广告话语中动态多模态隐喻的形式表征研究*
——聚焦模态调用特征及理据
2018-03-09王小平
王小平 王 军
(苏州大学,苏州 215006)
提 要:本文在改进多模态隐喻标注方式的基础上,以30则电视公益广告为例,聚焦广告话语中动态多模态隐喻的形式表征问题。研究发现,动态多模态隐喻形式表征在模态调用层面表现出一定的规律性:(1)多模态隐喻表征模态配置总体上呈现多元化态势;(2)图像、文字、声音3类模态调用总量的分布较均衡;(3)不同概念域的模态调用特征呈现分化:源域模态复杂度高于目标域,且两者显现出不同的模态偏好。针对上述特征,本文深入分析其模态调用理据。
1 引言
表征是认知科学的核心概念,指可反复指代某一外部或想象事物的任何符号或符号集(李恒威等 2008:27)。它涉及两个不同的阶段:第一,作为赖以处理、存储和表达信息的承载结构,是认知过程或状态的产生基础;第二,作为知识的表征,可理解为语义的认知加工和概念化过程。然而,当前语言学界有关隐喻表征的研究主要聚焦于第二个方面,基于具体语料探究道德、运动、情感等不同概念的认知表征,较少关注表征作为承载信息的形式化系统,其信息的组织形式。多模态隐喻植根于多模态语篇,其表征过程诉诸多样化的模态调用及配置,与普通文字隐喻相比,涉及更为复杂的形式化系统及信息组织机理,因此,多模态隐喻的形式表征是一个值得深入探索的话题。
当前,“模态调用”(陈松菁 2016:70)是多模态隐喻形式表征研究关注的热点问题,研究焦点主要关涉多模态隐喻表征过程中所调用的模态配置及其理据。但目前研究者主要围绕漫画(Erden 2009,俞燕明 2013)、海报(王天翼 甘霖 2015)、平面广告(Forceville 1996)以及叙事绘本(赵秀凤 2016)等静态多模态语篇展开研究,并未将动态图像、动态多模态隐喻纳入考察范围。此外,多模态隐喻的“模态调用”除隐喻总体的模态配置之外,源域和目标域各自的模态配置及“模态使用偏好”(Sobrino 2016:73)以及各模态的调用及分布也值得继续关注。
电视广告话语作为典型的动态多模态语篇研究重点关注广告内部隐喻的动态建构、隐转喻的互动、多模态互文等问题,对动态多模态隐喻的形式表征研究却鲜有涉及。本文在修订多模态隐喻标注及分类方法的基础上,探索广告话语中动态多模态隐喻表征的模态调用特征及理据。研究聚焦以下几个方面:(1)广告话语中多模态隐喻的模态配置类型有哪些,源域和目标域的模态配置有何异同;(2)各模态总体的调用情况如何?源域和目标域是否具有模态使用偏好;(3)动态多模态隐喻形式表征的模态调用理据是什么。
2 语料提取及相关处理
2.1 语料选取
本文以30则电视公益广告为研究语料,它们都来源于全国优秀广播电视公益广告作品库,该库由中国中央电视台(CCTV)官方网站承办。截止本文成文时,已收录电视公益广告803部,且相关语料一直在不断地更新扩充,语料兼具代表性与时效性,可体现当前国内电视广告制作的较高水准。该作品库以作品主题为标准将公益广告分为6个类别:文明道德类、环境保护类、安全教育类、反腐倡廉类、法制宣传类、节日纪念类,为体现本研究语料的代表性,我们从以上主题类别中分别随机挑选5则公益广告,共计30则,组成小型自建多模态语料库。
2.2 多模态隐喻的识别
