催化裂化MIP工艺原料油聚类研究
2018-03-13欧阳福生方伟刚
欧阳福生,李 盾,方伟刚
(华东理工大学石油加工研究所,上海 200237)
催化裂化是重油轻质化的主要工艺。我国催化裂化装置所生产的汽油和柴油约占成品汽油和柴油总量的70%和30%[1]。实际生产过程中,催化裂化主要以馏分油和渣油为原料,其中馏分油主要为直馏减压馏分油,也包括少量焦化蜡油,渣油主要为减压渣油、加氢处理渣油或脱沥青油等,并以一定比例掺入馏分油中进行加工。因催化裂化原料油种类和渣油掺炼比例的不同,原料油性质会发生较大变化。如果对不同原料油的加工不加以区分,仅凭借生产经验进行操作就会使大部分原料油难以达到最优的加工状态。聚类分析[2]是比较各个事物之间的性质,并将性质相似的归于一类,将性质差别较大的归入不同的类别中,与平常所说的“物以类聚”相仿。聚类分析是数据挖掘的一项重要功能,它不需要事先确定分类的准则来分析数据对象,而是在训练数据的过程中根据最大的组内相似性和最小的组间相似性为原则进行聚类和分组。在实际过程中,可以将一个类别中的数据对象作为一个整体来处理,因此,聚类分析在许多领域得到广泛应用[3-5]。传统的聚类算法主要包括划分聚类方法和层次聚类方法,划分聚类方法主要的算法有K-means算法、K-medoids算法、CLARA算法和CLARANS算法[6]。层次聚类的方法有BRICH算法、CHAMELEON算法、ROCK算法和CURE算法[7-8]。除此之外,传统的聚类算法还有基于网格的聚类、基于图论的聚类、基于模型的聚类、机器学习中的聚类算法和高维数据的聚类算法等[9-10]。除了上述传统聚类算法外,还有模糊聚类算法、综合聚类算法和新对象的聚类算法[11],这些聚类算法对传统聚类算法进行了扩展,使得它们具有更强的适用性。
MIP工艺是由中国石化石油化工科学研究院开发,通过对催化裂化氢转移反应的调控,直接降低催化裂化汽油烯烃含量,同时多产异构烷烃的催化裂化新工艺[12]。本研究在综合分析MIP装置原料油数据的基础上,以汽油收率最大为目标,通过建立原料油数据的聚类评价模型,旨在将性质最为相近的原料油聚为一类,并对每一类原料油的特征进行描述,以此为基础,有助于建立相应的智能化模型,寻找加工该类别原料油时目的产物收率最大的操作条件。
1 数据收集
原料油性质是决定催化裂化产品的基础。原料油为烷烃、烯烃、环烷烃和芳烃的混合物,其中烷烃发生分解反应;烯烃除发生分解反应外还发生氢转移、异构化、芳构化反应;环烷烃主要开环断裂生成烯烃或通过氢转移转化为芳烃;芳烃的烷基侧链容易发生断裂生成烯烃。一般认为原料油中支链烷烃、烯烃、环烷烃、带侧链芳烃的含量越高,其裂解性能越好,越有利于生成C5~C12汽油组分。因而,原料中各烃类含量对于反应速率的影响较大。原料油中含有的金属会引起催化剂的失活,主要影响反应的金属包括镍、钒、铁以及钙。催化裂化反应条件下,镍起脱氢的作用,使催化裂化产物生成多环芳烃聚合物和焦炭,使催化剂的选择性变差;钒会破坏分子筛中的晶体结构并使催化剂的活性下降。残炭反映原料中生焦物质含量的多少和生焦倾向,残炭越大,焦炭产率越高。因此,残炭也是一个重要的影响因素。
