数据驱动的任务图执行中并发构图方法
2018-03-19孟现粉郭聪聪
王 松,花 嵘,孟现粉,郭聪聪,傅 游
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引 言
目前,已有的结构化网格应用的编程框架主要有deal.II[1]、libMesh[2]、Chombo[3]等。这些框架针对分布主存的计算系统,在通信、负载平衡等各个方面做了大量的设计和改进,但是面对结构多样、存储层次复杂的多核体系结构并没有提供有效的解决方案[4]。
为了挖掘网格应用在多核平台上的任务图并行潜力,中国科学院计算技术研究所设计并开发了AceMesh任务调度系统作为运行时库[5],以支持网格应用基于数据驱动的任务图并行,但该系统的任务图构建是在并行执行前一次性完成,随后在构建的任务图基础上进行任务的调度、执行。在超大规模计算任务的情况下,构图时间开销占到整个程序执行时间的30%左右,并随着计算线程数的增加而增大。
本文以AceMesh任务调度系统为基础,提出了并发构图方法,优化了整个并行化调度执行过程,然后在多核平台上对案例进行大规模数据集测试,对比了并发构图和原有构图方案的性能,验证了并发构图方法的性能。
1 AceMesh任务调度系统构图过程分析
调用AceMesh并行化程序时,程序中可有向无环图(directed acyclic graph,DAG)并行化的区域必须是一个无嵌套的单入单出的结构化代码段[6,7]。AceMesh最初设计为单线程执行,在遇到DAG并行区域后通过线程初始化程序构造一个以它为主线程的线程池[8],该线程池中的所有线程共享DAG并行区域中的所有任务。
AceMesh任务调度主要分为依次执行的两个阶段:DAG图构建阶段和执行阶段。本文的研究对象集中在DAG图构建阶段。
DAG图构建包括任务构造和任务注册。任务构造是将用户代码中的数据访问区间进行分割,并将因空间分割而带来的与通信相关的邻接关系、读写信息、变量地址等封装成为可执行任务[9,10]。而任务注册是为可执行任务分配内存空间,建立当前注册任务与已注册任务之间的逻辑依赖关系,并对没有前驱和没有后继的任务进行分别记录,将一个空任务作为所有无后继任务的垂直后继,以便于任务图的调度执行和终止检查[11,12]。
DAG图构建阶段利用一个哈希表(图1)来记录地址信息。哈希表的读写信息中的r-tasks记录一组对该地址的最近读任务,而w_task记录对该地址的最后一个写任务。若代码中被访问的某一数据地址不在哈希表中,需在表中为其增加一个新表项,并记录读写信息;若数据地址已在哈希表中,则按照对该地址的读、写操作对其读写信息进行更新。
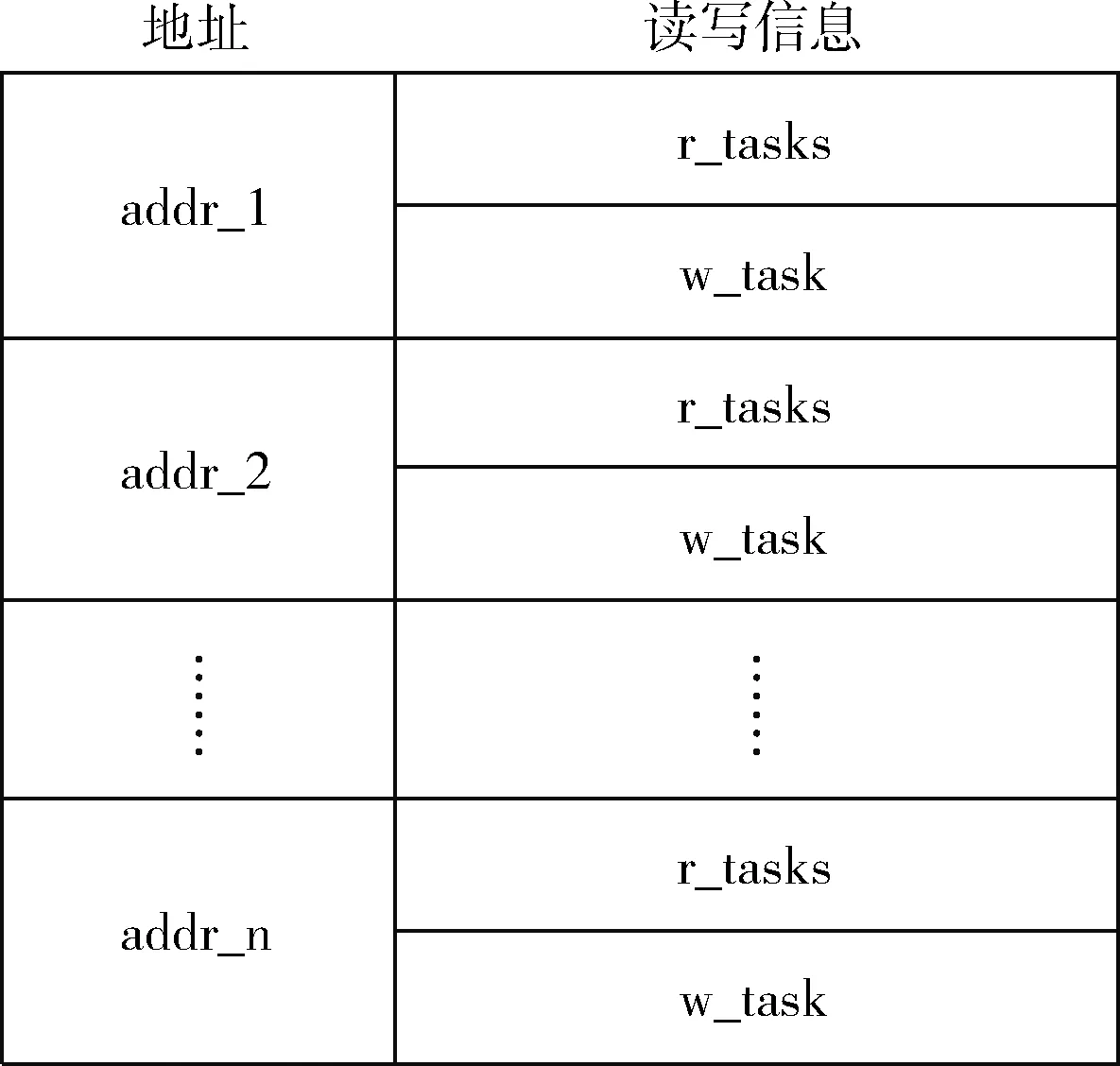
图1 哈希表结构
哈希表中某一地址项的读写信息随着对该地址的读、写操作而不断变化。任务之间的依赖关系也由对同一地址的新注册任务和已有注册任务读写操作的相关性而确定。
已经记录的没有前驱的任务会被优先调度执行。在执行过程中,其它任务会依据其前驱任务的执行情况而被调度执行。当空任务的引用计数随着前驱任务的执行递减为零时表示DAG图全部执行完成,哈希表中的信息也将会被删除[13]。
