大数据环境下的信息架构与数据模型
2018-03-29赵栋祥赵一鸣
洪 漪 赵栋祥 赵一鸣
(1.美国MedeAnalytics公司,艾默里维尔市,加利福尼亚州,美国 94608;2.武汉大学信息资源研究中心,武汉,430072)
1 引言
在大数据时代之前,人类处理和使用的数据主要是文献、关系数据库等。而到了大数据时代,数据来源异常丰富,包括科学仪器、社交媒体与网络、电子零售、传感器数据、智能终端、医疗记录、金融交易等[1]。每个数据来源在数据的规模、类型、频率、速度和真实性等方面都显示出不同的特征。
业界通常用4个V(即Volume、Variety、Velocity、Value)来概括大数据的特征[2]。其中,Volume指海量的数据总数,Seagate和IDC的一项新研究 “数据时代2025”表明,到2025年全球数据量将会从2016年的16ZB上升至163ZB[3]。Variety指数据形式和结构的多样性,相对于以往便于存储的结构化数据,非结构化数据包括网络日志、音频、视频、图片、地理位置信息等越来越多,非结构化数据占到了总数据量的80—90%。Velocity指快速的数据生成速度,据估计到2018年,全球网络流量将达到50000GB/S,这对数据处理速度和时效性提出了更高的要求。Value指数据价值,如何从多源、海量、异构数据中排除不相关信息的干扰,从而揭示关联模式、预测未来趋势、挖掘数据价值是大数据的关键。
虽然我们拥有如此丰富的数字信息资源,但是对数字信息资源的开发利用却不容乐观。据Gartner研究报告显示,大约有85%的世界财富500强企业无法利用大数据来获得竞争优势[4]。这意味着,只有少数的大企业会利用大数据分析技术超越已知、洞见未来,并带来更强的竞争优势[5]。由此可见,整体范围内数字信息资源的开发利用严重滞后。丰富的数字资源累积与数字信息资源开发利用不足之间的矛盾愈演愈烈,而矛盾缓解的关键就在于数据处理方式的演化。在操作型数据库盛行的年代,数据处理方式是在线事务处理OLTP,其目的主要在于实现用户的简单查询和业务交互。到了20世纪80年代,对历史数据进行汇总分析以促进商务智能的需求逐渐增长,数据仓库和联机分析处理OLAP的数据处理方式成为主流[6]。然而,对于海量异构、多源实时、价值密度低的大数据而言,传统的数据处理和分析方式显然难以满足数字信息资源开发利用的需求,因此能够适应大数据环境的信息架构与数据模型显得尤其重要[7]。
2 大数据处理的信息架构
2.1 从传统信息架构到大数据信息架构