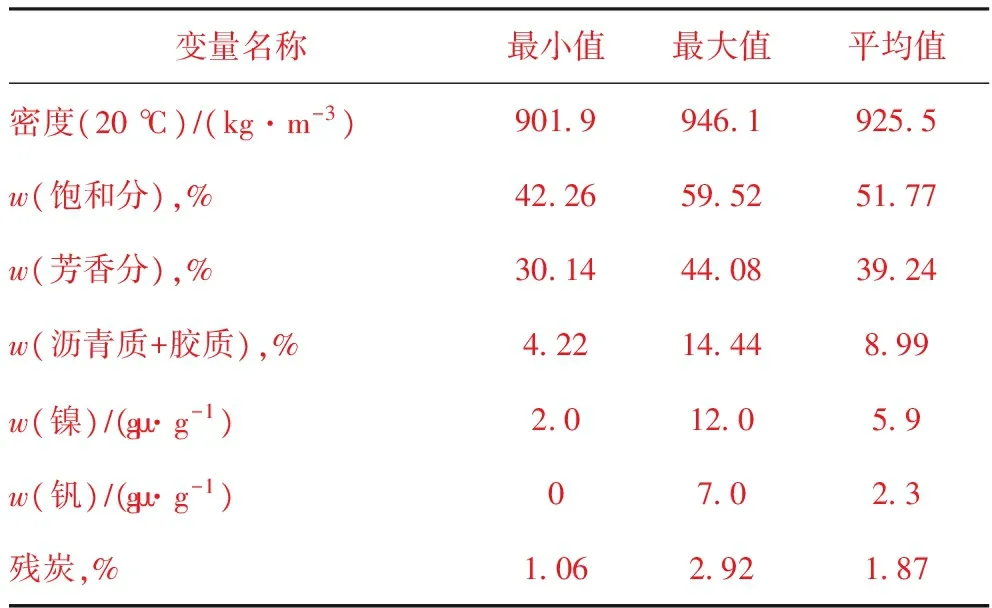
表1 原料油性质分布
2 原料油聚类模型的建立
K-means算法理论可靠、算法简单并且收敛速率快,除此之外该算法对大数据集有较高的效率,因此K-means算法作为一种基本的划分算法被广泛应用于数据挖掘领域[13]。模糊聚类算法可以得到每个样本属于各个类别的不确定程度,表达了样本类属的中介性,建立了样本属于各个类别的不确定程度,因此模糊聚类算法在聚类分析中的应用也比较广泛[14]。本研究分别采用K-means算法和模糊聚类算法建立原料油性质的聚类模型,采用MATLAB作为原料油性质聚类模型的编程平台。
2.1 K-means算法聚类
2.1.1K-means算法K-means算法是在给定聚类数k时,通过最小化组内误差平方和得到每一个样本点的分类。在使用时首先随机选择k个对象作为初始k个类的质心,然后对剩余的每个对象,根据其与各个质心的距离,将它赋给最近的类别,然后重新计算每个类别的质心。K-means算法在应用时通常采用欧式距离来计算对象与质心距离,计算式如(1)所示。
(1)
式中,xik、xjk分别表示第i和第j个数据对象在属性k上的取值。
数据对象和质心的距离会不断重复的计算,直到准则函数收敛,通常采用的准则函数为平方误差和准则函数,即SSE(sum of the squared error):
(2)
式中:SSE为数据集中所有对象的平方误差总和;p为数据对象;K-means算法将观测样本分为i个集合C= {C1,C2,…,Ci};mi为集合Ci的平均值。这个准则函数使得生成的结果尽可能紧凑和独立。
K-means算法的具体过程如下:
(1)给定大小为n的数据集,令I=1,选取k个初始聚类中心Zj(I),j=1,2,3,…,k。
(2)计算每个数据对象与聚类中心的距离D(xi,Zj(I)),i=1,2,3,…,n,j=1,2,3,…,k,如果满足:
D(xi,Zk(I))=min{D(xi,Zk(I)),
i=1,2,3,…,n}
(3)
则xi∈Ck。
(3)计算k个新的聚类中心:
(4)
以便下一步进行判断。
(4)判断:Zj(I+1)≠Zj(I),j=1,2,3,…,k,则I=I+1,返回(2);否则算法结束。
