基于Word2Vec和LDA主题模型的Web服务聚类方法
2018-03-05肖巧翔曹步清张祥平刘建勋李晏新闻
肖巧翔,曹步清, 2,张祥平,刘建勋,李晏新闻
基于Word2Vec和LDA主题模型的Web服务聚类方法
肖巧翔1,曹步清1, 2,张祥平1,刘建勋1,李晏新闻3
(1. 湖南科技大学 计算机科学与工程学院,湖南 湘潭,411201; 2. 北京邮电大学 网络与交换技术国家重点实验室,北京,100876; 3. 泉州师范学院 航海学院,福建 泉州,362699)
为高效地发现满足用户需求的Web服务,针对Web服务的描述文本较短、缺乏足够有效信息的问题,提出一种基于Word2Vec和LDA主题模型的Web服务聚类方法。该方法首先将Wikipedia语料库作为扩充源,使用word2vec对Web服务描述文档内容进行扩充,再将扩充后的描述文档利用主题模型进行特征建模,将短文本主题建模转化为长文本主题建模,更准确地实现服务内容主题表达,最后根据文档的主题分布矩阵寻找相似的服务并完成聚类,使用从ProgrammableWeb收集的真实数据进行实验。研究结果表明:本文方法与TFIDF-K,LDA,WT-LDA和LDA-K方法相比,分别提高419.74%,20.11%,15.60%和27.80%,利用扩充后的Web服务的描述文档进行聚类的方法能够有效提高Web服务聚类的效果。
Web服务;Word2Vec;LDA主题模型;K-means算法;Web服务聚类
近年来,随着互联网技术的快速发展,Web服务技术作为服务计算(SOC)和面向服务架构(SOA)的主要实现技术已经得到广泛应用[1]。通常,单个Web服务所提供的功能并不能满足用户多功能的需求。开发人员更倾向于通过以松散耦合的方式组合现有的基于RESTful的Web服务来创建多功能的Mashup服务。由于Mashup服务具有易编程和开发周期短等特性,Mashup服务变得越来越流行[2]。然而,与传统的Web服务相比,Mashup服务缺少规范的形式化描述模型,如Mashup服务的描述文本内容过少、描述语言不规范等,这些都增加了Mashup服务查找与发现的难 度[3]。如何发现适合的Mashup服务是Web服务发现所面临的一个重要问题。Web服务聚类技术是用于提高Web服务发现精度的一种重要技术[4],它将Web服务按照其功能属性进行划分,使得划分到相同簇中的Web服务功能相似度较高,不同簇中的Web服务功能相似度较低。通过计算Web服务功能相似度的聚类方法,能够有效提高Web服务搜索引擎的查找效率。目前,国内外研究者对Web服务聚类进行了大量研究。现有的关于Web服务聚类的研究主要聚焦于Web服务功能属性的聚类研究。基于功能的Web服务聚类主要依据的是Web服务功能的相似性而将它们聚到具有相似功能的类簇中。例如,YU等[5]提出一种基于服务和操作联合聚类的服务社区学习算法,把具有相似功能的服务聚类为同构服务社区。