基于深度信念网络的猪咳嗽声识别
2018-04-02雷明刚刘望宏龚永杰
黎 煊 赵 建 高 云 雷明刚 刘望宏 龚永杰
(1.华中农业大学工学院, 武汉 430070; 2.生猪健康养殖协同创新中心, 武汉 430070;3.华中农业大学动物科技学院动物医学院, 武汉 430070)
0 引言
近年来,国家着力转变生猪产业经济发展方式,引导生猪产业向规模化、集约化、标准化饲养方向发展。生猪产业规模化发展的同时,呼吸道疾病已成为各大养猪场最常见、危害最严重的疾病之一。而咳嗽是猪呼吸道疾病的主要症状,尤其是早期症状,因此可以通过监测咳嗽声进行猪早期呼吸道疾病预警[1-3]。目前所采用的方法一般为简单易行的人工检测,但是人工检测不仅人力成本高,并且识别率难以得到保证。随着现代信息、数字信号处理、传感器等技术的快速发展,将计算机技术与声音特征分析相结合,利用语音识别技术分析猪咳嗽声与猪非咳嗽声,对猪咳嗽声进行识别,有利于生猪呼吸道疾病的预警,促进生猪健康养殖的发展[4]。

图1 猪场环境噪声分析Fig.1 Analysis of environmental noise in pig farms
国外开展猪声音识别的研究相对较早。MITCHELL等[2]发现了健康猪和病猪咳嗽声短时能量动态变化的差异,测得健康猪咳嗽声持续时间一般为0.21 s,而病猪咳嗽声持续时间一般为0.3 s。SARA等[3]通过实验发现,病猪咳嗽音频的标准化压力均方差及峰值频率均值均低于健康猪,而病猪咳嗽声持续时间和频率均高于健康猪。EXADAKTYLOS等[5]采用改进的模糊c均值聚类算法识别猪咳嗽,总识别率达到85%,其中病猪咳嗽声识别率达到82%。GUARINO等[6]采用动态时间规整(Dynamic time warping,DTW)算法识别猪咳嗽,识别率达到85.5%,非咳嗽声识别率达到86.6%。HIRTUM等[7]考虑低频环境噪声对咳嗽声的影响,建立环境噪声模型,在此基础上构建基于模糊c均值聚类算法的咳嗽声识别模型,非实时单个咳嗽声识别率能够达到92%,但错误率达到21%。
目前,国内针对猪声音识别的研究尚处于起步阶段。马辉栋等[8]设计了基于短时能量和短时过零率的猪咳嗽声双门限端点检测算法。刘振宇等[9]采用隐马尔科夫模型(Hidden markov model,HMM)对猪咳嗽声进行识别,识别率达到80%。徐亚妮等[10]利用模糊c均值聚类算法进行猪咳嗽声与尖叫声识别,识别率分别达到83.4%和83.1%。
深度信念网络(Deep belief nets, DBN)由HINTON等[11]于2006年提出,DBN通过对人脑组织结构和功能的模拟,有着与人类类似的记忆能力、概括推理能力以及强大的分类、预测能力[12]。最近几年来,深度学习在语音识别领域得到了很好的应用,体现了其强大的声学建模能力[13-15]。本文把深度信念网络引入猪声音识别领域,以长白猪咳嗽、打喷嚏、吃食、尖叫、哼哼、甩耳朵等声音为研究对象,构建猪咳嗽声识别模型,为生猪健康养殖过程中猪咳嗽声的识别提供一种新方法。
1 猪声音采集与预处理
1.1 猪声音采集
