基于移动数据的用户出行方式识别研究
2018-02-28张鹤鹏李晓璐朱广宇
张鹤鹏,黄 达,杜 辰,李晓璐,2,朱广宇,2
(1.北京交通大学 交通运输学院,北京 100044;2.北京交通大学 综合交通运输大数据应用技术交通运输行业重点实验室,北京 100044)
0 引言
识别用户出行方式、获知城市居民出行行为的属性特征并借此获知城市居民的出行结构,是城市交通管理部门提供交通服务、实施交通组织管理的前提[1-2]。随着移动互联网技术的高速发展,通过智能手机等设备采集终端用户的移动数据并对其进行分析,可以获得交通参与者出行相关信息。而将交通参与者的这些信息进行处理后,再采用一定的算法就可以识别用户的出行方式,获得出行偏好等信息。交通出行方式的识别是对用户出行轨迹中每一对相邻出行节点中出行过程特征的识别。若相邻出行过程中运动轨迹特征大致相同,则认为相邻两阶段出行方式相同;若出现较大差异,则认为被调查者出现停驻或采用了其他的交通方式。目前很多学者针对出行方式识别的问题进行了研究,主要是基于以上提到的思路,提取出行者每一个全球定位系统(Global Positioning System,GPS)轨迹点信息,进而识别出行方式。Chang等[3]、Gong等[4]、Lu等[5]都是基于GPS采集到的数据,分别采用基于规则、基于模糊逻辑的算法将数据结合ArcGIS软件,对被调查者的出行方式进行识别。
智能手机可对用户每一时刻的出行信息进行记录并形成出行轨迹。识别用户的出行方式前需要运用一定的方法提取出行轨迹中的信息,从而获取用户的出行链以更加准确地体现出出行轨迹与出行方式选择的联系。在得到用户出行链的基础上,提取速度、加速度、方向变化率、出行起止时刻等特征,接着采用一定的识别方法,如:基于规则的方法、构建概率矩阵的方法、机器学习的方法对用户的出行方式进行判别。基于规则的方法是通过逻辑特征设定规则对出行方式进行判断,若对象满足某种出行方式的判断条件,就将其归类到某种方式。例如 Stopher等[6]、Bohte等[7]、Chen 等[8]都通过对平均速度、最大速度、出行时长设定不同的阈值来区分步行、公交、小汽车等交通方式。通过已有文献可以看出,基于规则的方法主观性强,规则和阈值的设定主要依据研究者的专业知识和经验,其精度和扩展性受到限制。