基于关联分析的Webshell检测方法研究
2018-04-02周颖胡勇
周 颖 胡 勇
(四川大学电子信息学院 成都 610065) (304941296@qq.com)
根据2017年Trustwave《2017全球安全报告》显示,99.7%的Web应用都有安全漏洞[1].Webshell以动态脚本形式存在,攻击者可以利用检测到的安全漏洞将其上传到受到威胁的Web服务器,以便远程执行任意命令,获取并提升管理权限[2],达到渗透入侵的目的.为逃避检测,经常对其加密混淆处理,使得Webshell的形式灵活多变,然而大多数安全产品仅通过建立恶意代码集合特征,基于特征匹配的方法实现检测,这会出现覆盖不全、准确率降低等问题.因此,本文针对Webshell特征混淆技术将统计学检测结果的数值作为样本特征,提出基于关联分析的Webshell检测方法,建立特征频繁项集获得关联规则,利用算法实现检测并提高准确率.
1 相关工作
Webshell的运作流程可理解为入侵者通过浏览器以HTTP协议访问Web服务器上的接口文件.根据攻击者编写恶意代码从一句话Webshel到可实现数据库操作、文件上传下载等功能型Webshell,可从恶意代码量和其实现功能性实现检测.文献[3]通过选取页面结构特征和文本特征利用SVM分类方法实现检测,该方法在检测未变异处理的Webshell上有较高的检测率,但由于特征选取仅仅只针对前端页面代码特征,对功能型或混淆后的Webshell的检测率有待验证;文献[4]通过提取Webshell脚本文本特征和部分操作函数调用特征,采用矩阵分解模型量化特征值,获得相应的评分矩阵与待检测矩阵实现检测,能一定概率完成对未知页面的预测,但检测中选取的特征过多,在数据处理时存在过拟合情况,影响检测结果,并且仅从文本上取特征对混淆后的Webshell检测准确率低.因此,本文针对Webshell的混淆性采用多种统计学特征作为检测样本特征,提出基于关联分析的Webshell检测模型,能快速建立特征库并有效检测混淆技术处理后的Webshell,在降低成本的同时提高检测的效率和准确率.
1.1 Webshell特征混淆技术
目前,Webshell检测工具还是以特征匹配扫描方式为主,这不仅依赖特征库建立是否全面可靠,而且不能有效检测各种特征混淆方法隐藏处理后的Webshell.因此,需针对Webshell特征混淆技术采取相应的对策,有效提取其特征数据.Webshell主要有以下几种混淆特征的方法[5]:
1) 使用加解密技术.对Webshell中的特征数据预先进行加密,待执行时再动态解密,加密后的参数一般比正常参数长度更长,因此可从加解密函数以及参数特征进行检测.
2) 无用信息插入.例如在PHP编写环境中插入注释不影响代码正常执行但会影响查杀,因此在处理此类特征提取时,应去掉类似注释等无用信息以减小干扰.
3) 字符串连接技术.功能型Webshell执行调用后台系统组件时,可通过拆分组件名称、在字符串中插入或替换特殊字符等方式来避免被检测到调用相关组件.因此,可预先对调用组件、函数和字符处理相关函数进行检测.
4) 化整为散技术.关键函数或参数过于集中时特征表现明显,易被检测.但若将完整页面拆分,降低关键函数参数的集中出现频次,再用如include包含指令整合,则可逃避检测.因此,检测该类Webshell时,需载入页面相关文件后再检测.
5) 多重编码技术.类似于代码加密,通过自定义函数加密、多次编码特征数据实现混淆干扰.因此对于此类恶意样本需先多次解码后再检测.
1.2 Webshell特征提取
针对Webshell的混淆技术,本文就混淆后的Webshell提取以下特征[6]进行检测:
1) 重合指数
重合指数可用于衡量文件代码是否被加密或混淆过,通常Webshell在使用加密混淆技术后变得杂乱,从脚本代码上看,Webshell也常包含二进制或者十六进制序列,因此计算混淆后的文件中扩展ASCII码(254个字符)的重合指数,指数值越低,是Webshell的可能性越大.若设一个长度为n的密文字符串X中,2个随机元素相同概率为
(1)
其中,i为任意字符,Z为字符种类数,P即为该密文字符的重合指数.
