边界先验和自适应区域合并的显著性检测
2018-03-19翟继友屠立忠庄严
翟继友,屠立忠,庄严
1.南京工程学院计算机工程学院,南京211167
2.河海大学计算机与信息学院,南京211100
边界先验和自适应区域合并的显著性检测
翟继友1,2,屠立忠1,庄严1
1.南京工程学院计算机工程学院,南京211167
2.河海大学计算机与信息学院,南京211100
CNKI网络出版:2017-04-01,http://kns.cnki.net/kcms/detail/11.2127.TP.20170401.0914.058.html
1 引言
视觉显著性检测是神经生物科学、认知心理科学和计算科学等多学科交叉的问题,它利用人的视觉原理,挖掘出当前图像中最能吸引人的或者最突出的目标。近20年来,图像显著性区域检测一直是计算机视觉等领域的一个研究热点。在视觉显著性问题研究过程中,最早的研究目标是预测眼光在当前图像停留的位置。到目前为止,该技术发展为检测当前图像区域中所包含的显著性目标并已取得相当大的进展,国内外研究人员已提出了成百上千种视觉显著性检测模型。目前,视觉注意算法主要围绕自顶向下和自底向上两种机制进行展开[1]。自底向上的方法基于数据驱动,利用图像底层特征作为基础数据来源去驱动任务的执行并对显著性区域进行感知[2]。在自顶向下的方法是基于任务驱动的,它跟目标识别的先验知识密切相关,比如任务的定义、目标分布、图像背景等。
由于该技术的实现过程简单、可靠、快速,能够提高对象识别、跟踪和检测的准确性,使其在图像分割、目标识别与跟踪、机器视觉等诸多领域都有着广泛的应用[3]。例如,Han等[4]人在马尔科夫随机场理论的基础上突出当前图像中的显著性信息,辅助完成图像的分割;钱晓亮[5]针对现有的基于频域的视觉显著性检测算法检测准确度不高的弱点,提出了一种基于加权稀疏编码的频域算法,有效地检测到显著的中心区域和周围的背景,但是产生的显著性映射易受到图像高频部分的影响;Gopalakrishnan等人[6]将使用随机游走预测未标记标签,但是随机游走产生的显著点的数目和位置比较难确定,其结果对选择的种子很敏感。最近,有人提出一种探索背景先验信息的显著性提取方法[7],该方法主要出发点是背景区域之间的距离比显著目标区域和背景区域之间的距离要小的理论。基于这个理论,节点标记任务(显著目标或背景)可以定义为能量最小化问题,但在处理大型图像数据库时,单一采用对比度先验信息还存在一定缺陷。为了避免这样的情况发生,文献[8]将图像的四条边分别作为背景的种子节点,然后利用传播机制对种子节点进行显著性信息扩散,生成四个子显著图,最后将四个子显著图融合成最终的显著图结果。然而这种方法在显著性目标稍微接触图像的边界时,边界假设是脆弱的甚至会失败。文献[9]中提出交互式图像分割算法,该算法虽能得到较好的分割结果,但在分割图像之前需要为图像进行人工标定标签,不适合大规模图像库;另外,用户标定标签存在随意性,分割结果千差万别。由此可见,视觉显著性检测仍然是一项极具挑战、亟待进一步发展的课题。针对现有的图像显著性区域检测算法中显著性区域检测不准确与阈值依赖问题,本文提出了一种基于边界先验和自适应区域合并的显著性检测算法。
2 相关工作
2.1 初始分割与图的构建
