复杂网络在人脸识别中的应用
2018-03-14李玲
李玲
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引言
传统的人脸识别方法通常以单幅人脸图像作为测试对象,在可控场景下大部分方法取得了良好的识别效果。然而,在非约束条件下,由于人脸图像在采集过程中易受光照、表情、姿态等因素的影响,基于单幅图像的人脸识别方法在很多实际应用场景中的识别效果不佳。随着数字图像技术、交互技术、海量存储设备及社交网络的快速发展,目前可以很方便地获取一个人的多幅图像即图像集,例如使用多个相机拍摄多视角图像、收集不同时期的多幅图像或从个人相册获取等。因此,在人脸识别过程中可以将测试图像集与训练图像集进行对比,从而提高分类的准确性。研究者将这类人脸识别问题称为基于图像集的人脸识别。与单幅人脸图像相比,图像集能够更全面地刻画同一类人脸图像中存在的各种面部表观变化,如表情、光照、姿态等,便于消除这些干扰因素的影响,因此基于图像集的人脸识别方法较基于单幅图像的人脸识别方法更能实现鲁棒的分类。
但是,目前基于图像集的人脸识别技术仍然存在不足之处:在非控条件下,由于受多种因素的干扰,同一人脸图像集内的多个样本在表观上存在着多种变化,因此图像集数据所在的流形中潜藏着多个子流形,这些子流形之间既存在着差别,也有着联系,而现有的人脸识别方法在识别过程中并没有考虑这些子流形之间的相互关系,势必会对识别结果的精确性不产生不利影响。为此,本文提出一种基于复杂网络和图像集的人脸识别方法,以非控条件下获取的人脸图像集为研究对象,将人脸图像集抽象成复杂网络系统,在复杂网络体系下划分图像集数据的子流形,以获取各潜在子流形的特征属性;在子流形划分的层面上,构建稀疏嵌入的图模型与最优投影目标函数,以保持人脸样本的内在低维结构信息;最后,在低维空间构建基于子流形的人脸图像集的联合识别模型。为了检验算法的有效性,本文将在多个不同类型的人脸图像集数据库上设计实验,对提出的算法进行标准测试和评估,并通过实验发现算法中存在的问题,从而对理论模型加以修正。
1 复杂网络理论[1]
典型的网络是由众多节点以及节点之间的连边组成的。自然界中存在着大量可以用网络来进行描述的复杂系统,其中每个节点分别表示系统中的每个个体,而连边则表示个体之间的相互关系。例如计算机网络、生物网络、电力与交通网络、神经网络、金融与经济网络、社会网络、语言网络、科研与教育网络等。
人们在研究网络模型时,往往只会关心网络中有多少个节点以及哪些节点之间有边直接相连这些基本特征,即网络的拓扑性质。在近两百年以来,研究者们提出了众多的拓扑结构,用于描述真实的系统,主要分为规则网络和随机网络。近来,计算机相关技术的飞速发为复杂网络的研究提供了强大的工具和技术支持,研究者们逐渐发现,自然界中尚存在大量不能直接用规则网络或者随机网络来描述的真实系统,并称其为复杂网络。
钱学森给出了复杂网络的一个较为严格的定义:具有自组织、自相似、吸引子、小世界、无标度中部分或全部性质的网络称为复杂网络。为刻画复杂网络结构的统计特性,研究者们提出了许多概念和方法,例如度、度分布、聚类系数等。下面就本文会用到的几个概念进行介绍。
度:无向网络中节点i的度ki定义为与该节点直接相连的边的数目。给定网络的邻接矩阵A=(aij)N×N,则有:

平均度:网络中所有节点的度的平均值称为网络的平均度,记为〈k〉。

聚类系数:网络中一个度为ki的节点i的聚类系数Ci定义为:
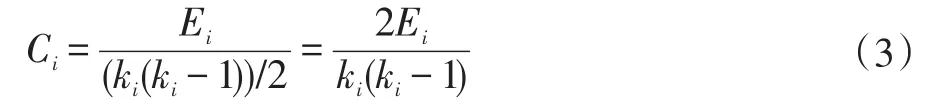
其中,Ei是节点i的ki个邻居节点之间实际存在的边的数目,即节点i的ki个邻居节点之间实际存在的邻居对的数目。
2 基于复杂网络的人脸识别
本文的人脸识别方法包括四个步骤:构造复杂网络系统、划分网络社团结构、稀疏降维、分类和识别。
2.1 构造复杂网络系统
将人脸图像集抽象成网络模型,网络中的节点表示人脸图像集中的各个样本,网络中的边表示样本之间的相互关系,并采用热核方法计算边的权重以度量样本之间的相似度,从而得到样本的关系矩阵S,即对于任意两个样本mi和mj,它们之间的相似度为Sij,则有(σ为适应性常量),由此便得到抽象的随机网络模型。但由于随机网络模型不具备高聚类特性,不便于分析节点之间的相互关系,需进一步将其转换成复杂网络模型,令:
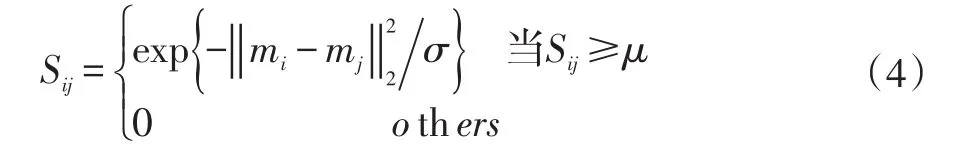
其中,μ为随机网络模型中所有节点对之间的相似度的平均值。随机网络模型转换成复杂网络模型之后,其图模型可能不连通。为确保图的连通性,假设复杂网络模型有n个连通分支,在任意两个连通分支之间寻找θ个距离最近的节点对,并在它们之间添加连边,其权重为随机网络模型中的样本相似度。然后采用Floyd或Dijkstra算法来计算任意两个样本之间的全局相似度(最短路径),最后基于全局相似度构造样本的k近邻关系矩阵W。
2.2 划分网络社团结构
构建无监督的层次聚类树模型对复杂网络进行分组,即划分人脸图像集数据的子流形。本文利用高斯混合模型(GMM)结合复杂网络系统的社团结构来对复杂网络进行社团的划分,即对人脸图像集数据进行子流形划分。利用GMM每次自顶向下地将数据划分成两个社团,并利用复杂网络理论中的聚类系数来控制每个社团是否需要继续划分。假设一个社团的节点数目为N,其邻接矩阵为A=(aij)N×N,则该社团的聚类系数C定义为社团中所有节点的聚类系数的平均值,即:

其中,Ci为社团中节点i的聚类系数,这里,ki为节点 i的度,为k近邻关系矩阵W中的相似度权重,ωijk为节点i与它的两个邻居节点j和k之间的两条连边的权值的归一化平均值,〈wi〉是以节点i为一个端点的所有边的权值的平均值。设定一个阈值t,当C<t时就用GMM对该社团进行聚类,这种聚类过程重复进行,直到C≥t,从而产生一棵聚类树,其叶子节点即为得到的人脸图像集数据的子流形。
2.3 稀疏降维
利用稀疏重建的思想,计算同一个子流形中每个样本与其他样本的关系系数以及流形之间的关系系数,采用监督的方法分别构造稀疏的类内图模型与类间图模型,以反映样本之间的相互关系。
首先,构建稀疏的类内图模型,以保持每个子流形的局部内在结构。设X=[x1,x2,…,xn],其中Xi为第i个人脸图像集(即第i个流形),每个人脸图像集被划分为ci个子流形,每个子流形包含nci个样本。对于每个子流形Xij(即第i个人脸图像集的第j个子流形)中的任意节点xk,其与该子流形中其它样本的关系系数sk由下面的L1范数最小化问题求得:
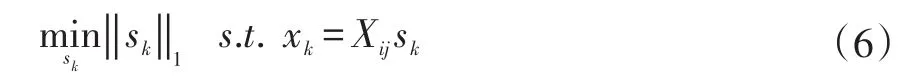
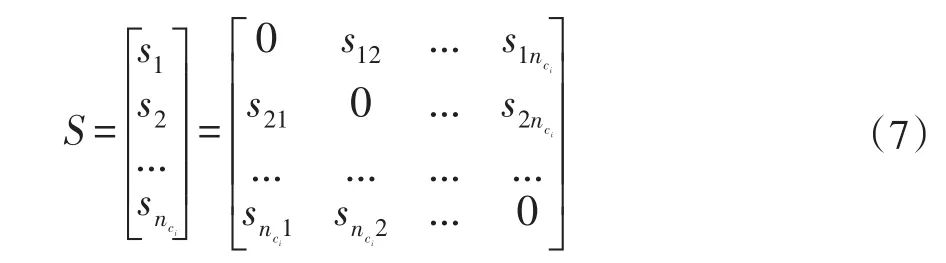
求得式(6)最优的sk之后,则子流形Xij的关系矩阵S为:
其次,构造稀疏的类间图模型,以反映人脸图像集子流形之间的相互关系。设μi、μj分别表示两个人脸图像集Xi和Xj(即第i个流形与第j个流形)中样本的均值。对于任意流形Xi,其与所有其他流形之间的关系系数ri由下面的L1范数最小化问题求得:
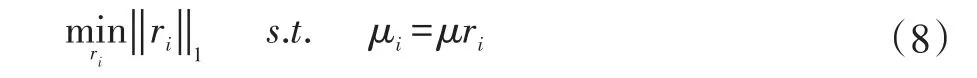
其中,μ=[μ1,μ2,…,μn]。求得式(8)最优的 ri之后,则流形之间的关系矩阵R为:
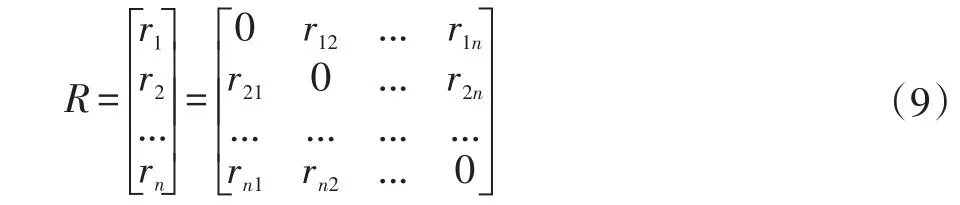
最后,构造最优投影目标函数。最优投影不仅要保持人脸图像集内部子流形的紧凑性,又要保持不同人脸图像集流形之间的分离性。即投影之后的样本应满足:每个子流形内的样本尽可能离得近,不同流形之间的样本尽可能地离得远。为此,本文定义如下的类内散度Sw与类间散度Sb:
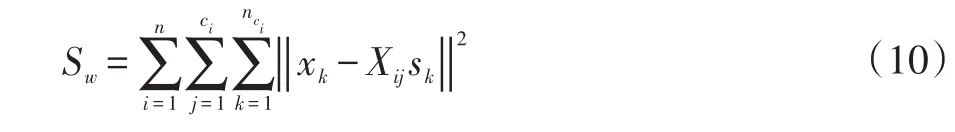

为了最小化类内散度同时最大化类间散度,联合式(10)和式(11)构造最优目标函数:
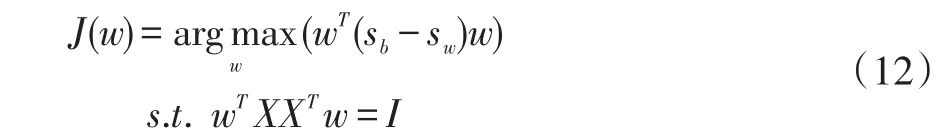
则最优投影矩阵W=[w1,w2,…,wd]的列向量为归一化的特征值问题(sb-sw)w=λXXTw的前d个最大的特征值所对应的特征向量。
2.4 分类和识别
(1)选取代表性图像。根据每个社团即每个子流形中样本的连通性对该社团中的所有样本排序,选取排序靠前的样本,从而滤除掉受干扰因素影响较大以及不相关的图像,保留质量较好且具有特征模式代表性的图像,使最终选出的样本图像满足:与该社团中的其他样本高度相似,同时与社团外的样本高度不相似。
(2)构造子流形联合表示模型。借鉴稀疏编码的思想,在子流形划分及代表性图像选取的基础上,构造测试人脸图像集与训练人脸图像集的联合表示模型,以挖掘出隐含在人脸图像集数据内部的结构与模式信息。在训练图像集中寻找一组超完备基向量,在最小化误差的基础上使用这些基向量的线性组合更高效地重建测试图像集。此外,加入“稀疏性”约束以解决因超完备而导致的退化问题,使线性组合中大于零的数据尽可能地少,即使用尽可能少的训练图像集的子流形来表示测试图像集。同时加入“局部性”约束以保持流形的局部结构特征。联合表示模型如下
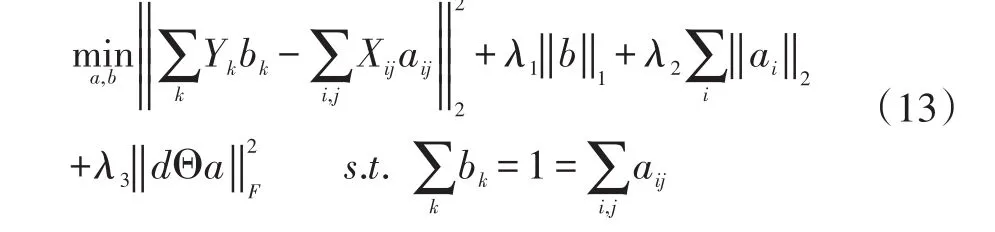
其中,Yk表示测试人脸图像集Y的第k个子流形,Xij表示第i个训练图像集的第j个子流形,aij、bk为对应子流形的系数向量,λ1、λ2、λ3为尺度数,d=为训练图像集数目),Θ表示点乘。式(13)中第一项确保重构误差最小化,第二项和第三项控制稀疏性,并且第三项融入了流形的类别属性,第四项用以保持流形的局部结构信息。利用拉格朗日乘子法,不断迭代直至得到最优解。最后基于最小重构误差对测试人脸图像集进行分类,即:

3 实验
3.1 实验设置
本文实验采用的数据集是三个被广泛研究的大型人脸视频数据库,即 Honda/UCSD[2]、CMU MoBo[3]和YouTube Celebrities[4],其中每个视频序列都被分解成帧并保存为一个图像集。在本节中,我们将评估本文方法在这三个数据库上的性能。
本节将本文提出的方法与四类最先进的方法进行比较:
(1)基于线性/仿射子空间的方法:互子空间方法(MSM)[5],基于仿射包的图像集距离方法(AHISD)[6]。
(2)基于非线性流形的方法:流行判别分析(MDA)方法[7]。
(3)基于格拉斯曼流形的方法:格拉斯曼流形判别分析(GDA)方法[8]。
(4)基于协同表示的方法:基于正则包的图像集协同表示和分类(RH-ISCRC)[9]。