2.1.2K-means聚类结果分析K-means聚类的最佳聚类数kopt事先无法确定,目前许多学者已经提出一些确定kopt的有效方法[15-16],但是由于这些方法中的构造函数自身存在缺陷,一般难以通过这些方法直接确定kopt。一般情况下,可以先确定聚类数的最小和最大值,然后在该范围内进行试算,计算结果最符合实际过程的聚类数即为最佳聚类数。本研究设定最小聚类数kmin=3,最大聚类数采用经验式(5)[17]计算。
(5)
式中,n表示聚类的样本数,由于原料油性质共95组样本,因此kmax=9。
将95组包含ρ,SH,AH,AR,Ni,V,CR的原料油数据进行归一化计算,计算式如式(6)所示。
(6)
式中:xi表示属性i的平均值;si表示属性i的标准差;xij表示属性i的第j组样本原始值;zij表示属性i的第j组样本标准化值。
聚类数从3依次变化至9,并设定最大迭代次数为80。使用MATLAB编好的程序进行原料油数据的聚类分析,计算结果如表2所示。

表2 变量贡献度分布表
表2是聚类数在3~9变化的过程中,各变量对聚类结果贡献度排列情况。因为聚类的目的是找到每一类原料油(智能化模型)在汽油收率最大的同时尽可能控制生焦量的操作条件。因此,聚类过程中应以影响汽油收率和生焦量的因素为主。汽油的生成主要是因为烷烃发生分解反应,烯烃发生裂化、氢转移和异构化反应,环烷烃发生断裂生成烯烃,芳烃的烷基侧链发生断裂生成烯烃等一系列反应;焦炭一般是多环芳烃的缩合结构,芳烃在侧链基团断裂后具有强烈的生焦倾向,而沥青质和胶质中也含有大量的多环芳烃和杂环芳烃。因此影响汽油收率的因素主要是SH和AH,其中SH对汽油的贡献最大;影响焦炭收率的主要因素是AH和AR,其中AR是主要影响因素。ρ从一定程度上表示原料的轻重程度,ρ越大,AR和AH越大,SH越小;反之,AR和AH越小,SH越大。CR是表示生焦倾向的一个重要指标,CR越大,表明原料在反应时越容易生焦。Ni和V在反应过程中主要影响催化剂的活性和使用寿命,一定程度上促进焦炭的生成,而在实际生产过程可以通过加入新鲜催化剂和金属钝化剂来保持催化剂活性在指标范围内。因此,重金属含量可以作为次要的因素考虑。综上所述,当聚类数为4时,各变量对聚类结果影响的重要性由大到小的顺序为:SH>AR>AH>ρ>CR>Ni>V,满足上述的分析过程,因此确定最佳聚类数kopt=4。
表3为当聚类数为4时,每一类每个变量的平均值。当原料油饱和分含量越高时,芳香分含量和(沥青质+胶质)含量越低,原料油密度越小,残炭越小。第一类原料油命名为“超重质原料油”,其特点是芳香分含量和(沥青质+胶质)含量、残炭、镍和钒的含量最高,残炭也最高。在反应过程中,该类油所产汽油收率很低,生焦量很高,高的烧焦负荷和高的重金属含量大大缩短了催化剂的使用寿命,能耗也高,因此这类油炼制成本较高。