2) 信息熵
通过使用ASCII码表衡量文件的不确定性.编码变形后,Webshell含有大量特殊字符、随机内容等会产生更多的ASCII码,此时计算得到的熵值比正常样本大,并可衡量Webshell区别于正常文件的不确定性.信息熵计算公式如下:
(2)
(3)
其中,n为ASCII码,且不等于127(127为空格字符,没有实际意义,不纳入计算),Xn为第n位ASCII码在该文件中出现的次数,S为总字符数.
3) 最长字符串
最长字符串为文件中最长不间断的字符串.经过Webshell伪造处理后的代码可生成无空格间断的长字符串,这明显有别于正常编码存储方式,因此,一般样本文件中含有特别长的字符串时可作为检测特征之一.
4) 文件压缩比
文件压缩比为压缩后文件大小与原始文件大小之比.实质在于消除特定字符的分配不均,经编码后的Webshell消除了非编码字符,表现为更小的分布不均衡,此时的压缩比的值大于正常文件.
5) 基于特征库匹配
参考主流特征库匹配检测如eval,exec等常用函数、已知特征码等,选用准确性和实用性较高的几种.目前使用较多的D盾[7]通过恶意字符串特征库进行特征匹配检测Webshell;河马Webshell[8]通过结合传统特征库和云端大数据双引擎查杀技术实现检测.
2 基于关联分析的Webshell检测模型
基于关联分析的检测模型是一种无监督的机器学习过程,最早是由Agrawal等人[9-10]提出,通过分析数据集,挖掘出所选特征潜在的关联规则.通过对已标记样本数据学习,设定项集的支持度、置信度得到关联规则,数据库中包含(支持)项集的事务的数目称为项集X的支持度计数,记为
σ(X)=|{ti|X⊆ti,ti∈T}|,
(4)
其中,T为事务的集,ti为某个特定项集,用于衡量关联规则在整个数据集中统计的重要性;关联规则X→Y的置信度代表Y在包含X的事务中出现的频繁程度为
(5)
用于衡量关联规则的可信度.
基于关联分析的检测模型如图1所示:

图1 Webshell检测模型框架
首先收集获取数据样本,针对样本Webshell的混淆技术采用上述5类特征进行提取,并生成相应的特征库;然后采用关联分析中的Apriori算法和FP-Growth算法训练样本;最后使用该分类器对混淆后的Webshell进行分类生成相应的关联规则,并输出检测结果.
2.1 Apriori算法
Apriori算法是一种同时满足最小支持度阈值和最小置信度阈值的关联规则挖掘算法.Apriori算法使用频繁项集的先验知识,通过逐层搜索的迭代方法探索项集度.在Webshell的检测中,可以通过关联分析得到多个特征结果的关联规则,避免某一个检测结果对检测的误判或遗漏.由于各特征值都表明了一个检测样本为Webshell的可能性,而关联分析法无法直接对数值进行分类,因此编写Java程序对选取的特征的数值进行定义描述,根据特征结果划分描述范围,使得数值集中的特征在同一类描述中,对训练样本和测试样本的数据按照同样的标准进行分组.Apriori算法通过扫描事务记录会找出所有频繁项集,并记为第1类,再利用第1类项集根据设置的支持度筛选出满足要求的其他4类集合的项集.在这个过程中不断获取新的数据集合,并重新扫描计数,直到不能再找出任何频繁项集为止.最后根据找出的所有频繁项集得到符合要求的强规则度,即为检测Webshell的关联规则.本文利用求得的关联规则,判断被检测文件是否为Webshell.