文献[4,6]从WSDL文档中抽取关键特征,用于表示1个Web服务;然后,基于这些特征,计算Web服务之间的相似性,将服务聚类到功能相似的类簇。也有许多方法引入许多辅助信息来改善主题模型的训练过程[7−9],例如,CHEN 等[7−8]使用WSDL文档和Tag信息作为输入信息,分别计算获得WSDL文档相似性和Tag相似性,并合成这2种相似性实现服务聚类。黄媛等[9]也提出一种基于标签推荐的Web服务聚类方法,该方法结合了描述文档和Web服务标签来进行聚类。李征等[10]提出了一种基于概率、融合领域特性的服务聚类模型。SHI 等[11]提出一种利用词向量的增强LDA(Latent Dirichlet Allocation)服务聚类方法。对Web服务描述文档中的所有词进行聚类,使这些词汇聚类信息参与LDA模型的训练过程。这些方法都是通过对Web服务的描述文档进行建模,抽取出Web服务的关键特征,再对Web服务进行聚类。但目前大部分主题模型都无法对这类缺乏训练语料库的短文本进行较好建模。由于原始描述文档包含较少信息并且使用自然语言来描述,这使得主题模型提取的Web服务隐含主题信息不够准确,虽然当前有些主题模型在训练过程中引入了辅助信息,如Web服务的标签信息、词聚类信息等,但相比传统的LDA主题模型[12],改进现有的主题模型对Web服务聚类准确率的提升并不明显。针对这一问题,本文提出一种基于Word2Vec和LDA主题模型的Web服务聚类方法。利用Word2Vec对Web服务的短文本进行扩充,能够获得额外的文本信息,将短文本主题建模转化为长文本主题建模,使得主题模型能够有效地估计出Web服务描述文本的隐含主题,提高聚类的精度。再将这些扩充后具有额外信息的描述文档用于LDA主题建模,从而获得更加准确的聚类效果。
1 预备知识
1.1 Word2vec文本扩充
Web服务的描述文本通常比较短,如在本文中使用的数据集,平均每一个Web服务的描述文档仅包含24.16个词。直接利用LDA等主题建模方法难以有效地估计出服务的隐含主题。因此,需要对Web服务的描述文本进行扩充。
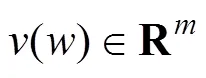
本文利用Word2vec训练出维基百科(Wikipedia)英文语料库的词向量模型。本文使用的Wikipedia英文语料库数据量大,共有11GB。因此,采用的是基于负采样的CBOW(continuous bag of words)模型。假设(,C)是从训练数据集提取出来的词及其上下文信息C信息对。那么通过周围词来预测当前词的概率如下:
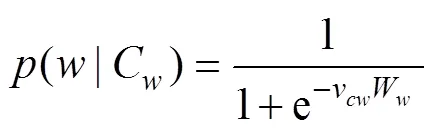

CBOW模型训练目标的极大似然估计函数,表达式如下:
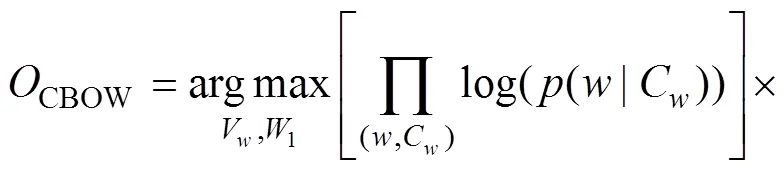

1.2 LDA特征建模
通过文本扩充,将短文本主题建模转化成为长文本主题建模,利用LDA主题模型对服务内容进行特征建模,实现Web服务内容的主题表达。