猪声音采集在校属精品猪场进行。采集工具为美博-M66录音笔,采样频率为48 000 Hz,采样精度为16位,可连续录音24 h。声音采集在3—4月猪病多发期进行,共采集10头75 kg左右长白猪的声音,经兽医诊断10头猪中5头猪感染呼吸道疾病,咳嗽明显。采用专家分类法对录音笔采集的猪声音进行分类标记,选取咳嗽、打喷嚏、吃食、尖叫、哼哼和甩耳朵声作为研究对象。得到猪声音样本1 400个,其中咳嗽样本594个,打喷嚏样本241个,吃食样本152个,尖叫样本130个,哼哼样本125个,甩耳朵样本158个,保存为wav格式。
1.2 猪声音预处理
猪场环境下采集到的猪声音样本包含很多噪声和无效声音,为提高猪咳嗽声与非咳嗽声识别率,在特征参数提取之前需要进行去噪和端点检测。
1.2.1猪声音样本噪声分析
从图1b和图1d可以看出,猪场环境噪声频段主要集中在5 kHz以下,并且与猪咳嗽声频段(0.3~8 kHz)[8]有重叠,传统数字滤波器(低通、高通或带通)难以对猪声音样本进行有效去噪,本文采用基于多窗谱的心理声学语音增强算法对猪声音样本实现去噪。
1.2.2基于多窗谱的心理声学语音增强
多窗谱即对待估计猪声音样本序列加多个相互正交的窗,分别计算频谱,然后求平均的非参数谱估计方法。人耳掩蔽阈值的心理声学约束可以对带噪猪声音信号中噪声失真进行限制[16-17]。
通过原始猪声音样本的多窗谱估计原始猪声音样本中噪声与含噪信号之比(即先验信噪比倒数),用基于噪声与含噪信号之比的幅度谱减法得到预估计猪声音信号,通过预估计猪声音信号计算隐蔽阈值,用心理声学算法得到去噪后的猪声音信号。
图2所示为基于多窗谱的心理声学语音增强算法处理前后猪声音样本波形图,对比语音增强前后波形图可知,语音增强后猪声音样本噪声明显减少,声音信号波形几乎没有发生失真。

图2 猪声音样本滤波前后对比Fig.2 Comparison of original pig sounds and sounds after denoising
1.2.3单参数双门限端点检测
语音信号端点检测是指从包含语音的一段信号中找出语音的起止点,把起止点之间的信号定义为有效信号。猪声音样本经过语音增强后,噪声显著减少,本文选择基于短时能量的方法进行猪声音样本端点检测[18]。对猪声音样本y(n),分帧后第v帧表示为yv(n),此帧猪声音信号的短时能量Ev计算公式为
(1)
式中L——帧长,根据声音信号的短时平稳特性取为200个采样点
n——猪声音样本采样点序号
基于短时能量的单参数双门限端点检测中,单参数是幅值归一化后的短时能量ev,计算公式为
(2)
式中V——猪声音样本总帧数
设定2个阈值T1和T2,其公式为
T1=1.5max(e1,e2,…,eFINS)
(3)
T2=1.1max(e1,e2,…,eFINS)
(4)
式中FINS——猪声音样本前导无话段帧长
eFINS——第FINS帧幅值归一化后的能量
由式(3)和式(4)计算得到T1、T2分别约为0.02、0.008。当ev高于T1时判定为语音帧,低于或高于T2时确定为猪声音样本起止点。图3所示为单参数双门限端点检测对应的猪声音样本检测结果。从图3可知,基于短时能量的端点检测可以较好地检测出有效信号。