2.2 FP-Growth算法
在Apriori算法中一个较为明显的缺陷在于对每个潜在的频繁项集都会扫描数据集判定并重新计数[11],Han等人[12]提出的FP-Growth算法基于Apriori算法,采用构建FP树,并从FP树中挖掘频繁项集,大大减少扫描次数,提高算法速度.本文为对比这2种算法运行速率,还采用FP-Growth算法将相同样本存储在称为FP树的紧凑数据结构中,FP代表频繁模式,通过链接来连接相关联的特征,被连接起的元素看成一个链表.在FP树中,一个元素项可在一棵树中出现多次,在FP树中存储项集出现的频率,即在检测中记录单个特征出现的频次并与另一特征相关联,出现相似元素集合时则共享树的一部分,完全不同时树出现分叉,最终通过训练学习获得Webshell的FP检测结构树,树中存储符合阈值的关联规则.本文将用这2种关联分析方法实现对Webshell的检测,并选取相同样本对2种算法进行对比.
3 仿真实验
3.1 特征提取及参数选择
Webshell一般有ASP,PHP,JSP等网页文件形式,由于编写相似且实现功能类似,对应的检测模型也一致,故选择使用率较高的开发语言PHP编写的Webshell脚本作为实验数据.本文搜集了465个恶意PHPWebshell样本和968个正常PHP页面样本作为本次实验数据,把搜集到的所有样本分为5份,任选4份进行机器学习,并检测余下样本,根据平均结果评估模型的检测能力.
本文使用开源工具NeoPI[13]量化每个样本特征,表1列出样本中部分Webshell量化值.
由于利用Weka采用关联分析对样本进行样本数据处理时,算法无法直接对数值进行处理分析,需对数值进行定义描述,因此本文将5种特征值的大小分别按高、中、低3类进行定义描述,表2列出Webshell样本在特征描述对应的数值范围.