LDA主题模型可以将每篇文档的主题以概率分布的形式给出[14],用来识别大规模文本中的隐含主题信息,在信息检索等都有得到了广泛的应用。
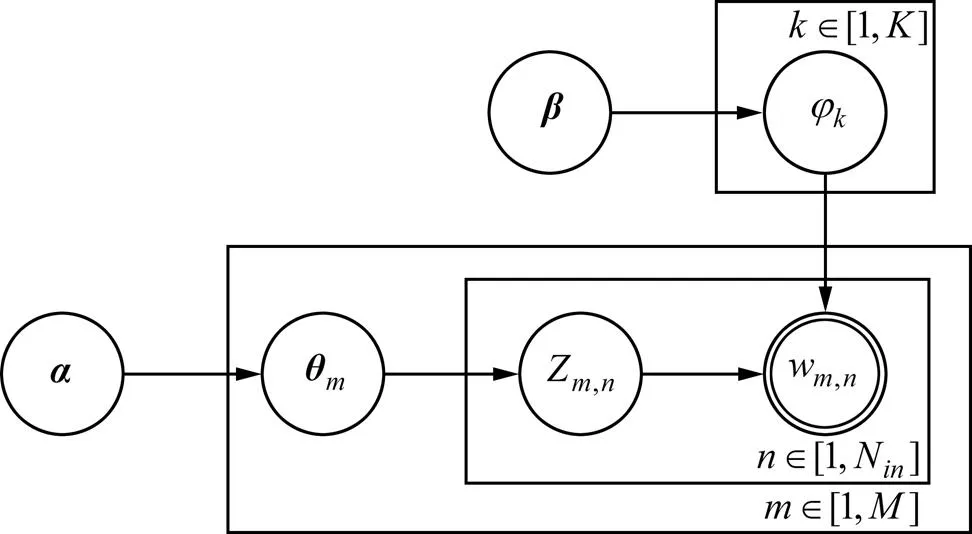
图1 LDA模型图
图1所示为LDA模型图。图1中,单圆环表示隐含变量,双圆环表示可观察值,矩形表示重复过程;大矩形表示从Dirichlet分布中为文档集中的每个文档反复抽取主题分布;小矩形表示从主题分布中反复抽样产生文档的词{1,2,…,w};为主题个数;为文档总数;N为第个文档的单词总数;Z,n为第个文档中第个词的主题;w,n为个文档中的第个词;和为它们的先验参数;隐含变量表示第个文档下的Topic分布;表示第个主题下词的分布。对于文档中每个词,可以通过公式(3)为其抽样1个主题Z。同时,通过公式(4)选择该词W。


将扩充后的Mashup描述文档作为LDA模型的输入,采用吉布斯抽样(Gibbs Sampling)方法,和分别可被推断出来,从而得到每个描述文档的文档主题矩阵和词主题矩阵。如图2所示。

图2 LDA词主题与文档主题矩阵
2 方法框架与过程
本文提出的方法总体框架如图3所示。首先,对收集到的Web服务数据集进行预处理。之后,使用Word2Vec工具对Wikipedia语料库进行训练,生成词向量模型。在词向量模型中寻找与Web服务的描述文档相似的词进行扩充,得到不同扩充程度的描述文档,使原始文本有足够的词频共现,使主题模型更加有效地估计服务的隐含主题。然后,使用文本聚类领域常用的工具LDA模型对扩充后的描述文档进行主题建模。接着,对LDA生成的文档主题分布矩阵使用K-means聚类方法实现服务聚类。最后,采用准确率、召回率以及对实验结果进行评价。
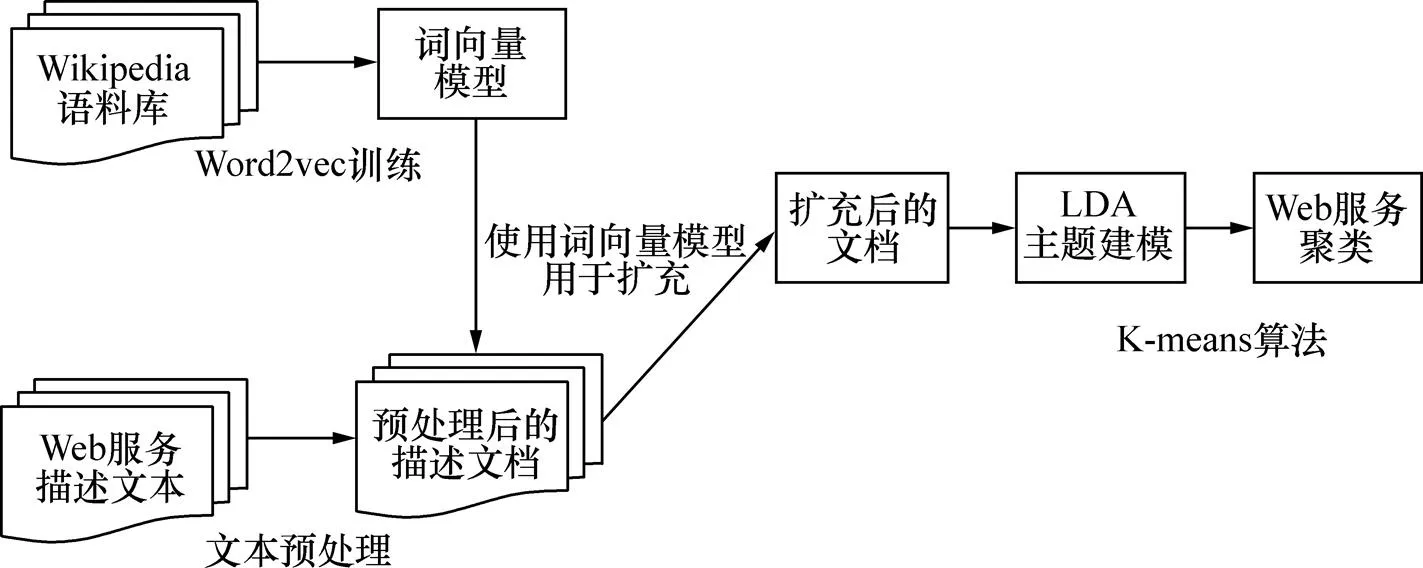
图3 方法总体框架
2.1 方法步骤
2.1.1 Wikipedia数据集以及词向量训练过程
Wikipedia是公认的互联网上最全面、最权威的网络百科全书,有丰富的语料库。本文采用2017年4月的英文维基百科语料库,下载地址为:https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2,约为11 GB。其中每个文件大约为1 MB,包含了多个英文文档。
本文使用python中的gensim模块对Wikipedia语料库进行训练,生成了Wikipedia语料库的词向量模型,具体参数设置如表1所示。

表1 Word2Vec参数设置
2.1.2 Web服务数据集及预处理
本实验的数据集来自于ProgrammableWeb网站,它是一个API资源发布和检索的权威平台,是世界上API的新闻和信息的主要来源。截至2017−05,该网站上中的Mashup数量已经超过6 300个,Web API的数量突破17 000个。
本文使用从ProgrammableWeb爬取的6 347个Mashup服务,包括服务名称、描述文本、所使用的Web API以及Tag等信息。在实验中挑选了数量最多的前五类Mashup,它们的分布情况如表2所示。