2 任务图规模决定因素和并发构图性能分析
根据DAG图构建过程分析,DAG图的规模由以下3个因素决定:
(1)迭代次数。迭代次数的增加会使DAG图的层次数增加,整个任务图的任务数也随之增加;
(2)数据规模。数据规模的扩大会使每一层循环的任务数增加,在分块尺寸固定的情况下,数据规模越大,划分的任务数越多;
(3)分块尺寸。分块尺寸指划分后的数据块大小,块数与任务数相对应。分块尺寸越小,任务数越大。
在实际测试中,任务图的规模往往较大。以Chombo中AMRPoisson为例,其一个进程内就有数以百万计的任务。
串行构图的调度系统的程序执行时间为
To=Tg+Texe
(1)
其中,To表示程序总的执行时间,Tg表示构图时间,Texe表示图执行时间。
并发构图的调度系统的程序执行时间为
(2)
其中,Tp表示并发构图后程序的总执行时间,N表示流水段数。
当任务规模不变时,通过并发构图隐藏的时间为
(3)
则r表示并发构图相对于串行构图总时间的性能提升率为
(4)
Tg越大则r越小,即,构图时间越大,性能提升率越高。
3 数据驱动的任务图并行中并发构图方法
并发构图是指在构图的同时进行图执行。开始调用AceMesh时初始化计算线程,主线程和执行线程会同时运行。通过建立“生产者-消费者”之间的数据流动关系,则不需要增加显式通信,两者可以并发执行。并发构图改变了任务调度执行的时机,不必等待DAG图全部构建完成,在构图过程中即可分批调度任务执行。在并发构图的过程中,新的任务不断地生成,同时也有任务不断地被执行,执行完成的任务不再有任何数据依赖,任务间数据依赖的建立需要适应随时有任务被执行完成的情况。为此,本文提出了一种哈希表维护策略。
3.1 并发构图无前驱任务的随时派生
在任务注册阶段,需在一个列表中记录所有的一级就绪任务,即无前驱的任务。构图完成后,主线程对一级就绪任务进行派生操作,由线程调度器自动进行图执行。
串行构图时,已经记录了所有需要发起执行的任务。而并发构图中,随时会有任务结束,一些新注册的任务因为没有检测到前驱,而成为无前驱的任务。因此,在并发构图中,必须随时处理新生成的、无前驱的任务。解决方法就是在任务注册阶段,随时派生新生成的、无前驱的任务。
3.2 并发构图下的哈希表维护
在执行流程为依次进行的情况下,系统需要记录对于同一地址的最近读写信息,才能进行动态的依赖分析。为提高依赖测试效率,对每一个必要的变量地址维护一个哈希表项。通过搜索哈希表中的表项内容,可以建立与前驱任务之间的依赖关系。当某个任务需建立依赖关系时,所有前驱任务都未执行,从而那些任务指针都未被释放,哈希表项中的任务指针都可访问。
由于并发构图会出现某个任务在注册的同时,有部分前驱任务已执行完成或正在执行的情况,其中已完成的任务在哈希表中随即被释放,哈希表项中的对应任务指针不可访问。此时注册的任务与已经完成的前驱任务之间不应建立依赖关系,需要对哈希表进行维护。
