深度学习在身份证字符识别中的应用研究
2018-03-22胡胤黄启权广东工业大学自动化学院
胡胤 黄启权 广东工业大学自动化学院
1 引言
受CNN模型成功应用于手写数字识别、交通信号识别及人脸识别等的启发,本文将汉字特征提取和特征降维过程相结合,提出一种基于CNN的汉字识别方法和另外一种成熟的基于CNN的数字识别方法应用到身份证识别中。
随着互联网的发展,需要网络实名认证的场景越来越多。当人们在享受互联网带来便利的同时,却不得不考虑到个人信息的甄别问题。将深度学习应用在字符识别场景中,能够快速准确的识别出数字和字符,也为录入身份证、行驶证、驾驶证等证件信息提供了便利。
2 了解 CNN
卷积神经网络类似于一般的神经网络,由可学习的权重和误差组成,每 一个神经元接受一些输入,完成一些非线性的操作。整个神经网络完成了一个可微的打分函数,从图像点到分类得分。在全连接或者最后一层他们也有一个损失函数。
卷积神经网络通常包含以下几层:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中提取更复杂的特征。
线 性 整 流 层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
全连接层(Fully-Connected layer),把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
以下是一个简单的LeNet-5卷积神经网络模型:
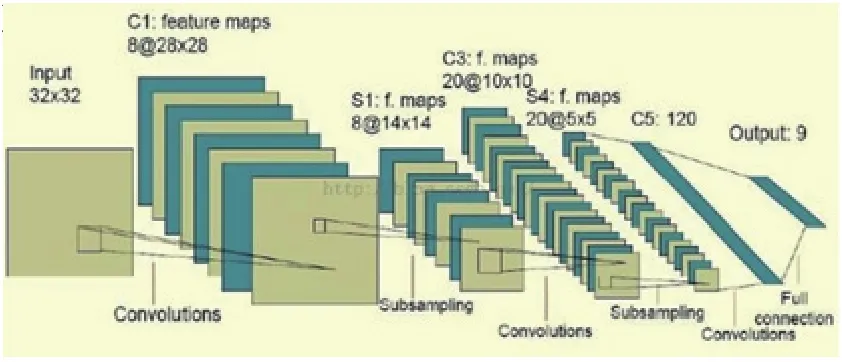
图1 LeNet-5网络模型
3 获取训练数据
3.1 阿拉伯数字
数字0~9一共分为10类,考虑类别少的因素,用MATLAB脚本生成数字数据时候使用二值图片,像素为48*48大小,对文字图片做随机旋转、随机裁剪、随机腐蚀膨胀核腐蚀膨胀、随机resize处理。
3.2 中文汉字
GB2312标准共收录6763个常用汉字,使用覆盖率在99.75%以上。用身份证的底色随机剪切作为训练图片的底色,然后用opencv生成随机底色、随机旋转、随机裁剪、随机腐蚀膨胀核腐蚀膨胀、随机resize,随机模糊噪点图片等作为训练数据。

图2 训练底色图

图3 训练数据
4 卷积网络训练模型
Google Inception Net首次出现在ILSVRC 2014的比赛中,以较大优势取得了第一名。那届比赛中的Inception Net通常被称为Inception V1,它最大的特点是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5错误率6.67%。
本文在GoogleNet的基础上结合本文任务进行了网络结构改造,改造后的网络模型IDNet如图所示:
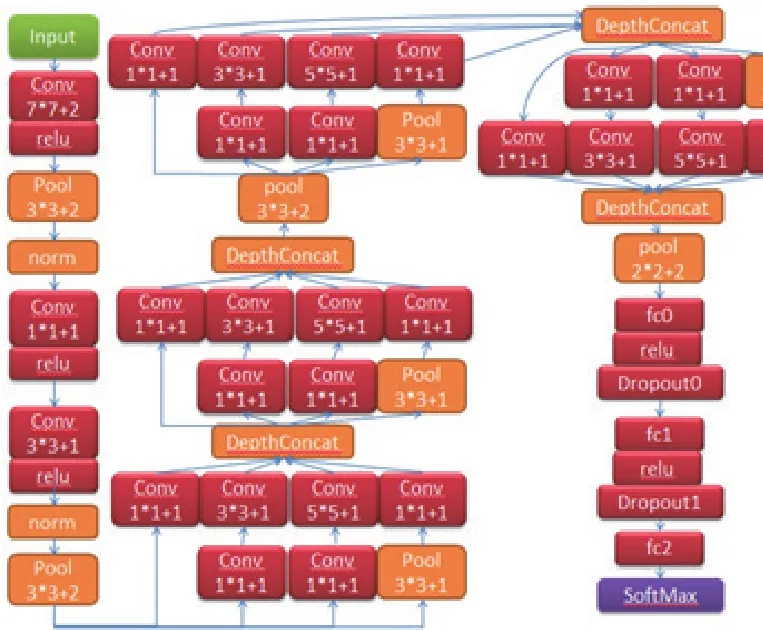
图4 IDNet网络模型结构
5 结论
训练使用GTX1080设备,数字和汉字训练都使用48*48的原始图片,crop_size为45*45的网络训练图片。
汉字训练图片为超参数学习率设为0.01,最大迭代次数设为30万次,batch_size设为128,stepsize设为100000,训练所用时间花费9个多小时,测试集使用一万张剪切的真实字符数据,最后测试得到的数字识别的正确率为99.91%,汉字识别的的正确率为99.82%。
[1]孙华,张航.字识别方法综述[J].Computer Engineering,2010,36(20).
[2]王有旺.深度学习及其在手写汉字识别中的应用研究[D].华南理工大学,2014.
[3]严曲.身份证识别系统的原理及算法研究[D].中南大学.2005.3
[4]倪桂博.印刷体文字识别技术的研究[D].华北电力大学.2008
[5]Romero R D,Touretzky D,Thibadeaun R H.Optical Chinese character recognition using probabilistic neural networks[J].Pattern Recognition,1997,30(8):127-129.
[6]Liu C L,Sako H,Fujisawa H.Handwritten Chinese Character Recognition:
Alternatives to Nonlinear Normalization[C].ICDAR. 2003, 3:524-528.