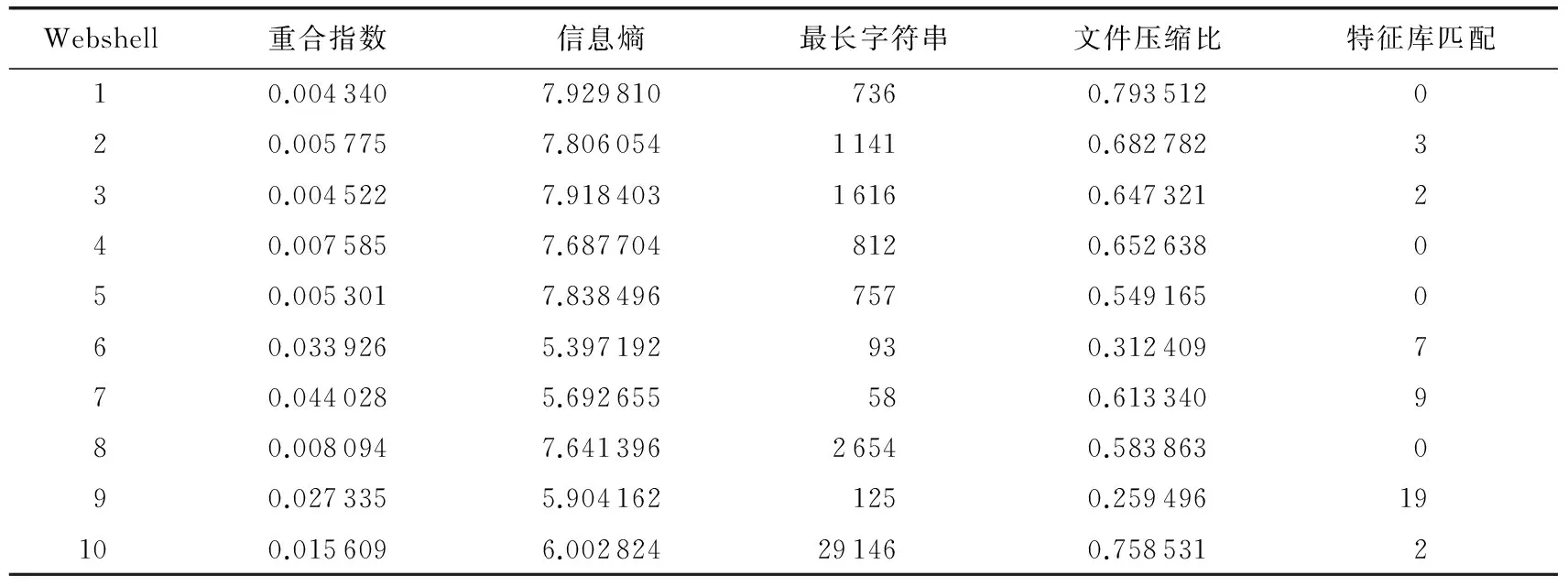
表1 部分Webshell特征量化值
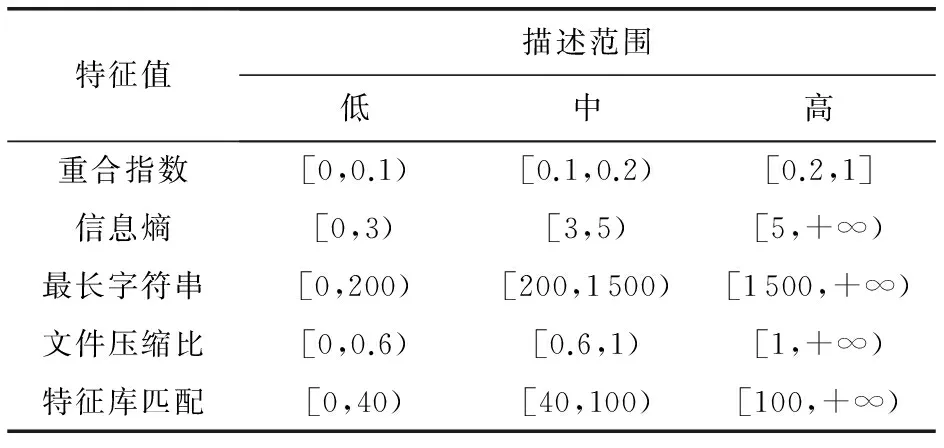
表2 Webshell样本特征值范围定义描述
3.2 算法比较
为了测试2种关联分析法的性能,实验从数据集中提取同样数量的样本数,分别用Apriori算法和FP-Growth算法生成相应的检测规则,从生成检测规则的时间和正确率进行比较,结果如表3所示.从表3可以看出,在处理相同样本数据的情况下,2种算法在检测正确率方面相差不大,但在生成规则时间上FP-Growth算法有明显的提升,体现了其在频繁集上的优化.

表3 Apriori算法和FP-Growth算法的比较结果
3.3 实验结果及分析
为了更准确地评估关联分析法检测的准确率,本文还采用准确率、召回率、F值评测[14]进行评估.准确率是指正确检测出Webshell的数量占所有检测样本的比例;召回率是指正确检测出Webshell数量占所有Webshell数量的比例.对应的结果分类情况如表4所示:

表4 预测结果分类
具体计算公式如下:0代表False(Negative),1代表True(Negative),TN代表实际结果为True但预测结果为Negative.预测的准确度为
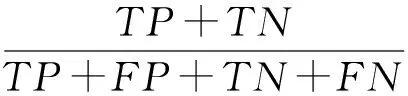
(6)
召回率为
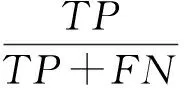
(7)
F值为
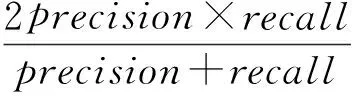
(8)
显然准确率、召回率、F值越高检测结果越好.