图模型能兼顾图像的局部信息和全局信息,本文将以图模型为基础进行显著性区域检测。图模型的基本原理是将图像以图的形式进行表示。如果直接从像素级别进行图模型的构建,计算量非常大。超像素是把特征相似的像素集中在一起形成一个基本的处理单元,更好地包含了图像的结构化信息,相比像素级而言,它不仅解决了计算量大的问题,也能较好地表示图的特征,已被广泛用于计算机视觉等领域。在多个超像素分割算法中,简单线性迭代聚类(Simple Linear Iterative Cluster,SLIC)算法[10]不仅运算效率高并且能在生成超像素的同时对图像中的像素进行初等分类,为后续显著性特征提取打下良好基础。因此,本文采用SLIC算法把图像进行过分割,以超像素区域内所有像素特征的均值为超像素的特征,通过把超像素看做图的一个顶点来进行构图。即首先把给定的输入图像过分割成n个超像素,并构建一个图G=<V,E>,其中V表示图中的节点集,E表示无向边集。vi∈V表示跟超像素对应的节点。wij=w(vi,vj)表示边(vi,vj)∈E的权重。这里使用文献[11]中边的连接方案,使图像所有边界节点相互连接,即每个节点不仅跟它的邻居节点相连,也跟它邻居的邻居节点相连,这种节点连接方式能完整保留全局信息。
2.2 边界先验
人们在拍摄图像时,常把注意点放在靠近图像中心的位置,一般不会把显著目标聚焦在图像边界上,所以边界先验比中心先验更具说服力,越来越多的自底向上模型更倾向使用图像的边界作为背景种子。然而,图像边界中的一部分可能被显著目标所占据,如果输入图像的边界被前景物体所占用,在基于背景的显著性检测中可能导致不恰当的结果。因此,本文首先通过定位和消除错误边界来优化边界影响。
鉴于背景和显著物体之间的颜色和对比度有明显差异,错误的边界相比其他三个往往具有独特的颜色分布。因此,把超像素边界看成连通区域并分别计算它们归一化的像素级RGB直方图:

式中,b∈{}
top,bottom,left,right表示图像四个边界的位置;n表示目标区域中的总像素;h=0,1,…,255是灰度值变量;Iq表示像素q的强度值;δ()⋅是单位脉冲函数;R,G,B三个通道分别用256灰度值进行计算。之后,计算四个直方图中的两两欧氏距离:
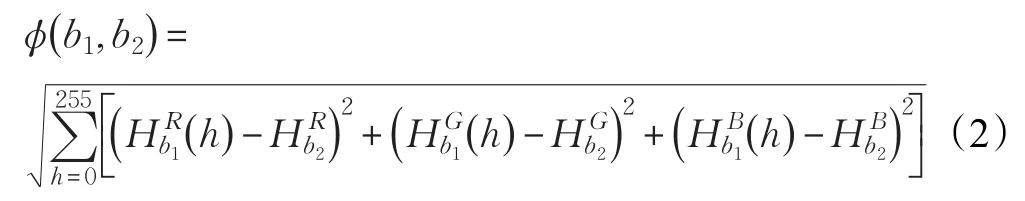
将结果组成4×4的矩阵φ并对列进行求和,其中最大值对应的边将被删除。比如,如果第二列的和最大,则把底边删除。这样得到背景基准集中存在很少的噪声,有助于提升下一阶段显著性检测的准确度。
3 自适应区域合并
3.1 初始种子节点选取
在缺少先验信息的背景下来确定初始种子节点相对困难。因此,在文献[12]的基础上来定义区域显著性指标:
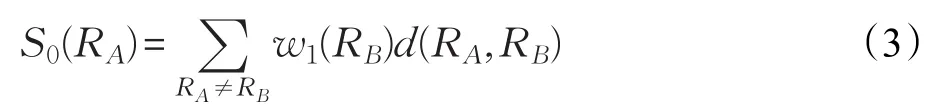
其中,w1(RB)表示区域RB中的像素点个数,用来强调较大区域的颜色对比度。可以看出,公式(3)中没有空间信息,计算后的结果可能出现某些背景区域的显著性指标与部分前景相同,对确定种子区域的选取造成困难。因此,本文在公式(3)的基础上加入了空间因素并重新定义显著性指标:
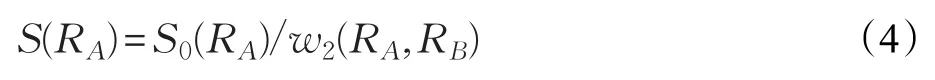
其中w2(RA,RB)表示RA、RB间欧氏距离。在本文算法中,一个区域或超像素表示一个节点。本文的自适应合并策略能够通过超像素区域合并来实现显著目标提取,在过分割后的图像上标记出初始背景和前景种子区域。通过对显著性指标进行归一化,取最大值对应显著区为前景种子区域,记为Mo。对于背景种子区域的选取不能直接选取最小值对应区域。原因是前景目标较大且背景较为复杂时,最小显著性指标对应的区域可能不是唯一的,有时会处在前景中。为了能够确定唯一的背景种子区域,本文选用图像边缘附近最小的显著性指标,记为MB。图像中剩余的其他区域则统一记为N,代表未标记区域。这样,图像就被分成前景种子,背景种子以及未标记三类区域,分别对应本文的前景、背景和未标记三类节点。
3.2 区域相似性度量