2 基于时间规整算法的猪声音特征参数提取
2.1 时间规整算法
由图3可知,经过端点检测后的猪声音信号长度不同,而一个结构确定的神经网络输入层神经元个数也是确定的,因此需要运用时间规整算法[19]将预处理后的猪声音样本规整为同一长度再进行特征参数提取。

图3 猪声音样本端点检测结果Fig.3 End point detection of pig sound

图4 时间规整网络结构图Fig.4 Structure diagram of time warping net
时间规整网络结构如图4所示,对于一个有V帧的猪声音样本,规整网络输入层有V个节点,第v个节点对应猪声音样本第v帧的特征矢量A0,v(v=1,2,…,V)。规整至第l层后将距离最近的2个特征矢量以加权平均合并,其余特征矢量不变,第l层就具有V-l个节点以及与之联系的V-l个矢量Al,v(v=1,2,…,V-l)。以此类推,经过V-N步合并,最终网络输出层具有N个节点以及与之联系的N个特征矢量AV-N,v(v=1,2,…,N)。
2.2 短时能量特征参数提取
由图2可知,不同种类猪声音的波形不同,为了反映这一区别,利用式(1)计算出猪声音信号的短时能量,6种猪声音信号的短时能量变化情况如图5所示。不同种类猪声音持续时间不同,同种猪声音持续时间也不完全相等。本文研究的6种猪声音中咳嗽、打喷嚏持续时间一般在0.4 s左右,而吃食、尖叫、哼哼和甩耳朵持续时间在0.6~1.4 s不等。为了进行统一衡量,可采用时间规整算法将所有猪声音样本规整到300帧组成的一个300维的短时能量特征参数数组。
V帧猪声音信号对应采样点数NV的计算公式为
NV=(V-1)Linc+L
(5)
式中Linc——帧移,取为帧长L的40%
NV采样点对应时长Δt的计算公式为
Δt=NV/Fs
(6)
式中Fs——采样频率
由式(5)可以计算出300帧对应采样点数NV为24 120,进一步由式(6)得到对应时间长度Δt为0.502 5 s。时间规整为300帧(即约0.5 s)后6种猪声音样本短时能量分布如图5所示。
对比时间规整前后猪声音短时能量变化图可知,猪咳嗽声和打喷嚏声短时能量波形图在0.4~0.5 s部分相对其他种类猪声音能量低,造成特征数组后面部分值相对较小。基于时间规整的短时能量特征参数可以同时反映不同种类猪声音信号短时能量动态变化的差异和不同种类猪声音信号持续时间的差异性。
2.3 梅尔频率倒谱系数特征参数提取
梅尔频率倒谱系数(Mel frequency cepstral coefficients,MFCC)的分析是基于人耳的听觉机理,依据人的听觉实验结果来分析声音的频谱特性[20-21]。将声音在频域上划分成若干频率群,选择梅尔频率滤波器组为24组。图6a所示为猪咳嗽声样本MFCC三维图,对于一个300帧的猪咳嗽样本,24维的MFCC数据量是比较大的,可以采用时间规整算法将300帧的MFCC规整到30帧组成720维的MFCC特征向量。图6b所示为时间规整后猪咳嗽声MFCC三维图。