延迟释放是维护哈希表的基本思路,按照时机,又分为最晚释放和最早释放两种策略。最晚释放是指被执行完的任务并不立即释放,而是拖延到整个程序结束再统一释放,此策略对存储资源的浪费严重。而最早释放实质上是一种需求驱动的释放策略,本文采用该策略进行任务释放。
实际上如果某个任务一直不被释放,则会一直保留在哈希表中,并随着应用的执行变化而改变其引用计数值:在并发构图-执行时,随着任务引用的增加,其引用计数逐渐从0上升到某正数;随着该任务引用数的减少,其引用计数降低到某正数直至0,或随引用数稳定而固定在一个值,该过程不一定是单调的如图2所示。

图2 任务引用计数变化情况
某个任务进入哈希表后,直到DAG图被执行完之前,其任务指针始终存在于哈希表的某些项中。
3.3 需求驱动的任务延迟释放策略
需求驱动的任务延迟释放策略将根据任务在哈希表中的引用计数决定何时释放该任务,其主要思想是:若某任务执行结束时,检测到引用计数为0,则释放该任务;一直没有释放的任务,会在DAG图执行完成后统一释放。
与一个任务相关的前驱任务可能有多个,为了判断哈希表中的某项是最后一个与该任务相关的任务项,给每个任务增加了两个参数:任务的判断状态finished和任务在哈希表中的引用计数refcnt4hash。在多线程的环境下,注册线程和执行线程可能会访问同一个任务,并且任务的状态和引用计数随时间发生变化,需要保证转换动作的原子性,以保证程序的正确性和线程安全性。
定义任务的状态集Q={未结束,已结束,等待释放,需释放,已释放},初始化状态为“未结束”,终止状态为“已释放”;定义事件集δ={refcnt4hash更新,调度器执行,调度器发现refcnt4hash≠0,调度器发现refcnt4hash=0,注册代码发现refcnt4hash=0,释放,DAG结束释放}。
任务注册代码和线程执行代码共同维护任务的状态。任务注册时,设定任务的finished为false,设refcnt4hash为零。根据读取的任务t的状态来决定是否建立t与后继的依赖关系:若t为“未结束”,则可建立依赖关系,若t为“结束”,则不建立依赖关系。线程在执行完任务t后,设置任务t的finished为true,此时若refcnt4hash=0,则立即释放任务t;若refcnt4hash≠0,则只有在为一个新注册任务建立依赖关系并检测到有依赖关系的某个前驱任务的refcnt4hash=0时,才将该任务立即释放。任务的状态转换过程如图3所示。
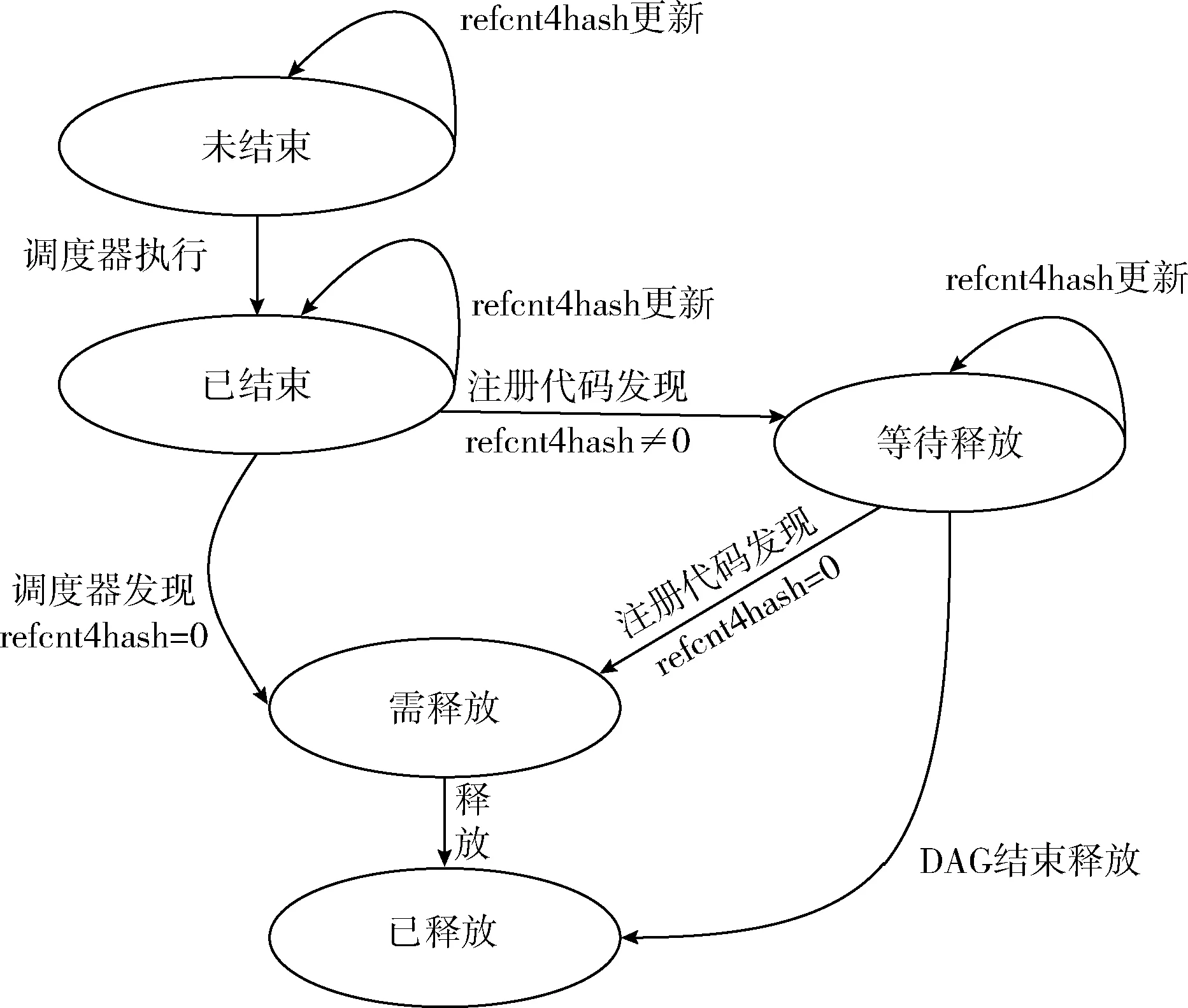
图3 并发构图情况下任务的状态转换
综上,需求驱动释放是根据任务在哈希表中的计数情况,适时释放执行完成的任务。当任务执行完成后不再与后继任务有依赖关系,不需要再对该任务进行任何操作时,释放占用的内存空间,避免内存资源的浪费。对程序结束后仍然存在于哈希表中的任务进行统一释放,避免内存泄漏。
3.4 并发构图的安全终止检查方案
并发构图情况下,做终止检查时,需及时删除无后继任务列表中已执行完成的任务指针,否则会出现内存浪费和DAG图死循环。
为解决这个问题,本文设计了基于无后继任务收集的即时终止方案,包括3个过程:①获得所有无后继任务的列表;②过滤已经执行完成的无后继任务,即将已完成的任务从列表中删除;③为列表中剩余的每个任务追加同一个空任务。