信息架构这一术语诞生于数据库设计领域,是指对某一特定内容的信息进行统筹、规划、设计和安排[8]。信息架构的主体对象是信息,它是一门由信息架构师来组织信息并设计信息环境、信息空间及信息体系结构,以满足需求者信息需求的艺术和科学。通俗地讲,信息架构就是研究信息的表达和传递,为信息与用户认知之间搭建一座畅通的桥梁[9]。
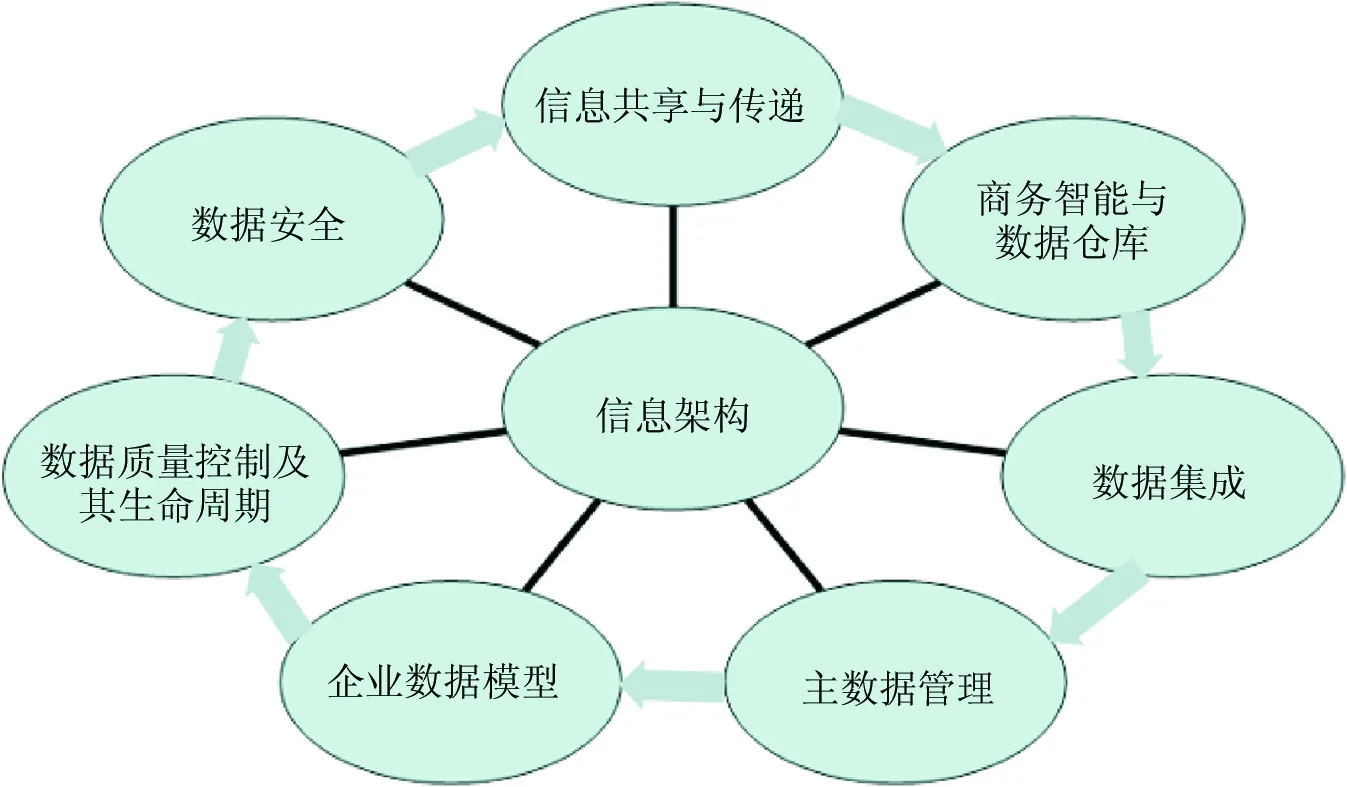
图1 信息架构的功能模型
从具体实现的角度来说,信息架构的功能模型包含以下要素:主数据管理、企业数据模型、数据质量控制及其生命周期、数据安全、信息共享与传递、商务智能与数据仓库、数据集成等,如图1所示。传统信息架构和大数据信息架构具有显著区别(见表1),但优质、及时和安全都是二者的主要架构原则。
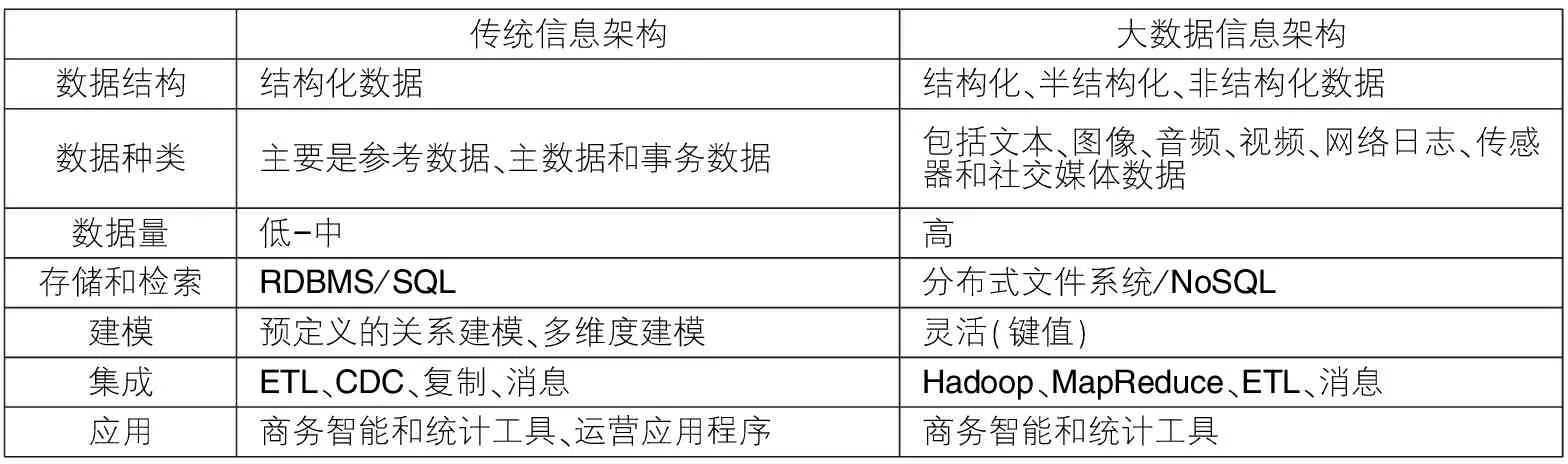
表1 传统信息架构和大数据信息架构的区别
2.2 大数据信息架构的核心
Hadoop和NoSQL是支撑大数据处理的基础技术,也是大数据信息架构的核心[10]。 所谓Hadoop,简单来说,就是以开源形式发布的一种对大规模数据进行分布式处理的技术。尤其是处理大数据时代所必需的非结构化数据时,Hadoop在性能和成本方面都具有优势,而且通过横向扩展进行扩容也相对容易。Hadoop最早是由三大部分组成的,即用于分布式存储大容量文件的HDFS分布式文件系统,用于对大量数据进行高效分布式处理的HadoopMapReduce框架,以及超大型数据表HBase。随后,Hadoop生态系统迅速扩展,衍生出多个子项目。从数据处理的角度看,HadoopMapReduce是其中最重要的部分。HadoopMapReduce并非用于配备高性能CPU和磁盘的计算机,而是一种运行在由多台通用型计算机组成的计算机集群上,对大规模数据进行分布式处理的框架。
NoSQL的全称为NotOnlySQL,是一种非关系型数据库管理系统,是为了解决大规模多种数据集合带来的挑战以及大数据应用难题应运而生的。传统的关系型数据库管理系统(RDBMS),以数据库表形式存储数据,采用SQL作为查询语言,用JOIN表链接方式将多个关系数据表中的数据用查询语句进行关联检索,适用于一般业务操作和数据处理,但其固有的无法处理非结构化数据、难以进行横向扩展等问题[11]使之难以满足对海量数据进行高效率存储和访问的需求。要作为以非结构化数据为中心的大数据处理的基础,则勉为其难[12]。NoSQL的数据存储不需要固定的表格模式,具有可扩展性,而且不使用复杂的SQL, 省略了JOIN查询的消耗,大大提升了数据处理的速度,在大数据环境下其性能是远远优于RDBMS的。然而,尽管NoSQL数据库不使用SQL查询语言,但并不意味着NoSQL数据库是对现有RDBMS的否定并将要取代RDBMS,NoSQL实际上是对RDBMS所不擅长部分的补充[13]。NoSQL数据库与RDBMS之间的主要区别如表2所示。

