基于卷积神经网络的石刻书法字识别方法
2018-03-19温佩芝沈嘉炜
温佩芝,姚 航,沈嘉炜
(1.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;2.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004)
0 引 言
笔迹识别中的关键环节是特征提取,通常分为局部特征和全局特征。对此,陈睿等[1]提出了基于关键词提取的笔迹鉴别方法,实质是通过关键词匹配将笔迹鉴别问题转化为特定字符鉴别问题,方法高度依赖文本,且毛笔字中存在大量异体字,导致通用性低、识别效果差;李庆武等[2]提出了基于笔画曲率特征的笔迹鉴别方法,提取出笔迹骨架后比较多个方向上笔画骨架的曲率,但对毛笔字鉴别中丢失了笔画粗细等特征,通用性较低;毛天骄等[3]采用SIFT算子提取书法字图像的特征,再通过KNN方法剔除特征不明显的特征点,实现字迹识别,该方法对形状统一的印刷字体效果较好,而对噪音较多且不规则的石刻字体识别率较低;王晓等[4]先提取出笔迹笔端,后使用一种笔端形状描述子来表达笔迹的特征,但对图像清晰度要求较高,难以识别个性化的手写笔迹;邱娟等[5]提出了一种结合Gabor滤波器和高斯马尔科夫随机场(GMRF)的笔迹特征提取方法,在Gabor滤波图上构建高斯马尔科夫随机场(GMRF)模型来描述不同作者的笔迹特征,但因建模时仅采用三阶邻域结构,无法表达出毛笔字复杂的局部结构。
针对以上问题,本文提出了一种基于改进的卷积神经网络的石刻、碑帖字体笔迹识别方法,首先对石刻字体图像进行预处理,去除噪音并分割出单个石刻字体;之后提取每个石刻字的骨架,分别建立石刻字原始图像与骨架图像的数据集;再采用基于RPReLU(随机泄漏修正线性单元)和随机退隐(Dropout)改进的卷积神经网络进行笔迹特征提取;然后将石刻字体骨架图像提取的特征与原始字体提取的特征相融合,拼接得到新的特征;在此基础上,利用三层神经网络提取更高层次的特征实现石刻、碑帖字体的识别。采用经典的方法和本文方法对6位不同书法家的作品进行了字体分类识别的实验对比。实验结果表明,本文提出的基于卷积神经网络的书法字体笔迹识别方法,对石刻、书法字识别的准确率达到99.1%,是一种高效的笔迹识别方法。
1 卷积神经网络基础理论
近年,深度学习成为机器学习中一个快速发展的新分支,建立在仿生学的基础之上,通过模拟人类大脑神经网络学习推理的过程,建立多层次的深度模型,将大量低层特征组合成更加抽象的高层特征,从而构建了从底层信号到高层语义的映射关系。其中,卷积神经网络(convolutional neural network,CNN)来自生物自然视觉认知机制的启发,是深度学习中一种高效的架构。Krizhevsky等[6]采用的卷积神经网络方法在ImageNet竞赛中取得了远优于其它算法的成绩,超出了第二名约10%,充分显示了深度学习模型的表达和执行能力。