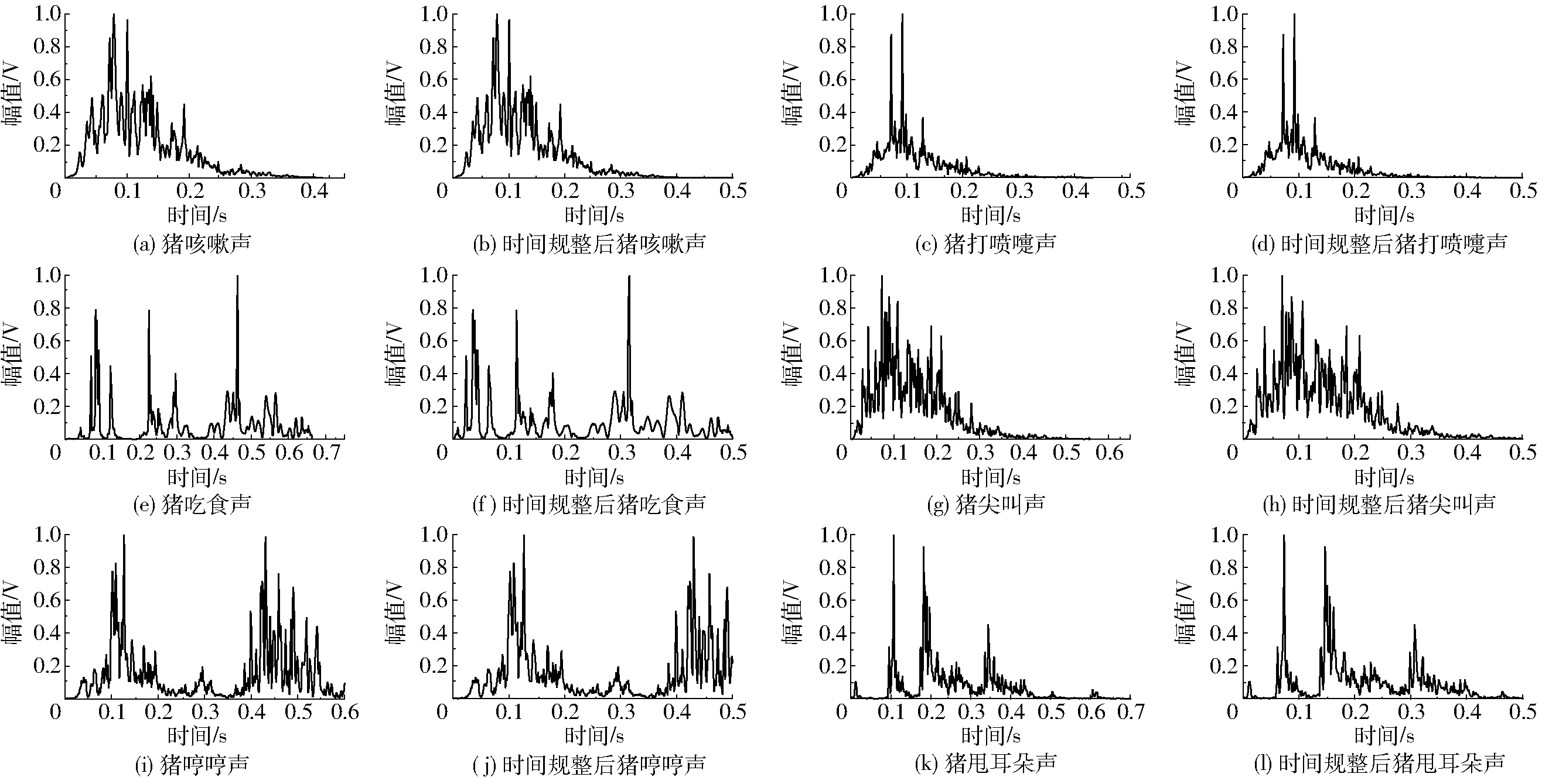
图5 猪声音样本短时能量时间规整前后对比Fig.5 Comparison of short-time energy of pig sound and sound after time warping

图6 猪咳嗽声的MFCC图Fig.6 MFCC of pig cough
由猪咳嗽样本MFCC时间规整前后三维图可知,图6b相对图6a帧数从300帧减少到30帧,数据量大大减少。同时,图6b也保留了图6a在时序上的动态变化特性。
3 猪咳嗽声识别
3.1 深度信念网络猪咳嗽声识别模型
深度信念网络是由多层受限玻尔兹曼机(Restricted boltzmann machine, RBM)堆叠而成的网络模型[11]。RBM是一个由两层神经元组成的层间全连接、层内无连接的网络结构,显层为输入层,隐层为特征提取层。其结构如图7所示。
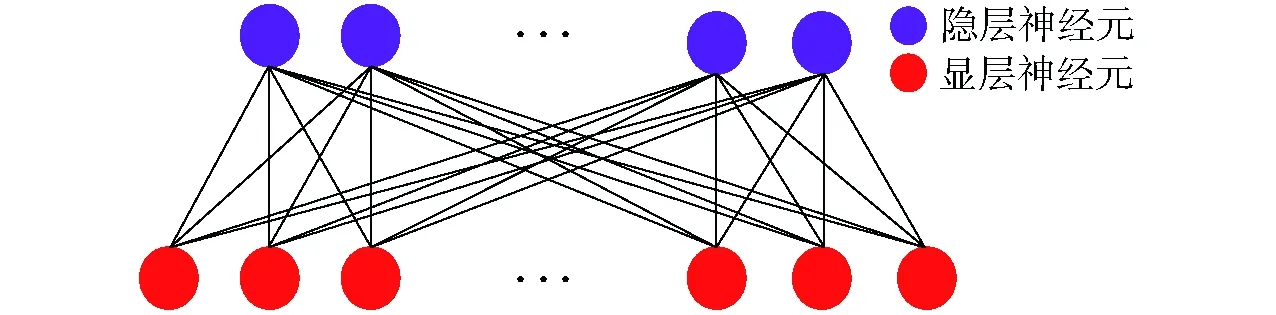
图7 受限玻尔兹曼机网络结构Fig.7 Structure of RBM
RBM中神经元通常只取0或1两种状态,状态0表示神经元处于抑制状态,状态1表示神经元处于激活状态。令向量s∈(0,1)d表示d个神经元的状态,wij表示神经元i与j之间的连接权值,θi表示神经元i的阈值,则状态向量s所对应的玻尔兹曼机能量计算公式为
(7)
若网络中的神经元以不依赖于输入值的顺序进行更新,则网络最终会达到玻尔兹曼分布。此时状态向量s出现的概率仅由其能量与所有可能状态向量的能量确定,状态向量s出现的概率计算公式为
(8)
本文采用3层RBM堆叠形成的DBN作为猪咳嗽声识别模型,网络结构如图8所示。

图8 深度信念网络猪咳嗽声识别模型Fig.8 Pig cough sound recognition model based on DBN
将经过时间规整算法提取的300维短时能量和720维MFCC组合得到1 020维组合特征参数作为DBN的输入,DBN输入层神经元个数选为1 020个。最后一层为输出层,根据识别对象为猪咳嗽声与猪非咳嗽声,将输出层神经元个数选为2个。隐层神经元个数选取不合理会导致DBN识别能力和网络容错性降低,设每个隐层神经元个数分别为l1、l2和l3,则DBN模型可表示为1020-l1-l2-l3-2。隐层神经元个数经验公式为
(9)
式中lh——隐层神经元个数
lh-——前一层神经元个数
lh+——后一层神经元个数
δ——平衡参数,取0~10之间的常数
根据式(9)得到求解各隐层神经元个数的方程组为
(10)
通过选取合适的δ值,解方程组(10)得l1=37,l2=12,l3=7。
为了得到最优的各隐层神经元个数,按照梯度5依次将l1取值为32、37、42和47,将l2取值为7、12、17和22,将l3取值为2、7、12和17。经过多次训练对比重构误差和训练收敛时长,最终将l1、l2和l3分别取值为42、17和7,故DBN网络模型结构设定为1020-42-17-7-2。
3.2 深度信念网络猪咳嗽声识别模型训练
