主题模型在检索结果聚类中的应用
2018-02-12蒋宗礼赵思露
蒋宗礼 赵思露

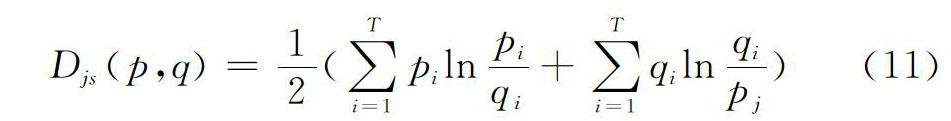
摘要:检索结果聚类能够有效帮助提高获取信息的效率和质量。针对传统文本聚类模型存在数据维数过高、缺乏语义理解等问题,提出一种面向检索结果聚类的融合共现分析主题建模算法。基于改進的LDA模型,对得到的“文档-主题”概率分布进行聚类分析,采用K-means算法完成聚类过程,最后提出根据聚类中心提取主题词作为类簇标签。实验结果表明,改进的LDA算法在检索结果聚类应用上不仅获得了很好的聚类效果,类簇标签也有良好的可读性。
关键词:LDA;共现分析;检索结果聚类;类簇标签
Research on Application of Topic Model in Clustering Search Results
JIANG Zong li,ZHAO Si lu
(Faculty of Information Technology,Beijing University of Technology,Beijing 100124,China)
Abstract:The clustering of search results can effectively help improve the efficiency and quality of information retrieval. Aiming at the problems of traditional data clustering models such as high data dimension and lack of semantic understanding, this paper proposes a fusion co occurrence analysis topic modeling algorithm oriented to the retrieval of results clustering.Based on the improved LDA model, the obtained “document subject” probability distribution is clustered, the K means algorithm is used to complete the clustering process, and finally the clustering center is used to extract topic words as cluster like tags. The experimental results show that the improved LDA algorithm not only has a good clustering effect on the clustering of search results, but also has a good readability of cluster labels.
Key Words:LDA;co occurrence analysis;clustering of search results;cluster label
0 引言
网络资源的不断增长使检索得到的返回结果数量庞大,而且根据检索相关性算法与排序算法的不同,返回的结果也具有一定差异性。检索结果聚类可以对得到的检索结果进行挖掘与组织,对信息进行合理总结与描述,从而有效提高了用户获取信息的效率和质量。它通过聚类技术将检索结果依据主题相似性划分到不同类簇,并提供类簇标签,使用户根据标签快速、准确定位到感兴趣信息所在的类别[1]。其主要有以下3个特征:①检索结果聚类不仅需要得到高质量的类簇,还需要描述每个类簇主题的可读标签;②检索结果聚类有许多可利用的信息,例如查询词信息、相关文档集信息等;③检索结果集本身就是一个以查询词为主题的大类簇,聚类后的类簇为查询词相关子主题的类簇。
传统基于VSM的聚类分析方法由于没有考虑文本中潜在的语义关联,不仅聚类效果受到限制,也使得到的类簇标签可读性差。
LDA主题模型可以有效挖掘文本内部的语义知识,因而被广泛应用于不同领域[2]。不同文本对象有其自身特点,当面向不同应用领域使用原始LDA主题模型时,结果都不够精准。本文在检索结果聚类应用研究基础上提出了基于查询关联分析的主题模型,并完成了检索聚类过程。
1 相关工作