CNN是一种多层神经网络,它的基本结构通常包含卷积层和采样层。其中卷积层又分为两部分,一部分是特征提取层,另一部分是特征映射层。特征提取层由若干个map构成,每一个map又是由若干个神经单元构成,每个神经元的输入和上一层的局部感受域连接来获取这个局部的特征,当这个局部特征被获取后,它和另外的特征之间的空间关系就确定了。在同一个map上所有的神经元使用相同的卷积核,一个卷积核一般表示一个特征,例如某个卷积核表示一段弧,将该卷积核在图像上进行滑窗后,较大卷积值的局部区域就有很大概率是一段弧。卷积核即是权重,把一个大小固定的权重矩阵匹配一个图像,该过程类似于卷积,所以命名为卷积神经网络。特征映射层,是将每个特征映射为一个map,map上全部神经元具有相等的权重,同时神经网络的每一个计算层包含若干个特征映射。特征映射结构的激活函数通常使用影响函数核较小的sigmoid函数,保证特征映射具有一定的核较小的sigmoid函数,保证特征映射具有一定的位移不变性,有时也会用到其它的一些激活函数,如ReLU或Leaky ReLU。
CNN是一种多层神经网络,它的基本结构通常包含卷积层和采样层。其中卷积层又分为两部分,一部分是特征提取层,另一部分是特征映射层。特征提取层由若干个map构成,每一个map又是由若干个神经单元构成,每个神经元的输入和上一层的局部感受域连接来获取这个局部的特征,当这个局部特征被获取后,它和另外的特征之间的空间关系就确定了。在同一个map上所有的神经元使用相同的卷积核,一个卷积核一般表示一个特征,例如某个卷积核表示一段弧,将该卷积核在图像上进行滑窗后,较大卷积值的局部区域就有很大概率是一段弧。卷积核即是权重,把一个大小固定的权重矩阵匹配一个图像,该过程类似于卷积,所以命名为卷积神经网络。特征映射层,是将每个特征映射为一个map,map上全部神经元具有相等的权重,同时神经网络的每一个计算层包含若干个特征映射。特征映射结构的激活函数通常使用影响函数核较小的sigmoid函数,保证特征映射具有一定的位移不变性,有时也会用到其它的一些激活函数,如ReLU或Leaky ReLU。
CNN的布局类似哺乳动物网络神经,可以将图像直接作为输入,这一特点可以避免图像高维特征提取和过沉重数据重建的复杂过程,具有独特的优越性。CNN模型还具有稀疏连接和权重共享的两种机制,可以极大减少网络参数的数量,从而降低了复杂性,提高网络模型的泛化能力。因此,本文采用了CNN多层次网络结构,如图1所示。
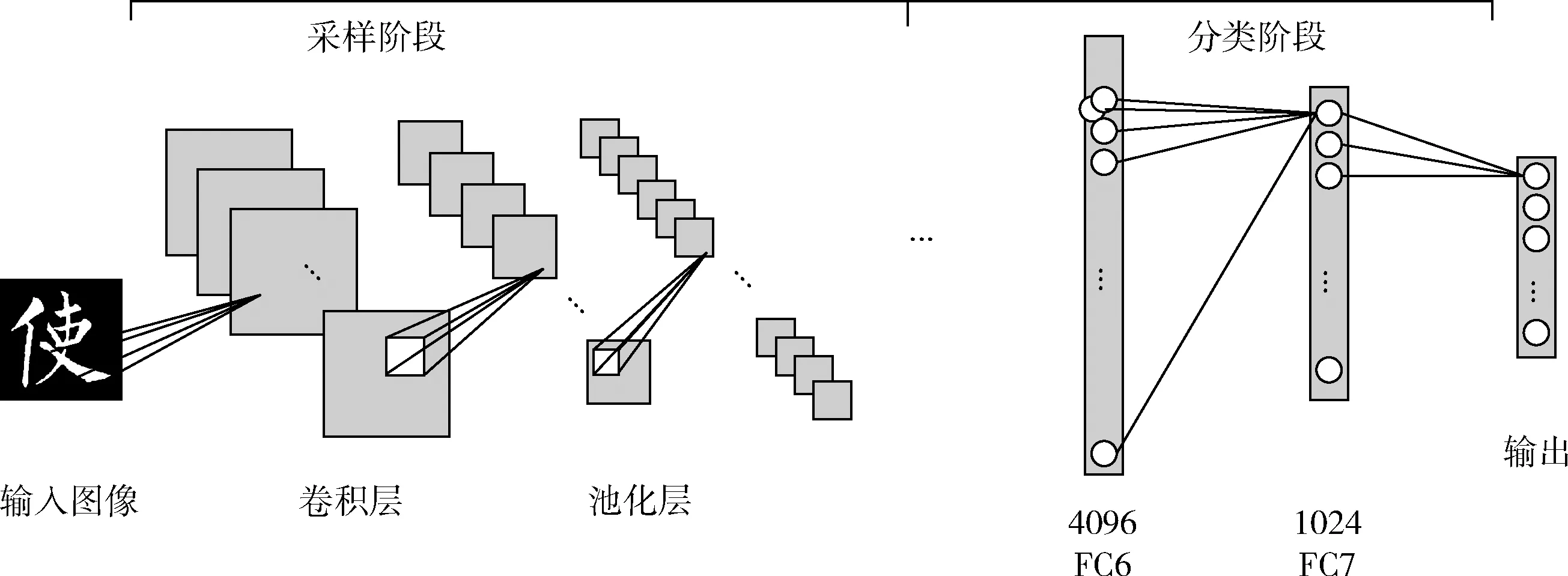
图1 多层次网络结构
1.1 稀疏连接
一般的神经网络的各神经元是全连接的,但在复杂的图像分类中,全连接会产生巨量的参数,如训练样本是256×256的图像,网络的卷积层有216个结点,全连接则有232个结点,使模型不稳定并难以收敛。
