基于Aprior算法的校园网络安全分析模型研究
2018-03-08朱恒蓓
朱恒蓓
(亳州职业技术学院 信息工程系,安徽 毫州 236800)
0 引言
在高校的信息化建设工作中,校园网是其重要的组成部分,由于校园网也是网络的一种.因此,其具备英特网的所有的特性及功能,所以校园网也存在着英特网所需要面临的所有网络安全问题.目前,由于大量的网络安全隐患的存在,导致校园网一直都处于亚健康的状态,对校园内部信息化办公也有一定的影响.为了解决这一现状本文构建了一种基于apriori算法的网络安全综合分析模型,从而有效的提高了网络安全分析效率和准确性.
1 数据挖掘技术
数据挖掘(DataMining DM),可以说是人工智能领域未来的重点方向.所谓的数据挖掘,即是对数据库中海量的数据进行一系列的处理,包括:预处理、抽取、统计及分析等步骤操作.进行数据挖掘的主要目的就是通过对海量数据进行处理后,利用人工智能、数据库技术、可视化技术及统计学等技术,统计并归纳出数据的逻辑.通过数据挖掘技术,在海量的数据中,发现和归纳出其规律和支持,为企业的决策人员提供技术支持.
1.1 决策树
所谓的决策树算法,通俗的来说它就是分类算法.利用决策树算法,可以对海量的无序数据进行分类方法,决策树算法主要应用在分类器和预测模型[1].因此,在本文设计的校园网络安全管理系统中,网络安全威胁检测模型的设计,是基于决策树算法,对连接到校园网络的用户行为进行预测的.基于决策树算法流程图,如图1所示.

图1 决策树算法流程
图1是一个典型的决策树算法流程图,决策树算法主要由以下两个步骤来实现:
(1)从网络攻击行为数据库中,抽取出训练需要的数据样本,为这些攻击行为数据样本建立决策树模型,通过决策树和剪枝来实现;
(2)为攻击行为训练样本的决策树模型建立后,对这些数据样本进行分类处理,逐步的进行分支方向确定.
其中,在构建决策树模型过程中,根据这些样本数据的度量,对具有不同特征属性的样本数据,进行决策处理.第一步,通过样本集合S,根据特征属性创建决策点N;第二步,按照决策树分类方法,对数据样本集合S进行判断和分支决策操作;最终,得到样本数据集合S的完整决策树.决策树构建流程,如图2所示.
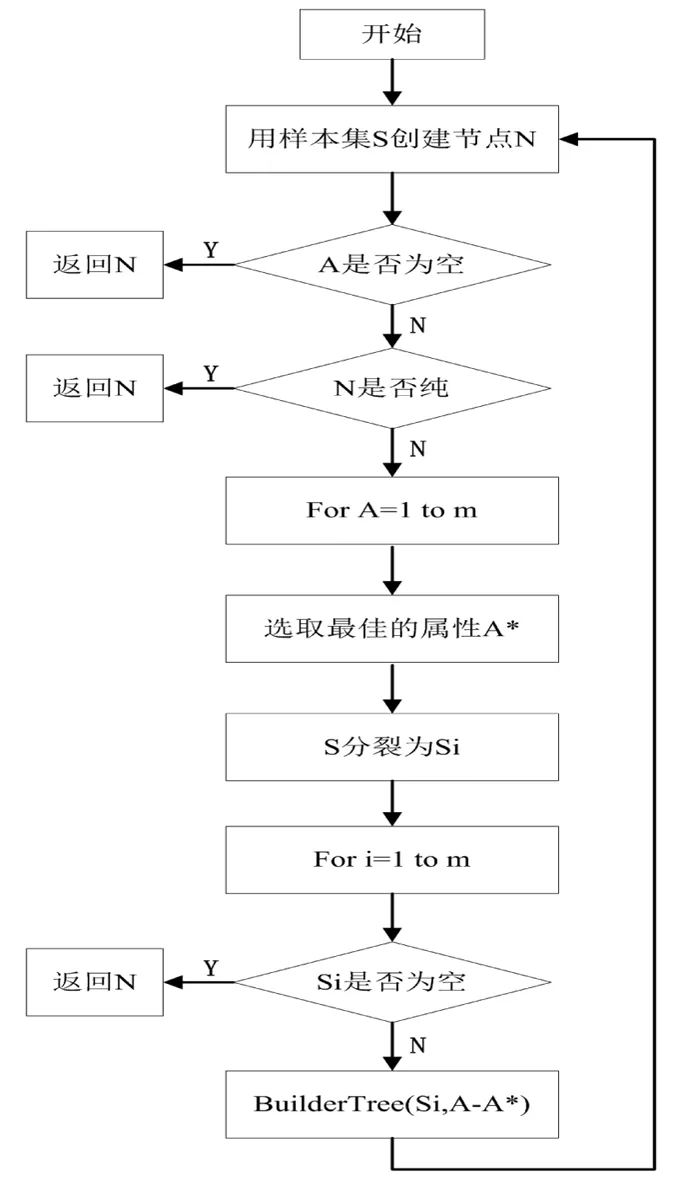
图2 完整的决策树构建流程
1.2 apriori算法原理
笔者经过对当前学校网络安全业务和相关的样本数据,进行全面的分析后,最终选择了apriori算法,来对网络安全系统的数据进行数据挖掘操作;apriori算法在数据挖掘分析系统中,被广泛的应用到.apriori是关联规则的频繁项集算法,它是通过逐层搜索的迭代方法进行划分的,通过L1频繁集合,来寻找频繁集合L2,逐渐的往下迭代,查找到项集L3···Ln,直到不能找到频繁k项集为止.在apriori算法过程中,每寻找到一个频繁项集Lk,系统就会重新对数据库进行扫描一次.apriori算法有以下两个特征:
特征1:基于apriori的查找过程,全部子集都是频繁的;
特征2:全部非频繁项集k-1,都不是频繁项集k的子集.
基于apriori算法的挖掘过程,分为连接与剪枝两个步骤[2]:
(1)连接
它是apriori算法实现过程中,最为重要的一个步骤.这个步骤存在的主要作用,是为了找出样本数据中所有的频繁项集Lk,通过项集Lk-1与apriori算法连接,产生的侯选频繁项集k,则该项集就被标记为Ck;
(2)剪枝
其中,Ck是Lk的超集.所谓超集的意思是在整个样本数据集合中,该样本内成员数据,可以是频繁子集,也可以是不频繁子集;但是,在集合内的所有子数据成员,只要它们自身的属性,有一个是满足频繁子集条件的,则该数据子集就要划分到Ck项集.apriori算法在执行过程中,首先对系统数据库进行扫描,通过扫描操作,来确定数据库中与Ck候选相关的项集,再来确定Lk项集.不过在Ck项集确定过程中,最终得到的Ck项集,可能是个很大的集合,这样就会给数据的处理带来很大的麻烦,使处理时间大幅度的增加;因此,通常采用压缩的方式,对产生的Ck项集进行压缩处理,从而提高运行的效率.
虽然,apriori是当前使用最广泛的数据关系分析算法,不过该算法也有自身的不足:
(1)算法实现过程中,会出现很大的候选集.
apriori算法,是通过频繁对系统数据库进行扫描,来最终产生候选集合.因此,这些候选集必然会是个庞大的集合.候选集合产生后是储存在系统内存中的,这就给系统的运行带来极大的压力,这种以损耗内存的算法,应用在校园网网络安全系统中,由于要对海量的数据信息进行扫描,结果直接导致服务器宕机;
(2)每对一个项集进行处理,就会扫描一次数据库.
在算法循环过程中,k次循环所才声的候选项集Ck中的每个子集,都需要通过对数据再一次的扫描验证,才能判断子集能否加入Lk项集.这个过程会很大的消耗系统的资源,使算法的性能下降[3].
2 基于apriori算法的安全分析模型设计
2.1 安全分析流程设计
基于apriori算法的数据挖掘流程,应用到校园网络安全综合分析模型中,进行安全分析流程的设计,在对网络数据进行挖掘过程中,分为数据准备及安全分析两个阶段;其中,在数据监测阶段,系统主要是对网络用户历史行为数据进行收集,并将这些数据进行预处理操作,对数据进行预处理的过程,就是对行为数据进行抽取、清洗及整理等操作,将从这些数据的特征信息进行提取,并保存到知识规则数据库内.当系统对数据流量进行分析时,通过与规则库内的特征值,进行对比和分析,当数据流量特征值达到或者超过设置的参数时,将向系统发出告警信息[4].基于apriori算法的网络安全分析流程图,如图3所示.