Cutting等[3]首先在Scatter/Gather系统中引入对检索结果进行聚类以便用户快速浏览的思想,其采用的是经典的K-means聚类。最早的检索结果聚类算法利用已有的文本聚类算法,在聚类完成后抽取类簇标签。虽然在聚类质量上占有优势,但提取标签的可读性较差。然而,对于检索结果聚类而言,没有一个好的标签,聚类将失去主要意义,由此产生了基于标签的聚类算法。该算法先从返回的检索结果中抽取词或短语作为标签,再将结果分类到对应标签中。典型代表有Zamir等[4]提出的STC后缀树聚类算法,该算法主要通过发现高频共现短语作为聚类依据,但其过度依赖高频关键词,而忽略了词项间的隐含语义关系。为强调标签的可读性与对簇的描述性,Banerjee等[5]基于Wikipedia挖掘高频词语义相关词作为候选簇标签;Tseng等[6]基于WordNet抽取查询关联类别作为聚类描述,这种依赖抽取规则与外部信息资源的方法虽然使标签质量较好,但增大了聚类的时空复杂度,且簇的连贯性较差。
查询关键词为检索结果聚类的一个重要线索,文献[7]中通过对查询的抽取,寻找查询的修饰与限制成分及概念外延,以确定潜在的类别标签,该方法需要外部资源与句法分析知识作为支撑;Gelgi等[8]使用关系图表示查询词与词项的关联关系,通过查询词关联度分析对词项进行加权,以提高检索结果聚类质量,但文献中未涉及类簇标签的获取。
类簇标签的需求使文本语义信息挖掘在检索结果聚类中显得尤为重要。LDA模型能够挖掘文本的潜在语义信息,一些学者将其应用于情感分析、文本分类与推荐系统等方面[9 11],取得了很好的效果。文献[12]中将原始LDA模型应用于检索结果的聚类,在聚类质量与聚类标签提取方面都具有较好的语义描述效果,但其忽略了文本对象的特殊性及模型本身的缺陷。本文在面向特定检索结果聚类任务中对LDA主题模型进行了改进,将查询关联度融入吉布斯采样,使建模结果不再向高频词倾斜,突出了相关主题词权重查询,基于该模型完成了检索结果聚类任务。
2 LDA主题模型
2.1 模型介绍
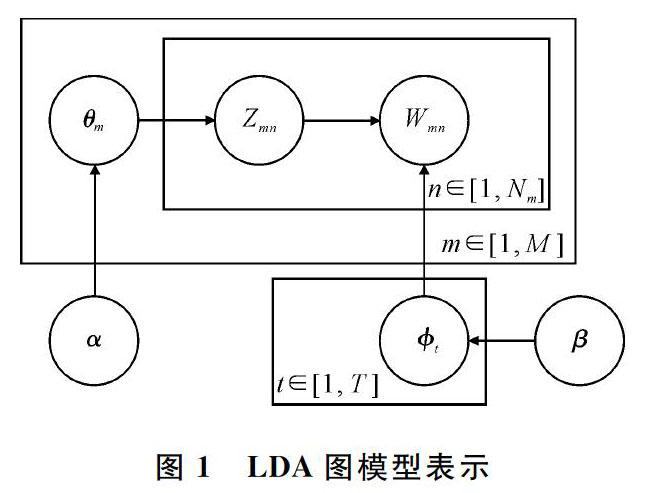
LDA主题模型是Blei等[13]提出的一个对离散数据集建模的三层产生式概率模型,其图模型表示如图1所示。
其中, M表示文档集总数,N m为文档m下的词总数,T为主题数目,θ m表示文档m的主题概率分布,φ t表示主题t的词项概率分布,α、β分别表示θ m和φ t Dirichlet先验分布的超参数, w mn、z mn表示第m篇文档下第n个单词与其主题,阴影节点表示可观测变量。该模型也解释了文本集中每篇文档的生成过程,共分为两步,对于文档m,先采样文档的主题概率分布为θ m~Dir(α),对于文档m的第n个单词w mn,先采样词的主题z mn~Mult(θ m)以及主题z mn的词分布采样w mn~Mult(φ z mn),重复N m次得到文档m。
采用Gibbs采样[14]对模型进行参数估计,其通过对联合分布各个分量轮换采样,构造收敛于目标概率分布的马尔可夫链,然后从中进行样本值采样。采样更新过程即估计当前采样词的主题后验分布如下:
得到每个词项的主题分配后,参数计算如下:
以上公式中,文档集中第i个词项w i=j,z i=k表示w i对应第k个主题;n(k) m,i表示第m篇文档除去第m个词后,主题k出现的次数;n(j) k,i表示第k个主题除去第i个词后,词项j出现的次数;α k、β j分别为主题k 与词项 j 的Dirichlet先验参数。
Gibbs算法通过采样得到每个主题的词项分布与文檔主题分布,然后根据式(1)得到当前采样词主题,最终得到一篇文档主题概率分布的表述。由分析可知,一个词的主题分配与该词在主题中的概率比,以及该词所在文档的主题概率分布有关,则高频词在文档与主题中的占比会较大。
2.2 LDA在检索结果聚类应用中存在的问题
根据对以上模型的分析,将主题模型应用于检索结果聚类具有以下优势:①可以避免传统聚类算法的维数灾难,将文档映射到较低维空间,实现文本基于语义层面的降维;②传统文本聚类方法基于概率词频统计,脱离了语义层面,基于主题模型的聚类以主题为依据,能将包含相似主题的文档聚为一类[15];③通过主题建模对文本集进行挖掘可以得到丰富的信息,并将其用于指导聚类质心选取等,改进聚类质量与效率[16];④对聚类结果的类簇标签抽取进行优化,得到的主题标签可读性更好,因而对于检索结果聚类具有重要意义;⑤模型参数空间规模固定,与文本自身规模无关,适合于大规模文本集。
