深度学习的模型搭建及过拟合问题的研究
2018-02-27陶砾杨朔杨威
陶砾+杨朔+杨威


摘 要: 深度学习是机器学习研究中的一个新的领域,它模仿人脑的机制来解释数据,例如图像,声音和文本。文章介绍了一种多层感知器结构的深度学习神经网络模型,并推导了其实现的算法。用数字识别实验验证了该模型及其算法的可靠性;验证了过拟合的发生与训练集的大小以及神经网络的复杂度之间的重要关系。过拟合问题的研究对降低误差有重要的意义。
关键词: 深度学习; 神经网络; 隐藏层; 过拟合
中图分类号:TP391.9 文献标志码:A 文章编号:1006-8228(2018)02-14-04
Abstract: Deep learning is a new field in machine learning research. It simulates the mechanism of human brain to interpret data, such as image, voice and text. In this paper, a deep learning neural network model of multilayer perceptron structure is introduced and its implementation algorithm is derived. The reliability of the model and its algorithm are also verified by some digital recognition experiments, and find that the size of the training set and the complexity of neural networks are highly related with the over-fitting. It is of great significance to study the problem of over-fitting to reduce the error.
Key words: deep learning; neural networks; hidden layer; over-fitting
0 引言
深度學习的概念源于人工神经网络的研究[3]。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层来表示属性类别或特征,以发现数据的分布式特征表示。在深度学习泛化(generalization)过程中,主要存在两个挑战:欠拟合和过拟合(overfitting)。欠拟合是指模型不能在训练集上获得足够小的误差,而过拟合是指训练误差和测试误差之间的差距太大。
1 模型设计
1.1 多层感知器结构[1]
本文采用多层感知器(MLP)作为训练模型,它是一种前馈人工神经网络模型。它包括至少一个隐藏层(除了一个输入层和一个输出层以外)本文采用的多层感知器模型中的信号流传播如下:
⑴ 输入:yi(n)为i神经元的输出,为下一个神经元j的输入。
⑵ 诱导局部区域:神经元j被它左边的yi(n)神经元产生的一组函数信号所馈,神经元j产生诱导局部区域。
⑶ 激活函数:神经元j输出处的函数信号yi(n)为,其中为j层神经元的激活函数。采用激活函数的一个好处是引入非线性因素,使神经网络变成非线性系统。本文采用Sigmoid函数作为激活函数,其定义为:,导数可用自身表示:
⑷ 误差:k为输出神经元,则误差ek(n)=dk(n)-yk(n),其中dk(n)为信号输出。
1.2 代价函数
代价函数是用来反映/度量预测结果yk(n)与实际结果dk(n)的偏差,本文采用最小平方(LMS)算法来构造代价函数:
1.3 随机梯度下降算法[4]
本文采用随机梯度下降算法(SGD)进行迭代,在此算法中,对的连续调整是在最速的方向进行的,即它是与梯度向量方向相反的。记为,因此,梯度下降算法一般表示为:。其中这里η是一个常数,称为学习率参数,是梯度向量值。
1.4 反向传播算法[5]
本文采用的反向传播算法以与1.3节类似的方式对突触权值应用一个修正值,它正比于偏导数,即:
1.4.1 神经元j是输出节点
图1为输出神经元j细节的信号流图。
根据微分的链式规则,可以将这个梯度表示为:
本文采用Sigmoid函数作为激活函数,即:
为了方便,我们定义:
1.4.2 神经元j是隐藏层节点
见图1,我们对式中通过链式规则后的偏导数可以看到:,神经元k是输出节点,故:
以上为倒数第一个隐藏层的传播公式,得出了δj的反向传播递推公式(k为j正向传播的下一个神经元),并用Sigmoid函数作为激活函数:
于是我们得出了递归的校正值的定义:
2 实验
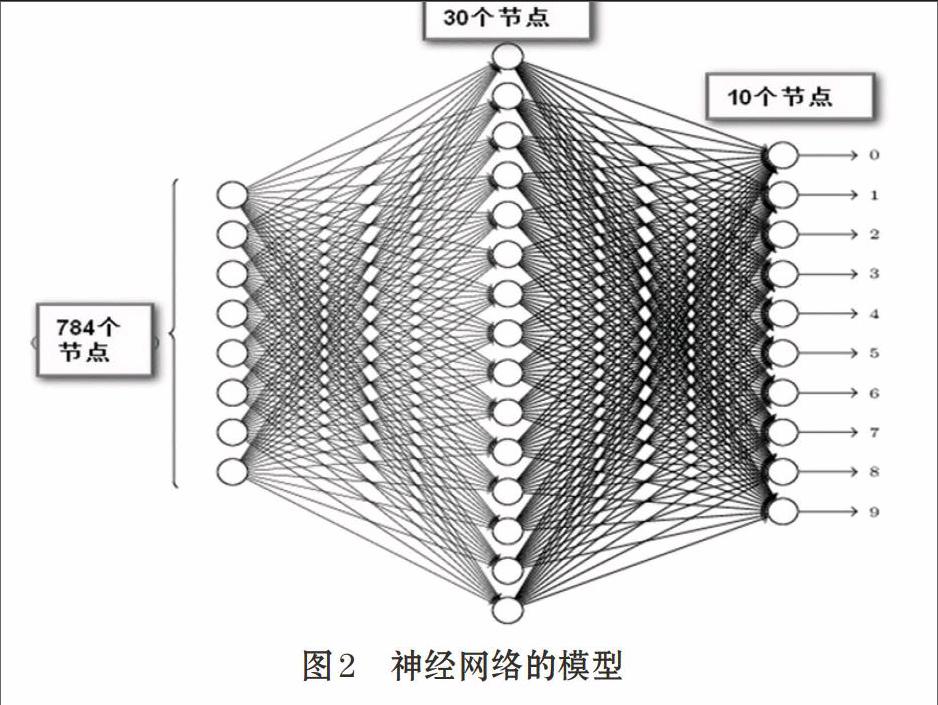
本模型以识别手写数字为例,测试深度学习模型。本文采用的数据集为著名的“MNIST数据集”。这个数据集有60000个训练样本和10000个测试用例。我们首先对该模型进行验证,然后通过调整训练集的大小和神经网络的结构来观察其对正确率的影响。
2.1 模型算法
学习阶段:本文采用mini-batch 梯度下降算法:假设总样本数为Sn,将Sn随机按每组N个样本分为(Sn/N)组。多层感知器的突触权值的调整在训练样本集合的所有N个样本例都出现后进行。(Sn/N)次完成整个样本集的训练,构成了一个训练的回合(epoch)。学习需经过多个回合,不断完善。具体步骤如下。endprint