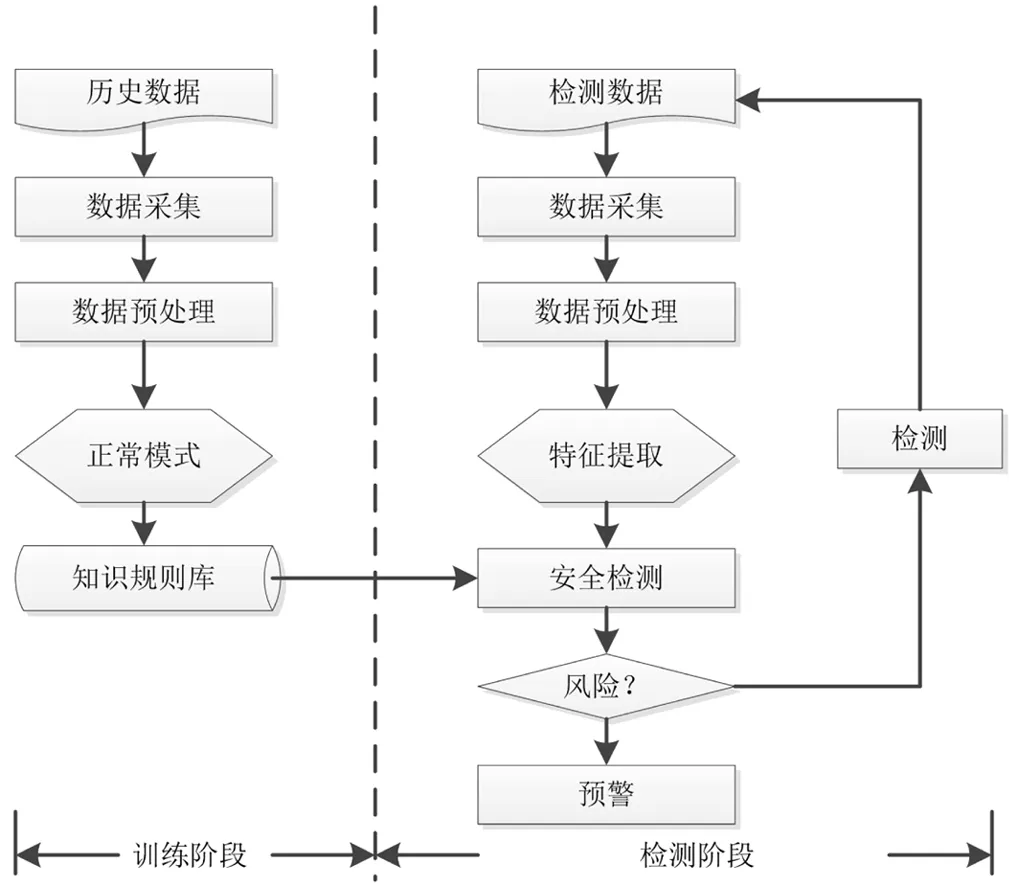
图3 安全分析流程图
2.2 网络安全检测模型设计.
基于apriori算法的网络安全检测模型,主要是由网络协议和流量安全检测及分析模型组成的.在对流量安全检测和网络协议安全检测模型,进行设计过程中.将结合优化后的apriori算法,来对流量检测和网络协议分析模型进行详细的设计.
(1)流量检测及分析模型设计
笔者对流量安全检测及分析模型的设计思路,是以传统检测及分析模型为基础的,通过将流量分析过程中,如果统计出流量特性不符合知识数据库规则模型的簇,将该流量设置为异常流量,同时分析过程中产生的离群点,也要被定义为异常流量[5].按照snort规则,对异常簇的特征,进行信息编码并保存到数据库中,将所有的异常簇信息编码应用到snort中,就使snort模块具有流量检测及分析功能了;在网络安全系统中,流量检测及分析模型,如图4所示.