然而原始的LDA模型基于词袋模型假设,认为每个词同等重要,使得模型向高频词主题倾斜,容易导致一些词出现次数不多但与查询词强相关,且主题区分度明显的词在建模过程中作用降低。本文充分利用查询词与查询相关文档的信息,将查询关联度权重融入主题模型,以改进文档建模效果,进而优化聚类质量。
3 面向检索结果聚类的LDA主题模型
3.1 检索结果文档集特征分析
检索结果文档都在查询词所限定的一个宽泛的主题下,通过聚类将其细分为一些更具体的子主题,每个子主题的文本都与查询词相关,每个子主题也与查询相关。为了更明确文本所属的子主题,通过表征该文本的特征词加以判断。图2为检索结果文本聚类结构。
显然与查询词关联程度越大的特征词,越能有效帮助一篇文档区分所属的子主题。
3.2 查询关联度计算
对于查询关键词,一般认为那些与其经常搭配出现的词可以更好地表现词的语义主题,其共现度越高,词项与其存在主题相关的可能性越大,越具有主题表达能力[17]。通过共现分析可以衡量词项与查询关键词之间的关联度,关联度越高,词项权重越大。
通常采用互信息分析词的共现关系,词 w i与w j 之间的互信息计算如式(4)所示.
p(w i,w j)为w i、w j同时出现的概率,p(w i)为w i出现的概率,p(w j)为w j出现的概率。假设检索结果集文档中每一个文档都包含查询词q,则对于文档集中任意词项w i,计算得到的共现关联度MI(w i,q)=0。若查询词在检索返回相关文档集中出现频率过高,则不适合采用互信息对查询词与文档集中的词项进行共现分析。而且这种方法只考虑了词项的共文档频率,而没有考虑两个词项的共现频度以及词项重要度。所谓共文档频度是指查询关键词与词项在检索结果文档集中共同出现在同一文档中的频度,而共现频度是指查询关键词与词项在同一篇文档中共同出现时,在该文档中两个词项分别出现的频度。
设D为检索结果文档集,|D|=M,d m∈D,m∈[1,M];W为文档集中所有的词项集合,|W|=N,w i∈W,i∈[1,N];Q为查询关键词集合,查询词q ∈Q;对于任意w i∈W,且w i≠q,w i、q在d m中出现的频度分别记作freq(w i|d m)与freq(q|d m),包含词项w i的文档集合记作D w i,则共现文档集合记作D w i,q;用M(w i,q)表示词项w i相对于查询关键词q的共文档率,即在出现查询词q的文档集中,同时出现w i的文档数与只出现查询词文档数的比。计算公式如下:
用F(w i,q)表示w i与查询词q在同一篇文档中的共现频度关系,查询词与共现词的紧密程度计算公式如下:
此外考虑词项与查询关键词在整个文档集中的重要性,以避免出现与查询关键词关联度很高的词在整个语料集上的重要性偏低,即其主题区分度不明显。此处引入逆文档频率IDF[18],计算公式如下:
其中C表示语料库中的文档集合,C w i为包含w i的文档集合。基于以上对共现因素的分析,构造查询关键词关联程度度量公式,用Cor(w i,Q)表示词项w i与查询词集Q的关联程度, 即:
其中 F(w i,q) 计算时需进行归一化处理。
3.3 改进后的LDA算法
得到各词项的查询关联度后,在对每个词的主题进行Gibbs采样过程中,当文档m的第i个词项w i=j分配到主题k时,式(2)中n(j) k,i的值不是累加1而是累加w i的词项关联度Cor(w i,Q)。同理,式(3)中的n(k) m,i也累加Cor(w i,Q)。由此得到“文档-主题”分布θ与“主题-词项”分布φ计算公式如下:
上式中,∑Mi=1n(k) m,i·Cor(w i,Q)为文档m主题k下所有词的关联度权重和,n(j) k,i·Cor(w i,Q)为主题k下所有词为j的关联度之和。
4 改进模型在检索结果聚类中的应用
本文采用基于划分的K means聚类算法[19],该算法具有线性时间复杂度,适合于处理大规模数据集合,其通过优化一个准则函数进行聚类划分。通过LDA建模后,文本被表示为主题概率向量。为发挥主题模型的优势,本文使用衡量概率分布差异的函数JS距离替代传统的相似度计算方法[20],其为KL散度的对称版本,将距离定义在区间[0,1]上。对于主题概率向量 p=(p 1,p 2,…,p T)与q=(q 1,q 2,…,q T) ,其相似度定义为:
由于類簇标签抽取对检索结果聚类具有重要意义,类簇标签应能清晰、准确地概括聚类中所有文档的共同主题[21]。传统基于最大词频的标签提取缺乏语义信息、可读性差、用户不易理解,对聚类的描述不够准确且与查询词的关联度低,主题特征不明显。LDA可将文本表示为主题概率分布向量,通过聚类,主题分布相似的文档被放在同一类簇中,主题分布率高的主题即代表该类簇主题,因此选取主题下词项概率分布高的词作为描述该类簇的标签,标签抽取具体步骤如下:
(1)得到聚类算法迭代终止时各类簇的聚类中心,选取距离聚类中心最近的s篇文档集合S={d 1,…,d s}。
(2)统计集合S中每篇文档的主题概率分布,将概率分布最大的主题作为类簇主题,记作Z max (i),i=1,…,K。
(3)得到主题Z max (i) 的“主题-词项”概率分布,选取占比最大的前两个词项作为主题描述词,即该类簇标签。
整个实验算法步骤如图3所示。
5 实验数据及结果分析
5.1 实验数据
由于目前尚没有一个应用于检索结果聚类评价的标准中文测试集,本文通过构造不同的查询关键词提交给百度搜索引擎,选取返回结果的前10页,约100个结果(排序算法已可保证覆盖查询词的大部分语义分布)作为数据源,用于构建实验数据集。构造5个查询词:“苹果”、“金刚”、“长城”、“猎豹”、“熊猫”,采集5个检索结果集合,共670篇网页文本。对网页文本进行预处理,包括HTML解析、分词、去停用词等,并对文档表示格式进行处理,作为LDA建模的输入。同时对每个集合中的文档采用人工进行分类,每个类别对应查询词在检索结果集合中的一个语义分布。
5.2 参数设置
LDA模型对检索结果集进行建模时,模型中的先验超参数按照经验值设置为 α=50/T,β=0.01,主题数T 设为20,Gibbs采样迭代次数为500次。聚类过程中, 若K值过大会导致聚类结果不易理解,过小则聚类效果不明显。为便于模型的实验测评,本文选取人工分类得到的主题数K进行聚类,随机选取初始聚类中心,为避免收敛到局部最优,重复执行多次。
5.3 建模结果评价分析
对“猎豹”的检索结果集分别使用原始LDA与BQ-LDA进行建模,表1、表2为两种模型的部分主题词项分布,词项根据分布数量由高到低排列。
由表1、表2可以看出,在LDA模型中,分布靠前的词项存在着一些主题区别度差且重要性低的词,而改进后的结果主题语义区分明显,靠前的词项能清晰地描述主题,与查询关联度更大的词项分布位序都得到了提升。
本文分别对不同查询词进行聚类,对于聚类结果,采用F-Measure作为评价标准,其定义参照信息检索的评测方法。假设聚类文档数为 N,N i表示正确划分时类别i中的文档个数,N j表示聚类结果类簇j中的文档个数,N(i,j)表示结果类簇j正确划分i中的文档数,则类别i与聚类结果j 的F-Measure计算如下:
其中P表示准确率,R表示召回率。
整个聚类结果的评价函数为:
图4为不同查询下文档集合使用不同模型的聚类效果。
由图4可以看到,使用主题模型的聚类质量比传统VSM要高,而改进后模型应用于聚类后的F值相比原始LDA更高,最多时高出了9个百分点。
在标签提取过程中, 将s值 设为3,查询词为“猎豹”时,各模型聚类下的类簇标签结果如表3所示。
由表3可以看出,VSM下的标签语义描述效果最差,根据标签并不能理解类簇主题,而相比于传统LDA模型,改进后的模型对簇的描述与区分度更好。
6 结语
将查询词信息融入聚类,基于融合查询关联度的主题模型对检索结果文档建模,使用基于主题模型的类簇抽取方法,可以得到不错的聚类效果与区分性强的类簇标签。然而,聚类算法实验中需要设定初始聚类数目,在Gibbs采样的时间效率方面尚存在不足之处,有待下一步改进。
参考文献:
[1] 柏晗,成颖,柯青.网络检索结果聚类研究综述[J].情报理论与实践,2015,38(10):138 144.
[2] 祖弦,谢飞.LDA主题模型研究综述[J].合肥师范学院学报,2015,33(6):55 58.
[3] CUTTING D R, KARGER D R,PEDERSEN J O, et al. Scatter/Gather: a cluster based approach to browsing large document collections[J]. 1992:318 329.
[4] ZAMIR O E. Clustering Web documents: a phrase based method for grouping seach engine results[C].University of Washington,1999.