以上方法的源代码均由原始作者提供,为了进行公平的比较,这些方法的重要参数都是根据原始参考文献的建议进行设置和调整的。对于MSM和AHISD,在学习线性子空间时,我们寻找最优的PCA能量,并为每一种方法记录最佳结果。对于MDA,构造最大线性补丁的参数是优化的,类间最近局部模型的数量和嵌入子空间的维数也是最优的[7]。对于GDA,子空间基向量的数量被调优到能够提供最好的结果,且只测试投影内核。对于RH-ISCRC,只测试能够达到更好性能的L1-范数规则。平衡表示剩余的正则化参数λ1和λ2都被设置为默认值0.001,压缩原子的数量限制在10~20之间,迭代的次数设置为20[9]。
在本文的实验中,对于Honda/UCSD数据库,采用文献[2]中提供的标准训练/测试配置:20个序列用于训练,剩下的39个序列用于测试,即随机选择每个人的一个序列用于训练,其余序列用于测试。对于CMU MoBo数据库,随机选择每个人的一个图像集用于构成训练数据,剩下的图像集用于构成测试数据。对于YTC数据库,将每个人的视频序列分为5组,并确保每组包含9个序列(最少重叠),这样该数据库就被分成5个组,每个组由47个人的423个序列组成。每组随机选择每个人的3个序列用于训练,6个序列用于测试。每个实验重复10次,实验结果如表1所示。
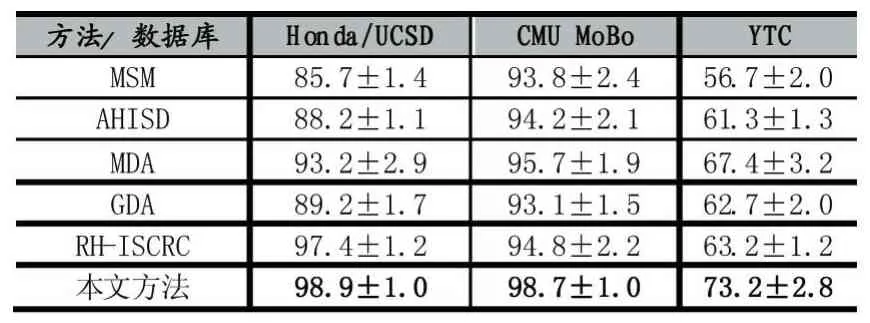
表1 三个数据库上的实验结果(平均识别率(%)和标准偏差),粗体条目显示了最高识别率。
3.2 实验结果及分析
表1总结了3种不同数据库上所有对比方法的识别结果。从表1可以看出,本文提出的方法在测试的大部分方面都取得了优越的性能。在Honda/UCSD数据库上,本文方法的平均识别率为98.9%,高于其他对比方法,RH-ISCRCS方法以97.4%的平均识别率仅次于本文方法。在CMU MoBo数据库上,所有方法的识别性能都不错,本文方法的平均识别率为98.7%,高于其他对比方法。在YTC数据库上,由于所有视频都来自真实世界,质量低且包含非常大的表观变化,所以所有方法的识别性能较前两个数据库都下降了许多。尽管如此,本文方法同样以73.2%的平均识别率高于其他对比方法,并且其优越性是显而易见的。
3.3 效率分析
在效率方面,表2比较了Honda/UCSD数据库上训练和测试阶段不同算法的平均时间消耗,这一实验是在英特尔酷睿i5-6200U PC上实现的。从表3可以看出,在训练阶段,本文方法的计算成本比其他方法要高,因为本文方法需要计算每个子流形内部及子流形之间的图像之间的稀疏重建权重向量,但仍然可以接受。在测试阶段,本文方法的测试速度比大多数最先进方法要快。
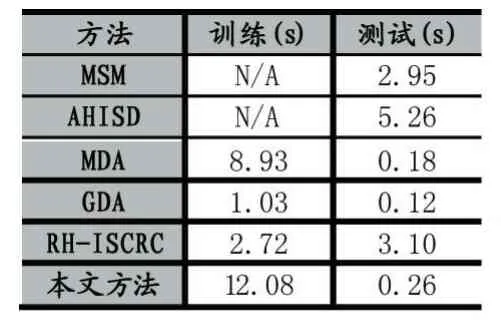
表2 Honda/UCSD数据库上不同方法的时间消耗(一个图像集的分类)
4 结语
本文提出了一种新的基于复杂网络和图像集的人脸识别方法。首先,将非约束条件下获取的人脸图像集抽象成复杂网络系统,在复杂网络体系下划分人脸图像集数据的子流形。其次,在子流形划分的基础上,构建稀疏嵌入的类内图模型与类间图模型以及最优投影目标函数,保持人脸样本的内在低维结构信息。最后,在低维空间构建人脸图像集的联合表示模型以实现人脸图像集的分类和识别。
基于复杂网络的思想,本文方法在理论上和实际上都很有吸引力。实验结果表明,本文方法适用于基于图像集的人脸识别问题,并可与最先进的方法相媲美。对于未来的工作,我们现在正在探索人脸图像集的鲁棒表征描述模型,它将抽取出人脸显著区域的视觉纹理特征,在解决人脸图像集的鲁棒表征问题上取得重要突破。而且,将新的训练集应用到增加学习也将会是我们今后的一个研究兴趣。