图4 流量检测及分析模型
(2)网络协议安全分析模型的设计.
在校园网网络安全系统中,网络协议安全分析模型的主要功能,是对网络的异常行为检测[6];该模型对网络的检测方式,不光有响应型检测请求,或者单一的网络请求;安全分析模型在检测过程中,模型将根据当前网络中的数据流的协议状态,进行安全分析及检,通过该模型能够检测到多个入侵行为.

图5 网络协议安全分析模型
2.3 apriori算法的改进及仿真结果分析
(1)apriori算法的改进[7]
在前面的章节中,已经对apriori算法原理进行详细的分析.同时,也对apriori算法的优势和劣势也进行了分析.通过分析可知,将apriori算法应用到网络安全系统中,在进行安全分析时,不但会产生庞大的候选集,还会多次的对数据库进行扫描,这样会极大的消耗系统内存,降低网络安全系统的工作效率;基于此,笔者将以上两方面的问题,采取相关的措施进行改进处理.
庞大候选集改进方案:按照apriori算法的性质来看,在频繁项集中全部的非空子集,必须也是频繁的.当项集i出现在k频繁项集Lk中,那么在项集Lk中,包含i的非空子集,就会有k-1个;当项集i在Lk-1中,出现的次数小于k-1次时,那么就说明项集i,不被包含在项集Lk中;因此,对庞大候选集方案的改进思路是,系统在生成新的频繁候选集Ck前,首先对项集Lk-1进行剪枝处理,剪到与k频繁项集生成没有关联的项集,来提高处理能力,这样也就减少了庞大候选集的生成.
多次扫描数据库改进方案[8]:由于apriori算法的网络安全系统,没运行一次就需要对数据库进行扫描,为了减少对数据库的扫描次数,可以采用以下两个规则,对数据库进行压缩处理.
规则①:在频繁项集k中,将那些比非频繁项集(k-1),多一项集的k中项集,进行剪枝处理;
规则②:每个项集的频繁项集(k-1)个生成后,对应的在数据库中,将k-1个项集是事物删除掉.
从规则①得出,比项集(k-1) 多一项的k项事务,不会出现在项集Lk中.因此,就可以采取提前对那些产生频繁项集无用的项集事务进行删除,就能实现减少扫描事务数据库.
综上所述,将apriori算法应用到网络安全系统前,对apriori算法的改进步骤:
步骤①:对数据库D进行扫描,找到频繁侯选集C1.
步骤②:通过比较C1中每个项集的支持度计数,找到频繁项集L1,将Lk中每个项集,根据支持度计数,进行升序进行排列.
步骤③:对事务数据库进行压缩.
步骤④:L1自连接生成项集C2.
步骤⑤:执行步骤⑨.
步骤⑥:根据规则①,对频繁项集进行剪枝.
步骤⑦:对剪枝后的项集进行重新排序,按照Lk-1x的升序规则,对Lk-1中项集进行重新排序,重新排序后的(k-1) 多频繁项集记为Lk-1.
步骤⑧:Lk-1自动连接后,生成频繁侯选k中项集Ckk>1.
步骤⑨:对事务数据库进行压缩.
步骤⑩:把项集Ck中,那些不满足最小支持度的项集,全部删除掉,就生成项集Lk.
(2)apriori算法改进仿真实验及分析
经过对apriori算法改进后,还需要对改进的结果进行验证,以验证其效果.因此,本文将进行apriori算法仿真实验.仿真实验在以下实验环境中完成,CPU:Celeron(R)2.53GHz;内存:1GB;数据库系统:Oracle10g;开发环境为MyEclipse;系统开发语言为Java.
实验方法:笔者选择10000条网络异常特征数据,这10000条网络数据是由5不同的业务需求组成的,将在实验环境下进行安全分析.仿真实验所需要的网络数据,是从系统系统数据库中导出的,对这10000条网络数据进行实验前,首先需要进行预处理操作,将它们进行归一化处理操作.仿真实验分两组来进行,通过结果分析,以验证apriori算法应用在网络安全分析挖掘模型中,对数据进行挖掘的可行性和有效性.当最小支持度sup_min,固定为1.5%时,针对不同的业务事务数,比较apriori算法、FA算法、改进型apriori算法,它们之间的执行时间.执行时间仿真实验结果,如图6所示.