本模型采用的非监督贪婪算法逐层预训练RBM和BP算法[22-23]以整体微调的方式来训练DBN。预训练的过程即逐层训练RBM的过程。将每一个猪声音样本特征参数作为一个状态向量s,RBM训练的目的是通过式(7)最小化玻尔兹曼机的能量,同时通过式(8)最大化状态向量s出现的概率,进而得到对应的RBM权值wij和阈值θi参数。这个过程用对比散度(Contrastive divergence,CD)算法来实现[24-25]。
对于一个含有ld个显层神经元、lq个隐层神经元的RBM,令v和h分别表示显层与隐层神经元的状态向量,由RBM的特殊网络结构可得,由隐层计算显层和显层计算隐层的条件概率分别为
(11)
(12)
由CD算法原理,对于每一个猪声音样本v,首先根据式(12)计算出隐层神经元的状态分布,然后由此概率分布通过吉布斯采样得到h;接着根据式(11)和式(12)得到RBM权值更新公式为
wt+1=wt+η(vhT-v′h′T)
(13)
式中η——学习率,本文设置为0.1
v′——v经过吉布斯采样的结果
h′——h经过吉布斯采样的结果
wt——第t次训练得到的权值
wt+1——第t+1次训练得到的权值
为了提高DBN训练效率,本文采用数据包(每包50个样本)分包进行学习训练。为防止DBN训练时陷入过拟合,在权值更新过程中引入权重衰减(Weight decay)进行修正,通常情况下权重衰减取值范围为0.000 01~0.01[26]。将式(13)修改为
wt+1=wt+η(vhT-v′h′T+rwt)
(14)
式中r——权重衰减,本文设置为0.000 2
3.3 猪咳嗽声识别结果分析
采用3个指标来衡量实验结果:猪咳嗽声识别率(正确识别的猪咳嗽样本占测试集中猪咳嗽样本总数百分比)、猪咳嗽声误识别率(被误识别为猪咳嗽声的猪非咳嗽样本占测试集中猪非咳嗽样本总数百分比)和总识别率(正确识别的猪咳嗽样本和猪非咳嗽样本占测试集样本总数百分比)。采用5折交叉验证方法进行交叉验证,即将猪咳嗽声与5种非咳嗽样本平均分成5等分,并按照训练集与测试集样本4∶1的比例分成5组,进行交叉验证,实验结果如表1所示。

表1 5折交叉验证结果Tab.1 Comparison of recognition rate of cross validation method %
通过表1可知,各组猪咳嗽声识别率和总识别率均高于90.00%,猪咳嗽声误识别率不超过8.07%,说明了本文采用的基于DBN的猪咳嗽声识别模型是有效的。表1中第1组猪咳嗽声识别率达到94.12%,误识别率达到7.45%,总识别率达到93.21%,为最佳实验组。
3.4 猪声音信号特征参数降维
经过时间规整算法提取的300维短时能量和720维MFCC组合的1 020维猪声音信号特征参数维数高,为了提炼出有效的特征参数进而提高猪咳嗽声识别效率,本文采用主成分分析(Principal component analysis,PCA)[27]舍去原1 020维特征参数中表征猪声音信号能力弱的特征分量。
其主要实现过程为:
设m为猪声音样本个数,n为每个样本特征参数维度,原始数据矩阵Xm×n可表示为