[1]汪小帆,李翔,陈关荣.网络科学导论[M].北京:高等教育出版社,2013.
[2]K.C.Lee,J.Ho,M.H.Yang,et al.Video-Based Face Recognition Using Probabilistic Appearance Manifolds,in:Pro-ceedings of International Conference on Computer Vision and Pattern Recognition(CVPR),pp.313-320,IEEE(2003).
[3]R.Gross,J.Shi.The CMU Motion of Body(MoBo)Database.Technical Report CMU-RI-TR-01-18,Robotics Institute,Carnegie Mellon University,pp.1-13(2001).
[4]M.Kim,S.Kumar,V.Pavlovic,et al.Face Tracking and Recognition with Visual Constraints in Real-World Videos.CVPR,pp.1787-1794,IEEE(2008).
[5]O.Yamaguchi,K.Fukui,K.Maeda.Face Recognition Using Temporal Image Sequence,in:Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition,pp.318-323,IEEE(1998).
[6]H.Cevikalp,B.Triggs.Face Recognition Based on Image Sets,in:Proceedings of International Conference on Computer Vision and Pattern Recognition(CVPR),pp.2567-2573,IEEE(201 0).
[7]R.Wang,X.Chen.Manifold Discriminant Analysis,in:Proceedings of International Conference on Computer Vision and Pattern Recognition(CVPR),pp.429-436,IEEE(2009).
[8]J.Hamm,D.D.Lee.Grassmann Discriminant Analysis:a Unifying View on Subspace-Based Learning,in:Proceedings of International Conference on Machine Learning(ICML),pp.376-383,IEEE(2008).
[9]P.Zhu,W.Zuo,L.Zhang,et al.Image Set-based Collaborative Representation for Face Recognition,IEEE Transactions on Information Forensics and Security,9(7),1120-1132(201 4).