表2 RDBMS与NoSQL数据库的区别
2.3 大数据处理架构模型
大数据处理的架构模型包含三个层次:数据存储层、数据管理层和计算模型层,如图2所示。其中,数据存储层是按不同的数据类型(如文本、图片、视频和音频等)对大数据系统中的原始数据进行归类存储的物理数据层;数据管理层是用于管理物理数据的逻辑结构层;计算模型层是根据业务需求创建数据流和计算任务并从大数据中挖掘有用信息获得商业价值的应用层。
大数据处理的信息架构覆盖了数据的捕获、分类、存储、建模、计算和分析等不同活动。对于不同来源的数据流,应按照数据类型特征将文档、图表、日志和邮件等不同类别的数据归类存储,通过构建数据模型实现数据的物理存储与数据应用之间的分离,使更便捷的数据管理成为可能。要构筑一个大数据模型,须基于数据存储、数据类型、数据关系以及读写需求等创建数据块。数据块(datablock)是由元数据定义的数据单元,包括数据存储的物理位置、数据的访问路径和数据的保存格式等。只有清楚数据的实际位置,才能在数据管理层对其进行建模,并通过计算机程序获取相应数据完成计算任务。计算模型层在大数据时代具有极其重要的意义,它主要用来设计计算任务、表述计算数据的逻辑路径,从而提升数据重用的效率。计算模型层的运行依赖于Hadoop提供的分布式数据处理模型和MapReduce的计算框架。为应对持续增长的商业需求和日益复杂的计算任务,优化数据流和计算流设计显得尤其重要。

图2 大数据架构模型的层次
3 大数据建模
3.1 传统数据建模技术面临的挑战
传统的数据建模技术是一种定义清晰的数据建模手段,如星模型(StarSchema),这样的建模手段主要是为与数据仓库相联系的分析工作服务的。但如今传统数据仓储手段的根基正在慢慢松动,随着能够线性扩展的分布式数据库的出现及云计算的迅猛发展,存储空间无限扩大,数据存储和计算的成本越来越低,数据处理时间成为更稀缺和更具价值的资源。此外,随着数据规模的持续增长和数据结构关系的复杂化,大批量捕获、存储、搜索、分享、分析数据及数据可视化不断挑战传统关系型数据库的数据处理能力,越来越多的数据管理机构开始尝试用NoSQL数据库去应对大数据带来的挑战[14]。
3.2 混合数据模型与大数据建模技术