第二类原料油命名为“重质原料油”,该类油比第一类油饱和分含量高,但是由于(沥青质+胶质)含量也比较高,使得残炭较高,此外重金属含量也较高,这类油所产汽油收率会比第一类油高,但是生焦量也会很大。第三类原料油命名为“超轻质原料油”,这类油的特点是饱和分含量最高,芳香分和沥青质、胶质总含量很低,同时镍和钒的含量也很低,这类油加工的经济效益最高。第四类原料油命名为“轻质原料油”,这类油的特点是饱和分含量较高,芳香分和沥青质、胶质总含量较低,同时镍和钒的含量也较低。
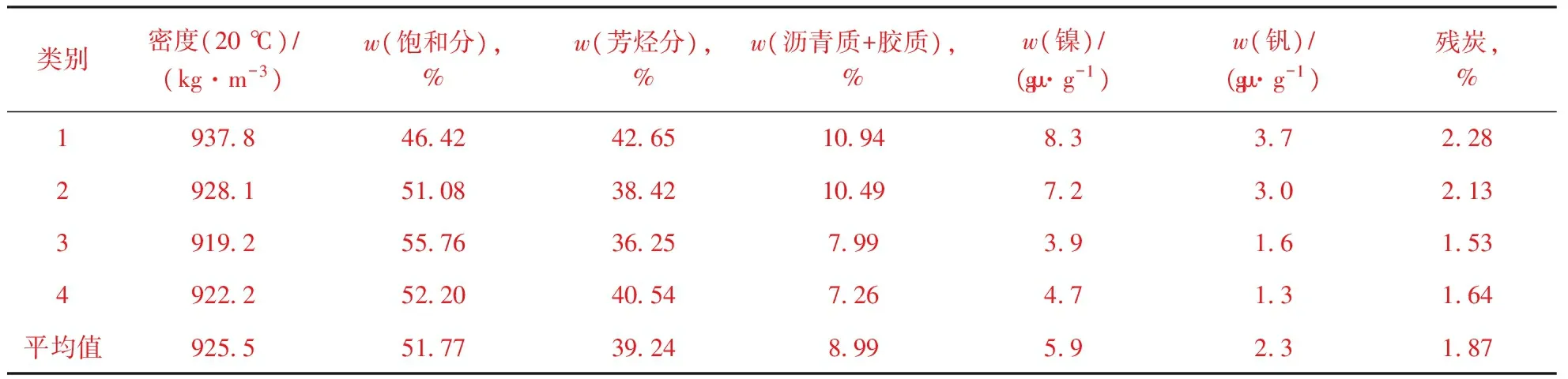
表3 当聚类数为4时每一类变量的平均值
以对汽油收率贡献大的饱和分含量为横坐标,对焦炭收率贡献大的(沥青质+胶质)含量为纵坐标,绘制了95组样本的散点图(图1)。由图1可以看出,每一类与其它类的边界较为明显,分类效果较好。
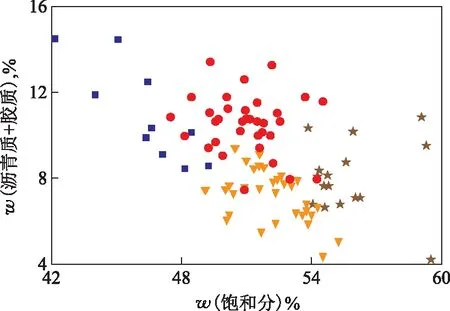
图1 K-means聚类散点图■—第一类油; ●—第二类油; ★—第三类油; 第四类油
2.2 模糊c均值聚类
K-means聚类分析是一种硬划分,它把每个待辨识的对象严格地划分到某个类中,具有非此即彼的性质。因此,K-means的每一类都具有明确的界限。而实际上有些对象并没有严格属性,它们在形态类属方面存在着中介性,于是人们开始使用模糊的方法来处理聚类问题,称之为模糊聚类分析。模糊划分的概念最早由Ruspini在1969年提出的[18],它是指某些对象或者概念并没有严格的属性,它们在形态和类属方面存在着中介性,利用这一概念人们提出了多种聚类方法,其中应用最广泛的是模糊c均值聚类算法(FCM,Fuzzy c-means)。
FCM在计算时给定数据集X={x1,x2,……,xn},其中每个元素包含s个属性。模糊聚类就是要把X划分为c类(2≤c≤n),v={v1,v2,……,vc}为c个聚类中心。在FCM中,每一个样本点不是严格地被划分到某一类,而是以一定的隶属度属于某一类。令μij表示第j个样本点属于第i类的隶属度,μij∈[0,1],数据对象的隶属度总和为1。

(7)
FCM的目标函数为:
(8)
式中:dij=‖xj-vi‖,为样本点xj与聚类中心vi之间的欧几里德距离;m∈[1,∞)]是模糊加权指数,通常m=2。
构造如下新的目标函数,可求得使式(8)达到最小值的必要条件:
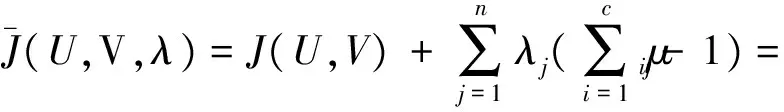
(9)
式中λj(j=1,2,……,n)是式(7)的n个约束式的拉格朗日算子。对输入变量进行求导,使式(8)达到最小的必要条件为:
(10)
(11)