而近年来运用机器学习的算法对用户出行方式的识别逐渐成为研究的重点,并且其精度和可扩展性都比以往的方法有了很大的提升。闫彭[9]、张治华[10]、汪磊等[11]对GPS采集到的定位数据分别使用BP(Back Propagation)神经网络、多层感知器神经网络、支持向量机(Support Vector Machine,SVM)模型进行交通出行方式的识别,且都到达了良好的识别精度。
纵观国内外文献,通过GPS定位系统获取位置数据是获取用户出行链的主要途径,而利用移动终端定位数据的相关研究较少。因此,本文主要对从移动终端获取到的用户位置数据进行分析,提出了一种新的用户出行链获取方法,并通过案例分析证明了该方法的有效性。研究文献[11]~[14]发现,可以采用多种识别方法对用户的出行方式进行判别,考虑到决策树算法具有较强的学习能力,且在交通领域已有较多的应用,比如道路交通事故预测、短时交通流预测、城市道路拥挤预测等。因此,本文采用机器学习算法中的C4.5决策树算法对移动用户的出行行为进行分析,包括用户的始发地、速度、交通方式的选择等。
1 出行方式特征分析
在对用户出行方式判别的过程中,识别出各类交通方式的数据特征,进而确定特征变量和判别阈值是其中较为关键的一部分。根据文献[15],最常用到统计特征为速度、加速度、出行距离、出行时长、停止率等统计量,因此需要对这些统计量进行特征分析,确定合适的分裂属性,进而构建决策树。
(1)速度
速度是区分交通方式最重要的特征变量,一般而言机动车速度大于非机动车和行人。现有文献中应用于出行方式识别的速度统计值一般有最大速度、平均速度、百分位速度等。由于定位点存在随机误差,最大速度难以保证准确性,所以本文采用第75个百分位速度(表示此车辆车速累计出现频率达75%的行驶速度)代替。
速度能够较好地区分各类交通方式,但同时也是最易误导识别的变量之一。虽然不同性能车辆在设计速度上具有很大差异,但是城市阻滞的行车环境其实较难将不同交通方式的差异显现出来。因此还需要结合其他的特征变量进行分析。
(2)速度的百分位数
文献[14]、[15]中基于速度的75分位数比较步行、自行车、公交车、小汽车的速度变化趋势,得到的结果如图1所示。