仿照人观察事物过程,不是每一个神经元都需记住所有内容,只需记住局部信息,并在高层抽象结合,据此采用稀疏局部连接方式构成CNN网络。CNN网络中前后两个层间通过采用局部连接的方式来获取图像数据的空间局部特征,即第l层的神经元只连接第l-1层的局部神经元,第l-1层中这个局部区域命名为空间连续感受域,示例连接结构如图2所示。通过捕获数据的空间局部特征,大大减少模型的参数数量,可以极大提高图像识别和检索的效率。

图2 CNN稀疏连接结构
1.2 权重共享
权重共享同样也是CNN中一种解决参数量巨大的方法。在CNN中,特征提取层中的某一个map的神经元通过共享卷积核的权重来连接上一层map的空间局部区域。
由图3所示,同种箭头拥有相同的权重;第l层包含3个神经元,它们使用同一种卷积核,包含3个权重a、b和c。本文采用梯度下降法来训练学习这些权重参数,通过权值共享可以大幅减少参数个数,降低网络的复杂度。
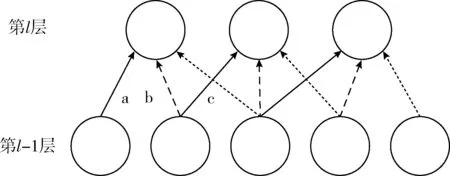
图3 CNN权重共享结构
2 基于CNN的石刻书法字识别方法
2.1 数据集的建立与预处理
通常,由于自然风化腐蚀导致石刻原始表面斑驳残缺等原因,以及数字成像技术的影响,实际采集的石刻书法字作品的数字化图像大多数为整张图片,而且包含大量噪音和干扰,如图4(a)所示,需要字体分割前进行预处理去除噪声和干扰。
对此,本文首先采用中值滤波对整张图像去噪后进行二值化,再利用数学形态法(膨胀与腐蚀)除去边缘噪声,然后利用图像在水平和垂直方向上的投影来切割出单个石刻字体,最后对字体进行归一化后合成相同大小(256×256)的笔迹图像,如图4(b)所示。

图4 预处理前后的石刻字体图像
其次,使用A-W细化法[7]对预处理后的图像进行字体骨架提取,建立石刻书法字体骨架集。A-W细化算法使用20种细化模板,以目标像素点和它的八邻域像素点组成3×3大小的目标窗口,与图像中的每个像素点进行对比,删除匹配的点。迭代使用该方法,直到图像中没有符合模板的像素点,后得到的图像即为汉字骨架。图5为处理后的石刻书法字体图像及书法字体骨架的图像。最后分别建立石刻字体图像数据集A和石刻字体骨架数据集B。
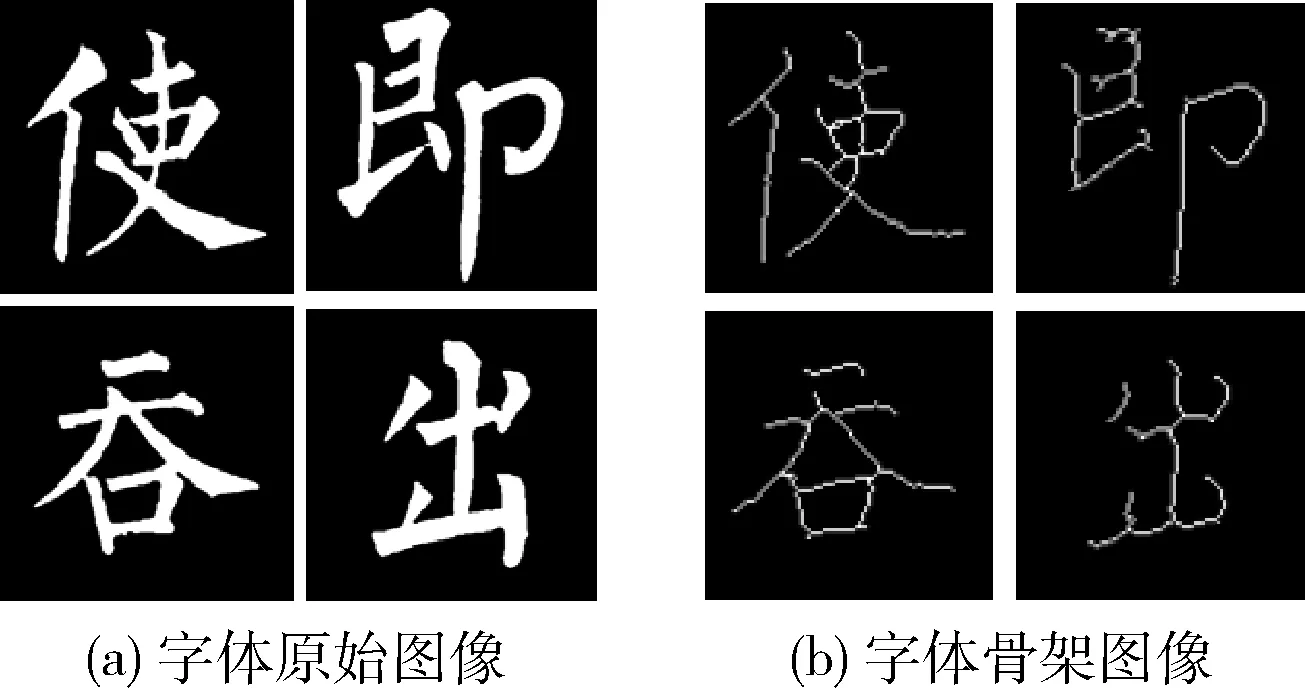
图5 石刻字体及石刻字体骨架图像
为了提高卷积神经网络模型训练后的泛化能力,将两个数据集内的石刻字体图像每90°旋转一次(共4次),建立扩增后的数据集A与数据集B,如图6所示。

图6 石刻字体图像数据集A和石刻字体骨架数据集B
2.2 ReLU、PReLU与RPReLU函数
过去通用采用的经典激活函数多为饱和激活函数(如sigmoid,tanh),但此类函数在饱和时梯度接近于0,导致函数收敛速度变慢。因为,近年来通过生物学角度提出了一种更精确模仿脑神经元的激活函数ReLU(纠正线性单元),这是一种不饱和的激活函数,有效解决了梯度消失问题,极大加快了收敛速度[8],其数学公式如式(1)所示,函数曲线如图7(a)所示