传统数据环境下,单一数据模型(如关系模型)可以应对大多数应用场景和数据处理任务。而到了大数据时代,由于大数据驱动着数据搜集与数据处理的变革,考虑到关联处理性能下降以及数据增长给硬件存储容量、处理能力带来的压力,需要重新审视当前采用的数据模型。关系型数据库的复杂性限制了数据存储的扩展,但它通过SQL引擎使查询数据变得非常简单。大数据NoSQL系统具备相反的特质:无限扩展但更有限的查询能力。因此,混合数据模型成为大数据环境下的必然选择[15]。与以往创建纯关系型模型不同,混合数据模型将NoSQL子模型嵌入到关系型数据模型中,使之既保留了强大的查询功能又能进一步扩展。简单来说,大数据模型是一个用于管理存储于物理设备的数据的抽象层,它提供了一种可视化的方式去管理数据源,并且创建基础数据架构以便有更多的应用去优化数据重用、减少计算成本。
数据的特征和需求差异是决定其数据模型和处理架构的重要因素。如果数据有如下特性:在线交易处理需要、ACID需求(原子性、一致性、隔离性、持久性)、复杂的数据关系、复杂的查询需求,就适用于传统的RDBMS。而对于规模增长迅速的数据、呈列增长模式的数据、文档以及数组数据、层级以及图类型数据,则更适合于NoSQL系统。
NoSQL数据库是根据典型的keyvalues模式存储的,具有非关联性、分布式、横向扩展和模式自由的特点。如果需要的话,可以重新设计数据模型,如可以逆规范化以减少对关系的依赖,在ER图中将不同的实体中的属性聚集到同一个实体。由于在文档中需要表述原始数据的层级关系,故需要一个好的数据表现形式去辅助理解原始数据的关系。随着表现层的变革,Erwin等数据建模工具能够分析模式的改变、生成代码模板,辅助完成从RDBMS到NoSQL数据库的数据迁移,并且提供发布于不同数据系统的完整视图。未来混合数据库系统应该能够提供内置的迁移工具以辅助开发NoSQL的潜能。目前,将既存系统迁移至NoSQL系统之前进行模型的重新定义是至关重要的事情,需要评估现有数据模型及建模工具,以确认能否满足新的需求[16]。
尽管可以采用NoSQL数据库去解决大数据管理的具体问题,但由于SQL语言的经久不衰,当前的趋势仍然是在一个数据库中支持SQL和NoSQL这两种功能。传统的关系型数据库厂商,如微软和甲骨文都在新近发布的数据库产品中提供对NoSQL特性的支持,比如微软SQLServer以及TeradataWarehouse对列式存储提供支持。同样,对于NoSQL数据库而言,比如Hadoop的子项目Hive,以及CQL查询语言的Cassandra,都很快地升级去支持类SQL的语言。此外,Google也在开发混合的分布式数据库Megastore,以实现在NoSQL的存储模式支持SQL的特性。