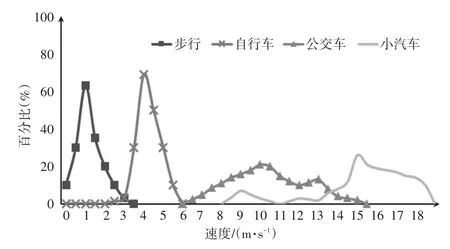
图1 速度的75分位数分布频率曲线图
由图1中各交通方式的分布曲线,文献指出以3m/s设定阈值,可以区分步行与自行车两种出行方式,而机动车出行速度与非机动车出行速度差别较大,且非机动车速度一般低于16m/s,故本文选取16m/s作为速度阈值,区分机动车与非机动车出行。
(3)轨迹点数量占比
为了进一步区分公交车出行和小汽车出行两种方式,首先提取瞬时速度大于15m/s的轨迹点作为

式(1)中:Ni是速度大于15 m/s的轨迹点个数(个);N是总的轨迹点个数(个)。
根据上述特征变量计算公式,对公交车、小汽车轨迹点数量占比进行分析,得到的结果见图2和图3。研究对象,剔除步行、自行车的干扰。引入轨迹点数量占比作为特征变量,其计算公式如下:
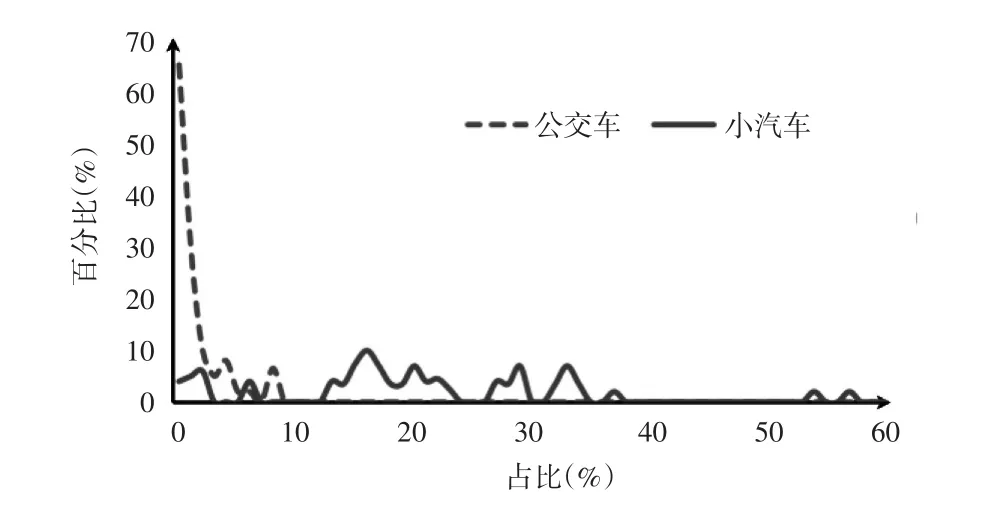
图2 速度大于15m/s的轨迹点数量占比分布曲线图
由图2和图3可以发现,小汽车与公交车的区分阈值为12%的轨迹点数量占比。当阈值大于12%是为小汽车,反之则为公交车。
(4)出行距离
依据城市居民出行画像描述[16],居民出行因距离不同,出行方式的偏好也不同。不同出行方式的出行距离分布见图4,步行的出行距离为1~2km;自行车的出行距离为6km以内;出行距离在20km以上的为小汽车。
(5)停止率
在城市居民公交车与小汽车出行画像的描述中[17],其停车率具有明显的不同。由于公交车的营运特征,在道路畅通的情况下,其停车率会明显高于小汽车。提取轨迹点中停车的轨迹点,作为停车点集合P:
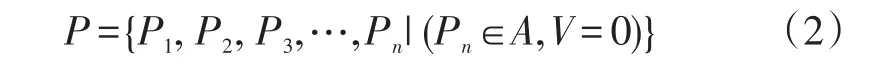
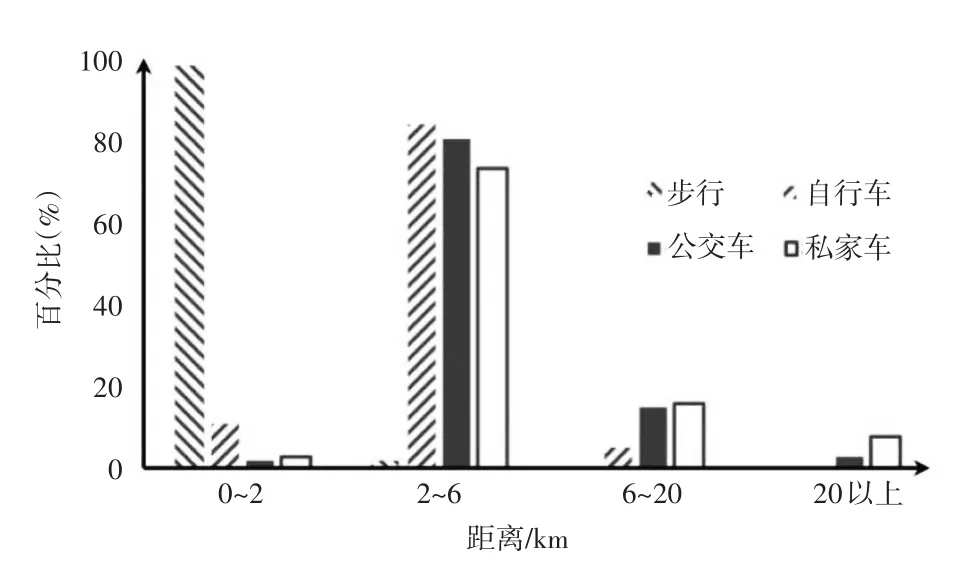
图4 不同出行方式的出行距离分布图
并定义停止率Stoprate为单位距离中停止点的个数:

式(2)~式(3)中:A为轨迹点的集合;V为轨迹点的速度(m/s);为一次出行中停止段的个数(个);|ps|是速度为0的停止段的集合;dis是一段出行中出行距离(km)。
根据以上公式,计算公交车和小汽车的停止率的区域分布情况,如图5所示。