(15)
将所有样本进行中心化得到初始化后的数据
(16)
初始化后的数据矩阵X′m×n的协方差矩阵为
(17)
Σ的特征值和特征向量为
(18)
式中λb——Σ的特征值
W——特征值λb对应的特征向量
将特征值λb从大到小排列,取前p个特征值对应的主成分,p值的选取通过特征值贡献率确定,其计算公式为
(19)
1 020维短时能量和MFCC特征参数与贡献率的关系如图9所示。

图9 特征参数维数的贡献率Fig.9 Contribution rate of dimension of feature parameters
图9中,当特征值的贡献率大于90%时,可认为这p个主成分的特征参数就能反映原猪声音信号的信息。经过计算,当p取479时,贡献率达到98.01%。于是,将1 070维特征参数降到479维。通过式(9)再次计算DBN网络结构为479-27-14-6-2,5折交叉验证实验结果如表2所示。

表2 特征参数降维后识别结果Tab.2 Recognition rate after feature parameters dimension reduction %
对比表1和表2识别结果可知降维后的各实验组猪咳嗽声识别率、误识别率和总识别率较降维前均有相应改善。降维后最佳组为第1组,相对降维前最佳组猪咳嗽声识别率提高了1.68个百分点,误识别率降低了0.62个百分点,总识别率提高了1.08个百分点,因此经过主成分分析法优化得到的479维猪声音特征参数可以代替原1 020维猪声音特征参数。
4 结论
(1)利用时间规整算法提取猪咳嗽、打喷嚏、吃食、尖叫、哼哼和甩耳朵6种声音短时能量300维,MFCC 720维,以此1 020维组合特征参数作为猪咳嗽声与猪非咳嗽声的衡量指标。进一步采用主成分分析法提取原6种声音的1 020维特征参数对应的贡献率为98.01%时的479维特征参数。实验表明,短时能量和MFCC的结合可以很好地衡量猪咳嗽声与猪非咳嗽声的差异。
(2)将深度信念网络引入猪声音识别领域,构建一个5层的深度信念网络猪咳嗽声识别模型,采用非监督贪婪算法逐层预训练RBM和BP算法以整体微调的方式训练DBN。设定50个样本的小批量数据包训练模式,学习率为0.1,引入权重衰减0.000 2,能够获取收敛较优的猪咳嗽声识别模型。
(3)通过5折交叉实验验证,采用1 020维特征参数,基于DBN的猪咳嗽声识别模型最佳组猪咳嗽声识别率达到94.12%,误识别率为7.45%,总识别率达到93.21%,经过PCA降维至479维后,猪咳嗽声识别率和总识别率相对降维前均有所提高,误识别率有所下降,最佳组猪咳嗽声识别率为95.80%,误识别率为6.83%,总识别率为94.29%。
1SILVA M, FERRARI S, COSTA A, et al. Cough localization for the detection of respiratory diseases in pig houses[J]. Computers and Electronics in Agriculture, 2008, 64(2):286-292.