有上述两个必要条件,FCM算法就变成了一个简单地迭代计算过程。在批处理方式下,FCM通过以下步骤来确定聚类中心ci和隶属矩阵U:步骤1,初始化隶属矩阵U,其值是[0,1]间的随机数并且满足式(7)中的约束条件;步骤2,用式(10)计算各个聚类的中心,记为ci,i=1,2,……,c;步骤3,根据式(8)计算目标函数的值,如果函数值小于预先设定的阀值,或它与上一次目标函数的差值的绝对值小于阀值,则算法停止;步骤4,用式(11)计算新的U矩阵,返回步骤2。
2.3 模糊c均值聚类结果
FCM聚类算法最重要的任务是确定最佳聚类数,现有的算法需要预先确定聚类的数目,但是实际问题中由于样本数量巨大,很难有效确定聚类数目。聚类有效性函数能够通过找到函数的极值达到对聚类数c的优选,而常用的有效性函数一般是基于隶属度的有效性函数,包括划分系数F(U,c)、可能性划分系数P(U,c)和聚类有效性函数P(U,c)[19]。对于给定的聚类数c和隶属度矩阵U:
(12)
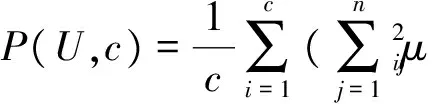
(13)
式中,n为聚类样本个数。
FP(U,c)=F(U,c)-P(U,c)
(14)
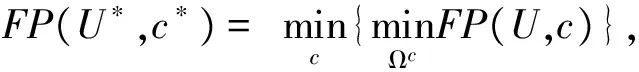
本研究中FCM算法的参数设置如表4所示。
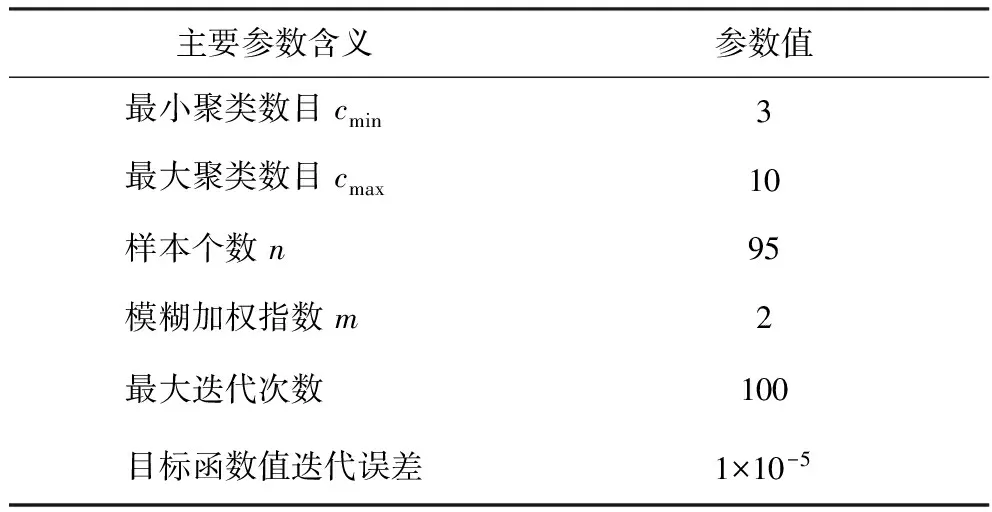
表4 FCM算法主要参数
FCM的最佳聚类数copt事先无法确定,目前许多学者已经提出一些确定copt的有效方法[15-16],但是由于这些方法中的构造函数自身存在缺陷,一般难以通过这些方法直接确定copt。一般情况下,可以先确定聚类数的最小和最大值,然后在该范围内进行试算,计算结果最符合实际过程的聚类数即为最佳聚类数。本研究设定最小聚类数cmin=3,最大聚类数采用经验公式(15)[17]计算。
(15)
式中,n为样本个数。在式(15)的基础上,取最大聚类数cmax=12。FCM聚类有效性函数值和收敛迭代次数与聚类数目的关系见表5。由表5可以看出,当聚类数为5时,对应的有效性函数值最小为0.006 8,因此,FCM算法的最佳聚类数copt=5。表5为当聚类数为5时,95组原料油样本对于不同类别的隶属度。由表6可以看出,第1组样本对于5个类别的隶属度中,对第1个类别的隶属度最大,为0.269 720,说明第1组样本的原料油性质与第1个类别的原料油性质最相近;第3组样本对于5个类别的隶属度中,对第3个类别的隶属度最大,为0.389 022,说明第3组样本的原料油性质与第3个类别的原料油性质最相近。

表5 数据集分类的有效性函数值和收敛迭代次数与聚类数目的关系
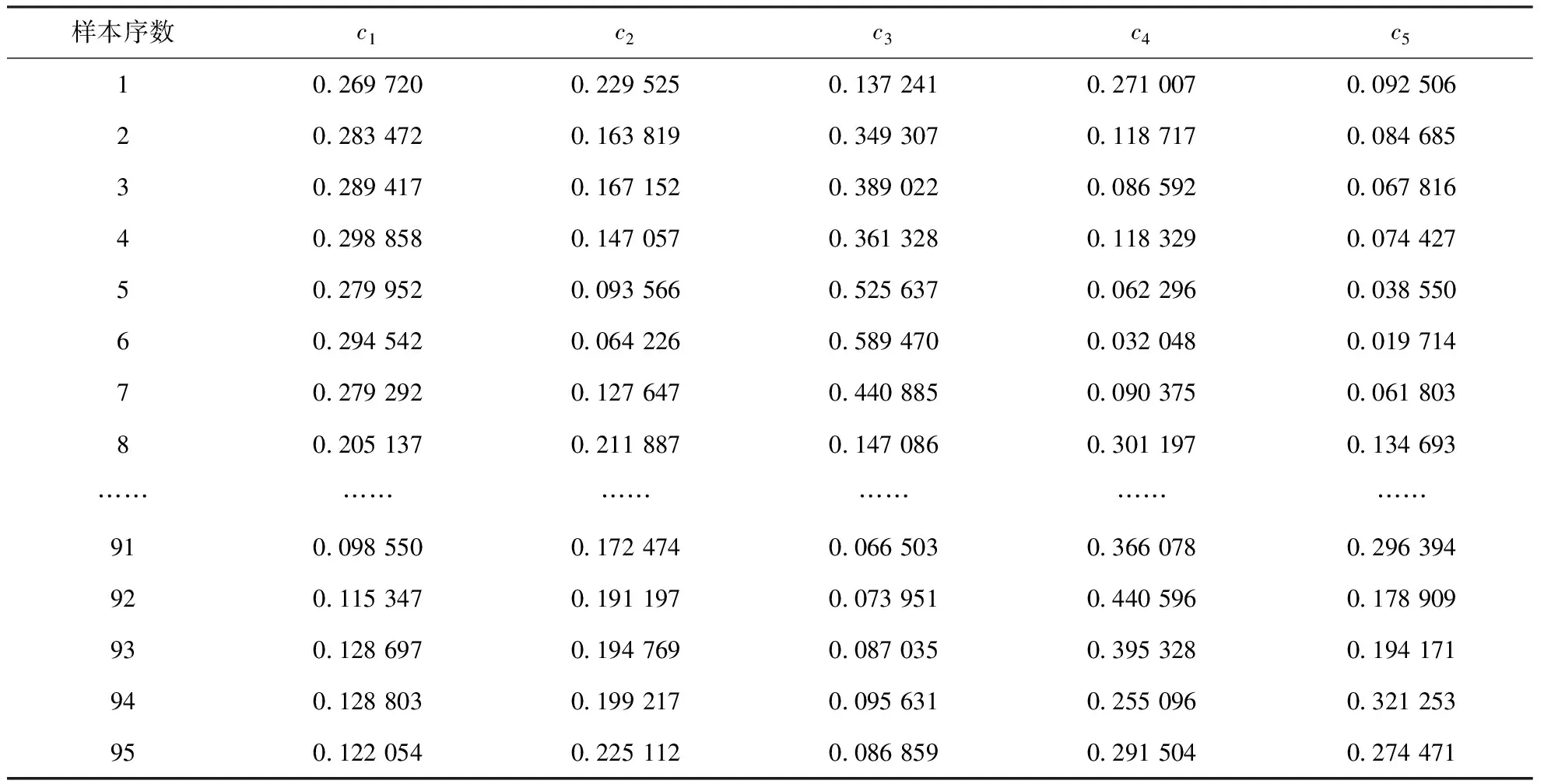