在建立依赖关系时已经得到了所有无后继的任务,即最后一层的任务,所有无后继任务一定是最晚释放的任务,也是最后进入哈希表的任务,可以通过任务指针被访问到。
当空任务的refcnt4hash为0时,DAG图全部执行完毕。
4 实验结果和评价
本节对并发构图策略下多线程执行的总时间进行测试,并与串行构图的情况进行比较。
本文选用曙光I950r-G作为测试平台,该平台操作系统为Red Hat Enterprise Linux 6.3,操作系统内核版本为2.6.32.279,TBB版本为4.1。测试环境中,采用了Intel的icc 13.1.0作为C/C++的编译器。测试程序为无patch的3d7p-stencil迭代计算。
无patch的3d7p-stencil的计算原理为
Bx,y,z(t+1)=αAx,y,z(t)+β(Ax-1,y,z(t)+Ax+1,y,z(t)+
Ax,y-1,z(t)+Ax,y+1,z(t)+Ax,y,z-1(t)+Ax,y,z+1(t))
(5)
B数组t+1时刻的 (x,y,z) 点数值取决于A数组t时刻的 (x,y,z)、 (x-1,y,z)、 (x+1,y,z)、 (x,y-1,z)、(x,y+1,z)、 (x,y,z-1)、 (x,y,z+1) 共7点的数值。
3d7p stencil计算的计算区域是256*256*256的三维立体空间,共迭代2000次,采用4×4二维分块。3d7p并发构图相对于串行构图的总时间对比如图4所示。
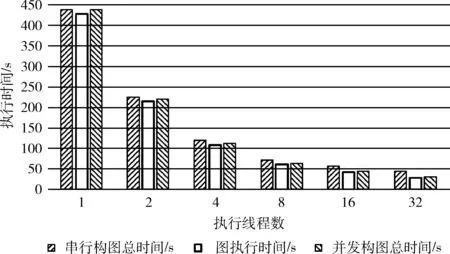
图4 3d7p并发构图与串行构图性能对比
由表1中的数据和图4中的性能对比结果表明,图的执行时间与串行构图执行总时间非常接近,即图执行过程在总体执行过程中占据了很大的比例。同时,图的注册时间也相对稳定。可以通过边构图边执行的策略使性能得到一定程度的提高。
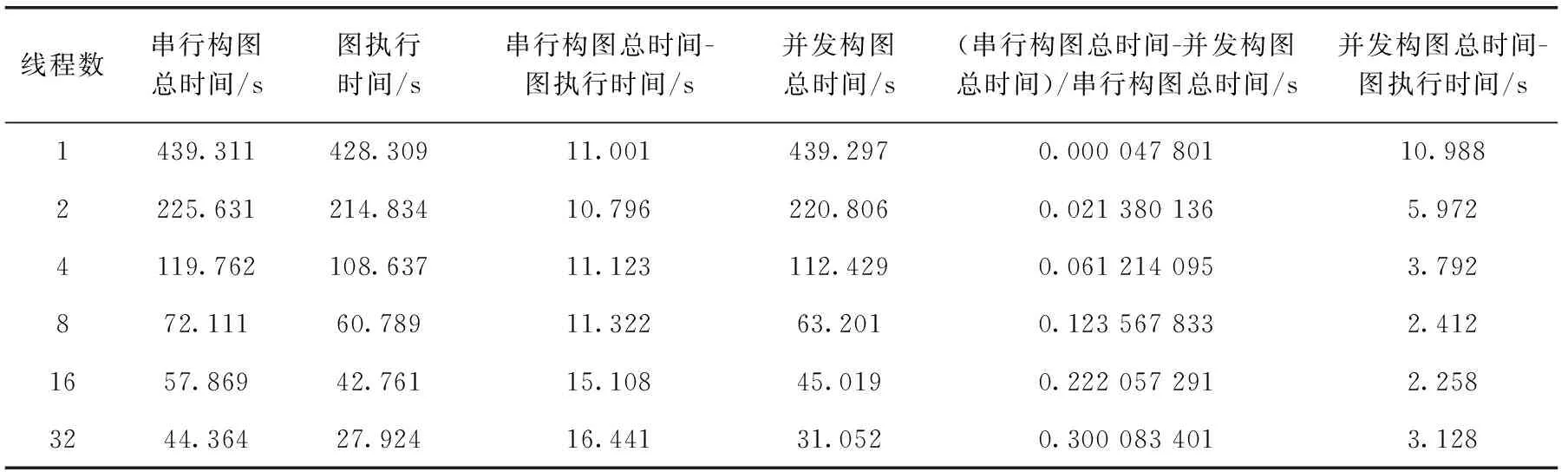
表1 3d7p两阶段执行模式下与并发构图性能对比
由表1中的数据表明,并发构图与串行构图相比,在2、4、8、16、32线程情况下性能分别提升了2%、6%、12%、22%、30%;在2、4、8、16、32线程情况下,并发构图相对于串行构图总时间分别隐藏了4.824 s、7.331 s、8.911 s、12.850 s、13.313 s;在2、4、8、16、32线程情况下,图构建时间的性能提升分别为45%、66%、79%、85%、81%。
可见,并发构图方法下程序执行的总时间与串行构图执行总时间相比,不同线程数下有不同程度的性能提升,线程数越大,性能提升越明显。
5 结束语
AceMesh任务调度系统的开发,降低了结构化网格应用并行化的难度,同时提升了执行效率。由于采用了两阶段执行的方案,构图阶段占用了大量的执行时间。
本文针对于构图时间所占总时间比例大的问题,提出了并发构图的方案,隐藏了任务图执行中构图时间,优化了AceMesh的调度执行过程。还对哈希表的维护策略、任务调度时机、任务图终止检查、任务释放等构图阶段的关键环节进行了优化,并通过算例的大规模数据集测试验证了并发构图方法的性能。