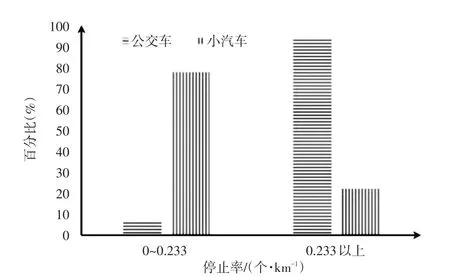
图5 停止率柱状分布图
2 数据类型及处理
移动数据与以往的GPS、传感器等方式采集到的出行数据相比存在很大差异,具体表现为蜂窝分布、数据采集频率不固定、乒乓切换等特征。这些特征的存在导致采集的数据不能直接被使用,需要对其进行预处理。先将每一段数据按照采集时间排序,剔除移动终端位置信息错误、时间信息错误和基站位置错误的数据,提高数据的质量,为后续的地图匹配提供可靠且有效的数据。
2.1 移动终端数据类型及预处理
移动终端利用扇形定位所采集到的定位数据主要由确定终端唯一标识的编号、经度、纬度和定位时间4类条目组成。本文主要对两种异常数据进行处理,包括经纬度越界数据和重复冗余数据。首先,通过在地图上标注区域边界,得到所在区域的经纬度范围,将经纬度坐标在此范围之外的移动定位数据点全部剔除。然后,剔除重复数据。接着,对处理完成的数据进行坐标变换以便进行地图匹配,需要调用坐标转换应用程序编程接口(Application Programming Interface,API)将原始移动定位坐标转换成电子地图中的坐标。
2.2 地图匹配
为了减少数据偏差,保证移动终端用户出行轨迹的可靠性和准确性,需要把预处理过的数据与数据地图进行匹配和对比。地图匹配技术建立在模式识别理论之上,其目标是完成定位点和道路网络之间的精准匹配。常用的地图匹配的方法有:定位点与道路匹配,轨迹线与路网匹配。
本文选取定位点与道路匹配的方法。具体如下:提取路网节点、道路线路等地理信息系统(Geographic Information System,GIS)路网数据,通过垂线投影法(原理见图6),寻找定位点与其距离最近的路段,以定位点向路段做垂线,垂足点为匹配点,与定位点距离最小的路段即为匹配路段。

图6 垂线投影法原理图
在图6中,I表示定位点,R1与R2表示定位点附近的道路,计算车辆与附近所有道路的距离以及与各个道路方向的夹角[16]。根据式(4)计算车辆位置点与附近所有道路的权值θi:

式(4)中:qi为定位点与道路的距离(m);wi为方向的夹角(rad);λq为距离的权重;λw为方向的权重。在R1与R2中选取权重较小的道路为匹配道路,该道路的垂足点为匹配点。