区域合并之前一个关键环节是计算区域特征间的相似度。本文的显著性检测算法是以超像素为基本处理单元,使用超像素的直方图特征作为它们的特征向量。文献[9]在基于区域合并的图像分割中计算图像超像素的单通道直方图来作为特征向量,相比其他特征更具稳健性,因此本文采用单通道索引颜色直方图来表示超像素区域,把输入图像在RGB色彩空间中的各通道量化成L级。设(xR,xG,xB)、(R,G,B)分别表示原始和量化后的颜色值,转化关系如下:

其中,f()表示沿负无穷方向的取整函数。原来图像3通道的取值从[0,255]转化为单通道的[0,L3-1]。
区域特征相似度测量方法一般可分成相似性度量(Similarity)和相异性度量(Dissimilarity)两种,两者统称为接近度(Proximity)。度量接近度可以有多种方法,比如Minkowski距离、Bhattacharyya系数等。本文采用Bhattacharyya系数[13]来度量区域间的相异度。设HistR和HistQ分别表示区域R和区域Q归一化后的颜色直方图特征,则区域R和区域Q之间的相异度d(R,Q)定义为:
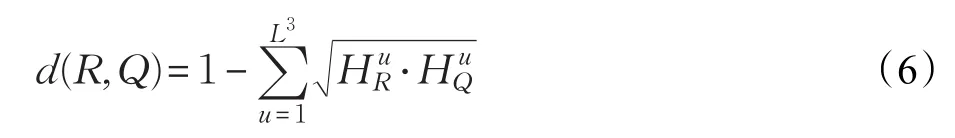
3.3 区域合并
前文完成了图的构建,下面将根据相似特征进行区域合并。颜色特征相似的区域将同属背景或前景目标。传统的区域合并算法中需要设置一个阈值,大于阈值才进行合并。阈值设置小很容易导致过合并,即一些目标区域被合并到了背景中,阈值设置较大则会导致背景区域或目标区域合并不完整。此外,传统区域合并算法中的合并停止条件也是比较难以选择的。在本文中,提出了一种自适应最小相异机制来合并区域。
合并准则:设Q为区域R相邻的区域,并令SQ=为Q相邻区域的集合,通过2,…,q计算Q及其邻域之间的颜色最小相异度。如果R和Q之间的最小相异度在所有值中是最小的,则把R和Q进行合并,合并后区域的标记与R相同,即:
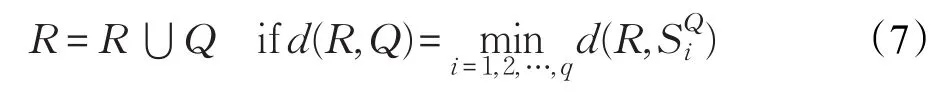
以上合并策略虽不需要提前设置合并阈值,但需要选择初始种子节点来引导区域融合。在合并过程中,从哪个区域开始很重要。选取不同的种子将会产生不同的合并结果,在没有先验信息的情况下,选取种子区域比较困难。受文献[9]的启发,本文选取图片边缘的超像素作为图像的种子节点引导合并的进行,在合并之前通过计算公式(2)去除最可能包含前景目标的一个边,来提高最终检测结果的准确性。整个区域合并过程分成三步:
步骤1从位于图像三个边缘的背景种子区域开始,如果满足公式(7),则把MB中的背景区域和N中没有被标记的区域进行合并,合并过程中N减少同时MB增加,直至MB找不到能进行合并的未标记区域,步骤1迭代结束。
步骤2N中没有被标记的区域之间进行自适应合并,随时更新标号N,直至找不到新的区域与N中区域合并时,步骤2迭代结束,如果此时N不为空,则返回执行步骤1。
步骤3N中所剩余区域标记为Mo。至此,图像中的所有区域均被标记为目标Mo或背景MB。
4 实验结果及分析
4.1 数据库和评价指标
将在本领域国际公开的图像数据库上验证本文图像显著性检测模型的有效性。为使比较结果更具说服力,在Achanta[14]提供的MSRA1000数据集上做仿真实验,该数据集包含了1 000张自然图像,大部分的图像分辨率为400×300,每幅图像均有对应的人工标定好的显著性区域真值参照图(GT)。将本文算法与SVO[15]、PCA[16]、RC[17]、DFRI[18]、HS[19]、LRMR[20]和MR[21]这几种流行算法进行定性和定量比较。从公平比较的角度出发,实验中用的对比算法都是运行网上直接下载到的原作者所提供的代码得到的。