总而言之,在大数据时代,“多种架构支持多类应用”成为数据库行业应对大数据的基本思路,数据库行业出现互为补充的三大阵营,适用于事务处理应用的OldSQL、适用于数据分析应用的NewSQL和适用于互联网应用的NoSQL[17]。但在一些复杂的应用场景中,单一数据库架构不能完全满足应用场景对海量结构化和非结构化数据的存储管理、复杂分析、关联查询、实时性处理和控制建设成本等多方面的需要,因此不同架构数据库混合部署成为满足复杂应用的必然选择[18]。
3.3 常用的数据建模工具
正确而连贯的数据流对商业用户做出快速、灵活、科学的决策起到决定性作用,因此,如何做好数据建模,即建立正确的数据流和数据结构具有重要意义。为此,我们需要使用专业的数据建模工具来帮助我们建立数据逻辑模型和物理模型、生成数据定义语言DDL,并且能够生成报告来描述这个模型,同时分享给其他伙伴。以下是最常用的5个数据建模工具的简单介绍,见表3。
4 大数据信息架构与数据模型在医疗数据分析中的应用
报告显示,2011年,单单美国的医疗健康系统数据量就达到了150EB[24],目前全球的医疗大数据已经超过了600EB,年增长率接近50%。按照此增长速度,到2020年,全世界的健康数据量将达到2314EB[25]。可能是出于保护患者隐私的考虑,医疗健康服务领域对大数据的挖掘与分析相比其他行业开始得较晚。因此,在医疗大数据信息架构和数据模型的创建过程中须特别注意保护患者个人信息及其医疗数据安全,加强数据质量管理,防范Hadoop和其它开源系统可能存在的安全漏洞。

表3 常用的数据建模工具
本文以美国医疗数据分析公司MedeAnalytics的大数据分析解决方案为例,从患者医保和财务数据分析、临床医疗质量管理和健康风险评估数据分析三个场景阐述大数据信息架构与数据模型在医疗健康大数据分析中的应用[26]。
4.1 在患者医保和财务数据分析中的应用
大数据模型应用于患者注册登记和付款结算流程的实时数据分析,可以准确预测患者的医疗总费用以及医保涵盖范围与自付额、验证医保资格。通过交互式的可视化图表界面和简明的工作列表展示患者医疗与保险数据,简化就医前的注册登记流程,提高患者注册登记的自动化程度,预防和减少因个人信息登记错误造成的医保拒付。图3所示的PatientAccess实时注册工作列表可针对每个患者的姓名、基本险、就诊日期、病患类型、医疗机构、预估/已付费用、注册来源等数据进行分析,通过醒目易用的红绿灯形按键链接到相应的界面进行医保资格验证和医疗补助资格筛选,并准确估算患者医疗费用金额。