3 出行方式识别模型的建立
从移动终端用户轨迹中判别交通方式是一个典型的模式识别问题,需根据轨迹对象的统计特征寻找合适的统计量,并使用机器学习算法建立判别规则。本文的交通方式判别工作包括出行段分割、统计量选取、机器学习3个步骤。首先根据出行轨迹信息识别停驻,并根据停驻将出行轨迹分割成多个出行;然后根据换乘点将出行分割成只含一种交通方式的出行段;最后基于出行段运用机器学习算法识别出行方式。
3.1 个人出行链的获取
出行链是指由一系列相邻节点间连续的出行而形成的链式结构,往往以空间上有向位移的方式体现。获取用户的出行链对出行者出行方式的识别有着至关重要的作用。但在获取用户出行轨迹后,考虑到存在的误差和基站分布的影响还需对异常漂移的轨迹点进行修正,进而提取用户出行链。
3.1.1 异常漂移修正
本文利用设定速度阈值的方式对出行轨迹链中出现的异常飘移的轨迹点进行修正。具体筛选与检验流程是,首先计算位置点间的时间:

其次,计算位置点间距离:
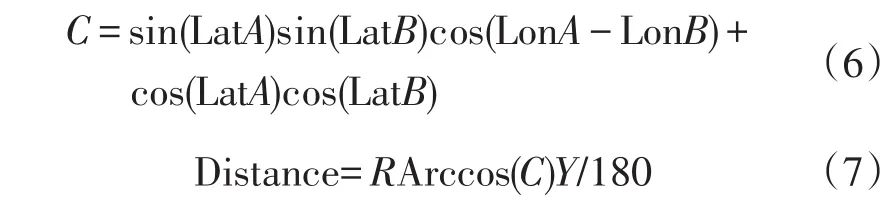
最后,计算位置点之间的移动速度,并判断位置点之间的移动速度是否符合阈值要求:

式(5)~式(8)中:ti为时间序列中第i个点的时刻信息;Δt为点间时间差(s);(LonA,LatA)为第i个位置点的经纬度坐标;(LonB,LatB)为第i+1个点的经纬度坐标;C为轨迹点与地球球心的夹角(rad);R为地球半径,取6 371km;Y为圆周率,取3.1416;vi为此终端用户出行时间序列上第i点的速度(m/s)。
3.1.2 用户出行链获取算法
根据以往经验设定距离阈值和时间阈值,将出行分割成多个出行片段,再应用算法逐段识别出行方式。个人出行链获取流程如图7所示。
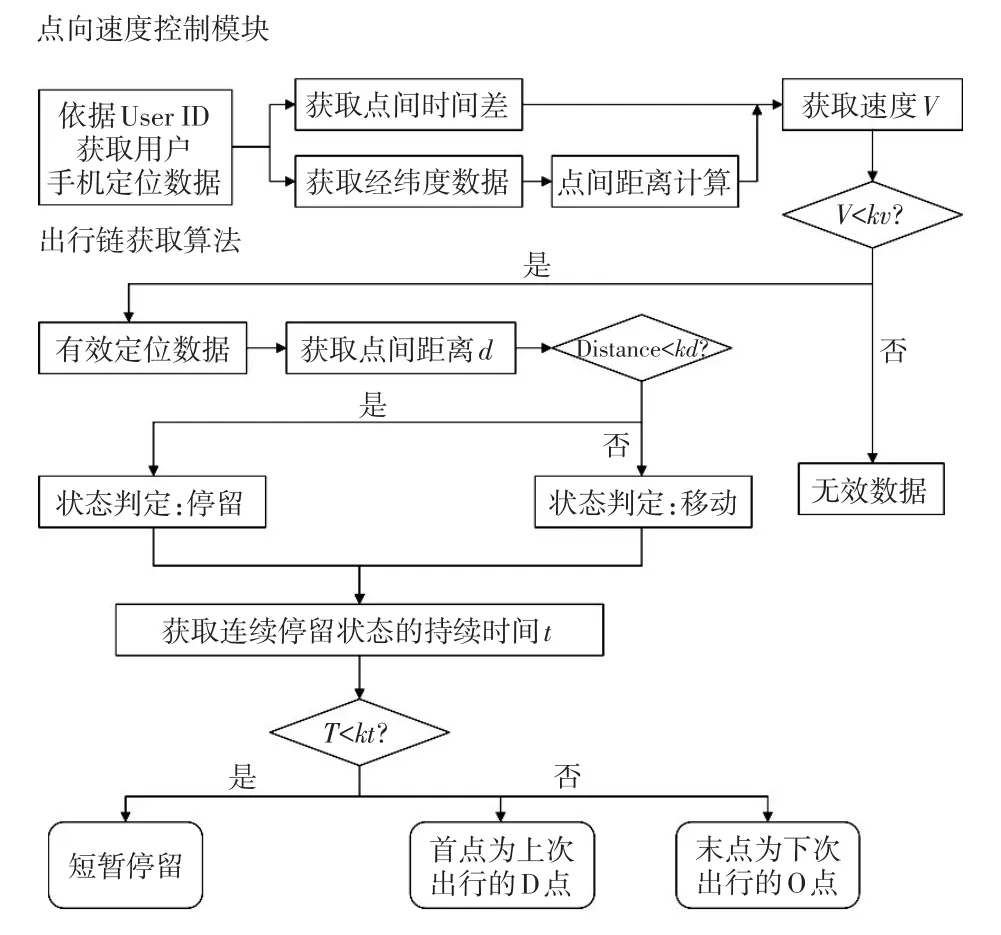
图7 基于手机定位信息的出行链获取流程图
图7中个人出行链获取流程包含点向速度控制模块和出行链获取算法两部分,而出行链获取算法作为出行链获取的主要部分,包含停靠点的判定和起讫(Origin-Destination,OD)点的判定两个环节。