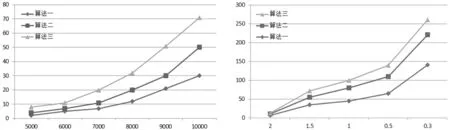
图6 apriori算法、FA算法、改进型apriori 图7 不同最小支持度,apriori、FA、改进型apriori
从图6中可知,apriori算法、FA算法、改进型apriori算法的执行时间,都是随着事务数的增加,执行时间也会同时增加.不过改进型apriori算法,在进行仿真实验前,已经进行了归一化处理操作,该预处理操作能减少47%侯选集的生成;因此,改进型apriori算法的执行时间想比较与apriori算法、FA算法而言,增长速度要明显的缓慢.由此可知,当挖掘的对象是海量数据时,改进型apriori算法在执行时间上,将更有优越性.
从图6中可知,当挖掘的事务数据固定在8000条时,最小支持度sup_min,不固定时,针对不同的业务事务数,比较apriori算法、FA算法、改进型apriori算法,它们之间的执行效率.执行效率仿真实验结果,如图7所示.
从图7中可知,最小支持度sup_min越小,apriori、FA、改进型apriori算法执行的时间也就越长.在仿真实验中,当最小支持度sup_min,从0.5%减小到0.3%时,apriori算法执行时间增长速度最快;FA算法执行时间相比apriori算法要慢一些;而改进型apriori算法,则执行时间增长速度是最慢的.在不同最小支持度仿真实验中,改进型Apriori_Sort算法,能减少52%候选集的生成.
2.4 改进型apriori算法的入侵识别模型设计.
在对apriori算法的进行改进验证后,结合前文的网络协议和流量异常安全检测模型[9].本文将设计一种基于改进后apriori算法的网络入侵安全分析模型,该模型能够有效的对网络中的异常流量和安全协议进行分析和识别.改进后apriori算法的网络入侵安全分析模型,如图8所示.
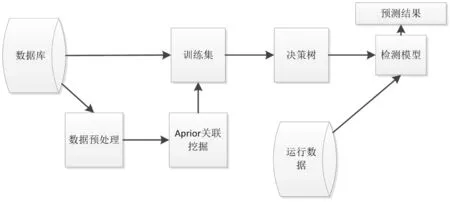
图8 改进型apriori算法的网络安全分析模型
在图8安全分析模型,是由决策树构建、检测模型、apriori算法关联挖掘及预处理四个核心模块组成的.其中,检测模型进行安全检测,是通过流量安全及网络协议安全检测及分析模型,来执行相关检测的.以下将对数据预处理、关联规则的产生及决策树的构建,这三个核心模块设计进行说明:
(1)数据预处理过程
在校园网网络运行过程中,不同网络网络行为事务的格式都不相同.因此,对网络数据的入侵行为检测过程中,利用改进型apriori算法,对时间进行处理时;首先,将采集到的不同类型事务的时间,进行格式化和标准化处理;然后,按照统一的规范数据格式,将它们保存到数据库中.数据预处理过程表,如表1所示.