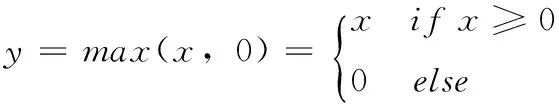
(1)
式中:x——隐藏层单元的输入。当x>0时,ReLU以梯度1被激活,为不饱和的函数。这可以在神经网络学习时,有效减轻梯度消失的问题,防止反向传播时局部梯度和该单元输出梯度相乘等于0的情况,极大提高了学习效率。当x≤0时,ReLU为饱和函数且输出为0,这使得神经元具有适当的稀疏性,可以更快更好地学习稀疏特征。
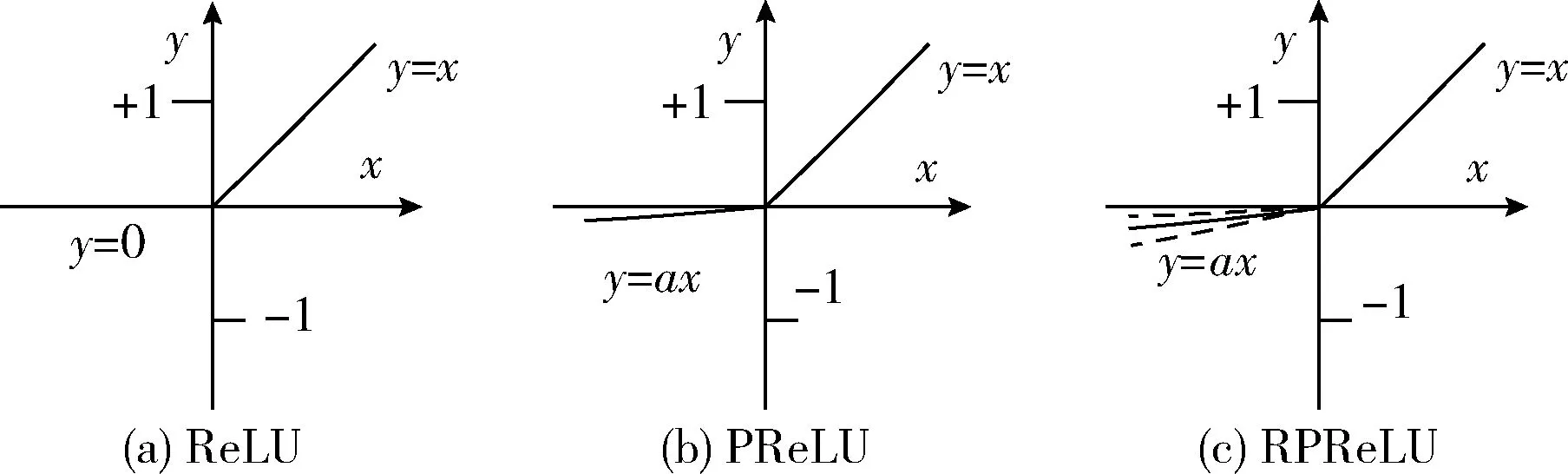
图7 ReLU/PReLU/RPReLU激活函数曲线
ReLU在输入为负时饱和这一特点,有利于识别不同大小的关键特征,使学习到的特征相对稀疏,起到自动解离的作用。但在训练时,当部分输入落入饱和区域时,会导致权重无法再被更新。ReLU的这一问题会使神经网络中部分神经元无法再被激活,导致数据多样化的丢失。
为了ReLU带来的部分神经元“死亡”问题,微软亚洲研究院的何凯明等[9]提出参数化纠正线性单元(parametric rectified linear unit,PReLU),其定义如式(2)所示
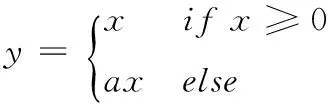
(2)
式中:固定a为区间(0,+∞)内的一个不变参数,函数曲线如图7(b)所示。当a=0时,则退化为ReLU。如果a是一个很小的固定值(如a=0.001),则PReLU退化为LReLU(leaky rectified linear unit)。
PReLU对ReLU函数的负部分由输出为0改为一个斜率很小的倾斜,同时保留正部分不变。当隐藏层输入x小于0时,存在一个很小的梯度,使整个激活值区域都不饱和,从而一定程度解决了部分隐藏层的神经在训练时无法被激活的问题。同时保留了ReLU在可以在反向传播中解决梯度弥散,快速更新神经网络参数的优点。
随机参数纠正线性单元(random parametric rectified li-near unit,RPReLU)是PReLU的随机版本[10],见式(3)
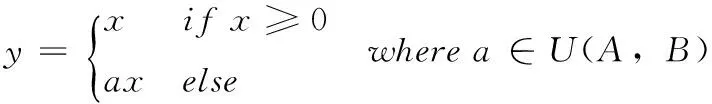
(3)
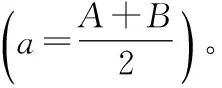
RPReLU和PReLU都具有适度稀疏性,然而由于RPReLU在a值选取上的随机性,使得其在优化学习的过程中会比PReLU更加鲁棒。
2.3 Dropout正则化
在一个较大的络中,如果数据集较小,系统能产生局部收敛导致过拟合。使训练后的模型在测试中分类效果较差。为解决这一问题,提出了随机隐退[11](Dropout)这一方法。Dropout是深度网络的一种重要的正则化方法,其思想是在训练中以一定概率,随机把隐含层的一些节点置0,使其不工作,但保留权重;每次更新网络权值时,隐含节点会随机出现,使两个节点并非每次都同时出现,避免了某些结点必须和另一结点共同出现才有作用的情况。这样可防止特征间互相依赖,使训练出来的模型具有更强的鲁棒性。