首先是停靠点的判定。出行者在出行时总会呈现出静止(或者在一定阈值内移动)的状态,因此可以设定距离阈值Distance为判定条件。当相邻两点间的距离大于该阈值,说明出行者处于出行过程中;当相邻两点间距离小于该阈值时,则表示出行者处于活动或静止状态。
其次是OD点的判定,以距离阈值Distance和时间阈值T为判定条件。判定的逻辑流程为:OD点可分为两种状态,当两点之间的距离大于阈值Distance时,此时状态称为移动;当两点之间的距离小于阈值Distance时,此时状态称为驻留。在OD点状态判定的基础上,根据时间数据计算驻留状态下的持续时间t。如果驻留状态所持续时间t大于时间阈值T,则该段时间内的第一个坐标点判定为上一次出行行为的D点,最后一个坐标点判定为下次出行行为的O点。
3.2 基于决策树分类法的出行方式判别模型
决策树是一种机器学习的算法。本文选用决策树中的C4.5算法进行出行方式的识别,主要考虑到以下几个方面:①C4.5算法具有计算量小、准确率高、易于提取规则的特点;②用信息增益率而非信息增益值来选择分裂属性,对样本数据量的依赖程度变低;③由于本文中的数据为数值型的连续数据,而决策树C4.5算法中加入了连续属性的处理算法,对非离散型的数据也能处理。在分裂属性选择完毕后,可以通过计算不同的阈值确定划分方案,从而计算各方案中的信息增益率,在其中选择最大的信息增益率所对应的阈值用作最优分裂谓词。
第一步:分裂属性选取。首先计算总的数据集S关于属性A(速度的75分位数、最大速度、出行距离、速度大于16m/s的概率、失真率、停止率等)统计量的熵,再依次分别计算统计量的增益率,根据增益率从大到小依次建立子节点,从中选取信息增益率最大的属性作为该决策树的根节点。其中选取分裂属性的关键公式如下。
数据集S的熵I(S)衡量数据集的无序程度,其计算公式为:
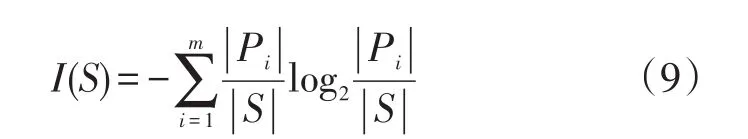
式(9)中:数据集S包含类别C1,C2,…,Cm;Pi为类别Ci在数据集S中出现的概率;|S|为S中的样本总和。
此外今年顺丰还打出“飞机+高铁”组合,累计增加近250吨运能。除高铁外,日前投入使用的波音747全货机也加入“双11”运力储备军,顺丰航空运力提升112.7吨。截至目前,顺丰航空机队已拥有48架全货机。
信息增益Gain(S,A)用来度量序数改进的结果,其计算公式为:

式(10)中:属性A具有6个不同的值(速度的75分位数、最大速度、出行距离、速度大于16m/s的概率、失真率、停止率等),可以用属性A将S划分为v个子集 {S1,S2,∙∙∙,Sv},|Sv|为子集v中各个类别样本数的和。
计算信息增益比例:
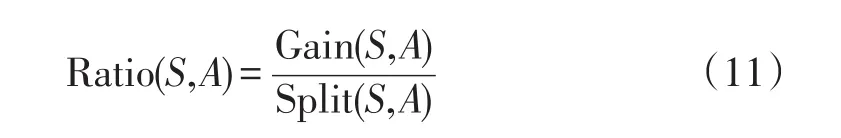
数据集S关于属性A的熵:
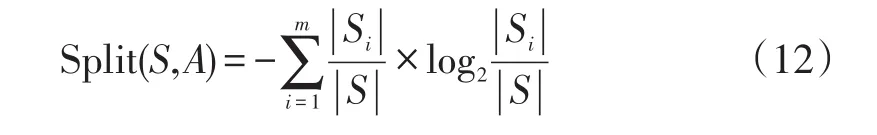
增益中包含把数据集划分为更小有序子集的属性A的偏差。要减少这个偏差,采用Split来计算每个变量相对于它的m个变量值的熵。
第二步:确定分裂谓词。C4.5算法中引入了信息增益率来确定分裂属性,针对某一个分裂属性,会有n个不同的数值,n个不同的数值对应了k种不同的分裂方案,计算每种方案下的信息增益比例,选取最大的信息增益比例所对应的数值作为最后的分裂谓词。
4 实例分析
本文以某地区移动终端位置数据分布图(见图8)为例,对用户出行方式进行研究,数据中包含了约7 000部移动终端的位置信息,共约30万条数据。
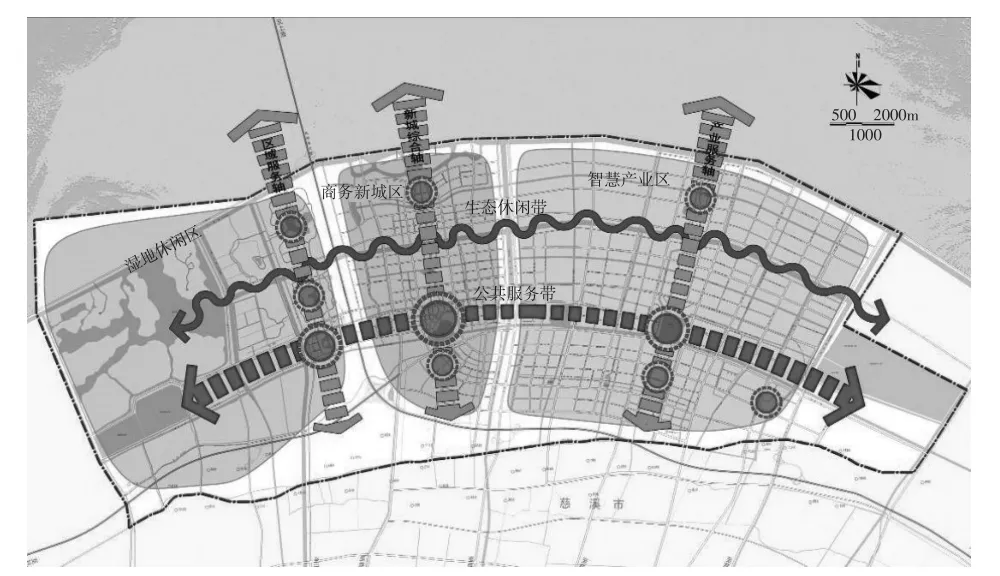
图8 研究区域空间结构图
4.1 移动终端位置数据的预处理
4.1.1 数据的标准化处理
本节运用2.1节中数据预处理的方法,为确定出行用户的定位点在数字地图中的具体位置,在剔除移动终端定位的异常数据后,将所得的出行数据映射到所研究的交通区域中,定位数据的属性示例如图9所示。其中,USERID为终端编号,是识别移动终端设备的唯一标识;TIME表示终端设备上传定位信息的时刻;LAT和LON分别为终端设备所在位置的纬、经度坐标;TYPE为触发定位信令的事件类型(001表示主叫,002表示被叫,003表示位置更新,004表示短信,005表示位置区切换)。

图9 移动终端定位数据的属性示例
4.1.2 地图匹配
同时考虑到定位数据存在一定误差以及为使计算简化,本文对道路宽度值的设定比实际情况有所扩展。以2016年2月10日的晚高峰时段为例,数字地图匹配前后对比见图10。
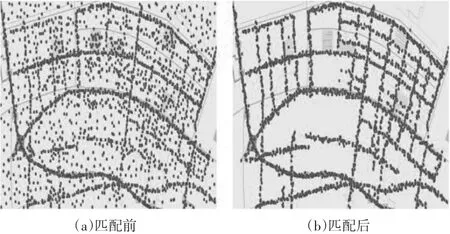
图10 地图匹配前后示意图