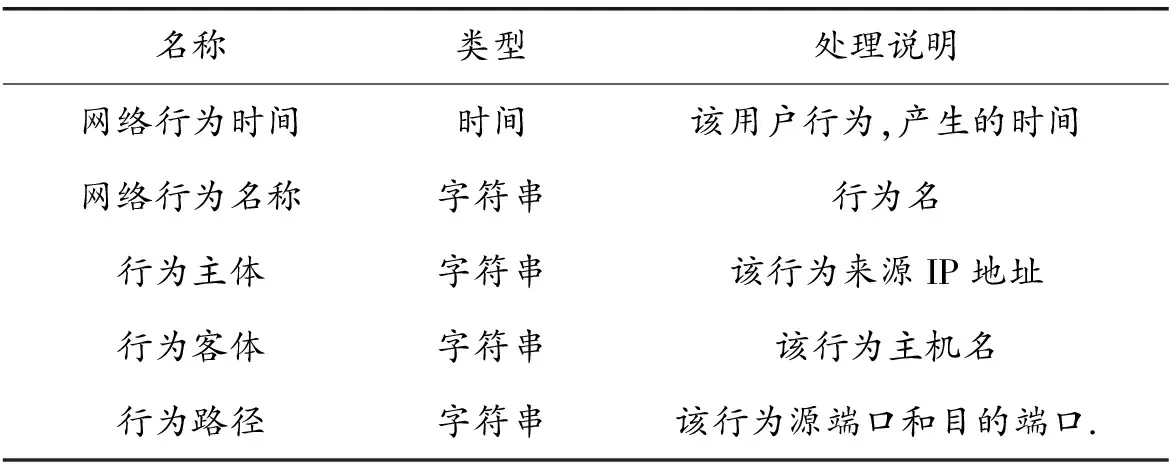
表1 数据预处理过程表
(2)关联规则的产生
当对相关的数据进行预处理后,利用apriori算法数据预处理过程表,进行关联性分析[10].对数据预处理过程表进行关联分析,采用的是bool关联模型来进行过程关联分析.将网络运行过程中,用户每次的网络行为处理成一个事务,通过采集大量的用户行为,构建整个网络环境的事务数据库.保存在事务数据库中用户的信息表由行为时间、行为名称、行为路径及行为客体字段构成;其中,在用户行为信息表中,用户行为的ID标记,具有唯一性.通过apriori算法的挖掘模型,进行数据的挖掘.挖掘完成后形成的关联规则,如表2所示.
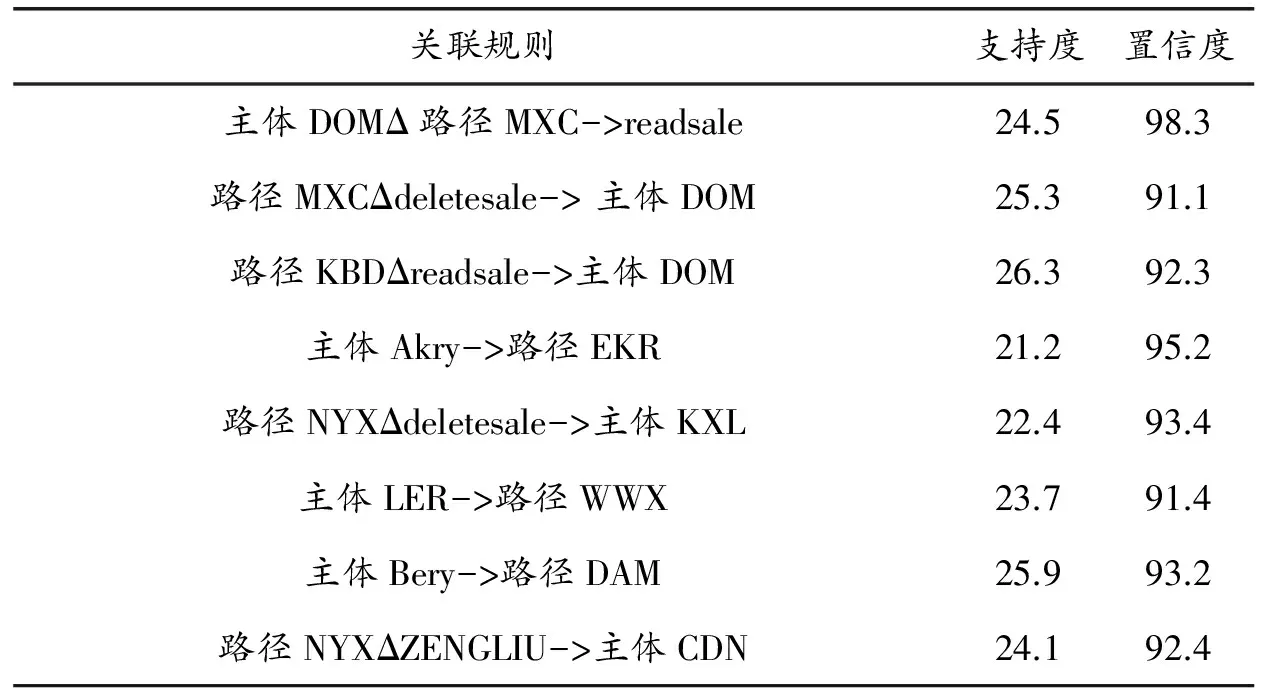
表2 关联规则结果表
如表2中,关联规则形成后,进一步构建决策树,对数据训练集进行扫描,并采用得到的关联,对训练集进行压缩后,对训练集的预处理完成.预处理训练集结果,如表3所示.