3 实验设计和对比
3.1 CNN网络结构搭建(CNN-1)
本文搭建的卷积神经网络的结构如图1所示,命名为CNN-1,用符号法可以描述为:256×256-96C(3,3,4)-MP(3,3,2)-256C(5,5,1)-MP(3,3,2)-384C(3,3,1)-384C(3,3,1)-MP(3,3,2)-256C(3,3,1)-MP(3,3,2)-4096FC-1024FC-6N。
各符号的含义为:“-”表示CNN的相邻层;“256×256”表示输入图像的大小;“96C(3,3,4)” 中C表示该层为卷积层,“96”为卷积层特征映射图的数量,“(3,3,4)”表示卷积核的尺寸是3×3,步长为4;“MP(3,3,2)”中“MP”表示该层为Max-pooling层,“(3,3,2)”代表pooling区域大小是3×3,步长为2;“4096FC”中FC代表是全连接层,“4096”代表该层节点数量。
其中采用激活函数为RPReLU的5个卷积层、4个池化层作为采样阶段;采用加入Dropout层的两个全连接层和一个6维的输出层为识别阶段。
3.2 多图像特征融合(CNN-2)
每个石刻字体的原始图像和骨架图像都包含有笔迹的特征信息。石刻字体原始图像与骨架图像都是描述同一石刻字体。主要思想为:首先使用CNN-1网络分别对含有原始石刻字体图像的数据集A和含有石刻字体骨架图像的数据集B分别提取特征;之后拼接两者提取的特征,融合识别后获得更高层次的特征,该网络命名为CNN-2。该方法主要包含以下步骤:
(1)分别将数据集A和数据集B中的石刻字体图像输入CNN-1网络;
(2)将上一步中CNN-1网络中最后一个隐含层(1024FC),拼接成新的特征层,该特征层维度为2048(1024×2);
(3)将上一步中生成的特征层作为DNN的输入层,训练一个新的DNN模型,用于最终的结果。该DNN结构为2048FC-1000FC-1000FC-6N,即该网络共4层,输入2048个节点,2层1000个节点的隐含层;
(4)利用softmax识别器输出6个节点,对应6位石刻字体作者。
本文搭建的卷积神经网络如图8所示。为提高性能,FC8,FC9每层都接入Dropout来防止过拟合、增强泛化能力。
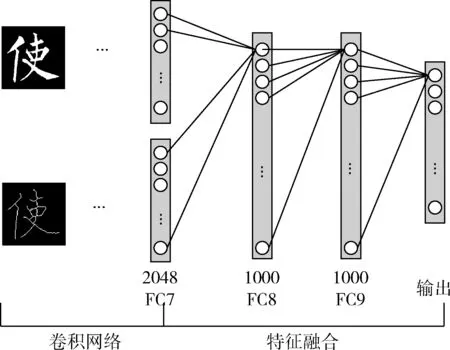
图8 CNN-2特征融合
4 实验结果及分析
本文实验软硬件环境为CPU Intel Core i7-4720,GPU NVidia GTX970M,内存8G。实验数据来自CADAL数字图书馆的书法类目,收集了6位不同作者的书法字,经预处理后建立数据集A和B,采用CAFFE(convolutional architecture for fast feature embedding)深度学习框架,支持命令行、Python和Matlab接口,支持调用GPU(图形处理器)加速运行。