4.2 移动终端用户的出行链获取
根据3.1节中给出的获取用户出行轨迹的方法,筛检出移动终端用户的出行轨迹;具体过程为:获取用户USERID的所有记录,按照TIME字段排序后输出该用户出行轨迹;在输出用户轨迹链基础之上,利用电子地图的API将单用户的轨迹链在地图上表现出来,如图11所示。
4.3 出行方式判别结果分析
根据3.2节中给出的基于决策树法的出行方式判别模型,建立决策树如图12所示。
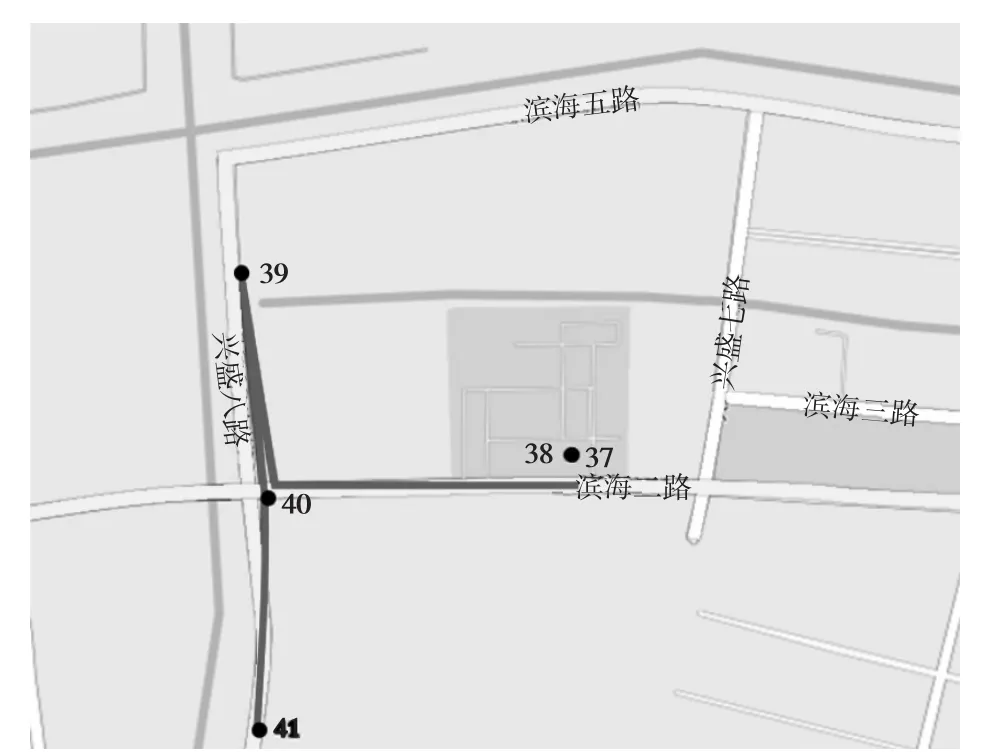
图11 单用户手机定位点记录图
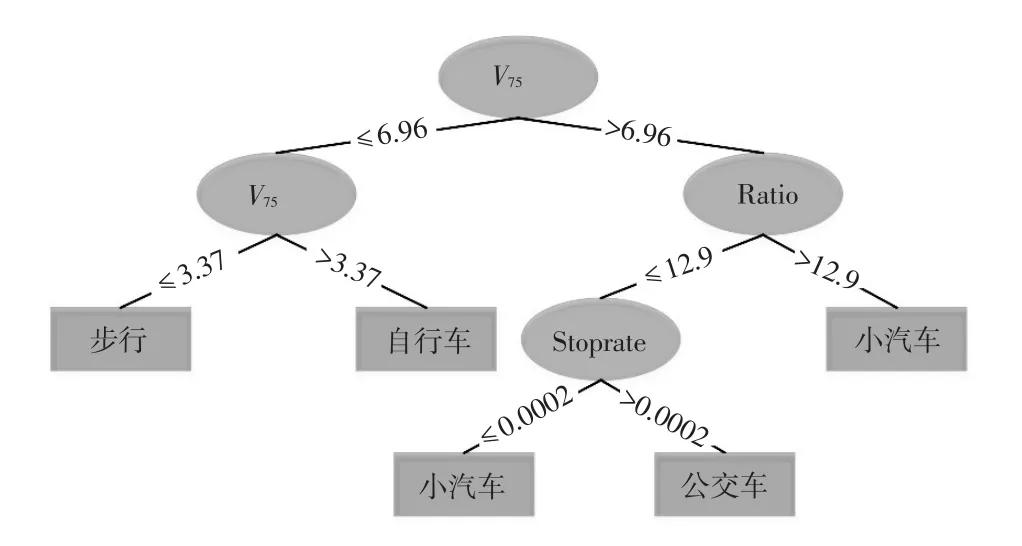
图12 C4.5决策树示意图
利用建好的决策树对用户的出行方式进行分析,得到的最终结果如表1所示。

表1 判别结果与实际对比
从表1可以看出,根据C4.5决策树算法得到的结果在判别步行或者自行车方式方面具有明显的优势,实际中出行方式是自行车的,会有可能被判别为步行和自行车,但可能性较低。在判别公交车和自行车方面此算法也有较好的表现,实际中出行方式是公交车的,会有可能被判别为小汽车;实际中出行方式是小汽车的,也有可能判别为小汽车,但均不会出现判别为自行车或者步行的判别结果。
5 结语
本文提出了一种基于移动定位数据的用户出行方式识别算法,通过将定位数据与现有路网进行匹配,识别出了个人出行链;对用户的出行选择行为进行了分析,确定了用户的起始位置、移动速度和选择的出行方式等。经实例验证,本文提出的识别步行、自行车、公交车、小汽车的方法是可行的,能够有效、准确地区分机动车和非机动车。该研究成果有利于更好地推广移动定位技术在交通领域的应用,对于提高居民交通出行调查效率、合理布局交通设施、优化交通系统具有重要意义。
在今后的研究中,以下两方面有待深入:(1)在提取用户出行链时,本文采用的地图匹配方法是定位点与道路匹配,这种方法的优势是方便、快捷、高效,但适用性和延展性不高,对于复杂路网的地图匹配需要寻找更合适的办法;(2)识别的出行方式类别需要进一步丰富,本文只是针对4种出行方式进行识别,但日常生活中人们的交通出行方式远多于4种。随着出行方式类别的多样化,识别难度将进一步增加,提升识别效率的方法有待探究。