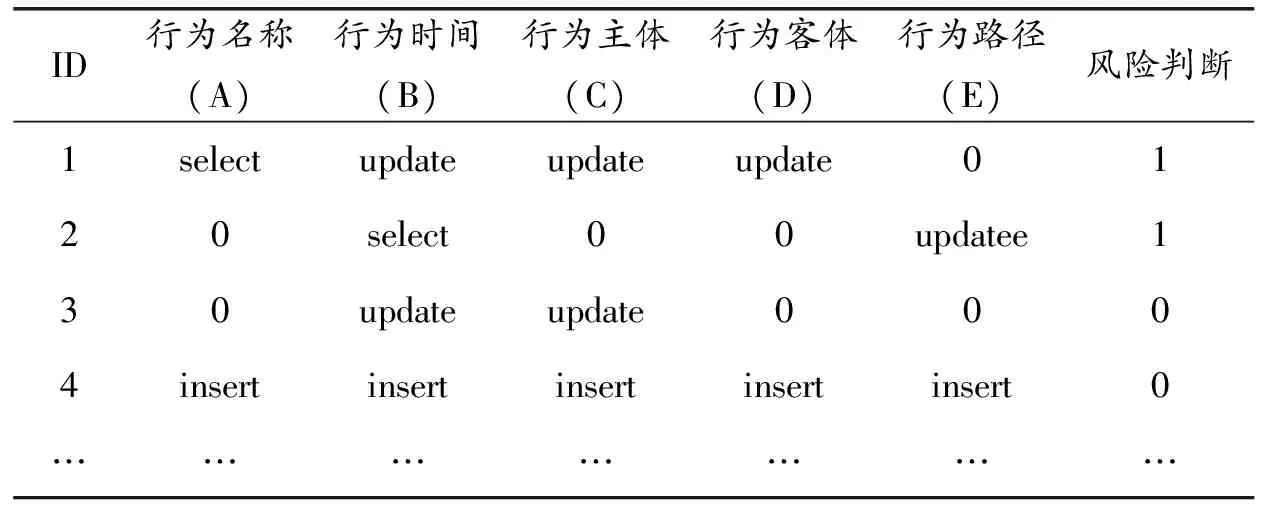
表3 预处理训练集表
最后,利用聚簇规则,训练集进行压缩处理.在聚簇规则中,对于count小于*018的规则,进行全部的删除.压缩后的训练样本数据表,如表4所示.

表4 压缩后训练样本数据表
(3)决策树的构建
基于关联规则的决策树构建,推导到本文的网络安全分析模型中,决策树结构图,如图9所示.