在定量比较实验中,本文引入普遍采用的Precision(查准率)、Recall(召回率)和F-measure三个评判显著性的量化指标[15]。查准率反映算法检测出来的显著点多少是正确的,表示显著性检测算法的准确的。召回率反映有多少真正的显著点被检出,表示检测算法的完整性。这两个指标相互约束,召回率的提高往往是以降低查准率为代价,因此需要同时考虑以上两个指标的第三种评估方法,即F-measure,它表示Precision和Recall的加权调和平均数,计算形式如公式(8)。F-measure值越大则表明检测算法的性能就越好。为了强调查准率的重要性,本文采用Achanna等人的建议,β2的值设置为0.3。
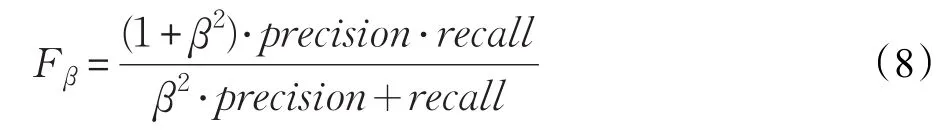
根据经验本文把SLIC超像素分割数设置为200。为了更可靠地对显著图进行衡量,设置256个阈值(0~255),把图像分成256个二值图,计算256个查准率和召回率得到变化曲线,然后根据公式(8)计算每幅图像的F-measure。

图1 不同算法的效果对比图
4.2 比较实验
图1展示了不同算法的定性检测结果。图2给出了本文的显著性检测算法跟其他算法的定量比较结果。图1显示,SVO算法将部分的背景内容错误地检测到显著性区域中。PCA算法主要利用模式进行检测,虽然能很好地检出显著目标轮廓,但是丢失了显著区域的很多内部信息。RC会错误地将一些图像中背景误以为是显著性目标。DFRI算法在多级图像分割基础上使用监督学习将区域特征向量映射到显著性分量,通过对多级显著性分量融合得到显著性区域。但它所使用的大部分图像训练集只包含一个显著目标,很难将所有显著目标提取出来。DSR首先在图像边界提取背景区域的模板,然后基于该模板将整个图像的密集和稀疏的外观模型作为显著性区域的搜寻方法。LRMR结合了一些高级先验知识,如图像的中心和暖色调的显著性特点。MR算法仅用一个高斯函数来计算边的权值去度量节点之间的相似性,不能很好地检出靠近图像边缘的显著目标。本文算法能很好地处理图像比较复杂且背景比较杂乱的情况,尤其是图像显著性目标落在图像边界的时候,本文算法表现好于其他算法,例如图1第五行的图像显著性区域占据了图像部分背景的边界区域,通过去除掉最可能包含前景目标的一个边之后取得了较好的检测效果。

图2 各算法的Precision、Recall和F-measure柱状图
从图2可以看出,在所有显著性检测算法中,本文算法获得了最好的查准率和最高的F-measure值。本文算法的性能非常接近MR,查全率不如MR,但整体优于其他算法,如DFRI、RC、DSR和PCA。准确度高的重要原因之一是采用了改进后的边界先验。
本文算法和其他算法的运行时间对比情况如表1所示。从公平比较的角度出发,本文全部在MATLAB2010a环境下对各算法进行显著性区域检测。硬件平台参数:英特尔双核E6500处理器,2.93 GHz主频,2 GB内存。从表1中可以看到,本文算法比SVO、PCA、DFRI、DSR和LRMR更快。SVO算法比其他算法慢很多,该算法最耗时的步骤是生成通用对象检测器和自底而上显著区域检测器。虽然DFRI算法仅需要12 s多就能完成给定图像的检测,但对数据进行训练需要24 h以上。虽然本文算法比MR算法稍慢一些,但能产生更优质的显著图。

表1 不同的算法的运行时间
5 结论
本文提出了一种基于边界先验和自适应区域合并的显著性检测算法来检测当前图像中显著性区域。对于给定图像,首先采用SLIC算法把图像进行过分割,以超像素区域内所有像素特征的均值为超像素的特征,通过把超像素看做图的一个顶点来进行构图;然后通过定位和消除错误边界来优化边界影响,使背景基准集中存在很少的噪声,有助于提升下一阶段显著性检测的准确度;最后采用单通道索引颜色直方图度量区域相似度并进行区域合并得到显著图。定性和定量实验表明本文算法相比其他算法取得了较好的实验结果,得到的显著区域轮廓清晰,显著目标完整,说明了算法的有效性。随着深度学习理论的日渐成熟,下一步将把相关理论和改进方法应用到视觉注意领域,改进当前显著性目标检测中的不足。