表6 聚类数为5时原料油样本对于不同类别的隶属度
表7为当聚类数为5时,每一类中每个变量的平均值。由表7可以看出,原料油饱和分含量越高,(胶质+沥青质)含量越低,原料油密度越小,残炭越低。第一类原料油命名为“轻质原料油”,这类油的特点是饱和分含量较高,芳香分和(沥青质+胶质)含量较低,同时镍和钒的含量也较低。第二类和第五类原料油密度相近,(胶质+沥青质)含量也相近,说明这两类油轻重程度相似,但是这两类油重金属含量不同,第二类重金属含量明显低于第五类油,因此可以将第二类油命名为“低金属重质原料油”,第五类原料油命名为“高金属重质原料油”,第二类油的饱和分含量相对较高,残炭相对较低,因此汽油收率相对于第五类油大,同时焦炭收率小,催化剂的消耗量较小。第三类原料油命名为“超轻质原料油”,这类油的特点是饱和分含量最高,芳香分和(沥青质+胶质)含量最低,同时镍和钒的含量也最低,这类油的经济效益最高。第四类原料油命名为“超重质原料油”,其特点是芳香分含量和(沥青质+胶质)含量最高,残炭也最高,在反应过程中,该类油汽油收率很低,生焦量很高,同时镍和钒的含量也最高,催化剂的损耗也最高,因此这类油炼制成本最高。

表7 聚类数为5时每一类变量的平均值
3 结 论
以催化裂化MIP装置工业数据为基础,选取原料油性质中的密度、饱和分含量、芳香分、(沥青质+胶质)含量、镍含量、钒含量、残炭等7个变量,建立了原料油性质的K-means和FCM聚类模型。K-means聚类法将原料油性质的95组样本分为4类,分别为“超重质原料油”、“重质原料油”、“超轻质油”和“轻质油”,FCM聚类法将原料油性质的95组样本分为5类,5类油的命名方式是在K-means的基础上将重质原料油分为“低金属重质油”和“高金属重质油”两类。聚类结果中的每一类原料油特征都比较明显,表明K-means和FCM聚类法对于原料油性质的聚类分析均具有较好的适用性。这样,可以针对每一类原料油建立相应的产品分布优化智能模型,从而寻找到使目的产品收率最大的操作条件,对提高炼油厂的经济效益具有一定的指导意义。
[1] 许友好. 我国催化裂化工艺技术进展[J]. 中国科学,2014,44(1):13-24
[2] 周涛,陆惠玲. 数据挖掘中聚类算法研究进展[J]. 计算机工程与应用,2012,48(12):100-111
[3] 杨敬一,邹华伟,蔡海军,等. 原料性质对焦化行为的影响[J]. 石油炼制与化工,2015,46(10):6-11
[4] 鲁红英,肖思和,杨尽. 模糊聚类分析方法在土地整治分区中的应用[J]. 成都理工大学学报:自然科学版,2014,41(1):124-128