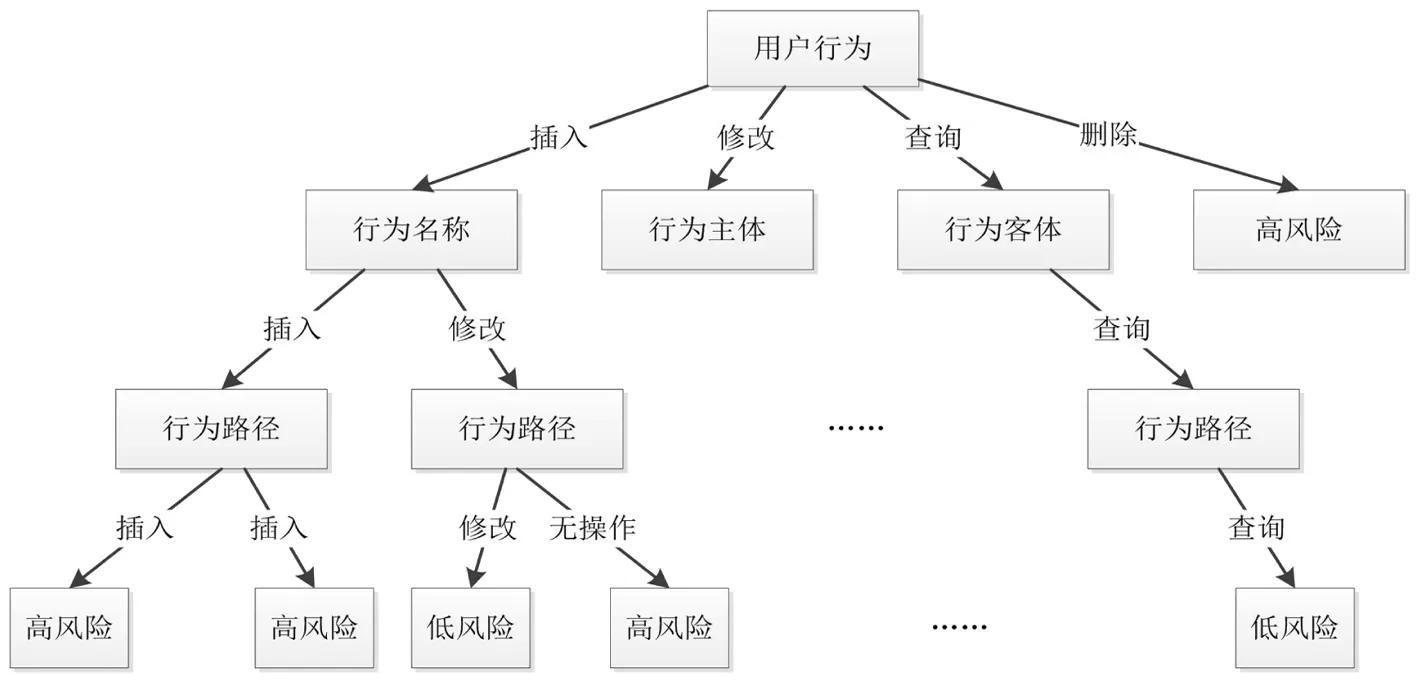
图9 决策树结构图
3 结论
通过对apriori算法原理的理解,结果本文的实际需要,将aprior算法应用网络安全检测及分析模型中.同时,考虑到apriori算法有重复扫描数据库及产生庞大候选集问题,笔者在apriori算法的基础上,进行了改进处理.使改进后的apriori算法,应用在校园网络安全系统中,执行的效率越高,占用系统资源更少.
[1]王雪丽,宋启祥.一种新型计算机网络拓扑组建模式研究[J].枣庄学院学报,2017,34(5):105-108.
[2]白莹莹,申晨晨.基于关联规则挖掘的Apriori改进算法[J].电子技术与软件工程.2017, (3):203-204.
[3]Ponsam J G, Srinivasan R. Multilayer Intrusion Detection in MANET[J]. International Journal of Computer Applications,2014, 98(20):78-80.
[4]刘强.基于数据挖掘的入侵检测系统设计与实现[D].电子科技大学,2013:48-50.
[5]Elhag S, Fernández A, Bawakid A, et al. On the combination of genetic fuzzy systems and pairwise learning for improving detection rates on Intrusion Detection Systems[J]. Expert Systems with Applications,2015, 42(1):193-202.
[6]Mehra L, Gupta M K, Guruji M B. An Effectual and Secure Approach for the Detection and Efficient Searching of Network Intrusion Detection System NIDS[J].International Journal of Computer Applications,2014, 108(15):89-91.
[7]邢雪霞.基于数据挖掘的网络入侵检测系统的研究[D].成都理工大学,2014:21-23.
[8]张志杰.基于数据挖掘的网络安全态势分析[J].网络安全技术与应用,2016 (3):62-62.
[9]牛晨晨.大数据流式计算的关键技术研究[J].枣庄学院学报, 2017 , 34 (2):110-115.
[10]潘晓君,李如平.基于RFID的二进制树形存储搜索算法的应用研究[J].枣庄学院学报,2017,34 (2):123-127.