[5] BANERJEE S, RAMANATHAN K, GUPTA A. Clustering short texts using Wikipedia[C].International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM,2007:787 788.
[6] TSENG Y H, LIN C J, CHEN H H,et al. Toward generic title generation for clustered documents[M]. Berlin: Springer Berlin Heidelberg,2006.
[7] 陈毅恒.文本检索结果聚类及类别标签抽取技术研究[D].哈尔滨:哈尔滨工业大学,2010.
[8] GELGI F, DAVULCU H, VADREVU S. Term ranking for clustering Web search results[J]. Proceedings of International Workshop on the Web & Databases,2007.
[9] LI F,HUANG M, ZHU X. Sentiment analysis with global topics and local dependency[C].Twenty Fourth AAAI Conference on Artificial Intelligence. AAAI Press,2010:1371 1376.
[10] 李文波,孙乐,张大鲲.基于Labeled LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620 627.
[11] YANG M, CUI T, TU W. Ordering sensitive and semantic aware topic modeling[C].Proceedings of the Twenty Ninth AAAI Conference on Artificial Intelligence, 2015:2353 2359.
[12] 阮光册,夏磊.基于主题模型的检索结果聚类应用研究[J].情报杂志,2017,36(3):179 184.
[13] BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. J Machine Learning Research Archive,2003,3:993 1022.
[14] GRIFFITHS T L, STEYVERS M. Finding scientific topics[J].Proceedings of the National Academy of Sciences of USA, 2004(1):5228 5235.
[15] 王李冬,魏寶刚,袁杰.基于概率主题模型的文档聚类[J].电子学报,2012,40(11):2346 2350.
[16] 王春龙,张敬旭.基于LDA的改进K means算法在文本聚类中的应用[J].计算机应用,2014,34(1):249 254.
[17] 赵蓉英,陈晨.基于共现分析的中文文献检索结果聚类研究[J].情报科学,2014(1):115 118.
[18] JONES K S. A statistical interpretation of term specificity and its application in retrieval[J]. Journal of Documentation, 1972,28(1):493 502.
[19] NASRAOUI O. Web data mining: exploring hyperlinks, contents, and usage data[M]. New York:ACM,2008.
[20] ENDRES D M, SCHINDELIN J E. A new metric for probability distributions[J]. IEEE Transactions on Information Theory,2003,49(7):1858 1860.
[21] 韩中华.检索结果聚类中的类别标签抽取技术研究[D].哈尔滨: 哈尔滨工业大学,2011.
