分析,相比较单一的使用PCFG句法分析器,句法分析的结果有所提高,准确率提高3.2%,主要原因是PCFG对句法解析的过程是粗粒度的,不能捕捉到上下文的信息,因此在句法解析的过程中,捕捉不到上下文的信息;其次,PCFG在进行句法解析的过程中,还需要句法规则,因此对语料的规模要求较高,以上因素导致基于PCFG的句法分析结果不够理想。从表5中的实验结果可以看出,句长为1~5的实验结果显示,重排序之后准确率提高3.2%;句长为6~15重排序之后准确率提高3.7%;句长大于15重排序之后准确率提高2.6%。主要原因在于,较短的句子,句法结构不是特别规范,较长的句子结构较复杂。因此,句子结构较完整又较规范的句子效果最好。
由实验结果可以明显地看出,重排序的句法分析结果比PCFG效果要好,但在句法解析结果中,仍有些句法解析的结果不够理想,主要原因如下:
(1) 在PCFG解析过程中,有些句子并没有匹配正确的规则,因此产生的候选树的结果并不是特别理想。
(2) 有些句子的结构比较难,有些句子的结构不是严格的按照句法规则,PCFG在进行句法解析的过程中存在一定的难度。
4 结束语
本文描述了由粗到精的哈萨克语短语结构句法分析。主要由PCFG解析器对每个待分析的句子进行解析,生成20个最佳候选树,然后由感知机进行训练得到参数以及特征模板,再对生成的20个最佳候选树进行重排序。PCFG对语言的描述是粗粒度的,该文的重排序的方法是细粒度的,弥补了其不能捕捉到上下文信息的不足。在PCFG进行句法解析的过程当中,需要大量的语料,以及需要的语料题材多样性,因此,之后的工作之一是对语料以及语料题材进一步扩大。语言是复杂的,在感知机训练阶段,重排序过程当中,使用相同的参数,并没有将语言的特性很好的表现出来,在后续的重排序的的过程当中,可以考虑使用不同的参数,结合每个结点的信息,进行参数训练,对生成的候选句法树进行重排序。
[1]吴伟成, 周俊生, 曲维光. 基于统计学习模型的句法分析方法综述[J]. 中文信息学报, 2013, 27(3): 9-19.
[2]刘挺, 马金山. 汉语自动句法分析的理论与方法[J]. 当代语言学, 2009(2): 100-112.
[3]尚文清, 古丽拉·阿东别克, 牛娜,等. 基于PCFG模型的哈萨克语句法分析[J]. 现代计算机(专业版), 2015(5): 7-10.
[4]古丽扎达·海沙, 古丽拉·阿东别克. 哈萨克语动词短语自动识别研究与实现[J]. 计算机工程与应用, 2015, 51(2): 218-223.
[5]汪泱, 古丽拉·阿东别克, 户冰心,等. 基于条件随机场的哈萨克语基本短语自动识别[J]. 计算机工程与设计, 2014(10): 3602-3607.
[6]孙瑞娜, 古丽拉·阿东别克. 哈萨克语基本名词短语自动识别研究与实现[J]. 中文信息学报, 2010, 24(6): 114-119.
[7]尚文清, 古丽拉·阿东别克, 牛娜,等. 基于PChart算法的哈萨克语句法分析[J]. 计算机工程与设计, 2016, 37(3): 832-836.
[8]Charniak E, Johnson M. Coarse-to-fine n -best parsing and MaxEnt discriminative reranking[C]//Proceedings of the ACL 2005, Meeting of the Association for Computational Linguistics, Proceedings of the Conference, 25-30 June 2005, University of Michigan, USA. DBLP, 2005: 173-180.
[9]Kasami T. An efficient recognition and syntax-analysis algorithm for context-free languages[J], 1966.
[10]Collins M, Roark B. Incremental parsing with the perceptron algorithm[C]//Proceedings of the Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2004: 111.
[11]Martí, Nez C, Prodinger H. Discriminative Training Methods for Hidden Markov Models: Theory and Experiments with Perceptron Algorithms[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2002: 1-8.
[12]Charniak E. A maximum-entropy-inspired parser[C]//Proceedings of the 1st North American Chapter of the Association for Computational Linguistics Conference. Association for Computational Linguistics, 2000: 132-139.
[13]Socher R, Bauer J, Manning C D, et al. Parsing with Compositional Vector Grammars[C]//Proceedings of the ACL (1). 2013: 455-465.