基于自建的多模态语料库,本文采取定量为主,定性为辅的研究方法,对所选取语料中的多模态隐喻形式表征问题进行分析。其中,多模态隐喻的识别是后续研究的基础,因此,对所选的每一则公益广告都进行穷尽式的研究,在参考Bounegru和Forceville(2011:213)识别方式的基础上,本文提出以下多模态隐喻的甄别方法:第一,多模态语篇中的两个概念分属两个不同范畴,并存在相似性;第二,两概念可分别被识解为概念隐喻的源域和目标域,且关系不可逆;第三,两概念域由两种及以上模态共同表达。我们依据以上3个步骤对语料中的多模态隐喻进行穷尽性的识别与统计。
2.3 多模态隐喻标注及分类方式
对语料中的多模态隐喻进行识别后,本文对获取的多模态隐喻进行标注并分类。综览相关文献发现,目前的研究主要基于表征隐喻所调用的模态配置对多模态隐喻进行标注并分类。俞燕明(2013)基于新闻漫画这一语类,提出图文隐喻(PVMs)、图像—符号隐喻(PSMs)、图像隐喻(PPMs)、源域图像目标域隐含的隐喻(PØMs)、目标域隐含的图像隐喻(VØMs)等6类表征方式,并在海报(杨友文 2015)、平面广告(王扬 向恩白 2016)等其他语类中得到验证,显示出一定的阐释力。然而,这一方法存在以下不足:第一,基于静态多模态语篇提出,且标注公式中仅涉及文字、图像两种模态,而动态多模态隐喻表征所调用的模态,配置更为复杂,因此在动态多模态环境中,其适应性存疑;第二,多模态隐喻天然地涉及源域和目标域表征,且两者在隐喻运作机制中的作用及特征并不相同,因此仅笼统地标注模态类型而忽略源域和目标域的分化,并不能全然体现表征的规律与特征。
针对以上问题,我们提出改进当前的多模态隐喻标注方式,在标注公式中凸显源域和目标域,并分别标注两域表征所调用的模态配置;以S和 T分别表示源域和目标域,以p表示图像模态(pictorial mode),a表示声音模态 (auditory mode),w表示文字模态 (written language)。假设某隐喻的源域调用图像模态和声音模态,可标注为S-ap;目标域若由文字模态和图像模态表征,则可标注为T-pw,那么,该隐喻可被标注为S-apT-pw. 这一标注方式既可保留俞燕明(2013)标注方法的优点,可清晰突显调用模态;又可清楚地突显源域和目标域各自的模态配置及使用偏好,有利于更为系统性地探索多模态隐喻形式表征的规律。本研究拟使用这一方式对语料中的多模态隐喻进行标注,并根据其模态配置进行分类。
3 动态多模态隐喻的模态调用
3.1 模态配置
按照多模态隐喻的识别方法我们对选取语料进行穷尽式的研究,共识别出85条动态多模态隐喻,并依据本文改进的标注方式,将其分为9种不同模态表征类型(见表1)。
表1显示, 电视广告话语中多模态隐喻数量最多的3种模态配置类型为:S-apwT-apw(30例,35.29%)、S-apwT-pw(16例,18.82%)、S-apwT-aw(11例,12.94%),占所有模态配置类型的67.05%。以上3类配置都调用图像、声音和文字3种模态,源域和目标域的表征模态也较为复杂。除以上3类,S-apT-apw(9例,10.59%)和S-apwT-p(6例,7.06%)两类也调用3种模态,共计72例,占所有类别的84.7%。这说明,电视广告话语作为一种动态多模态话语,倾向于使用多种不同模态,调动多重感官参与认知。