图3 实时患者注册登记工作列表
图4中的收入周期数据表(dashboard)通过对患者注册登记及医疗保险机构本月和上个月数据的分析和趋势动向,用图表形式以医疗机构和医保机构为单位展示医保拒付动态。
图5用直观图表形式展示了销售点现金收集趋势、销售点现金收集占预估金额的百分比、完成医保资格验证的百分比、患者预测精确度走向、患者个人信息确认状况、帐户安全动向等数据分析结果。

图4 收入周期与医保拒付动态的分析报告
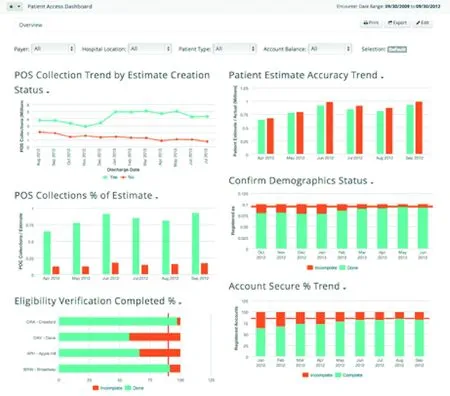
图5 患者医保财务数据分析报告图表
4.2 在临床医疗质量管理中的应用
美国医疗和医保机构的质量管理大多采用HEDIS(HealthcareEffectivenessDataandInformationSet)、ACO(AccountableCareOrganization)和P4P(PayforPerformance)等医疗质量评估系统的测量指标对临床医疗质量进行监测评估,将客户的临床和医保数据输入基于Hadoop的质量评估引擎获取评估结果,并通过标准认证。HEDIS医疗质量测量指标由NCQA(NationalCommitteeforQualityAssurance,美国国家质量保证委员会)发布,被美国90%以上医疗机构及健保系统采纳。这些指标针对医疗服务的有效性、医疗服务的可及性、对医疗服务的满意度、医疗服务的应用、医疗服务的成本、健康计划的稳定性、对医疗服务的知情选择等对不同医疗机构的服务质量加以评判,并对全美医疗系统的临床医疗质量依据年报进行星级评比。图6展示了某医疗机构2011年的成人哮喘患者就诊率、癌症筛查、高血压控制、流感预防等质量评估指标的分析结果。
图7的ACO质量评估报告中包含了按人群展示的前五名(PMPM,PerMemberPerMonth,每月每人)医保费用以及急诊科(ED)利用率趋势和常去急诊科就诊的患者图表。
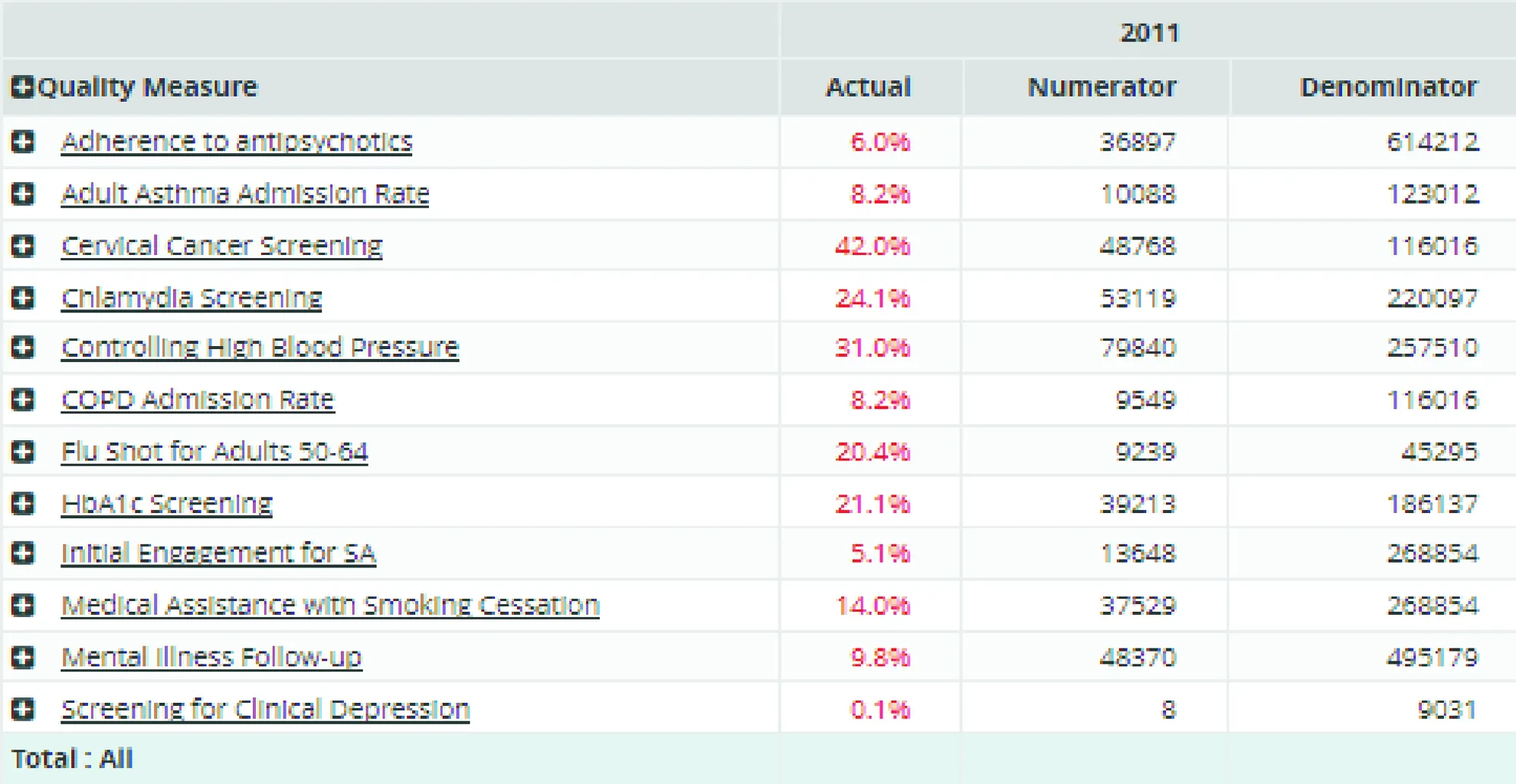
图6 HEDIS医疗质量指标评估分析报告样例
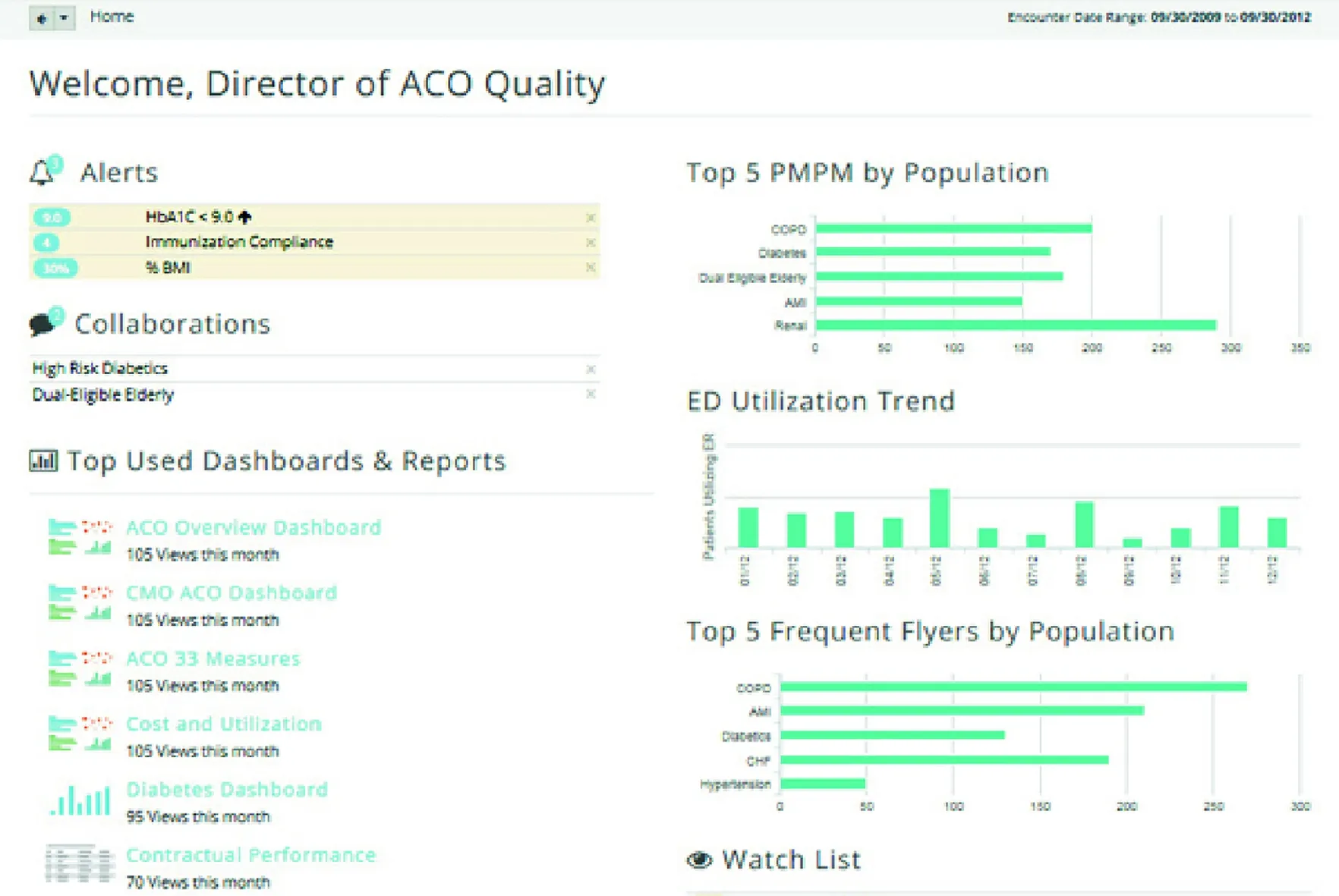
图7 ACO医疗质量评估分析报告样例
4.3 在医疗健康风险评估中的应用