CNN模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过多次的迭代训练提高网络的精度,迭代次数是构建高效模型的一个重要参数,随着迭代次数增加,准确率趋向于定值。但模型训练时间就越久,则可能产生过拟合,使模型仅对训练数据效果好,却在实际应用中效果较差。对此,本文对迭代次数与准确率、消耗时间的关系进行了实验果如图9所示。图中,横轴为迭代次数,左侧纵坐标为准确率(%),右侧纵坐标为消耗的时间(分钟)。分析三者间关系,本文迭代次数采用6000次。
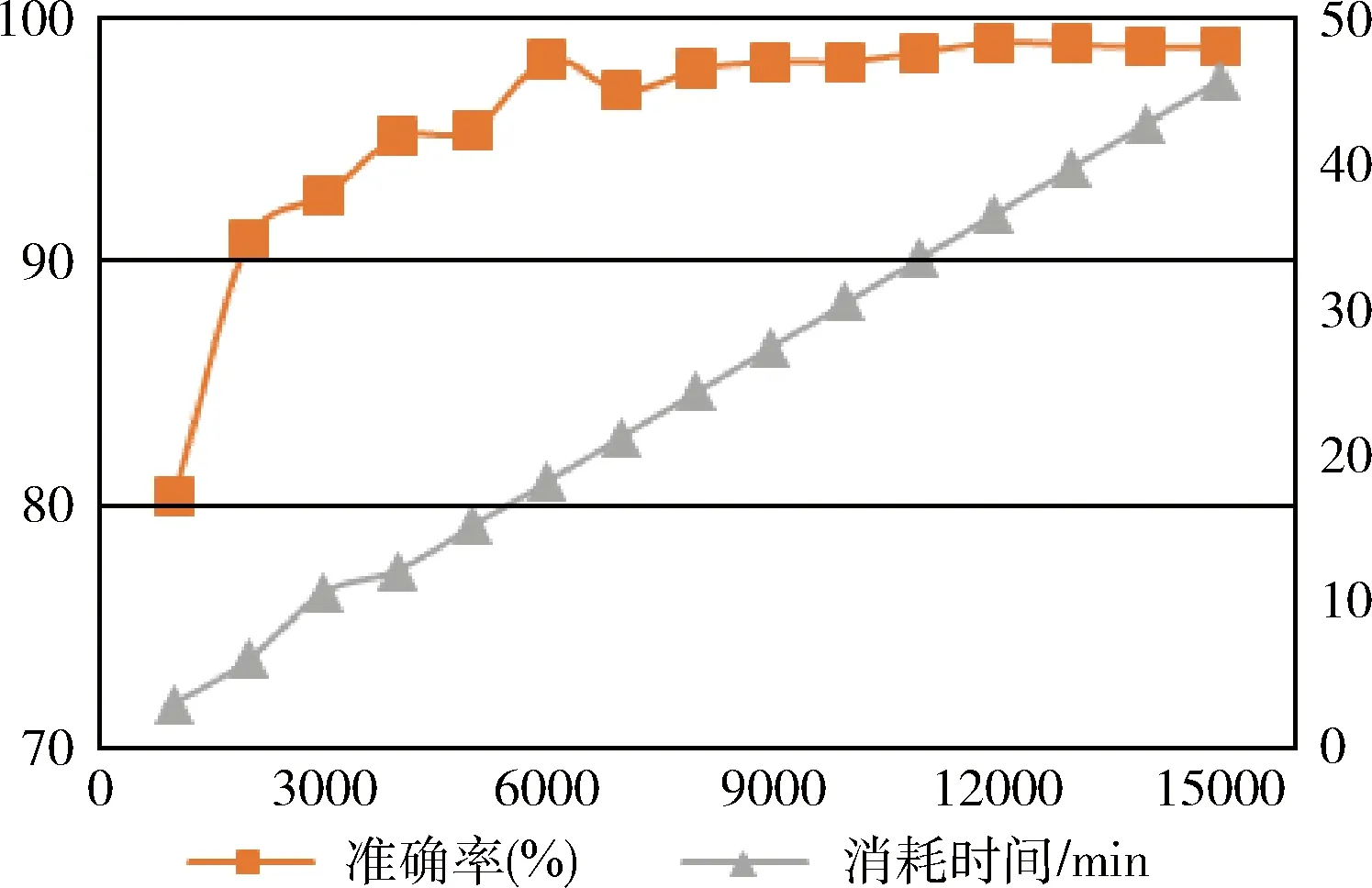
图9 迭代次数与准确率、消耗时间的关系
实验中,首先按本文第3.1节的方法建立样本数据库,后按第4小节的方法,分别测试字体图像和字体骨架图像通过CNN-1网络的分类效果。再特征融合两者的特征,使用CNN-2网络分类验证方法的有效性。作为对比,采用之前效果较好的方法作为对照,采用使用效果较好的Gabor方法作为对比,参数设置参考文献[12]。
为获取更多的有效果信息,验证方法的鲁棒性,实验中将每位作者的笔迹随机分为n份(n=5),每次取出4份作为训练数据样本,1份作为验证数据样本,取平均值作为最后的结果。同时,为验证笔迹样本数量对识别的影响,实验中分别选取不同的原始样本数N进行测试。每位作家或书写者有相同数量的样本集(N/6)。N分别选取3000、5000、8000、12 000,实验结果见表1。
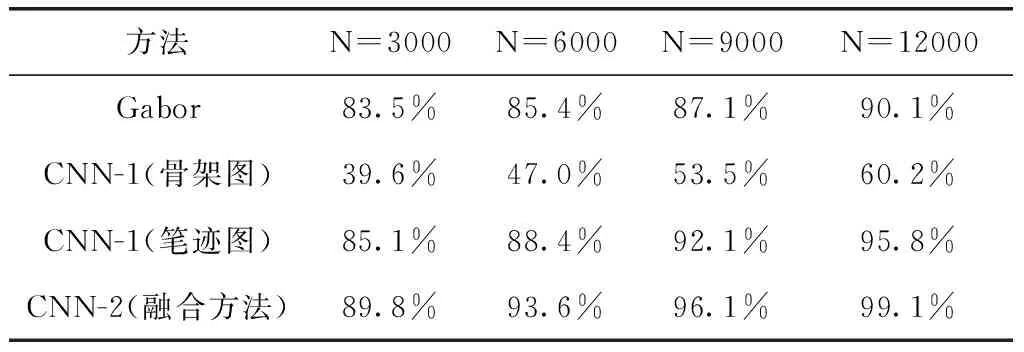
表1 笔迹样本交叉验证识别率
由表1可以后出,Gabor方法较为不理想,是因为该方法一般针对整篇文章,而碑帖、书法字文本较为零碎,且笔迹纹理块生成依赖字符拼接来,不同的组合会使纹理本身发生变化。
CNN-1网络用于笔迹骨架图像上时,效果不理想。因为在提取骨架的过程中丢失了很多细节,如笔划粗细、笔锋角度,但仍保留一定的特征。CNN-1网络应用在预处理后的笔迹图像上得到的结果,效果较好,已经超越Gabor方法,表现出了卷积神经网络在图像识别上的优越性。CNN-2融合了前两种CNN网络已提取的特征,即将前两种方法中已提取的高层次拼接,再利用神经网络,获得更高层次的特征。表中的实验数据表明,该方法有效提高了识别的准确率。
同时,从表1中看出,随着样本数量的增加,几种方法的识别准确率都有一定提高。卷积神经网络作为大数据训练的一种方法,样本数量对其有较大的影响,提高样本数可以让卷积神经网络拥有更强的特征表达能力。
5 结束语