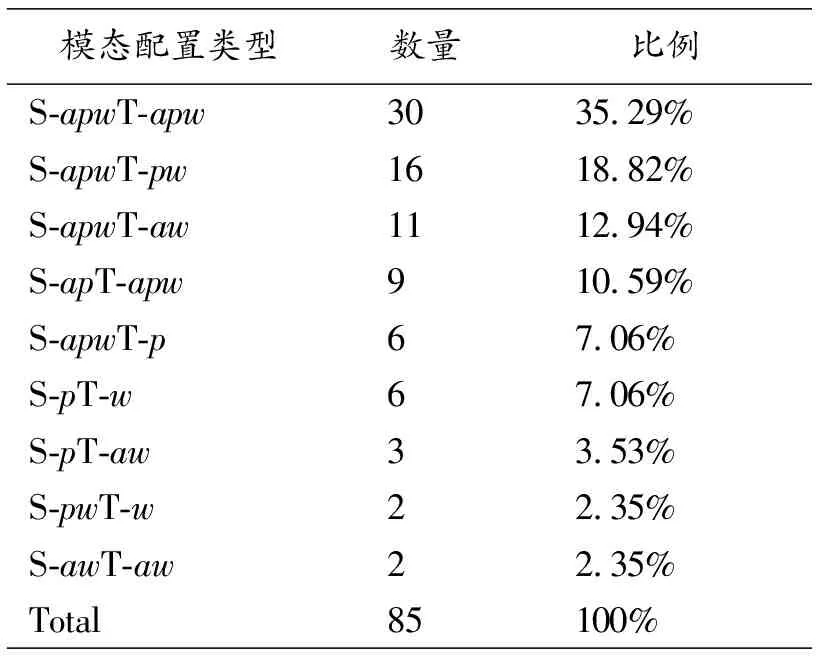
表1 电视公益广告中多模态隐喻模态配置类型①
与此形成鲜明对比的是,数量最少的3类即S-pT-aw(3例,3.53%)、S-pwT-w(2例,2.35%)和S-awT-aw(2例,2.35%)仅占8.23%。分析发现,这几类模态配置文字模态的比例偏高,而图像模态使用较少,这说明广告话语中动态多模态隐喻并不倾向使用较为单一模态,而更倾向于文字与感官模态组合使用。
观察表1可以发现,广告话语中多模态隐喻的源域和目标域由两种及以上不同模态进行表征的比例很高,这从另一个层面证明动态多模态隐喻模态配置的复杂性。然而,我们也发现两者的模态配置表现出不同特征。
3.11 源域的模态配置
根据模态配置,可以将表1中多模态隐喻的源域分为5种类型(见表2)。从数据分布上看,源域的模态类型分布较为集中,最为突出的源域模态配置为S-apw(63例,74.12%),占比接近总数的3/4。这一类型调用3类模态,且3者比例均衡,说明在动态多模态环境中,多模态隐喻的源域表征更加注重调动多重感官系统。
分析源域的模态分布后发现,图像模态在源域模态中的地位几乎无可替代。如表2所示,除S-aw外,其余4类调用图像模态占总数的97.65%,表明在动态多模态语篇中图像模态的特殊地位。

表2 多模态隐喻源域和目标域的模态表征类型
3.12 目标域的模态配置
与源域相比,目标域模态表征类型的数据分布相对分散,最主要的模态配置为T-apw(39例,45.88%),而T-pw和T-aw各16例,分别占18.82%,3类共占目标域模态表征类型的83.52%。从中可以看出,虽然目标域表征同时调用图像、文字及声音3类模态的比例也较高(45.88%),但却远低于源域(74.12%)。在目标域表征过程中,文字模态一般搭配图像或声音模态一同使用,搭配使用的表征类型(71例)占比所有涉及文字模态表征类型(79例)的89.87%。这说明,动态多模态隐喻的目标域诉诸多种感官模态的普遍性。
3.2 模态分布特征
基于表1和表2,我们对电视公益广告中的3种主要模态即图像、文字和声音进行统计,如表3所示:3类模态的使用率都很高,且总体分布较为均衡,文字模态的使用次数最多,共计146次,占比34.84%。图像模态和声音模态则分别使用144次和129次,分别占34.37%和30.79%。然而,对比源域和目标域的模态分布情况发现,两者存在不同的模态偏好。

表3 多模态隐喻的模态使用情况
3.21 源域模态使用偏好
在源域表征所涉及的3类模态中,图像和声音等具象模态的使用率高于文字模态,其中图像模态使用次数最多,共计83次(见表3),占所有源域表征类型的97.65%,声音模态次之(74次),文字模态使用次数最少(67次),这显示图像模态在电视广告这一动态多模态语篇的多模态隐喻表征过程中承载比其他两者更多的信息内容。但图像模态通常与其他模态共同参与表征。广告话语之所以更加依赖图像、声音等具象模态,可能与此类模态更具感官吸引力有关。研究表明,“图像模态在大脑中留下的印象更为深刻”(Siborino 2016:79),且多模态隐喻的运作机制依然是通过源域来理解目标域,即源域的表征更为形象具体,因而可能须要诉诸更多的感官模态。
3.22 目标域模态使用偏好