利用医疗大数据对疾病危险因素和患者健康风险进行监测评估可以深入到个体病患级别。例如,对医疗保健成本及其影响因素进行分析,以发现影响各个医疗机构不同部门医疗费用的关键因素;提前了解人群中哪些人可能在下一年医疗消费昂贵,针对社区中不同人群的健康状况和疾病负担,对健康计划和资源分配的重点做出相应调整,从而有效管理临床和财务风险,提供更有价值的医疗服务。图8是根据患者的疾病状况所作的医疗健康风险评估结果,其中PRI(PredictedResourceIndex,预测资源指数)也称总成本资源指数,是根据患者的疾病状况预估平均医疗费用的相对风险评分。分数越高,风险越大,医疗费用越高。
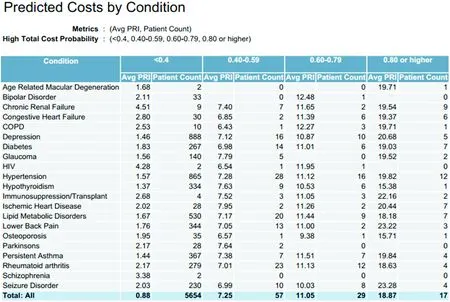
图8 根据患者疾病状况所作的医疗健康风险评估
以上解决方案均基于大数据信息架构和数据模型,通过对多源异构、海量实时的医疗健康大数据进行整合和分析而实现的。医疗健康大数据的挖掘和分析可为患者提供高效率、高质量的临床诊断以及更加优质、高效的医疗服务,为公共卫生保健提供预防决策支持与保健咨询服务,从而促进医疗信息资源共享,提高医疗质量,保障患者安全,降低健康风险与医疗成本,提升医疗卫生服务水平。
5 结语
数据环境的持续变化在丰富数字信息资源的同时,也给传统的数据处理和分析方式带来了诸多挑战。在大数据环境下,信息架构和数据模型的原有认知与实践应用亟待更新。此外,在不同的行业领域和应用场景下,大数据处理的基础架构与数据模型又存在规范和要求上的差异,这也促使人们对大数据环境下的信息架构和数据模型进行进一步探索与研究。
本文在大数据背景分析基础上,针对大数据架构的特征和核心内容,阐述了一个包含数据存储层、数据管理层和计算模型层的大数据处理架构模型;讨论了混合数据模型与大数据建模技术在大数据环境下的探索与应用,梳理了常用的数据建模工具;并以医疗健康领域的典型场景为例,分析了大数据信息架构与数据模型在患者医保和财务数据分析、医疗质量管理以及健康风险评估中的应用。大数据领域方兴未艾,希望本文能对大数据环境下数据处理与数据建模相关的研究与实践有所裨益。
[1]ChenH,ChiangRH,StoreyVC,etal.Businessintelligenceandanalytics:Frombigdatatobigimpact[J].ManagementInformationSystemsQuarterly,2012,36(4):1165-1188.
[2]IBMBigData&AnalyticsHub.ThefourV’sofBigData[EB/OL]. [2017-10-26].http://www.ibmbigdatahub.com/infographic/four-vs-big-data.