[1] Itti L,Koch C,Niebur E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[2] Sugano Y,Matsushita Y,Sato Y.Calibration-free gaze sensingusingsaliencymaps[C]//IEEEConferenceon Computer Vision and Pattern Recognition,2010:2667-2674.
[3] 黄娟,梅浙川,黄小明.融合区域合并和Graph Cuts的彩色图像分割方法[J].计算机工程与应用,2016,52(17):225-228.
[4] Han J,Ngan K N,Li M,et al.Unsupervised extraction of visual attention objects in color images[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,16:141-145.
[5] 钱晓亮,郭雷,韩军伟,等.一种基于加权稀疏编码的频域视觉显著性检测算法[J].电子学报,2013,41(6):1159-1165.
[6] Gopalakrishnan V,Hu Y Q,Rajan D.Salient region detection by modeling distributions of color and orientation[J].IEEE Transactions on Multimedia,2009,11(5):892-905.
[7] Wei Y C,Wen F,Zhu W J,et al.Geodesic saliency using background priors[C]//the 12th European Conference on Computer Vision,2012:29-42.
[8] Zhou J,Gao S,Yan Y,et al.Saliency detection framework via linear neighborhood propagation[J].IET Image Processing,2014,8(12):804-814.
[9] Ning J,Zhang L,Zhang D,et al.Interactive image segmentation by maximal similarity based region merging[J].Pattern Recognition,2010,43(2):445-456.
[10] Achanta R,Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274-2282.
[11] Yang C,Zhang L,Lu H,et al.Saliency detection via graph-based manifold ranking[C]//IEEE Conference on Computer Vision and Pattern Recognition.Portland,USA:IEEE,2013:3166-3173.
[12] Moscheni F,Bhattacharjee S,Kunt M.Spatio-temporal segmentation based on region merging[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(9):897-915.
