探究GPU对神经网络的加速作用
2018-02-15朱永贵华敏杰张佳佳
朱永贵,华敏杰,张佳佳
(中国传媒大学理学院,北京 100024)
1 引言
随着深度学习技术的发展,ANN(Artificial Neural Networks,人工神经网络)由于其强大的学习能力受到了研究人员的广泛关注,它是一种模仿动物大脑神经突触连接结构进行分布式并行信息处理的算法模型,在工程和学术界也常简称为神经网络[1]。ANN的网络结构通常包含输入层、隐含层和输出层,其中输入层和输出层只有一层,而隐含层可以有多层。每层都含有若干个神经元,相邻层之间的所有神经元之间都存在连接,每个连接上都有一个权重。神经网络的目标就是优化连接上的权值,使得从输入层到输出层的映射最能符合实际情况。
但是,由于ANN的各层之间均采用全连接结构,这使得其参数量十分巨大,尤其是在对图像的处理过程中,每个像素点都是一个特征值,全连接结构所产生的可学习参数量是难以接受的。并且,全连接结构的参数是非常冗余的,既加大了神经网络的计算量,减慢了训练时的收敛速度,又增加了过拟合现象出现的概率。
CNN(Convolutional Neural Networks,卷积神经网络)是一种特殊的神经网络,引入了卷积、池化、局部感受野以及权值共享等概念,使得CNN能够利用输入数据的二维结构[2]。因此,与传统的神经网络相比,CNN更适合用于处理图像问题。
2 GPU的发展现状与计算特性
GPU(Graphic Processing Unit,图形处理单元)这一概念最早由Nvidia在1999年发布GeForce 256图形处理芯片时提出。在此之前的显卡仅能用于简单的文字和图形输出,而GeForce 256采用了“T&L”硬件(硬件级的光影转换引擎)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理等核心技术,同时,OpenGL(Open Graphics Library,开源图形库)和DirectX 7均提供了硬件顶点变换的编程接口。从此以后,大量的坐标和光影转换工作从CPU解放出来,转而交由GPU完成。
虽然GPU的设计初衷是为了解决图形渲染效率的问题,但是随着技术的不断进步,微软发布了Shader Model(渲染单元模式),Shader由此诞生。Shader从本质上说是一段能针对3D图像进行操作并被GPU所执行的图形渲染指令集[3],通过这些指令集,开发人员能够在GPU上实现像素的可编程。正因如此,GPU的作用不再局限于图形领域,对于提升计算密集型程序的效率也同样适用,因此就出现了GPGPU(General Purpose GPU,通用计算图形处理单元)这一概念。
GPU之所以比CPU更适合可并行计算,是因为CPU与GPU的架构大不相同。人们最初在设计CPU时,希望其具备很强的通用性来处理各种不同的数据类型,同时需要进行逻辑判断,这又会引入大量的分支跳转和中断的处理,这使得CPU的结构非常复杂;而GPU面对的是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境[4],因此我们希望GPU拥有强大的计算能力而无需具备复杂的逻辑判断能力。如图1所示,其中绿色表示的是计算单元,橙色表示的是存储单元,黄色表示的是控制单元。从图中可以看出,GPU采用了数量众多的计算单元,而其控制逻辑却非常简单,并且省去了缓存区;而CPU不仅被缓存占据了大量的空间,而且还有复杂的控制逻辑,与GPU相比,CPU的计算单元却只占用其很小的一部分。因此,CPU适用于逻辑复杂且计算量不大的程序,而GPU则适用于逻辑简单、计算密集且易于并行的程序。