[1]Bangerth W,Hartmann R,Kanschat G.Deal.II—A general-purpose object-oriented finite element library[J].ACM Tran-sactions on Mathematical Software,2007,33(4):467-473.
[2]Kirk B S,Peterson J W,Stogner R H,et al.libMesh:A C++ library for parallel adaptive mesh refinement/coarsening simulations[J].Engineering with Computers,2006,22(3-4):237-254.
[3]Nordén M,Holmgren S,Thuné M.OpenMP versus MPI for PDE solvers based on regular sparse numerical operators[C]//International Conference on Computational Science.Springer Berlin Heidelberg,2002:681-690.
[4]Meng Q,Luitjens J,Berzins M.Dynamic task scheduling for the Uintah framework[C]//IEEE Workshop on Many-Task Computing on Grids and Supercomputers.IEEE,2010:1-10.
[5]HOU Xionghui.Research on task scheduling techniques for optimizing data reuse in grid applications[D].Beijing:University of Chinese Academy of Sciences,2014(in Chinese).[侯雄辉.网格应用中优化数据重用的任务调度技术研究[D].北京:中国科学院大学,2014.]
[6]WANG Lei,CUI Huimin,CHEN Li,et al.Research and development task parallel programming models[J].Journal of Software,2013,24(1):77-90(in Chinese).[王蕾,崔慧敏,陈莉,等.任务并行编程模型研究与进展[J].软件学报,2013,24(1):77-90.]
[7]Nguyen T,Cicotti P,Bylaska E,et al.Bamboo:Translating MPI applications to a latency-tolerant,data-driven form[C]//Proceedings of the International Conference on High Performance Computing,Networking,Storage and Analysis.IEEE Computer Society Press,2012.