为了提高文本聚类的精确度,首先对这些Mashup的描述文档进行预处理。过程如下。
1) 文本令牌化(tokenize)。将每个单词按照空格分开,且将单词和标点符号也分开,使得文本中的单词、字符变成单独的单元。

表2 Top5类的Mashup服务分布图
2) 过滤停用词(stop words)。去除英文中一些无意义的词以及标点符号,如:“a”,“and”,“or”,“to”和“@”等。
3) 词干化处理(stemming)。在英文文本中,同一个单词会因为人称、时态的不同而有不同的表现形式,如“connection”,“connected”和“connecting”,它们实际上都是同一个单词“connect”。若将这些单词看作是不同的单词,那么之后的实验结果的准确度捡回降低。故需要进行词干化处理。
以上处理步骤均采用python中的自然语言处理工具包[15]NLTK(Natural Language Toolkit)进行处理。在完成以上3个步骤后,便获得了处理好的Web服务描述文档text。
2.1.3 词向量扩充处理
使用Word2vec工具对Wikipedia语料库进行训练,得到Wikipedia语料库的词向量模型。接着利用训练好的词向量模型来进行Web服务描述文档的扩充。具体方法为:在词向量空间中寻找与原始Web服务描述文档中的词最相近的前个词进行扩充,得到不同扩充程度的Web服务描述文档[16]。例如:原始单词Earth与Google,经过扩充之后形成的前10个扩充词分别为{planet,martian,mars,venusian,planets,spaceship,universe planetary,moon,deimos}和{gmail,dropbox,evernote,app,adsense,yahoo,microsoft,flickr,hotmail}。

2.1.4 LDA主题建模

2.1.5 Web服务功能聚类
K-means聚类算法是Web服务聚类中使用最为广泛的算法之一。该算法的步骤如下[17]。
1) 在个样本中,任选个样本作为初始聚类中心=(1,2,…,z)。
2) 对每个样本x找到离它最近的聚类中心z,并将其分配到z所标明的类c中。
3) 采取平均的方法计算重新分类后的各类的聚类中心。
4) 计算

5) 若值收敛,则返回聚类结果,并终止本算法,否则转至步骤 2)。
其中,步骤4)在计算每个Mashup服务到聚类中心的距离时,采用的是余弦相似度。假设某个Mashup服务m和聚类中心z它们的主题向量是(P1,P2,…,P)与(P1,P2,…,P),那么m与z之间的余弦距离为

将文本主题矩阵作为K-means的输入,最小化所有Mashup与其所关联的聚类中心点之间的距离之和,将得到最终的聚类结果。图4所示为Web服务聚类结果中的2个簇的示例图。每一个簇类的主题为该簇类出现次数最多的1个主题。
图4 Web服务聚类示例