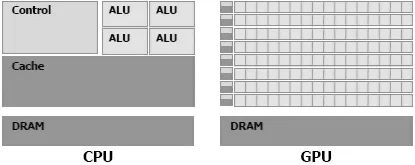
图1 CPU与GPU架构的比较
Nvidia一直处于GPU市场的领先地位,在GPGPU的概念出现后,Nvidia推出了CUDA库(Compute Unified Device Architecture,通用并行计算架构),从而使开发者能更加轻松地利用Nvidia的GPU优化自己的算法[5]。随着深度学习技术的快速发展,Nvidia在人工智能高性能计算方面远远地甩开了其竞争对手AMD,逐渐确立起了其在高性能通用计算型GPU市场中的霸主地位。起初,Nvidia主打的GPU系列是GeForce,主要用于家庭和企业的娱乐应用,面向游戏用户,此时GPU的作用也主要在于图形渲染和光照运算;而Quadro系列则主要应用于图形工作站,面向专业的图形绘制专家。随着人工智能研究的不断推进,计算力逐渐成为深度学习算法的训练瓶颈,CPU已经难以支撑起日渐庞大的模型和数据。于是,Nvidia推出了Tesla系列GPU,为企业级深度学习研究人员提供了强大的硬件支持。2017年5月11日,在加州圣何塞举办的2017年度GPU技术大会上,Nvidia发布了最新款Tesla系列GPU:Tesla V100。相比于其上一代产品Tesla P100,V100搭载了新款图形处理器GV100,采用Volta架构代替了P100的Pascal架构,CUDA核心数从3584个增加到5120个,并且增加了640个能提高深度计算性能的Tensor内核,双精度浮点运算速度从4.7 TFLOPs提升到7 TFLOPs,单精度浮点运算速度从9.3 TFLOPs提升到14 TFLOPs。
图2对比了Tesla P100与V100对于ResNet-50网络的训练与预测效率[6],从图中可知,在训练过程中,P100使用单精度进行运算,每秒能处理200多张图片,而V100使用Tensor内核进行运算,每秒能处理将近600张图片,V100的训练效率是P100的2.4倍;而在预测过程中,P100使用半精度进行运算,每秒能处理约1500张图片,V100仍使用Tensor内核进行运算,每秒能处理5000多张图片,V100的训练效率是P100的3.7倍。
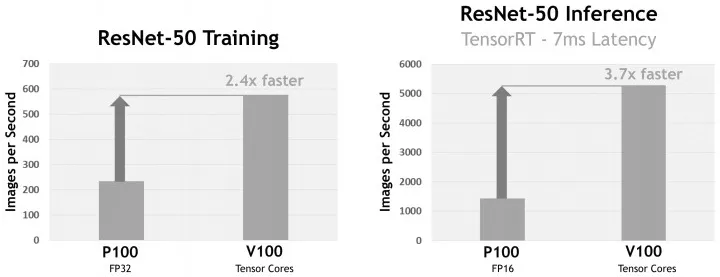
图2 Nvidia Tesla P100与V100性能对比
2017年12月8日,Nvidia在NIPS(Conference and Workshop on Neural Information Processing Systems,神经信息处理系统大会)会议上发布了其全新的Titan系列GPU:Nvidia Titan V。与Tesla系列略有不同,Titan系列更专注于神经信息处理方向,因此更专注于单精度浮点运算。Titan V的单精度浮点速度达到了15 TFLOPS,比Tesla V100的14 TFLOPS还要高。