[3]IDC.DataAge2025:TheevolutionofdatatoLife-Critical[R/OL]. [2017-10-26].https://www.seagate.com/www-content/our-story/trends/files/Seagate-WP-DataAge2025-March-2017.pdf.
[4]LaneyD.Informationinnovation:Innovationkeyinitiativeoverview[EB/OL].[2017-10-26].https://www.gartner.com/doc/1991317/information-innovation-innovation-key-initiative.
[5]JohnstonA.Only15%ofFortune500companiesusebigdataanalyticstolookbeyondthe‘known-knowns’-Why?[EB/OL]. [2017-10-26].https://www.forbes.com/sites/teradata/2015/06/24/why-only-15-of-the-fortune-500-uses-big-data-analytics-to-look-beyond-the-known-knowns/#5cfc00105d9a.
[6]ElmasriR,NavatheSB. 数据库系统基础: 高级篇[M]. 邵佩英, 徐俊刚, 王文杰, 等译. 北京: 人民邮电出版社,2008,255-256.
[7]JiCQ,LiY,QiuWM,etal.Bigdataprocessing:Bigchallengesandopportunities[J].JournalofInterconnectionNetworks,2012,13(3):1250009.
[8]ResminiA,RosatiL.Abriefhistoryofinformationarchitecture[J].JournalofInformationArchitecture,2011,3(2):33-46.
[9]RosenfeldL,MorvilleP,ArangoJ. 信息架构: 超越web设计[M]. 樊旺斌, 师蓉, 译. 北京: 电子工业出版社,2016,19-31.
[10]DemchenkoY,NgoC,MembreyP.Architectureframeworkandcomponentsforthebigdataecosystem[R/OL]. [2017-10-26].http://uazone.org/demch/worksinprogress/sne-2013-02-techreport-bdaf-draft02.pdf.
[11] 吕明育, 李小勇.NoSQL数据库与关系数据库的比较分析[J]. 微型电脑应用,2011,27(10):55-58.
[12]KumarR,ParasharBB,GuptaS,etal.ApacheHadoop,NoSQLandNewSQLsolutionsofbigdata[J].InternationalJournalofAdvanceFoundationandResearchinScience&Engineering.2014,1(6):28-36.
[13]ZafarR,YafiE,ZuhairiMF,etal.BigData:TheNoSQLandRDBMSreview[C]//InternationalConferenceonInformationandCommunicationTechnology.IEEE,2017:16790625.
[14]IT168. 大数据的逆袭:传统数据库市场的变革[EB/OL]. [2017-10-26].http://tech.it168.com/a2013/0630/1501/000001501628.shtml.
[15] 林金芳, 欧锋. 分布式混合数据库系统[J]. 计算机系统应用,2015,24(10):32-37.
[16]AlamiAE,BahajM.MigrationofarelationaldatabasestoNoSQL:Thewayforward[C]//InternationalConferenceonMultimediaComputingandSystems.IEEE,2017:18-23.
[17]InfoQ.SQL与NoSQL混合数据库正在取得进展 [EB/OL]. [2017-10-26].http://www.infoq.com/cn/news/2012/02/Hybrid-SQL-NoSQL.
[18] 黄硕, 梁英, 刘越,等. 一种支持智能电网大数据处理的混合存储模型[C]// 中国计算机学会. 第31届中国数据库学术会议论文集.北京,《计算机研究与发展》编辑部,2014:142-152.
[19] 赵韶平, 徐茂生, 罗海燕, 等.PowerDesigner系统分析与建模[M]. 北京: 清华大学出版社,2010:1-7.
[20]Datamodelingformulti-platformenvironments:ER/Studiodataarchitect[EB/OL]. [2017-10-26].https://www.idera.com/er-studio-data-architect-software.
[21]EnterpriseArchitect[EB/OL]. [2017-10-26].http://www.sparxsystems.cn/products/.
[22]CAERwin®datamodelermethodsguide[EB/OL]. [2017-10-26].https://support.ca.com/cadocs/0/CA%20ERwin%20Data%20Modeler%20r8-ENU/Bookshelf_Files/PDF/ERwin_Methods.pdf.
[23]InfoSphereDataArchitect:Bestpracticesformodelingandmodelmanagement[EB/OL]. [2017-10-26].https://www.ibm.com/developerworks/data/library/techarticle/dm-1311infodatartbp/index.html.
[24] 陈遵秋. 浅谈医学大数据(上)[EB/OL].[2017-11-12].https://cosx.org/2015/03/the-big-data-of-medicine1/.
[25] 比格数据|大数据带你看医疗健康行业投资趋势[EB/OL].[2017-11-16].http://wemedia.ifeng.com/30165927/wemedia.shtml.
[26]MedeAnalytics[EB/OL].[2017-11-12].http://medeanalytics.com/solutions.