Fig. 4 Examples of Web service clustering
3 实验评估
3.1 评价标准
为了评价服务聚类的性能,采用准确率、召回率以及综合评价指标进行评价[18]。其中,准确率表示所有被划分到同一簇的服务中应被划分到该簇的概率,召回率表示所有被聚类到同一簇中的服务占所有应被聚类到该簇的比例,为准确率和召回率的调和平均值,具体计算公式如下:




3.2 对比方法
选取以下方法与本文所提出的方法进行比较。
1) TFIDF-K[2]。该方法采用 K-mean 算法对服务进行聚类,基于词频和逆文档频率进行服务之间相似度的计算。
2) LDA。该方法基于 LDA 主题模型进行划分,每个服务属于主题概率最大的类别。具有相同主题的Web服务被划分为1个类。
3) WT-LDA[7]。该方法在传统的LDA主题建模过程中添加了Web服务标签信息,每个服务属于主题概率最大的类别,具有相同主题的 Web服务被聚为1个类。
4) LDA-K[2]:该方法针对原始的、未扩充的服务文本进行聚类。首先,基于LDA模型的主题分布矩阵进行Web服务之间的相似度计算;然后,使用K-means算法对Mashup服务进行聚类。
5) ELDA-K-i。该方法即为本文提出的方法。首先对Mashup服务描述文本进行扩充,使短文本扩充成为长文本,再对其进行主题建模,得到文档−主题矩阵。再依据主题分布进行相似度的计算,并使用K-Means聚类算法进行聚类。其中,表示扩充的词语数量。
6) ELDA-HC。该方法采用相同的文本扩充方法、不同的聚类算法实现服务聚类。首先,对Mashup服务描述文本进行扩充,使短文本扩充成为长文本。使用层次聚类算法对生成的主题分布矩阵进行聚类。
4 实验结果
4.1 不同扩充情况对服务聚类的影响
本文设计了一组实验,用于考察不同扩充情况的Web服务描述文本对实验效果的影响。将LDA的预先设定的主题数设置为20,40,60,80以及100。同时,LDA模型中的先验参数和根据主题数来设定,=50/,=0.1。对LDA生成的文档主题向量使用K-means算法进行聚类。实验结果如下:4种不同扩充情况为分别为无扩充、扩充词数为3、扩充词数为5、扩充词数为10。从图5~7中可以看出:不扩充时的聚类效果最差,这是因为原始文本较短,包含的信息较少;在扩充词数为3时,其准确率、召回率以及这3个指标均要比其余扩充情况的高,但随着扩充词数的继续增加,聚类的效果反而降低。这是因为扩充词并不单单表示原单词的含义,还会包含其他语义信息。过多的扩充词会使得主题模型无法准确地推断出隐含主题,使得扩充后的Mashup描述文档的语义变得模糊,导致LDA模型建模效果降低。
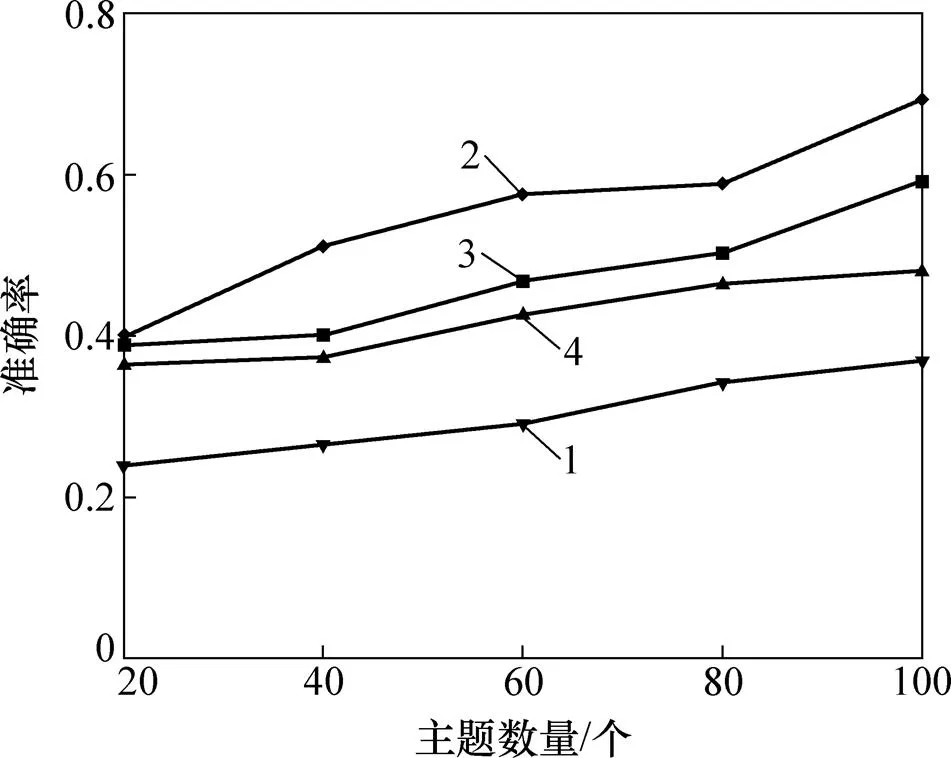
1—LDA-K;2—ELDA-K-3;3—ELDA-K-5;4—ELDA-K-10。

1—LDA-K;2—ELDA-K-3;3—ELDA-K-5;4—ELDA-K-10。