2MITCHELL S, VASILEIOS E, SARA F, et al. The influence of respiratory disease on the energy envelope dynamics of pig cough sounds[J]. Computers and Electronics in Agriculture, 2009, 69(1):80-85.
3SARA F, MITCHELL S, MARCELLA G, et al. Cough sound analysis to identify respiratory infection in pigs[J]. Computers and Electronics in Agriculture, 2008, 64(2):318-325.
4何东健, 刘冬, 赵凯旋. 精准畜牧业中动物信息智能感知与行为检测研究进展[J/OL]. 农业机械学报, 2016, 47(5):231-244.http:∥www.j-csam.org/jcsam/ch/reader/view_abstract.aspx?flag=1&file_no=20160532&journal_id=jcsam.DOI:10.6041/j.issn.1000-1298.2016.05.032.
HE Dongjian, LIU Dong, ZHAO Kaixuan. Review of perceiving animal information and behavior in precision livestock farming[J/OL]. Transactions of the Chinese Society for Agricultural Machinery, 2016,47(5): 231-244.(in Chinese)
5EXADAKTYLOS V, SILVA M, AERTS J M, et al. Real-time recognition of sick pig cough sounds[J]. Computers and Electronics in Agriculture, 2008, 63(2):207-214.
6GUARINO M, JANS P, COSTA A, et al. Field test of algorithm for automatic cough detection in pig house[J]. Computers and Electronics in Agriculture, 2008, 62(1):22-28.
7HIRTUM A V, BERCKMANS D. Fuzzy approach for improved recognition of citric acid induced piglet coughing from continuous registration[J]. Journal of Sound and Vibration, 2003, 266(3):677-686.
8马辉栋,刘振宇. 语音端点检测算法在猪咳嗽检测中的应用研究[J].山西农业大学学报:自然科学版, 2016,36(6): 445-449.
MA Huidong, LIU Zhenyu.Application of end point detection in pig cough signal detection[J]. Journal of Shanxi Agricultural University:Natural Science Edition, 2016,36 (6): 445-449. (in Chinese)
9刘振宇,赫晓燕,桑静,等.基于隐马尔可夫模型的猪咳嗽声音识别的研究[C]∥中国畜牧兽医学会信息技术分会第十届学术研讨会论文集,2015:99-104.
10徐亚妮,沈明霞,闫丽,等. 待产梅山母猪咳嗽声识别算法的研究[J].南京农业大学学报,2016,39(4): 681-687.
XU Yani, SHEN Mingxia, YAN Li, et al. Research of predelivery Meishan sow cough recognition algorithm[J]. Journal of Nanjing Agricultural University, 2016,39(4): 681-687. (in Chinese)
11HINTON G E, OSINDERO S,TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006,18(7):1527-1554.
12HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504-507.
13LECUN Y,BENGIO Y, HINTON G E.Deep learning[J]. Nature,2015,512:436-444.