与源域不同,目标域表征调用最多的模态为文字模态(79次),而后是图像模态(61次),最少的是声音模态(55次)。此外,综合对比目标域的5类模态配置方式发现,其中4类表征类型都用到文字模态,占所有类型的92.94%,这说明文字模态在目标域模态配置中的普遍性。文字模态除参与隐喻表征外,更可发挥对图像、声音等模态的锚定作用,降低产生歧义的可能性。
跨域比较发现,源域中图像、声音模态的分布高于目标域,文字模态的分布则低于目标域(见表3),这体现出源域和目标域的表征特点。从模态使用偏好可以看出,源域的刻画总体上比目标域更加形象具体。须要注意的是,我们不能忽视比例偏低模态在其所在概念域中的重要作用,虽然比例偏低,但绝对数量并不少。例如,源域中分布最少的文字模态使用次数仍达67例,占所有源域类型的78.82%,而目标域中分布最少的声音模态有55例,占64.71%。虽然各种模态比例存在一定差别,但图像、声音及文字3种模态的总体调用较为均衡,在一定程度上顺应人在认知外部世界过程中依赖多重感官的认知习惯。
4 动态多模态隐喻模态调用的理据
数据显示,多模态隐喻的模态调用表现出一定的规律性:第一,电视广告话语作为动态多模态语篇倾向诉诸较为复杂的模态配置,同时调用图像、声音及文字3类模态的频率较高;第二,3类模态分布存在一些差异,但在总量上基本均衡;第三,两概念域的模态调用特征出现分化,源域的模态配置较目标域更为复杂,且图像、声音两类模态的分布高于目标域,而文字模态的调用则少于目标域。下面,我们分别从3个方面对以上特征的理据性进行解释。
4.1 模态调用的复杂化
在广告话语中,多模态隐喻的模态调用呈现复杂化,同时使用图像、文字和声音3类模态比例很高,达84.71%。研究发现,这一特征与模态表征及认知过程的具身性相关。
在多模态隐喻表征过程中,人类的多重知觉发挥重要作用。知觉符号论认为,认知植根于认知主体与世界互动所获得的感觉中(李恒 张积家 2017)。在这一过程中,人并非基于单一渠道,而是诉诸多重感官体验,而隐喻的多模态化表征正顺应这一认知机制。多模态隐喻表征所诉诸的不同模态分别对应人类不同的知觉符号,而知觉符号则对应于认知通道所接受的感官刺激。图像模态对应于视觉符号,所接收信息是对认知对象视觉特征的归纳与突显;声音模态则对应于听觉符号,接收的信息关涉认知对象听觉特征。多元化的感官知觉经过提取、加工、抽象、存储等认知加工过程而形成体验性符号存储于人类的认知系统,成为表征事物的知觉符号。在多模态隐喻表征过程中,对应不同知觉的多元化模态通过组合和拼接融入隐喻及整合机制,使调动不同感官协同创生意义成为可能。
认知是知觉和动作的融合与交织,概念由一系列对真实世界、身体状态、行为内部表征的模拟组成(牛保义 2016:2),因此多模态隐喻在以知觉仿真方式对概念进行仿拟与再现的过程中,必须全方位的考虑认知对象涉及不同感官渠道的知觉特征。以“玫瑰花”为例,若要对其进行全面的仿拟与再现,至少需要考虑3种知觉特征,视觉(花型)、嗅觉(花香)以及触觉(刺)。在调用相关模态塑造对应的知觉特征基础上,更要使其与相关事物产生相似性排列,以诱发认知主体对模态表征内容类似的具身体验。再例如,在某则宣传食品安全的公益广告中,食用油被塑造为“武林高手”的隐喻形象,其中视觉通道上,以健壮的男子样态,红色拳击手套以及流畅的武术动作仿拟“武林高手”的视觉特征,配合各种武打音效对相关图式听觉特征的仿拟,可全方位地再现武林高手的视听觉感知特征,成功激活关于武林高手的具身认知,进而成为优质食用油概念化进程的认知参照,以“武林高手”的健壮与高水平映射“食品安全”的可靠性。在上例中,隐喻性概念的表征对应不同感官的多元知觉符号,以调动人大脑中存储的事物的多模态信息。此外,知觉表征的本质在于认知模仿,其核心在于激活认知主体的感知觉通道及其神经关联,并对多元感官信息进行整合与表征。