本文针对笔迹鉴定中的特征提取问题,提出了一种改进的深度卷积神经网络。一方面通过引入RPReLU激活函数、Dropout和对数据进行旋转防止过拟合,提高了运算效率。一方面通过少量人工干预,从不同方面描述同一石刻字体图片,融合两种特征来提升识别的准确率。通过与Gabor、GMRF方法进行实验对比可见,本文方法的识别准确率大大提高,验证了该方法是一种高效的方法。此外,本方法在特征提取过程中自动提取了大量特征点,下一步将研究如何利用这些特征点,进一步自动模仿生成相应风格的石刻字体。
[1]CHEN Rui,TANG Yan.Writer verification for Chinese handwritten documents based on keyword extraction[J].Journal of Sichuan University (Natural Science Edition),2013(4):719-727(in Chinese).[陈睿,唐雁.基于关键词提取的手写汉字文本依存笔迹鉴别技术[J].四川大学学报(自然科学版),2013(4):719-727.]
[2]LI Qingwu,MA Yunpeng,ZHOU Yan,et al.Method of writer identification based on curvature of strokes[J].Journal of Chinese Information Processing,2016,30(5):209-215(in Chinese).[李庆武,马云鹏,周妍,等.基于笔画曲率特征的笔迹鉴别方法[J].中文信息学报,2016,30(5):209-215.]
[3]Mao T,Wu J,Gao P,et al.Calligraphy word style recognition by KNN based feature library filtering[C]//Proc of the 3rd International Conference on Multimedia Technology,2013:934-941.
[4]WANG Xiao,LYU Xiaoqing,TANG Zhi.Optical font recognition of Chinese based on the stroke tip similarity[J].Acta Scientiarum Naturalism Universities Pekinensis,2013,49(1):54-60(in Chinese).[王晓,吕肖庆,汤帜.基于笔端形状相似性的汉字字体识别[J].北京大学学报(自然科学版),2013,49(1):54-60.]
[5]QIU Juan,XIE Hao,ZHANG Chuanlin.Handwriting feature extraction method based on optimal Gabor filter and GMRF[J].Computer Engineering and Applications,2015,51(17):145-150(in Chinese).[邱娟,谢昊,张传林.基于优化Gabor滤波器和GMRF的笔迹特征提取方法[J].计算机工程与应用,2015,51(17):145-150.]
[6]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012:1106-1114.
[7]ZHANG Jiulong,WANG Xiani,ZHANG Zhendong,et al.An optimization algorithm for Chinese characters skeleton extraction[J].Journal of Xi’an University of Technology,2016,32(1):35-38(in Chinese).[张九龙,王夏妮,张镇东,等.一种书法字骨架提取优化方法[J].西安理工大学学报,2016,32(1):35-38.]
[8]Tóth L.Phone recognition with deep sparse rectifier neural networks[C]//IEEE International Conference on Acoustics,Speech and Signal Processing,2013:6985-6989.
[9]He K,Zhang X,Ren S,et al.Delving deep into rectifiers:Surpassing human-level performance on image net classification[C]//Proceedings of the IEEE International Conference on Computer vision,2015:1026-1034.
[10]Iandola F N,Moskewicz M W,Ashraf K,et al.FireCaffe:Near-linear acceleration of deep neural network training on compute clusters[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:2592-2600.
[11]Hinton G E,Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[12]Nusaibath C,Ameera Mol P M.Off-line handwritten Malayalam character recognition using Gabor filters[J].Internatio-nal Journal of Computer Trends and Technology,2013,4(8):2476-2479.