[13] Ayed I B.Graph cut segmentation with a global constraint:Recovering region distribution via a bound of theBhattacharyyameasure[C]//IEEEConferenceon Computer Vision and Pattern Recognition,San Francisco,2010:3288-3295.
[14] Xia C,Qi F,Shi G,et al.Nonlocal center-surround reconstruction-based bottom-up saliency estimation[J].Pattern Recognition,2015,48(4):1337-1348.
[15] Margolin R,Tal A,Zelnik-manor L.What makes a patch distinction[C]//IEEEConferenceonComputerVision and Pattern Recognition.Portland,USA:IEEE,2013,9(4):1139-1146.
[16] Yan Q,Xu L,Shi J,et al.Hierarchical saliency detection[C]//IEEE Conference on Computer Vision and Pattern Recognition.Portland,USA:IEEE,2013,38(4):1155-1162.
[17] Wang L,Xue J,Zheng N,et al.Automatic salient object extractionwithcontextualcue[C]//IEEEInternational Conference on Computer Vision.Barcelona,Spain:IEEE,2011:105-112.
[18] Jiang H,Wang J,Yuan Z,et al.Salient object detection:A discriminative regional feature integration approach[C]//IEEE Conference on Computer Vision and Pattern Recognition,2013:2083-2090.
[19] Yan Q,Xu L,Shi J,et al.Hierarchical saliency detection[C]//IEEE Conference on Computer Vision and Pattern Recognition,2013:1155-1162.
[20] Achanta R,Hemami S,Estrada F,et al.Frequency-tuned salient region detection[C]//IEEE Conference on Computer Vision and Pattern Recognition.Miami,USA:IEEE,2009:1597-1604.
[21] Chang K Y,Liu T L,Chen H T,et al.Fusing generic objectness and visual saliency for salient object detection[C]//Proceedings of the 2011 ICCV,Barcelona,Spain,2011:914-921.
ZHAI Jiyou,TU Lizhong,ZHUANG Yan.Saliency detection based on boundary prior and adaptive region merging.Computer Engineering andApplications,2018,54(6):178-182.
ZHAI Jiyou1,2,TU Lizhong1,ZHUANG Yan1
1.School of Computer Engineering,Nanjing Institute of Technology,Nanjing 211167,China 2.College of Computer and Information,Hohai University,Nanjing 211100,China
In order to efficiently extract the salient region of images,a novel saliency detection algorithm based on boundary and adaptive region merging is proposed.Firstly,the input image is over-segmented by using a superpixel segmentation algorithm and a graph is constructed by taking a superpixel as a vertex.Then through locating and eliminating error bounds,there is little noise in the background,and errors are reduced when objects touch the boundary of images.Finally,single channel index color histogram is used to measure the regional similarity and saliency map is obtained by region merging.Experimental result shows that this algorithm has higher precision than other algorithms and shows the effectiveness.
boundary;adaptive;region merging;saliency detection
为了对图像中的显著目标进行更精确的识别,提出了一种基于边界先验和自适应区域合并的显著性检测算法。采用超像素分割算法对图像进行过分割,把超像素看做图的一个顶点来进行构图;定位和消除错误边界,使背景基准集中存在很少的噪声,减小目标接触图像边界时造成的误检;采用单通道索引颜色直方图度量区域相似度并进行区域合并得到显著图。对比实验表明该算法相比其他算法取得了较高的查准率,说明了算法的有效性。
边界;自适应;区域合并;显著性检测
2016-10-27
2017-01-05
1002-8331(2018)06-0178-05
A
TP391.4
10.3778/j.issn.1002-8331.1610-0335
南京工程学院校级科研基金(No.CKJA201306)。
翟继友(1978—),男,博士研究生,助理研究员,主要研究方向为机器学习,图像分析,E-mail:jiyou1018@126.com;屠立忠(1968—),男,博士,副教授,主要研究方向为数据挖掘;庄严(1969—),男,硕士,主要研究方向为图像处理,机器视觉。