将处理好的样本与机器学习工具Weka3.8进行实验,选择相应的算法规则与现有的2种检测工具的准确率进行对比,实验结果如表5所示:
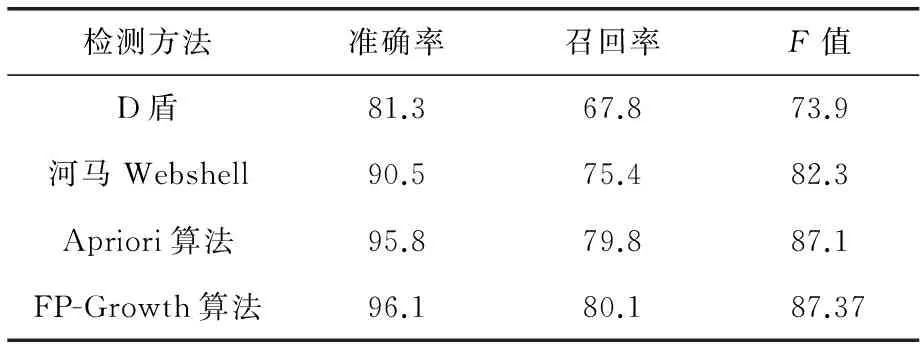
表5 Webshell的准确率、召回率及F值预测结果 %
从实验结果可以看出,关联分析法在准确率、召回率、F值评测的结果较其他2种检测工具更好,说明利用该方法进行Webshell的检测是有效的.
4 结 语
本文针对Webshell特征混淆,采用关联分析法对Webshell进行检测,可以准确快速地检测出恶意Webshell,并通过在同类检测工具的分析比较中表现出了较好的性能.但由于样本选取数量有限,在2种关联方法生成关联规则的效率上对比不够明显,同时还应考虑训练样本数量的增加对算法模型生成速度也有一定的影响,在机器学习算法上可以对关联分类候选频繁项集进行筛选,减少频繁项集生成遍历次数,也可以缩小待扫描集合范围,降低算法时间复杂度,提升检测模型的性能,并且仅依靠样本数据和自身数据的建立不能满足新的防护要求,需要进一步研究有关检测的优化方法.
[1]Trustwava. 2017 Trustwave Global Security Report[EBOL]. 2017 [2018-02-15]. https:www.trustware.comResourcesLibraryDocuments2017Trustware-Global-Securiby-Report
[2]Starov O, Dahse J, Ahmad S S, et al. No honor among thieves: A large-scale analysis of malicious Web shells[C]Proc of Int Conf on World Wide Web. 2016: 1021-1032
[3]叶飞, 龚俭, 杨望. 基于支持向量机的Webshell黑盒检测[J]. 南京航空航天大学学报, 2015, 47(6): 924-930
[4]Dai H, Dai H, Dai H. A matrix decomposition based Webshell detection method[C]Proc of Int Conf on Cryptography, Security and Privacy. New York: ACM, 2017: 66-70
[5]潘杰. 基于机器学习的Webshell检测关键技术研究[D]. 天津: 中国民航大学计算机学院, 2015: 16-17
[6]马艳发. 基于WAF入侵检测和变异WebShell检测算法的Web安全研究[D]. 天津: 天津理工大学, 2016: 13-15
[7]D盾. D盾_Web查杀[EBOL]. [2018-02-15]. http:www.d99net.net
[8]河马Webshell. Webshell.pub[EBOL].[2018-02-15]. http:www.webshell.pub
[9]Agrawal R, Srikant R. Fast algorithms for mining association rules in large databases[C]Proc of Int Conf on Very Large Data Bases. San Francisco: Morgan Kaufmann, 1994: 487-499
[10]Agrawal R, Imieliński T, Swami A. Mining assocation rules between sets of items in large databases[J]. AcmSigmod Record, 1993, 22(2): 207-216
[11]王文槿, 刘宝旭. 一种基于关联规则挖掘的入侵检测系统[J]. 核电子学与探测技术, 2015, 35(2): 119-123
[12]Han J, Pei J, Yin Y. Mining frequent patterns without candidate generation[J]. ACM SIGMOD Record, 1999, 29(2): 1-12
[13]NeoPI: Detection of Webshells using statistical methods[EBOL]. (2014-09-18) [2018-02-15]. https:github.comNeoPI
[14]李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012

周颖
硕士研究生,主要研究方向为Web安全.
304941296@qq.com

胡勇
副教授,硕士生导师,主要研究方向为信息系统安全.
huyong@scu.edu.cn