[5] 周俊,刘丽川,杨继平. 基于K-均值聚类与小波分析的声发射信号去噪[J]. 石油化工高等学校学报,2013,26(3):69-73
[6] 黎敏. 数据挖掘算法研究与应用[D]. 大连:大连理工大学,2004
[7] 向先全,王海波,路文海,等. 基于数据挖掘的渤海湾水生态环境特性研究[J]. 海洋通报,2013,32(1):72-77
[8] Guha S,Rastogi R,Shim K. Cure:An efficient clustering algorithm for large databases [J]. Information Systems,2001,26(1):35-58.
[9] 贺玲,吴玲达,蔡益朝,等. 数据挖掘中的聚类算法综述[J]. 计算机应用研究,2007,24(1):10-13
[10] 陈安,陈宁,周龙骧. 数据挖掘技术及应用[M]. 北京:科学出版社,2006:183-203
[11] 马飞. 数据挖掘中的聚类算法研究[D]. 南京:南京理工大学,2008
[12] 许友好,张久顺,龙军,等. 多产异构烷烃的催化裂化工业技术开发与应用[J]. 中国工程科学,2003,5(5):55-58
[13] 王千,王成,冯振元,等. K-means 聚类算法研究综述[J]. 电子设计工程,2012,20(7):21-24
[14] 高新波,谢维信. 模糊聚类理论发展及应用的研究进展[J]. 科学通报,1999,44(21):2241-2251
[15] Bezdek J C,Pal N R. Some new indexes of cluster validity [J]. IEEE Transactions on Systems,Man,and Cybernetics,Part B(Cybernetics),1998,28(3):301-315.
[16] 于剑,程乾生. 模糊聚类方法中的最佳聚类数的搜索范围[J]. 中国科学(E辑),2002,32(2):274-280
[17] Rezaee M R,Lelieveldt B P,Reiber J H. A new cluster validity index for the fuzzyc-mean[J]. Pattern Recognition Letters,1998,19(3):237-246
[18] Ruspini E H. A new approach to clustering[J]. Information and Control,1969,15(1):22-32
[19] Bezdek J C. Clustering validity with fuzzy sets[J]. Mathematical Biology,1974(1):57-71