14MOHAMED A R, DAHL G E, HINTON G E. Acoustic modeling using deep belief networks[J]. IEEE Transactions on Audio Speech and Language Processing, 2011, 20(1):14-22.
15LI Xiangang, YANG Yuning, PANG Zaihu,et al. A comparative study on selecting acoustic modeling units in deep neural networks based large vocabulary Chinese speech recognition[J].Neurocomputing,2015,170:251-256.
16HU Y, LOIZOU P C. Incorporating a psychoacoustical model in frequency domain speech enhancement[J]. Signal Processing Letters IEEE, 2004, 11(2):270-273.
17吴红卫, 吴镇扬, 赵力. 基于多窗谱的心理声学语音增强[J].声学学报, 2007, 32(3):275-281.
WU Hongwei, WU Zhenyang, ZHAO Li. Psychoacoustical enhancement of speech based on multitaper spectrum[J]. Acta Acustica,2007,32(3):275-281.(in Chinese)
18戴元红,陈鸿昶,乔德江,等. 基于短时能量比的语音端点检测算法的研究[J]. 通信技术,2009,42(2):181-183.
DAI Yuanhong, CHEN Hongchang, QIAO Dejiang, et al. Speech endpoint detection algorithm analysis based on short-term energy ratio[J]. Communications Technology, 2009,42(2):181-183.(in Chinese)
19王山海,景新幸,杨海燕. 基于深度学习神经网络的孤立词语音识别的研究[J]. 计算机应用研究,2015,32(8):2289-2292.
WANG Shanhai, JING Xinxing, YANG Haiyan. Study of isolated speech recognition based on deep learning neural networks[J].Application Research of Computers,2015,32(8):2289-2292.(in Chinese)
20林玮,杨莉莉,徐柏龄. 基于修正MFCC参数汉语耳语音的话者识别[J]. 南京大学学报:自然科学版,2006,42(1):54-62.
LIN Wei, YANG Lili, XU Boling. Speaker identification in Chinese whispered speech based on modified-MFCC[J]. Journal of Nanjing Uninersity: Natural Sciences,2006,42(1):54-62.(in Chinese)
21李志忠,腾光辉. 基于改进MFCC的家禽发声特征提取方法[J]. 农业工程学报, 2008,24(11):202-205.
LI Zhizhong, TENG Guanghui. Feature extraction for poultry vocalization recognition based on improved MFCC[J]. Transactions of the CSAE,2008,24(11):202-205.(in Chinese)
22YU C C, LIU B D. A backpropagation algorithm with adaptive learning rate and momentum coefficient[C]∥International Joint Conference on Neural Networks. IEEE, 2002:1218-1223.
23HAMEED A A, KARLIK B, SALMAN M S. Back-propagation algorithm with variable adaptive momentum[J]. Knowledge-Based Systems, 2016,114:79-87.
24ERHAN D, BENGIO Y, COURVILLE A, et al. Why does unsupervised pre-training help deep learning?[J]. Journal of Machine Learning Research, 2010, 11(3):625-660.
25HINTON G E.Learning multiple layers of representation[J]. Trends in Cognitive Sciences, 2007, 11(10):428-434.
26HINTON G E. A practical guide to training restricted boltzmann machines[J]. Momentum, 2012, 9(1):599-619.
27李慧,祁力钧,张建华,等. 基于PCA-SVM的棉花出苗期杂草类型识别[J/OL].农业机械学报,2012,43(9):184-189.http:∥www.j-csam.org/jcsam/ch/reader/view_abstract.aspx?flag=1&file_no=20120934&journal_id=jcsam.DOI:10.6041/j.issn.1000-1298.2012.09.034.
LI Hui, QI Lijun, ZHANG Jianhua, et al. Recognition of weed during cotton emergence based on principal component analysis and support vector machine[J/OL]. Transactions of the Chinese Society for Agricultural Machinery, 2012,43(9): 184-189.(in Chinese)