4.2 各模态的分布
图像、文字及声音3类模态在多模态隐喻形式表征中所占比重虽存在差别,但总体相对均衡(见表3),这可能与模态表征功能上的互补性相关。作为典型的动态多模态语篇,电视公益广告在建构过程中需要多元媒介符号的协同作用。在3类模态所构成的“多模态集合”(multimodal ensemble)中,每一类模态基于自身特有的“符号逻辑”(semiotic logic),具有不同的供应特征。图像模态在广告话语中以动态图像的形式出现,其符号逻辑兼具时间性与空间性(Serafini 2010:87)。时间性指其实现过程通过镜头或图像的连续性切换;空间性则指每一个镜头或者图像都是由限定于某空间框架(spatial frame)内的成分共时呈现。在多模态隐喻表征过程中,图像模态可诉诸连续性画面再现或仿拟某事的发展过程,进而突显其动态性特征;而单一镜头或画面则可利用图像叙事的共现性,提供相对完整的信息内容,推进叙事的进程。
声音模态作为动态多模态话语中的重要媒介符号,可以突显多模态隐喻的动态性与叙事性。声音模态的符号逻辑体现在其物质性(materiality),即都以声音为载体,这意味着声音的延续性、音高、音量等不同维度成为其意义潜势。其中,声音模态的延续是多模态隐喻在时间维度上具有动态性的重要动因(Forceville 2008:468),而叙事性则可利用声音模态的两个不同要素实现:(1)诉诸有声话语直接引导故事走向与发展;(2)利用音量及音高等变量强调相关信息,表达态度及情感,增强多模态隐喻的叙事性。此外,声音模态还能打破图像模态单一画面的单调,扩大观众想象空间,补充相关重要信息,锚定图像内容。
动态模态的广泛调用可以加强动态性与叙事性,也会使语篇有相对开放的解读方式。动态模态在信息呈现及表达过程中虽然较为生动形象,但因其解读方式主要根据观者的兴趣而并不具有特定的方向性(directionality),会产生歧义或意义模糊(Kress 2009:56)。对此,文字模态可起到补充作用。文字模态的符号逻辑主要体现在文字、短语、句子根据语法及句法乃至社会文化等规则对语言的规定与限制,这一限制直接催生文字模态的“线性”以及“方向性”规则(同上),可在一定程度上锚定图像解读方向,减少动态模态引起的歧义性和模糊性,因此文字模态在动态广告话语中得到广泛使用。不难发现,图像、声音及文字3类模态在电视广告话语中优势互补,相得益彰,共同构成这一语类中的模态集合,多模态隐喻可利用模态的协同作用与互补强化其意义表达。
4.3 源域和目标域的模态偏好
动态多模态隐喻源域和目标域在表征过程中对不同模态存有偏好,如表2和表3所示,源域比目标域模态复杂度更高,且前者图像、声音模态的分布比文字模态更为广泛。我们认为,这可能与两者在隐喻基本运作机制中角色的不同有关。