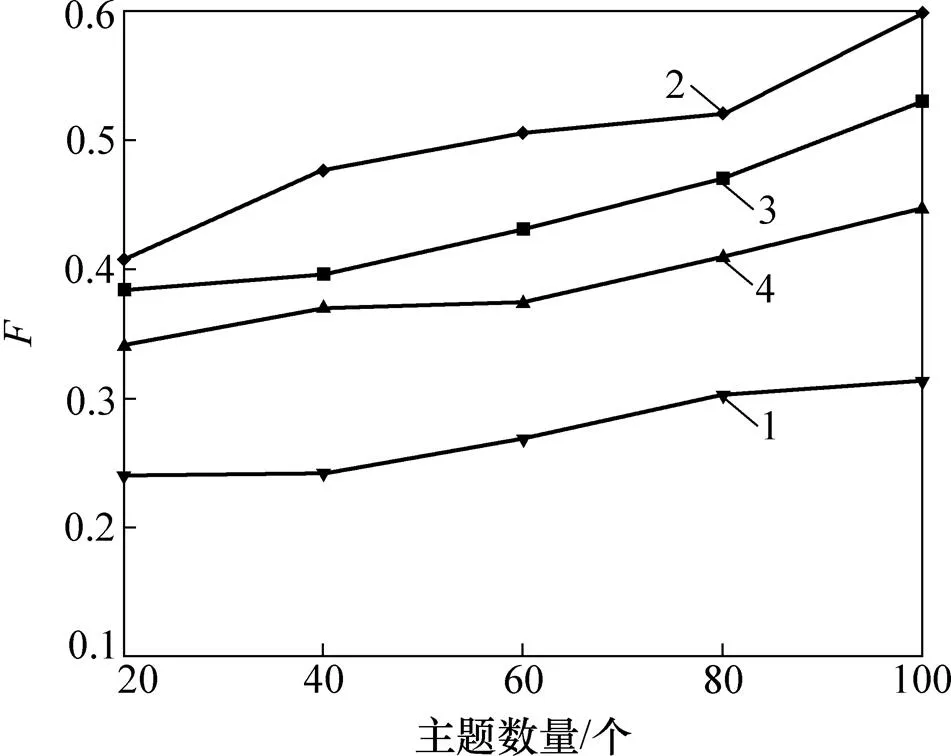
1—LDA-K;2—ELDA-K-3;3—ELDA-K-5;4—ELDA-K-10。
4.2 不同聚类方法的比较
通过实验可知:当扩充词数为3时,本文方法具有最好的效果。因此,选择ELDA-K-3方法与之前提到的其他方法进行对比,结果如表3所示。本文提出的方法所得准确率、召回率以及都最高。
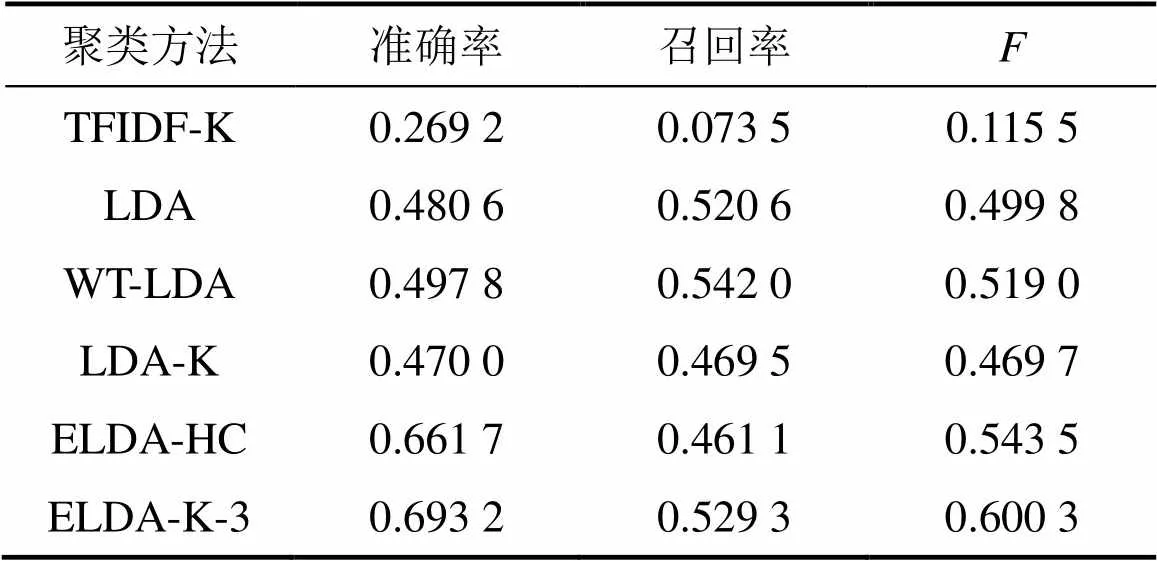
表3 不同聚类方法的实验结果比较
从表3可见:本文提出的方法比其他方法有着明显的优势,与TFIDF-K,LDA,WT-LDA和LDA-K相比,本文方法所得分别提高419.74%,20.11%,15.60%和27.80%。这是因为扩充后的描述文档包含更多的关于Web服务的有效信息,而这些信息有助于Web服务功能信息特征的提取,并且在同样扩充情况下,使用K-means聚类方法获得的实验结果要优于层次聚类方法所得结果。这是因为层次聚类在分类过程中,当1个点被分类之后就无法进行修正,聚类质量会受到影响。而K-means聚类方法在聚类过程中仍可以进行聚类结果的修正。
5 结论
1) Web服务的数据规模越来越大,将服务进行聚类是一种有效提高服务发现的手段。基于服务描述文本通常比较短,缺乏足够的有效信息,本文提出了一种基于Word2Vec和LDA主题模型的Web服务聚类方法。该方法将Web服务描述文档进行扩充,将服务描述短文本扩充成长文本,再对扩充后的描述文档进行主题建模,最后计算各个Web服务的主题分布向量之间的距离,完成聚类。
2) 在真实的数据集上进行实验,并用3种评价指标验证本文方法的有效性,结果证明利用扩充后的Web服务的描述文档进行聚类能够有效提高Web服务聚类的效果。
[1] IBRAHIM N M, HASSAN M F B. A survey on different interoperability frameworks of SOA systems towards seamless interoperability[C]//Information Technology. Washington D C, USA: IEEE, 2010: 1119−1123.
[2] CAO B, LIU X, LI B, et al. Mashup service clustering based on an integration of service content and network via exploiting a two-level topic model[C]//IEEE International Conference on Web Services San Francisco, USA. IEEE, 2016: 212−219.