除了PC端GPU以外,Nvidia也推出了供移动端使用的嵌入式GPU:Jetson模块。如Jetson TX2,兼具了高效能与低能耗,非常适合部署在机器人、无人机或智能家居等智能终端装置上,用于加速神经网络计算。虽然Jetson TX2的性能与PC端GPU相比逊色不少,仅配备了256个CUDA核心,但其计算神经网络的效率仍远远高于移动端CPU。
由此可见,以Nvidia为代表的GPU生产商已经发现深度学习算法在人工智能应用领域中的巨大潜力,而深度学习算法在面对海量的数据时,需要巨大的计算力的支持。随着专用于并行计算的GPU逐渐进入人工智能领域,深度学习在计算层面的瓶颈得到了极大地缓解,GPU也不再仅仅是图形学计算的工具。
3 神经网络的计算方法
3.1 人工神经网络的计算
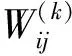
对于有多个隐含层的神经网络,计算方法可以类推,只需将上一层的输出值作为下一层的输入值,逐层传导即可。
3.2 卷积神经网络的计算
卷积层是CNN的核心构成单元,一个卷积层由若干卷积核组成,卷积核包含若干可学习的参数。每个卷积核只连接上一层中的某几个神经元,常见的卷积核尺寸为,意味着每个卷积核的感受野仅限于一个的局部区域。假设Wij表示卷积核中第i行,第j列的权值,表示该卷积核的偏置项权值,xi,j表示该卷积核当前对应的上一层感受野区域中第i行,第j列的特征值,那么该卷积操作的输出值y按以下公式进行计算:
4 GPU对卷积神经网络的加速
a(k+1)=f(W(k)·a(k)+b(k))
而对于CNN中的卷积层计算,我们也可以将其转化为矩阵乘法运算。如图3所示,中间为输入的特征图像,上方展示了传统的卷积计算方法,下方展示了将卷积转化为矩阵乘法的方法,主要思路是将卷积核和对应窗口的特征图展开成一维向量。
对于矩阵乘法的运算,Nvidia提供了基于CUDA实现的线性代数库cuBLAS(CUDA Basic Linear
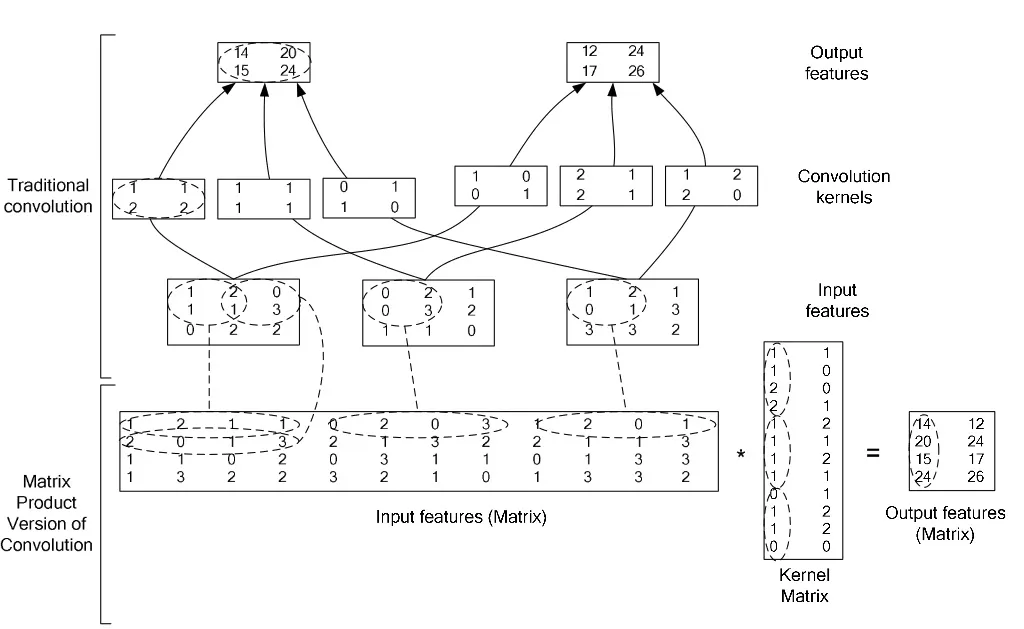
图3 卷积转化为矩阵乘法示意图
Algebra Subprograms,CUDA基础线性代数库)[7]。cuBLAS通过Nvidia的GPU加速线性代数的运算,用户可以调用cuBLAS API来计算向量加法、内积,矩阵加法、乘法等常用的线性运算。在调用cuBLAS API时,程序会在GPU中分配矩阵或向量所需的内存空间,并加载数据,调用对应的cuBLAS函数,在GPU计算完成后,再将计算结果从GPU内存空间上传到主机。
除此以外,Nvidia还针对深度神经网络进行专门的GPU优化,提供了cuDNN计算库[8]。可以看到,在将卷积转化为矩阵乘法的过程中,会产生很多冗余的数据量。而GPU的内存是非常宝贵的,在理想状态下,GPU内存中应该储存的是样本数据、参数和神经的激活值,而不是在计算过程中所产生的辅助数据。cuDNN的目标是在保证计算精度的前提下,消除这些额外的内存消耗,同时加快神经网络的计算速度。因此,cuDNN有助于GPU加载更大型的神经网络,同时训练更多的样本数据,也提高了神经网络的收敛速度。
5 总结
本文对GPU的发展现状进行了阐述,并将其与CPU在物理特性方面进行对比。然后对ANN和CNN卷积操作的计算方法进行说明,发现两者在计算过程中的共同特征,最后介绍了GPU对神经网络进行加速的方法和一些计算库,对深度学习算法的相关研究人员和从业人员具有一定的参考价值。