一般人们认为,隐喻的基本运作机制是通过较为具体的源域来理解或体验相对抽象的目标域(Schilperoord, Maes 2009:214),即源域为目标域的概念化过程提供较为形象具体的概念参照,这在一定程度上决定源域概念要比目标域的概念结构更为清晰。这一特征在多模态语境中也基本得到延续,虽然多模态隐喻的源域和目标域同时基于具体事物的可能性很高,但是“具体”与“抽象”在这里是一个相对的概念,通常来讲,多模态隐喻的源域要比目标域更加形象具体(王扬 向恩白 2016:92),即需要多元模态对其进行刻画与表征。相关研究证明,模态复杂度与相关概念或活动的复杂程度存在一定的关联(Norris 2011:82-83),复杂的概念或活动因为涉及更为多元的内容或结构须要调用多元媒介,所以模态配置的复杂度较高。与目标域相比,源域作为认知参照在表征过程中须要呈现更多的细节,结构明显更为复杂,这可能是源域模态复杂度偏高的原因。
此外,图像、声音模态在源域中的分布之所以比在目标域中更为集中,也与两者在表征中不同的角色相关。源域作为概念参照所需具体化的表征要求在多模态语篇中体现为图像、声音模态的集中调用。由于概念域本质上是一种概念空间,而“概念空间由不同的维度构成,例如颜色、音高、温度、重量以及其他维度,这些维度都基于我们的感官知觉”(Zenker, Gärdenfors 2015:4),这些固然可以通过文字模态进行描写,但却无法完全表现非语言模态的鲜明特色,比如图像模态在电视广告中的物质性特征除“颜色”“形状”“线条”等因素外,还独具动态性,这赋予它特殊的意义潜势。目标域在多模态语篇中的表征形式虽然与传统文本语篇相比也较为复杂,然而作为隐喻的认知对象,其表征义及可识别性不容有过多的模糊空间,因此文字模态作为意义锚定的主要工具,在目标域的分布比源域更为集中。由此可见,源域和目标域自身认知角色的不同是影响概念域模态使用偏好的重要因素。
5 结束语
本文以模态调用特征及其理据性作为切入点,阐释动态多模态隐喻在电视广告话语中的形式表征。研究提出在多模态隐喻表达式中分别标注源域和目标域及其各自的模态配置,以改进多模态隐喻的标注方式。对广告话语的应用分析验证这一方式对于揭示并细化动态多模态隐喻模态的调用规律的可行性及有效性,此外,通过对多模态隐喻模态配置及其分布理据性的探究,进一步揭示不同模态参与多模态隐喻表征的组合方式及其内在机理。研究结果显示,动态多模态隐喻的模态组合类型呈现出多元化态势,这表现在电视广告中多模态隐喻的表征倾向于同时使用图像、声音、文字3类模态;此外,源域和目标域具有不同模态配置类型,并表现出相差迥异的模态使用偏好。前者不仅模态配置类型更为复杂,而且图像及声音等模态的调用也远超后者,显示出在电视广告中多模态隐喻形式表征的显著特征。多模态隐喻的核心要义在于认知模仿,而认知模仿的核心在于激活认知主体不同方面的感知觉通道及其神经关联,并对多元感官信息进行整合与表征,这可能是不同模态得到广泛调用的原因。每一类模态基于自身的“符号逻辑”,具有不同的意义潜势,因此它们总体的分布较为均衡。然而由于源域和目标域认知功能的差异,两概念域对不同模态表现出不同的使用偏好。在电视广告这一语类中,不仅要平衡不同模态的调用,更要结合广告宣达目的、概念域特征及符号逻辑对其进行有侧重的运用,以使多模态隐喻的形式表征发挥最大效用。
注释
①表1和表2中的数据均以四舍五入方式精确至小数点后两位,所以存在一定的误差。