[3] 黄兴, 刘小青, 曹步清, 等. 融合K-Means与Agnes的Mashup服务聚类方法[J]. 小型微型计算机系统, 2015, 36(11): 2492−2497. HUANG Xing, LIU Xiaoqing, CAO Buqing, et al. MSCA:Mashup service clustering approach integrating K-Means and agnes algorithms[J]. Journal of Chinese Computer Systems, 2015, 36(11): 2492−2497.
[4] ELGAZZAR K, HASSAN A E, MARTIN P. Clustering WSDL Documents to Bootstrap the Discovery of Web Services[C]// ICWS2010. Florida, USA: IEEE Computer Society, 2010: 147−154.
[5] YU Q, REGE M. On Service community learning: A Co-clustering approach[C]//IEEE International Conference on Web Services. Washington D C, USA: IEEE Computer Society, 2010: 283−290.
[6] HASAN M H, JAAFAR J, HASSAN M F. Fuzzy-based clustering of Web services’ quality of service: A review[J]. Journal of Communications, 2014, 9(1): 81−90.
[7] CHEN L, WANG Y, YU Q. WT-LDA: User tagging augmented LDA for Web service clustering[C]//International Conference on Service-Oriented Computing. Berlin, Heidelberg: Springer, 2013: 162−176.
[8] CHEN L, HU L, ZHENG Z. WTCluster: Utilizing tags for Web services clustering[M]. Service-Oriented Computing. Berlin Heidelberg: Springer 2011: 204−218.
[9] 黄媛, 李兵, 何鹏, 等. 基于标签推荐的Mashup服务聚类[J]. 计算机科学, 2013, 40(2): 167−171.HUANG Yuan, LI Bing, HE Peng, et al. Mashup services clustering based on tag recommendation[J]. Computer Science, 2013, 40(2): 167−171.