[8]Acar U A,Chargueraud A,Rainey M.Scheduling parallel programs by work stealing with private deques[J].ACM Sigplan Notices,2013,48(8):219-228.
[9]Williams S,Kalamkar D D,Singh A,et al.Optimization of geometric multigrid for emerging multi-and manycore processors[C]//Proceedings of the International Conference on High Performance Computing,Networking,Storage and Analysis.IEEE Computer Society Press,2012:96.
[10]Chen L,Huo W,Long X J,et al.Parallel programming languages on multi-core and many-core architectures[J].Information Technology Letter,2012,10(1):23-40.
[11]Lee I,Angelina T,Boyd-Wickizer S,et al.Using memory mapping to support cactus stacks in work-stealing runtime systems[C]//Proceedings of the 19th International Conference on Parllel Architectures and Compilation Techniques.ACM,2010:411-420.
[12]Olivier S L,Porterfield A K,Wheeler K B,et al.Scheduling task parallelism on multi-socket multicore systems[C]//Proceedings of the 1st International Workshop on Runtime and Operating Systems for Supercomputers.ACM,2011:49-56.
[13]Cao Y J,Qian D P,Wei-Guo W U,et al.Adaptive scheduling algorithm based on dynamic core-resource partitions for many-core processor systems[J].Journal of Software,2012,712(2):240-252.