[10] 李征, 王健, 张能, 等. 一种面向主题的领域服务聚类方法. 计算机研究与发展, 2014, 51(2): 408−419. LI Zheng, WANG Jian, ZHANG Neng, et al. A topic-oriented clustering approach for domain services[J]. Journal of Computer Research and Development, 2014, 51(2): 408−419.
[11] SHI Min, LIU Jianxun, ZHOU Dong, et al. WE-LDA: A word embeddings augmented LDA model for Web services clustering[C]//IEEE International Conference on Web Services. Honolulu, USA: IEEE Computer Society, 2017: 9−16.
[12] 褚征, 于炯, 王佳玉, 等. 基于LDA主题模型的移动应用相似度构建方法[J]. 计算机应用, 2017, 37(4): 1075−1082. CHU Zheng, YU Jong, WANG Jayu, et al. Construction method of mobile application similarity matrix based on latent Dirichlet allocation topic model[J]. Journal of Computer Applications, 2017, 37(4): 1075−1082.
[13] 黄仁, 张卫. 基于word2vec的互联网商品评论情感倾向研究[J]. 计算机科学, 2016, 43(S1): 387−389. HUANG Ren, ZHANG Wei. Study on sentiment analyzing of internet commodities review based on Word2vec[J]. Computer Science, 2016, 43(S1): 387−389.
[14] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(3): 993−1022.
[15] BIRD W W S, KLEIN E. Natural Language Processing with Python, Analyzing Text with the Natural Language Toolkit[J]. Language Resources & Evaluation, 2010, 44(4): 421−424.
[16] 魏强, 金芝, 许焱. 基于概率主题模型的物联网服务发现. 软件学报, 2014, 25(8): 1640−1658. WEI Qiang, JIN Zhi, XU Yan. Service discovery for internet of things based on probabilistic topic model[J]. Journal of Software, 2014, 25(8): 1640−1658
[17] 金建国. 聚类方法综述[J]. 计算机科学, 2014, 41(b11): 288−293. JIN Jianguo. Review of clustering method[J]. Computer Science, 2014, 41(b11): 288−293.
[18] CAO Buqing, LIU Xiaoqing, LIU Jianxun, et al. Domain-aware Mashup service clustering based on LDA topic model from multiple data sources[J]. Information & Software Technology, 2017, 90: 40−54.
Web services clustering based on Word2Vec and LDA topic model
XIAO Qiaoxiang1, CAO Buqing1, 2, ZHANG Xiangping1, LIU Jianxun1, LI Yanxinwen3
(1. Hunan University of Science & Technology, Xiangtan 411201, China; 2. State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China; 3. College of Navigation, Quanzhou Normal University, Quanzhou 362699, China)
Considering that the description text of Web service is short and lack of enough effective information, a Web service clustering method was proposed based on Word2Vec and LDA topic model in order to find the Web service that meets user’s needs efficiently. Firstly, Wikipedia corpus was used as an extension source, and Word2Vec was used to extend the content of Web service description document, and then the expanded description document was modeled using the topic model. The short text topic modeling was transformed into a long text topic modeling, which achieved the topic of service content expression more accurately. Finally the similar service was found based on the topic distribution matrix of the document and the clustering was completed. Real data from ProgrammableWeb was used to carry out experiments. The results show that F obtained by the method increases by 419.74%, 20.11%, 15.60%, 27.80%, respectively, compared with those using TFIDF-K, LDA, WT-LDA and LDA-K. The use of extended Web service description documents clustering method can effectively improve the effectiveness of Web service clustering.
Web services; Word2Vec; LDA topic model; K-means algorithm; Web service clustering
10.11817/j.issn.1672−7207.2018.12.011
TP301
A
1672−7207(2018)12−2979−07
2018−01−12;
2018−03−21
国家自然科学基金资助项目(61873316, 61872139);湖南省自然科学基金资助项目(2017JJ2098);网络与交换技术国家重点实验室(北京邮电大学)开放课题 (SKLNST-2016-2-26)(Projects(61873316, 61872139) supported by the National Natural Science Foundation of China; Project(2017JJ2098) supported by the Natural Science Foundation of Hunan Province; Project(SKLNST-2016-2-26) supported by the Open Foundation of State Key Laboratory of Networking and Switching Technology (Beijing University of Posts and Telecommunications)
曹步清,博士,副教授,从事服务计算与云计算等方面的研究;E-mail:buqingcao@gmail.com
(编辑 陈灿华)
